MapReduce计算模型是大数据处理模式的鼻祖,这种模型很容易实现数据处理对并行化,并且编程模型简单,但对于复杂的运算逻辑往往需要大量的代码。
MapReduce任务涉及到的组件
在hadoop1.x中,MapReduce的运行依赖于JobTracker和TaskTracker,但在最新的hadoop版本中,以及被yarn替代,涉及到的主要组件有:
1)ResourceManager:负责整集群的资源管理和任务分配
2)NodeManager:负责单个节点的资源管理及执行任务
3)ApplicationMaster:负责当前Job的资源申请,任务调度以及错误处理等
4)Container:Yarn中资源的抽象,Task运行在Container所规则的资源边界内
MapReduce的运行模式
本地模式
本地模式是运行在程序员电脑上,以多线程的方式模拟MapReducer过程,适合本地调试
Yarn-Client
MapTask和ReduceTask运行在集群的NodeManager节点上,但ApplicationMaster运行在客户端,这种模式能够更好但观察到Job的运行情况
Yarn-Cluster
这种方式是将Task和ApplicationMaster都运行在NodeManager的Container上,好处是客户端可以快速返回,不用阻塞等待计算结果。但由于ApplicationMaster由ResourceManager分配,不利于查找相关日志。
MapReduce的运行步骤
mapreduce任务主要分为四个步骤:
1)输入分片
2)maptask
3)shuffle
4)reduce
输入分配由FileInputFormat完成,将输入数据划分为多个分片,每个分片对应一个MapTask,默认分片大小为块大小,可用通过参数进行调节。分片是从逻辑上切分数据,而不是在物理上重新划分数据块。
maptask阶段就会执行程序员指定的map函数处理逻辑。
shuffle是mapreduce最神奇最神秘的地方,在这里会执行combiner,分区,排序等操作。shuffle通过可以分为map端shuffle和reduce端shuffle。
reduce是最后一个步骤,执行程序员指定的处理逻辑,然后会将最终写入存储中。
MapReduce的执行流程
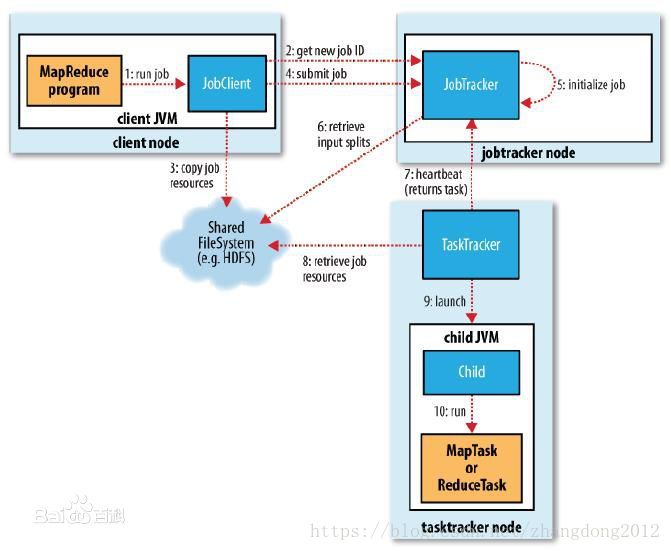
准备阶段
1)客户端请求ResourceManager运行作业,并得到一个jobid
2)客户端InputFormat对输入进行分片,分片大小为:
Math.max(minSplitSize, Math.min(maxSplitSize, blockSize))
然后生成分片描述文件
3)客户端将分片描述文件,job配置文件及jar包上传到hdfs指定目录下
4)客户端再次请求ResourceManager运行job
5)ResourceManager根据集群负载及各个节点中资源到使用情况,选择一个NodeManager启动一个Container,然后在这个Container上启动一个ApplicationMaster
6)ApplicationMaster向ResourceManager注册自己
7)ApplicationMaster从hdfs上下载job对应的分片描述文件,并根据分片描述文件计算task任务数及所需资源
8)ApplicationMaster向ResourceManager申请计算资源(Container)
9)ApplicationMaster根据ResourceManager分配的资源描述找到对应的ResourceManager并在其中启动Container
10)ApplicationMaster将Task分配到这些Container上,并实时监控运行状态以及负责Task任务到容错
执行阶段
1)maptask读取输入分片到数据,以文件为例,文本行号作为key,行内容作为value传入map函数
2)执行程序员指定到map计算逻辑
3)map函数在运行过程中,首先会将结果写入到内存中的环形缓冲区,该环形缓冲区默认大小为100M
4)当环形缓中区使用量超过80%时,启动后台线程,将缓冲区中的数据溢写到磁盘
5)在溢写到过程中会进行分区和排序,保证每个溢写文件中到内存分区内有序
6)如果配置了Combainer函数,那么还会在溢写的最后,对每个分区内对数据引用Combiner函数进行预聚合,减少shuffle阶段对磁盘IO和网络IO
7)当maptask全部执行完成后,合并所有溢写文件并再次进行分区,排序,执行Combiner函数,最终生成一个大文件,文件内对数据按分区进行分段,每个分区内的数据保证有序
8)reducer端首先从不同的map节点上拉取属于自己所在分区的数据,然后进行合并和排序,并且合并相同的key对应的value值,每个key-values会调用一次reduce函数
9)然后执行程序员指定的reduce函数计算逻辑
10)最终将结果写出
MapReduce的优化策略
推测执行
在执行过程中,如果ApplicationMaster发现某个task执行速度非常缓慢,会再启动一个相同的task,如果有一个task执行完成,就会把另一个杀掉,这样在一些场景下可以避免因为一些偶然因素拖慢task执行进而影响整个作业。
JVM重用
默认情况下,每个task对应一个jvm进程,这样如果运行的任务都是一些小任务,就会造成频繁启动和销毁jvm,造成大量额外开销,这时可以开启jvm重用机制,将具有串行关系的task调度到同一个jvm实例上,这样就可以最大限度到限制jvm实例数量,降低频繁启动和销毁jvm造成到开销。