版权声明:版权归零零天所有 https://blog.csdn.net/qq_39188039/article/details/86225364
序列化/反序列化机制
当自定义一个类之后,如果想要产生的对象在hadoop中进行传输,那么需要
这个类实现Writable的接口进行序列化/反序列化
案例:统计每一个人产生的总流量
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class Flow implements Writable{
private String phone;
private String city;
private String name;
private int flow;
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getFlow() {
return flow;
}
public void setFlow(int flow) {
this.flow = flow;
}
// 反序列化
@Override
public void readFields(DataInput in) throws IOException {
// 按照序列化的顺序一个一个将数据读取出来
this.phone = in.readUTF();
this.city = in.readUTF();
this.name = in.readUTF();
this.flow = in.readInt();
}
// 序列化
@Override
public void write(DataOutput out) throws IOException {
// 按照顺序将属性一个一个的写出即可
out.writeUTF(phone);
out.writeUTF(city);
out.writeUTF(name);
out.writeInt(flow);
}
}
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowMapper extends Mapper<LongWritable, Text, Text, Flow> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Flow f = new Flow();
f.setPhone(arr[0]);
f.setCity(arr[1]);
f.setName(arr[2]);
f.setFlow(Integer.parseInt(arr[3]));
context.write(new Text(f.getPhone()), f);
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowReducer extends Reducer<Text, Flow, Text, IntWritable> {
public void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException {
int sum = 0;
String name = null;
for (Flow val : values) {
name = val.getName();
sum += val.getFlow();
}
context.write(new Text(key.toString() + " " + name), new IntWritable(sum));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.flow.FlowDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Flow.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.60.132:9000/mr/flow.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.60.132:9000/flowresult"));
if (!job.waitForCompletion(true))
return;
}
}
练习:统计每一个学生的总成绩 — score.txt
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class Student implements Writable {
private int month;
private String name;
private int score;
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public void readFields(DataInput in) throws IOException {
this.month = in.readInt();
this.name = in.readUTF();
this.score = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(month);
out.writeUTF(name);
out.writeInt(score);
}
}
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class ScoreMapper extends Mapper<LongWritable, Text, Text, Student> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Student s = new Student();
s.setMonth(Integer.parseInt(arr[0]));
s.setName(arr[1]);
s.setScore(Integer.parseInt(arr[2]));
context.write(new Text(s.getName()), s);
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ScoreReducer extends Reducer<Text, Student, Text, IntWritable> {
public void reduce(Text key, Iterable<Student> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (Student val : values) {
sum += val.getScore();
}
context.write(key, new IntWritable(sum));
}
}
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ScorePatitioner extends Partitioner<Text, Student> {
@Override
public int getPartition(Text key, Student value, int numPartitions) {
int month = value.getMonth();
return month - 1;
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ScoreDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.score.ScoreDriver.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
job.setPartitionerClass(ScorePatitioner.class);
job.setNumReduceTasks(4);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Student.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.60.132:9000/mr/score1"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.60.132:9000/scoreresult"));
if (!job.waitForCompletion(true))
return;
}
}
分区 - Partitioner
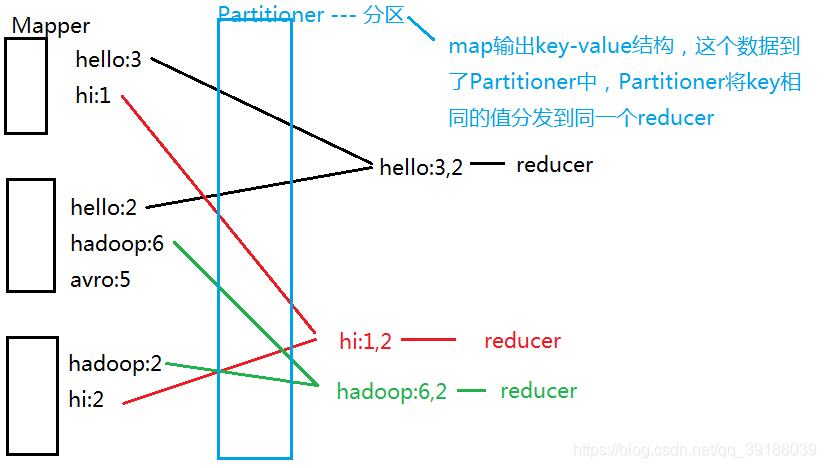
分区操作是shuffle操作中的一个重要过程,作用就是将map的结果按照规则
分发到不同reduce中进行处理,从而按照分区得到多个输出结果。
Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类
HashPartitioner是mapreduce的默认partitioner。计算方法是:which
reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
注:默认情况下,reduceTask数量为1
很多时候MR自带的分区规则并不能满足我们需求,为了实现特定的效果,
可以需要自己来定义分区规则。
案例:根据城市区分,来统计每一个城市中每一个人产生的流量
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class Flow implements Writable{
private String phone;
private String city;
private String name;
private int flow;
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getFlow() {
return flow;
}
public void setFlow(int flow) {
this.flow = flow;
}
// 反序列化
@Override
public void readFields(DataInput in) throws IOException {
// 按照序列化的顺序一个一个将数据读取出来
this.phone = in.readUTF();
this.city = in.readUTF();
this.name = in.readUTF();
this.flow = in.readInt();
}
// 序列化
@Override
public void write(DataOutput out) throws IOException {
// 按照顺序将属性一个一个的写出即可
out.writeUTF(phone);
out.writeUTF(city);
out.writeUTF(name);
out.writeInt(flow);
}
}
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowMapper extends Mapper<LongWritable, Text, Text, Flow> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Flow f = new Flow();
f.setPhone(arr[0]);
f.setCity(arr[1]);
f.setName(arr[2]);
f.setFlow(Integer.parseInt(arr[3]));
context.write(new Text(f.getPhone()), f);
}
}
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class FlowPartitioner extends Partitioner<Text, Flow> {
@Override
public int getPartition(Text key, Flow value, int numPartitions) {
String city = value.getCity();
if(city.equals("bj"))
return 0;
else if(city.equals("sh"))
return 1;
else
return 2;
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowReducer extends Reducer<Text, Flow, Text, IntWritable> {
public void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (Flow val : values) {
sum += val.getFlow();
}
context.write(key, new IntWritable(sum));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.flow2.FlowDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Flow.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定分区
job.setPartitionerClass(FlowPartitioner.class);
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.60.132:9000/mr/flow.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.60.132:9000/fpresult"));
if (!job.waitForCompletion(true))
return;
}
}
Combiner
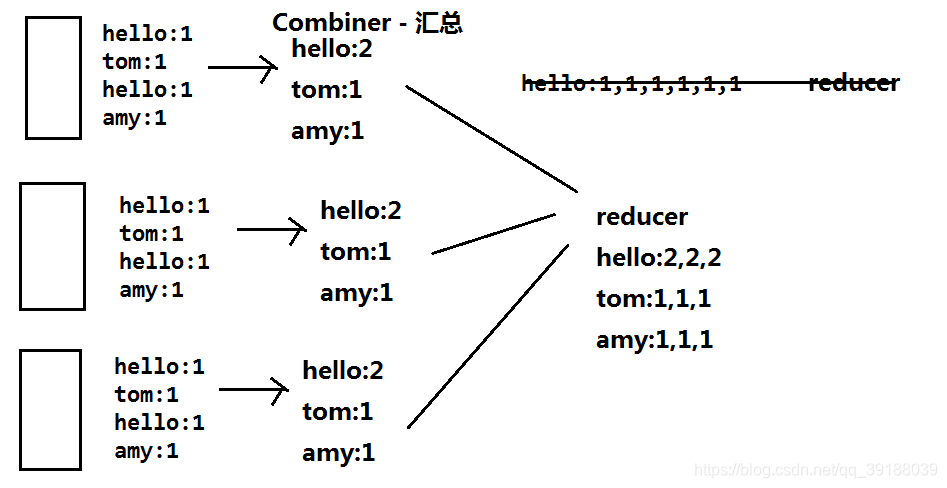
Combiner实际上就是一个Reducer
Map任务
- 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成
key、value对。每一个键值对调用一次map函数。 - 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
- 对输出的key、value进行分区。
- 对相同分区的数据,按照key进行排序(默认按照字典顺序进行排序)、分
组。相同key的value放到一个集合中。 - (可选)分组后的数据进行归约。
Map任务:
注意:在MapReduce中,Mapper可以单独存在,但是Reducer不能存在
Reducer任务
- 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce
节点。这个过程并不是map将数据发送给reduce,而是reduce主动去获取
数据。— Reducer的个数 >= 分区的数量 - 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输
入的key、value处理,转换成新的key、value输出。 - 把reduce的输出保存到文件中。
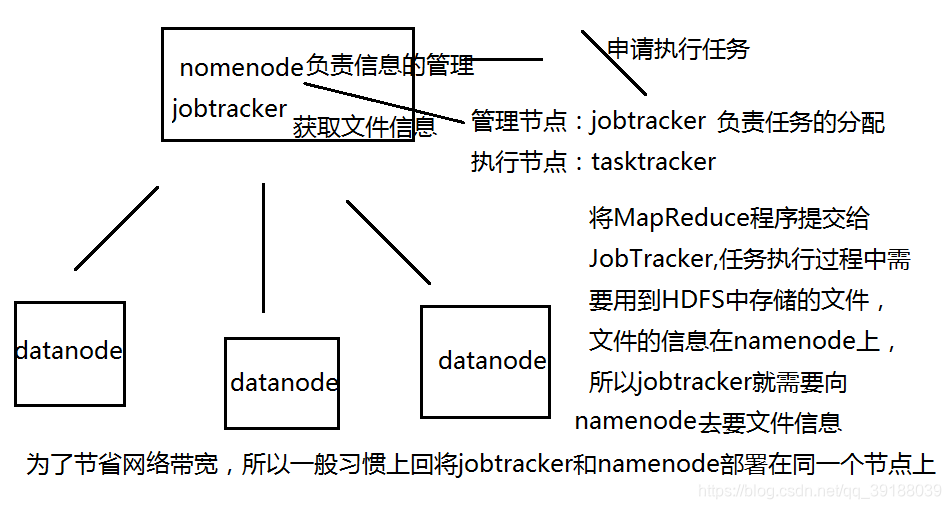
MapReduce的执行流程
- run job:客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar …。
- 做job环境信息的收集,比如各个组件类,输入输出的kv类型等,检测是否合法
- 检测输入输出的路径是否合法
- JobClient通过RPC和ResourceManager进行通信,返回一个存放jar包的地
址(HDFS)和jobId。jobID是全局唯一的,用于标识该job - client将jar包写入到HDFS当中(path = hdfs上的地址 + jobId) 3.
- 开始提交任务(任务的描述信息,不是jar, 包括jobid,jar存放的位置,配
置信息等等) - JobTracker进行初始化任务
- 读取HDFS上的要处理的文件,开始计算输入切片,每一个切片对应一个
MapperTask。注意,切片是一个对象,存储的是这个切片的数据描述信
息;切块是文件块(数据块),里面存储的是真正的文件数据。 - TaskTracker通过心跳机制领取任务(任务的描述信息)。切片一般和切
块是一样的,即在实际开发中,切块和切片认为是相同的。在领取到任
务之后,要满足数据本地化策略。 - 下载所需的jar,配置文件等。体现的思想:移动的是运算/逻辑,而不是
数据。 - TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask
或ReducerTask) - 将结果写入到HDFS当中
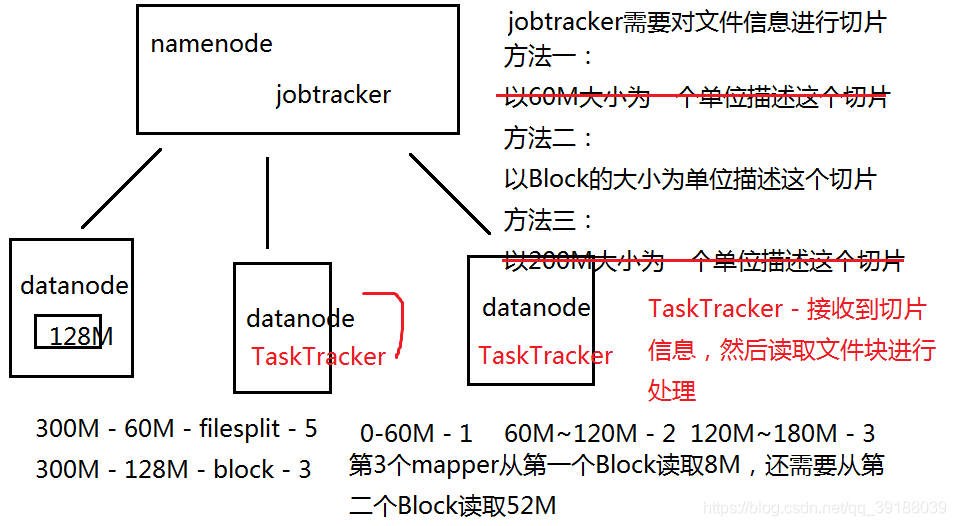
- 一般而言,切片的描述的大小和切块的大小是一致的 1.
- 习惯上,会将namenode也作为jobtracker,将datanode作为tasktracker
排序
如果想要进行排序,需要将排序的对象作为键才可以
案例:将利润求和后按照顺序排序
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
// WritableComparable -- 序列化 排序
public class Profit implements WritableComparable<Profit> {
private String name;
private int profit;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getProfit() {
return profit;
}
public void setProfit(int profit) {
this.profit = profit;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(profit);
}
@Override
public void readFields(DataInput in) throws IOException {
this.name = in.readUTF();
this.profit = in.readInt();
}
// 如果需要对结果排序,需要将排序规则写到这个方法中
@Override
public int compareTo(Profit o) {
return this.profit - o.profit;
}
}
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SortMapper extends Mapper<LongWritable, Text, Profit, NullWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split("\t");
Profit p = new Profit();
p.setName(arr[0]);
p.setProfit(Integer.parseInt(arr[1]));
context.write(p, NullWritable.get());
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SortReducer extends Reducer<Profit, NullWritable, Text, IntWritable> {
public void reduce(Profit key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(new Text(key.getName()), new IntWritable(key.getProfit()));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SumProfitDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.profit.SumProfitDriver.class);
job.setMapperClass(SumProfitMapper.class);
job.setReducerClass(SumProfitReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.60.132:9000/mr/profit.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.60.132:9000/sumprofit"));
if (!job.waitForCompletion(true))
return;
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SumProfitMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Text name = new Text(arr[1]);
int profit = Integer.parseInt(arr[2]) - Integer.parseInt(arr[3]);
context.write(name, new IntWritable(profit));
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SumProfitReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SortDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.profit.SortDriver.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setMapOutputKeyClass(Profit.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.60.132:9000/sumprofit"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.60.132:9000/sort"));
if (!job.waitForCompletion(true))
return;
}
}
数据
1 ls 2850 100
2 ls 3566 200
3 ls 4555 323
1 zs 19000 2000
2 zs 28599 3900
3 zs 34567 5000
1 ww 355 10
2 ww 555 222
3 ww 667 192