Convolutional Pose Machine总结
目录
Convolutional Pose Machine简介
Convolutional Pose Machine 简称CPM,将深度学习应用于人体姿态分析,是CMU开源项目OpenPose的前身,在MPII竞赛single person中排名第七。
算法详细分析
Pose estimation任务属于FCN的一种,输入是一张人体姿势图,输出n张热力图,代表n个关节的响应。

CPM的网络结构和感受野如下图所示:

CPM的算法思想来源于Pose Machine,上图中的网络结构详细介绍如下:
插图(a)和(b)是pose machine中的结构,(c)和(d)是对应的卷积网络。插图(e)展示图片在网络中传输的不同阶段的感受野。
stage 1
stage1如上述插图(a)和(c)所示,stage 1只对输入图片做处理。在该阶段,输入图片经过X代表的经典VGG结构,并用1*1卷积,输出一个belief map,如果人体有p个关节点,那么belief map有p层,每一层表示一个关节点的heatmap。belief map与label计算该阶段的loss,并存储起来,在网络末尾将每一层的loss加起来作为total loss用于反向传输,实现中间监督,避免梯度消失。stage t
对于stage 2 以及后面的stage,其结构一致,我们统称为stage t。
在stage t 中,网络的输入包含两个内容:
(1)上一个stage输出的belief map;
(2)对原始图片的处理结果,这里的处理操作如插图(d)x‘部分所示,与stage 1中的X一样,也是借鉴经典的VGG中的结构。
如果图片中有多个人物,需要对多人进行姿态估计时,在这里还要输入一个center map。center map是一个高斯响应,当图片中有多人时,center map告诉神经网络目前要处理的人的位置,从而自底向上处理多人pose问题。
stage t阶段输出与stage 1 一致,也是标注关节点位置的belief map。感受野
感受野即输出图片一个像素在原始图片上映射的区域大小。CMP采用大卷积核获得大感受野,对于推断被遮挡的关节很有效。可以看到在网络的stage 2 的输出部分,感受野已经扩大到400*400的大小。
作者在论文中指出,预测的准确率随着感受野的增大而提高(这里应该指的是在同一个网络中感受野的增大,即在同一次训练过程中感受野的增大),在FLIC数据集中对于手腕关节的预测,当感受野增大到250pixcel时预测的准确率趋于稳定状态,这表明神经网络编码了(encode)身体部件之间的长距离交互。在以上网络结构图最好的输出结果中,将原始图片预处理至368*368,stage 2 输出值的感受野相当于原始输入图片的400*400像素,此时感受野可以覆盖图片中身体的任何一个部件。stage越多,感受野也就越大。下面是论文中给出的准确率随感受野上升的曲线图:
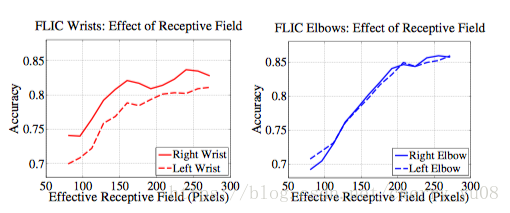
论文中指出,为了增大感受野,一般有如下几种方式:
1. 增大pool,但是这种做法对图片额外添加的信息过多,会牺牲精度;
2. 增大卷积核,但这种方式会增加参数量;
3. 增加卷积层,但卷积层过多会造成网络的负担,造成梯度消失等问题。
论文中提出的增大卷积和的方式是增大stride,确实stride越大感受野相应的也增大,并且论文中指出,在高精度区域,8stride和4stride表现一样好。
算法流程
训练阶段
网络输入彩色图像(绿色ori image)。以半身模型为例,分为四个阶段(stage)。每个阶段都能输出各个部件的响应图(蓝色score),使用时以最后一个阶段的响应图输出为准。

center map(绿色)是一个提前生成的高斯函数模板,用来把响应归拢到图像中心。

使用阶段
人物检测
人物检测部分代码与姿态估计类似,只是最后一个stage输出的是一个指示了人物位置的map。
首先将图片resize到固定大小,然后pad(因为网络会将图片downsize所以先pad,这样能得到与原始图片相同大小的输出图片),运行网络,得到定义人物位置的块:
对应人物的位置:
单人姿态估计的话可以省略这一步。姿态估计
根据上面的center position将每个人物分割开来,使用CPM网络进行预测。输出的图片中,另加一层background channel绘制关节点的位置,如果需要,可以连接关节点。


创新点
CPM的网络结构相当于结合了VGG(网络结构图中的X和X‘部分)和FCN(pixcel level的处理,输出不是向量而是与图片等宽等高的矩阵),在此基础之上加入三个辅助内容:
1. belief map
一方面是获取每一个stage输出的heatmap,同时该belief map有助于后续stage的训练,根据论文中下图图片描述可知,belief map提供的易于检测部位的上下文信息为不易检测的部位(遮挡部位)提供了检测的线索:

2. 中间监督
在每一个stage的输出阶段计算bilief map和label的loss,最后将所有loss加和得到total loss,根据每一个stage的loss更新该阶段的参数w,这种方法实现中间监督,可以有效避免梯度消失(或者梯度爆炸)
3. center map
center map是一个与图片同等大小、通道数为1的高斯模版,用于处理图片中多个人物的情况,实现多目标的姿态估计。
数据集
MPII Human Pose Dataset
数据集内容如下,该数据集定义了人体带检测的关节点的种类以及坐标,神经网络也是根据这些坐标信息实现pixel level的训练。
LSP dataset
- FLIC dataset

效果展示
- 手势预测:
对于手部关节点,CPM提出的方法可以做出很好的预测,convolutional-pose-machines-tensorflow 如下所示的手势预测:
身体姿态预测:
单人效果:
多人效果:
其它
根据上面两项功能类推,对于一些与面部相关的预测也是可以实现的。



本文主要是自己对CPM学习的总结,文中有错误之处欢迎批评指正。
参考资料
博客
- 贴出了相关的代码,很清晰明了
https://blog.csdn.net/yeahDeDiQiZhang/article/details/78131566?locationNum=1&fps=1 - 给出了网络的结构流程图和详细的讲解
https://blog.csdn.net/shenxiaolu1984/article/details/51094959 - 对论文思路有较清晰的解读
https://blog.csdn.net/mpsk07/article/details/79522809 - 画出来CPM的网络结构流程图
https://blog.csdn.net/qq_36165459/article/details/78321054
github
- convolutional-pose-machines-release(论文对应的代码)
https://github.com/shihenw/convolutional-pose-machines-release - convolutional-pose-machines-release的python版
https://github.com/shihenw/convolutional-pose-machines-release/blob/master/testing/python/demo.ipynb - convolutional-pose-machines-tensorflow
https://github.com/timctho/convolutional-pose-machines-tensorflow - cpm
https://github.com/psycharo/cpm - Convolutional-Pose-Machine-tf
https://github.com/mpskex/Convolutional-Pose-Machine-tf - 3D_hand_pose_estimation_from_single_depth_image
https://github.com/Peng154/3D_hand_pose_estimation_from_single_depth_image - tf-pose-estimation
https://github.com/ildoonet/tf-pose-estimation