文章目录
参考博客:
https://www.aiuai.cn/aifarm176.html
https://blog.csdn.net/shenxiaolu1984/article/details/51094959
代码链接:
caffe
tensorflow
该论文展示了如何将卷积网络嵌入到人体姿态估计框架中,来学习图像特征和与图像无关的空域特征。
贡献点:
使用序列化的卷积结构来表达图像信息和空间信息。
序列化的卷积结构表现在网络分为多个阶段,每个阶段都有监督训练的部分,前面阶段使用原始图片作为输入,后面阶段使用之前阶段的特征图作为输入,产生对局部位置越来越精细的估计。主要是为了融合空间信息,纹理信息和中心约束。另外,对同一个卷积架构同时使用多个尺度来处理输入的特征和响应,能够在保证精度的同时,不失其空间结构信息。
1. Introduction
本文提出了一种针对人体姿态估计任务的 Convolutional Pose Machines (CPMs)
CPMs的特点:
- 能够从数据中直接学到图像和空间信息的特征表达
- 能够使用BP进行端到端的学习
- 能够解决大量数据的高效训练
CPMs组成结构:序列化的卷积网络,能够不断的提取每个局部位置的2D特征图
每个stage的输入: 来自前一stage的图像特征+响应图
每个响应图(belief maps)可以提供:为下一阶段的stage提供每个部件的表达性强的非参数化编码。
网络学习的东西: 没有使用图形化模型[28,38,39]或专门的后处理步骤[38,40]来显式解析这种响应图,而是学习直接作用于中间响应图的卷积网络,并学习每个部分之间依赖于图像的隐式空间模型间的关系。
每个部件响应的空间信息可以提供很强的二义性消除线索,所以,CPM的每个stage都可以提供对每个部件的位置信息越来越精确的估计,如下图所示:

为了捕捉每个部件间的 long range 的关系,每个stage的设计都是为了实现在图像上和响应图上的大的感受野。并且,经过实验,我们发现响应图上大的感受野对学习 long range 空间关系非常重要。
CPM中将多个卷积网络组合起来带来的问题: 训练过程会有梯度消失现象
CMP中如何解决: 使用对称的网络结构来修正梯度,并通过网络定期执行中间监督来引导网络生成越来越精确的响应图。
主要贡献:
- 通过有序的组合卷积结果来学习隐式空间模型
- 利用对称的网络来同时学习图像特征和依赖于图像的空间模型
2. 网络结构简介
网络结构:
网络输入彩色图像(绿色ori image)。以半身模型为例,分为四个阶段(stage)。每个阶段都能输出各个部件的响应图(蓝色score),使用时以最后一个阶段的响应图输出为准。

center map(绿色)是一个提前生成的高斯函数模板,用来把响应归拢到图像中心。

第一阶段:
第一阶段是一个基本的卷积网络1(白色convs),从彩色图像直接预测每个部件的响应。半身模型有9个部件,另外包含一个背景响应,共10层响应图。
第二阶段:
第二阶段也是从彩色图像预测各部件响应,但是在卷积层中段多了一个串联层(红色concat),把以下三个数据合一:
- 阶段性的卷积结果(464632)→→ 纹理特征
- 前一阶段各部件响应(464610)→→ 空间特征
- 中心约束(46461)
串联后的结果尺寸不变,深度变为32+10+1 = 43。
第三阶段:
第三阶段不再使用原始图像为输入,而是从第二阶段的中途取出一个深度为128的特征图(feature image)作为输入。同样使用串联层综合三种因素:纹理特征+空间特征+中心约束。
原始图像和128层中的部分特征图层:

后续阶段:
第四阶段结构和第三阶段完全相同。在设计更复杂的网络时(例如全身模型),只需调整部件数量(从10变为15),并重复第三阶段结构即可。

数据扩展:
为了丰富训练样本,对原始图片进行随机旋转缩放镜像。
这部分由一个新定义的caffe层cpm_data实现。仅在训练时使用。
标定:
姿态数据集中标定的是各个部件的位置,可以通过在每个关键点的真实位置上放置一个高斯响应,来构造响应图的真值。
对于包含多个人的图像,生成两种真值响应:
a. 在每个人的相应部件位置,放置高斯响应。(下图左)
b. 只在标定的人的相应部件位置,放置高斯响应。(下图右)

由于第一阶段只能考虑局部特征,故将a用于第一阶段网络训练,b用于后续阶段网络训练。
中间监督优化:
每层输出都计算loss

多尺度:
训练时,已经通过cpm_data层对数据进行了尺度扩充。在测试时,直接从原图生成不同尺度的图像,分别送入网络。将所得相应结果求和。下图示出第1,4,8,12尺度:

3. Method
3.1 Pose Machines
每个位置的坐标 , 是第 p 个 part 的像素位置
本文的目标: 预测 个 parts 在图像中的位置 .
Pose Machine组成部分: 一系列的多类别预测器 ,这个预测器分别被用来预测每个尺度特征图中 part 位置。
在每个stage 中, 会预测响应图,用来给每个 part分配位置。
上述位置怎么得到:
- 1、每个位置 上所抽取的图像特征
- 2、前一个stage
的分类器得到的
附近的上下文信息

stage t=1 时,分类器 预测的响应值为:
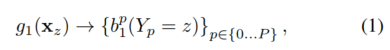
其中, 是分类器 的第一个stage中预测的第p个部件在位置 z 上的得分。
记在图片中每个位置 z 的部件p的所有置信得分为
,其中,w和h分别为宽和高。
则:
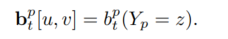
方便起见,将所有部件(关键点)的响应图(belief maps)集合标记如下,p个关键点+1个背景类

stage>1时,分类器基于两种输入来预测关键点位置的置信(belief):
- 图片特征
- 前一stage分类器输出的每个关键点周围的上下文信息
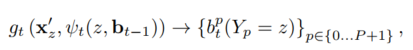
其中,
是置信
到上下文特征的映射。
每个stage计算的置信(beliefs)对每个关键点的位置估计越来越精细。
这里,第一个stage之后的所有stage用到的图像特征 和 stage=1时所用到的图像特征 是不同的。
pose machine 使用 boosted random forests 来作为分类器 ,手工设计每个stage的所有图像特征 (x’=x),手工设计特征图来学习所有stages的空间信息。
3.2 Convolutional Pose Machines —— CPMs
本节描述如何利用CPM来代替PM来实现直接从数据来学习图像和上下文的特征表示。
根据源码给出的 deploy.prototxt,CPM 部署时是 multi-scales 的,处理流程:
[1] - 基于每个 scale,计算网络预测的各关节点 heatmap;
[2] - 依次累加每个关节点对应的所有 scales 的 heatmaps;
[3] - 根据累加 heatmaps,如果其最大值大于指定阈值,则该最大值所在位置 (x,y) 即为预测的关节点位置.

3.2.1 Keypoint Localization Using Local Image Evidence
stage=1时的关键点定位
stage=1时,CPM仅仅根据局部图像信息(Local image evidence)来预测关键点。
局部图像信息:stage=1时,网络的感受野被约束到输出像素位置的small patch(小的块儿),如图所示:

输入图像经过一个全卷积网络:5 个卷积层和 2 个1x1 卷积层
为了得到较好的precision,文中将输入crop到368x368大小,上述全卷积网络的感受野就是160x160大小。
该网络结构可以被看做:大小为368x368的图像,经过一个卷积网络的滑动提取特征,从每个在160x160大小的patch 中的局部图像信息中回归一个p+1个输出向量,表示每个位置上每个关键点出现的得分。
卷积层不改变图像大小,经过三次pooling,输出46x46大小的特征图,共p+1个特征图。
t>=2时,网络的输出是一致的,都是46x46x(p+1)的特征图。
3.2.2 Sequential Prediction with Learned Spatial Context Features
检测外观始终比较一致的landmarks会比较容易,比如头和肩膀。但一些低于人体固件链接的 landmarks 的准确率会很低,由于这些的结构和外观很多变。
尽管关键点邻域内的响应图会有一定的噪声,但是同样可以提供很多的信息。
如图3所示,当检测类似于右手手肘这些有挑战性的关键点时,右肩膀的响应图会有一个尖锐的峰值,这可以被看做一个强线索。
也就是容易检测的关键点可以为难以检测的关键点提高有用的信息。
容易检测的关键点队友后续stage的响应图来说,有助于消除其错误的估计(红色),提升其正确的估计(绿色)。

stage>1时,所有 stage 的预测器(
)都可以使用图像位置
邻域内的噪声响应图的空域信息,因为一个关键点肯定出现在一个固定的几何关系空间。
t=2时,分类器 的输入如图,包括:
- 原始图像特征图像特征
- 卷积结果:前面的stage对每个关键点的belief,通过特征函数 计算得到的特征
- 生成的center 的Gaussian中心约束(caffe代码)
t>2时,分类器 的输入,不再包括原始图片特征,而是替换为上一层的卷积结果,其它的输入与 t=2 相同. 也是三个输入.
特征函数 的作用是对先前 stage 不同关节点的空间 belief maps 编码.
CMP中,不需要用函数计算上下文特征,而是定义 作为分类器在前一stage的belief上的感受野。
设计网络的灵感:为了实现第二个stage的输出足够大,能够保证可以学习到关键点间的潜在信息和 long-range 联系。

大的感受野可以通过很多方法来得到:
- pooling,会牺牲精度
- 大的kernel size,会使参数量增加,训练时出现梯度消失的风险
- 提升卷积层数量
该文章中使用如图2(d)中的方法来提升感受野:
- 使用多个卷积层来实现在8x下采样的heatmap上的大的感受野
- 作者发现步长为8的网络可以和步长为4的网络 表现效果相当,大步长带来了大的感受野

3.2.3 CMP的学习过程
将pose machine换成深度的结构,会导致参数量增加,也会出现梯度消失的现象。
pose machine 的每个stage 都会产生每个关键点的预测结果,重复的输出每个关键点位置的belief maps,以逐渐精细化的方式估计关键点。
所以,每个stage输出后都计算loss,作为中介监督loss避免梯度消失的问题。
loss函数:最小化每个关键点的预测和真实 belief map 的 距离
关键点p的ground truth belief map 记为
,是通过在每个关键点 p 的真实为(x,y) 放置gaussian函数模板的方式得到的。
如:

loss函数是最小化每个level中每个stage的输出,所以:
每个stage的loss函数:
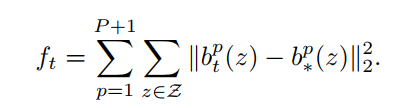
最终的loss函数:
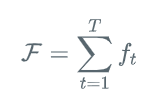
所有的 stage t>=2,共享特征图x‘(caffe实现中 T=6)’
4. 实验
4.1 分析
梯度消失:
证明使用中间loss对梯度消失的作用:
图5中是不同深度的结构,有/无中间监督的梯度情况

early epoch:没有中间监督时,由于有梯度消失,所以梯度的分布在0周围
有中间监督时,每个层的梯度分布方差都较大
端到端训练的效果: Fig6(a)
中间监督的效果: Fig6(b)
每个stage的结果: Fig6©

实验结果:


