综述
所谓:“近朱者赤,近墨者黑”
本文采用编译器:jupyter
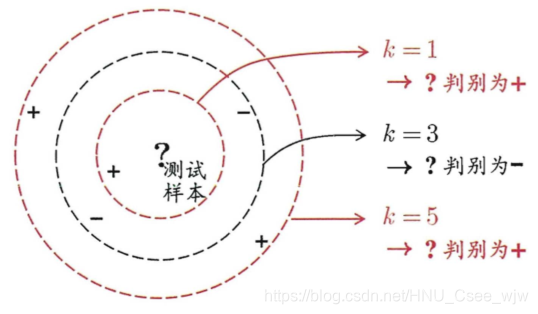
k近邻(简称kNN)算法是一种常用的监督学习算法, 其工作机制非常简单 : 给定测试样本,基于某种距离度量找出训练集中与其最靠近的 k个训练样本,然后基于这 k个"邻居"的信息来进行预测。
通常, 在分类任务中可使用"投票法" 即选择这 k个样本中出现最多的类别标记作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
kNN算法的示意图如下,可以很明显的看出当k取值不同时,判别结果可能产生较大的差异。
可以看出它天然的可以解决多分类问题,思想简单却十分强大!
01 kNN基础
以下为数据准备阶段
# 导入所需要的两个包
import numpy as np
import matplotlib.pyplot as plt
# 各数据点
raw_data_X = [[3.3935, 2.3312],
[3.1100, 1.7815],
[1.3438, 3.3683],
[3.5822, 4.6791],
[2.2803, 2.8669],
[7.4234, 4.6965],
[5.7450, 3.5339],
[9.1721, 2.5111],
[7.7927, 3.4240],
[7.9398, 0.7916]
]
# 各数据点所对应的标记
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
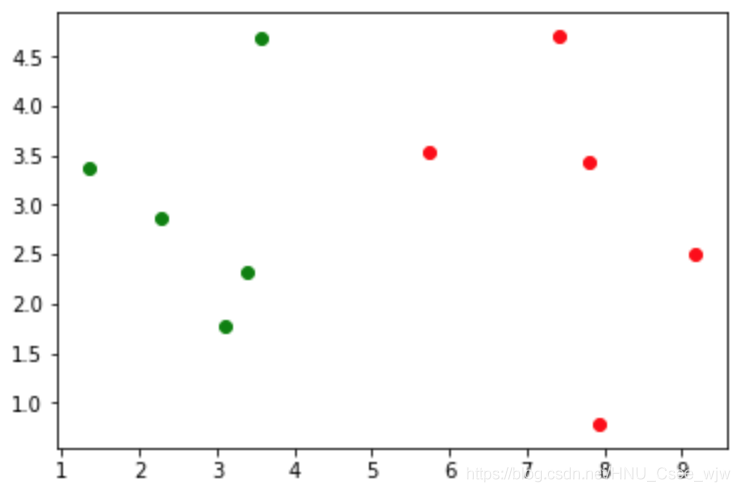
#绘制散点图
plt.scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], color='g')
plt.scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], color='r')
plt.show()
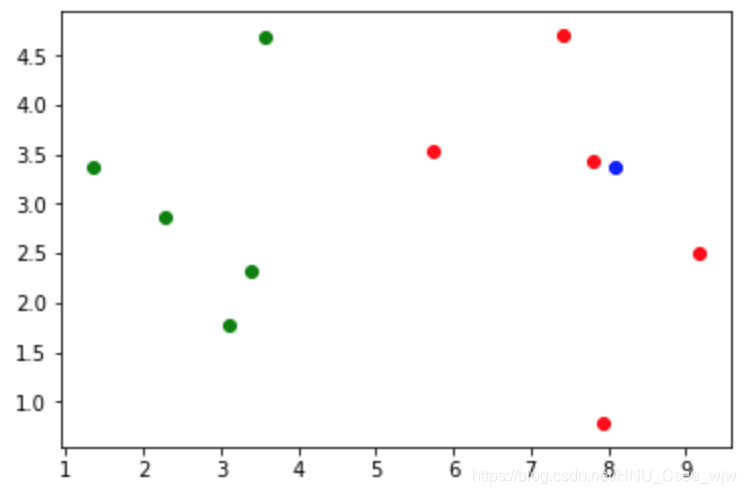
# 模拟待分类数据
x = np.array([8.0936, 3.3657])
plt.scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], color='g')
plt.scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], color='r')
plt.scatter(x[0], x[1], color='b')
plt.show()
执行结果:
kNN的过程
1.计算待测数据与所有数据点的“距离”
2.指定k的大小
3.找出模型中与待测点最近的k个点
4.应用“投票法”预测出分类结果
# 计算欧拉距离所需跟方操作
from math import sqrt
distances = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x) ** 2)) # Universal
distances.append(d)
# distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in X_train]
nearest = np.argsort(distances) # 找离x最近的k个点的索引
# 指定k
k = 6
# 计算最近点k个点
topK_y = [y_train[i] for i in nearest[:k]]
# 使用Counter方法统计标签类别
from collections import Counter
votes = Counter(topK_y)
# In [22]:
# votes.most_common(1) # 找出票数最多的那1个类别,
# Out[22]:
# [(1, 5)]
predict_y = votes.most_common(1)[0][0] # 预测结果
# In [27]:
# predict_y
# Out[27]:
# 102 使用scikit_learn中的kNN
python标准库scikit_learn中也为我们封装好了kNN算法
# 导入kNN算法
from sklearn.neighbors import KNeighborsClassifier
# 创建分类器对象
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train, y_train) # 先训练模型
“”“
fit方法返回对象本身
Out[7]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=6, p=2, weights='uniform')
”“”
X_predict = x.reshape(1, -1) # 传入的数据需要是一个矩阵,这里待预测的x只是一个向量
# In [9]:
# X_predict
# Out[9]:
# array([[ 8.0936, 3.3657]])
y_predict = kNN_classifier.predict(X_predict)
# In [13]:
# y_predict[0]
# Out[13]:
# 1
03 测试我们的算法
本例使用datasets数据集中的鸢尾花数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 加在鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# In [4]:
# X.shape
# Out[4]:
# (150, 4)
# In [5]:
# y.shape
# Out[5]:
# (150,)
train_test_split
平时我们在拿到一个数据集时,往往将其一部分用于对机器进行训练,另一部分用于对训练过后的机器进行测试,即train_test_split
"""
In [6]:
y
Out[6]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
"""
shuffle_indexes = np.random.permutation(len(X)) # 打乱数据,形成150个索引的随机排列
"""
In [8]:
shuffle_indexes
Out[8]:
array([ 22, 142, 86, 111, 72, 80, 17, 137, 5, 66, 33, 55, 40, 122, 108, 24, 45, 110, 68, 46, 118, 44, 136, 121, 78, 31, 103, 35, 105, 107, 76, 116, 84, 144, 123, 57, 42, 7, 38, 28, 117, 115, 89, 58, 126, 74, 49, 27, 94, 77, 85, 21, 119, 132, 100, 120, 6, 104, 62, 53, 64, 41, 106, 26, 29, 18, 129, 146, 148, 1, 82, 139, 135, 96, 127, 56, 37, 130, 65, 149, 113, 92, 131, 2, 4, 125, 54, 79, 50, 61, 112, 95, 19, 109, 102, 141, 30, 39, 83, 25, 140, 60, 12, 20, 138, 71, 59, 11, 13, 0, 52, 91, 3, 73, 23, 124, 15, 14, 81, 97, 75, 114, 16, 69, 32, 134, 36, 8, 63, 51, 147, 67, 93, 47, 133, 48, 143, 43, 34, 98, 87, 88, 145, 70, 90, 9, 10, 128, 101, 99])
"""
test_ratio = 0.2 # 设置测试数据集的占比
test_size = int(len(X) * test_ratio)
test_indexes = shuffle_indexes[:test_size] # 测试数据集索引
train_indexes = shuffle_indexes[test_size:] # 训练数据集索引
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
print(X_train.shape)
print(y_train.shape)
# (120, 4) (120,)
print(X_test.shape)
print(y_test.shape)
# (30, 4) (30,)
sklearn中的train_test_split
sklearn中同样为我们提供了将数据集分成训练集与测试集的方法
# 首先创建一个kNN分类器my_knn_clf,略
# 导入模块
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
print(X_train.shape)
print(y_train.shape)
# (120, 4) (120,)
print(X_test.shape)
print(y_test.shape)
# (30, 4) (30,)
my_knn_clf.fit(X_train, y_train)
# Out[32]:
# KNN(k=3)
y_predict = my_knn_clf.predict(X_test)
sum(y_predict == y_test)/len(y_test)
# Out[34]:
# 1.004 分类准确度
本例使用datasets中手写识别数据集来演示分类准确度的计算
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits() # 手写识别数据集
# In [3]:
# digits.keys()
# Out[3]:
# dict_keys(['data', 'target', 'target_names', 'images', 'DESCR'])
print(digits.DESCR)
X = digits.data # 数据集
y = digits.target # 标记
# 随便取一个数据集
some_digit = X[666]
some_digit_image = some_digit.reshape(8, 8)
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary)
plt.show()执行结果:

scikit-learn中的accuracy_score
# 导入split方法先将数据集拆分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 导入创建kNN分类器的方法
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
# 导入sklearn中计算准确度的方法
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
# Out[27]:
# 0.99444444444444446
05 超参数
超参数:在算法运行前需要确定的参数,即kNN中的k
模型参数:算法过程中学习到的参数
通过以上对kNN方法的讨论可知,kNN算法没有模型参数
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
knn_clf.score(X_test, y_test)
# Out[4]:
# 0.98611111111111116
寻找最好的k
best_score = 0.0
best_k = -1
for k in range(1, 11): # 搜索1到10中最好的k,分别创建k等于不同值时的分类器,用score方法评判
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
print("best_k=",best_k)
print("best_score=",best_score)
# best_k= 7
# best_score= 0.988888888889
考虑距离?不考虑距离?
kNN算法如果考虑距离,则分类过程中待测数据点与临近点的关系成反比,距离越大,得票的权重越小
best_method = ""
best_score = 0.0
best_k = -1
for method in ["uniform", "distance"]:
for k in range(1, 11): # 搜索1到10中最好的k
knn_clf = KNeighborsClassifier(n_neighbors=k, weights=method)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
best_method = method
print("best_method=",best_method)
print("best_k=",best_k)
print("best_score=",best_score)
# best_method= uniform
# best_k= 1
# best_score= 0.994444444444搜索明可夫斯基距离相应的p
%%time
best_p = -1
best_score = 0.0
best_k = -1
for k in range(1, 11): # 搜索1到10中最好的k
for p in range(1, 6): # 距离参数
knn_clf = KNeighborsClassifier(n_neighbors=k, weights="distance", p = p)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
best_p = p
print("best_p=", best_p)
print("best_k=", best_k)
print("best_score=", best_score)
# best_p= 2
# best_k= 1
# best_score= 0.994444444444
# CPU times: user 15.3 s, sys: 51.5 ms, total: 15.4 s Wall time: 15.5 s以上多重循环的过程可以抽象成一张网格,将网格上面的所有点都遍历一遍求最好的值
06 网格搜索
补充:kNN中的“距离”
明可夫斯基距离:此时获得了一个超参数p,当p = 1时为曼哈顿距离,当p = 2时为欧拉距离
![]()
数据准备:
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
knn_clf.score(X_test, y_test)
# Out[4]:
# 0.98888888888888893Grid Search
可以将上一节中的网格搜索思想用以下方法更简便的表达出来
# 定义网格参数,每个字典写上要遍历的参数的取值集合
param_grid = [
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1, 11)]
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1, 11)],
'p':[i for i in range(1, 6)]
}
]
knn_clf = KNeighborsClassifier()
# 导入网格搜索方法(此方法使用交叉验证CV)
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_clf, param_grid)
%%time
grid_search.fit(X_train, y_train)
# CPU times: user 2min 2s, sys: 320 ms, total: 2min 2s Wall time: 2min 3s
“”“
GridSearchCV(cv=None, error_score='raise', estimator=KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform'),
fit_params=None, iid=True, n_jobs=1, param_grid=[{'weights': ['uniform'],
'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}, {'weights': ['distance'],
'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'p': [1, 2, 3, 4, 5]}],
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None,
verbose=0)
”“”
grid_search.best_estimator_ # 返回最好的分类器,(变量名最后带一个下划线是因为这是根据用户输入所计算出来的)
“”“
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=3, p=3, weights='distance')
”“”
grid_search.best_score_ # 最好方法的准确率
# Out[11]:
# 0.98538622129436326
grid_search.best_params_ # 最优方法的对应参数
# Out[12]:
# {'n_neighbors': 3, 'p': 3, 'weights': 'distance'}
knn_clf = grid_search.best_estimator_
knn_clf.score(X_test, y_test)
# Out[14]:
# 0.98333333333333328
%%time
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=2) # n_jobs采用多少核,verbose:执行时输出,整数越大,信息越详细
grid_search.fit(X_train, y_train)
Fitting 3 folds for each of 60 candidates, totalling 180 fits
[CV] n_neighbors=1, weights=uniform ..................................
[CV] n_neighbors=1, weights=uniform ..................................
[CV] n_neighbors=1, weights=uniform ..................................
[CV] n_neighbors=2, weights=uniform ..................................
[CV] ................... n_neighbors=1, weights=uniform, total= 0.7s
[CV] n_neighbors=3, weights=uniform ..................................
[CV] ................... n_neighbors=2, weights=uniform, total= 1.0s ......
CPU times: user 651 ms, sys: 343 ms, total: 994 ms Wall time: 1min 23s
[Parallel(n_jobs=-1)]: Done 180 out of 180 | elapsed: 1.4min finished
07 数据归一化处理
import numpy as np
import matplotlib.pyplot as plt最值归一化Normalization
x = np.random.randint(1, 100, size = 100)
(x - np.min(x)) / (np.max(x) - np.min(x)) # 最值归一化
# 对矩阵的处理
X = np.random.randint(0, 100, (50, 2))
X = np.array(X, dtype=float) # 转换成能取小数的类型
X[:,0] = (X[:, 0] - np.min(X[:, 0])) / (np.max(X[:, 0]) - np.min(X[:, 0]))
X[:,1] = (X[:, 1] - np.min(X[:, 1])) / (np.max(X[:, 1]) - np.min(X[:, 1]))
plt.scatter(X[:,0], X[:,1])
plt.show() 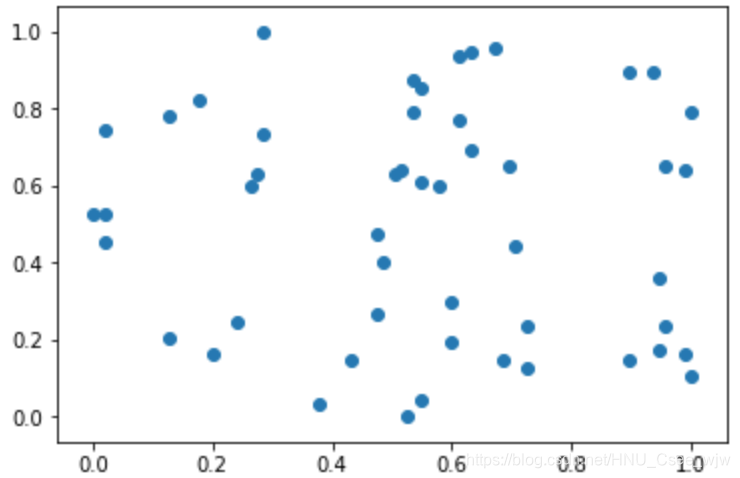
# 查看最值归一化方法的性质
np.mean(X[:,0]) # 第一列均值
# Out[13]:
# 0.55073684210526319
np.std(X[:,0]) # 第一列方差
# Out[14]:
# 0.29028548370502699
np.mean(X[:,1]) # 第二列均值
# Out[15]:
# 0.50515463917525782
np.std(X[:,1]) # 第二列方差
# Out[16]:
# 0.29547909688276441均值方差归一化Standardization
X2 = np.random.randint(0, 100, (50, 2))
X2 = np.array(X2, dtype=float)
X2[:,0] = (X2[:,0] - np.mean(X2[:,0])) / np.std(X2[:,0])
X2[:,1] = (X2[:,1] - np.mean(X2[:,1])) / np.std(X2[:,1])
plt.scatter(X2[:,0], X2[:,1])
plt.show()
# 查看均值方差归一化方法性质
np.mean(X2[:,0]) # 查看均值
# Out[24]:
# -3.9968028886505634e-17
np.std(X2[:,0]) # 查看方差
# Out[25]:
# 0.99999999999999989
np.mean(X2[:,1])
# Out[26]:
# -3.552713678800501e-17
np.std(X2[:,1])
# Out[27]:
# 1.0
注意对测试数据集的归一化方法:由于测试数据集模拟的是真实的数据,在实际应用中可能只有一个数据,此时如果对其本身求均值意义不大,所以此处减去训练数据的均值再除以方差。
08 Scikit-Learn中的Scaler
Scikit-Learn中专门为数据归一化操作提供了专门的类,和kNN类的对象一样,需要先进行fit操作之后再执行归一化操作,如下:
数据准备
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size = 0.2, random_state=666)
scikit-learn中的StandardScaler
# 导入均值方差归一化对象
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(X_train)
StandardScaler(copy=True, with_mean=True, with_std=True)
# 查看归一化方法性质
standardScaler.mean_
# Out[9]:
# array([ 5.83416667, 3.0825 , 3.70916667, 1.16916667])
standardScaler.scale_ # 标准差
# Out[10]:
# array([ 0.81019502, 0.44076874, 1.76295187, 0.75429833])
X_train = standardScaler.transform(X_train)
# 训练数据经过归一化之后测试数据也应该进行归一化操作
X_test_standard = standardScaler.transform(X_test)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
# Out[17]:
“”“KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=3, p=2, weights='uniform')
”“”
knn_clf.score(X_test_standard, y_test)
# Out[18]:
# 1.0
knn_clf.score(X_test, y_test) # 此结果有误,传进来的测试数据集也必须和训练数据集一样归一化
# Out[19]:
# 0.33333333333333331
附件:仿照实现sklearn中的kNN分类器,调用方法完全一样。
pycharm,sublime,记事本可以用各种写,你懂的
kNN.py:
import numpy as np
from math import sqrt
from collections import Counter
from .metrics import accuracy_score
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k"
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def score(self, X_test, y_test):
"""根据测试数据集确定当前准确度"""
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
def __repr__(self):
return "KNN(k=%d)" % self.k
metrics.py:
import numpy as np
def accuracy_score(y_true, y_predict):
"""计算y_true和y_predict之间的准确率"""
# 保证预测对象的个数与正确对象个数相同,才能一一对比
assert y_true.shape[0] == y_predict.shape[0], \
"the size of y_true must be equal to the size of y_predict"
return sum(y_predict == y_true) / len(y_true)
model_selection.py:
import numpy as np
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将数据X和y按照test_ratio分割成X_train, X_test, y_train, y_test"""
# 确保有多少个数据就有多少个标签
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, \
"test_ratio must be valid"
if seed:
np.random.seed(seed)
shuffle_indexes = np.random.permutation(len(X)) # 打乱数据,形成150个索引的随机排列
test_size = int(len(X) * test_ratio)
test_indexes = shuffle_indexes[:test_size] # 测试数据集索引
train_indexes = shuffle_indexes[test_size:] # 训练数据集
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test
preprocessing.py:
import numpy as np
class StandardScaler:
def __init__(self):
self.mean_ = None
self.scale_ = None
def fit(self, X):
"""根据训练数据集X获得数据的均值和方差"""
assert X.ndim == 2, "The dimension of X must be 2"
self.mean_ = np.array([np.mean(X[:,i]) for i in range(X.shape[1])])
self.scale_ = np.array([np.std(X[:, i]) for i in range(X.shape[1])])
return self
def transform(self, X):
"""将X根据这个StandardScaler进行均值方差归一化处理"""
assert X.ndim == 2, "The dimension of X must be 2"
assert self.mean_ is not None and self.scale_ is not None, \
"must fit before transform!"
assert X.shape[1] == len(self.mean_), \
"the feature number of X must be equal to mean_ and std_"
resX = np.empty(shape=X.shape, dtype=float)
for col in range(X.shape[1]):
resX[:,col] = (X[:,col] - self.mean_[col]) / self.scale_[col]
return resX
