-
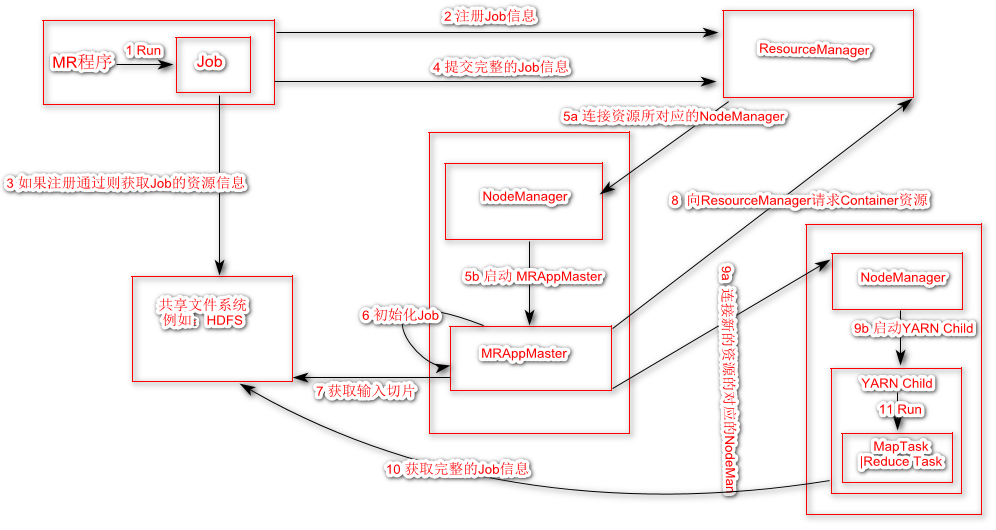
MapReduce计算流程
2 一个MR程序就是一个Job,Job信息会给Resourcemanger,向Resourcemanger注册信息
-
3 在注册通过后,Job会拷贝相关的资源信息(从HDFS中)
4 紧接着会向Resourcemanger提交完整的Job信息(包括资源信息)
5a Resourcemanger 会通过提交的Job信息,计算出Job所需的资源,为Job分配Container资源
5b 计算资源会分发给对应的NodeManger,NodeManager会创建一个MRAppMaster
6 MRAppMaster初始化Job
7 获取输入切片信息
8 MRAppMaster向ResourceManager 请求资源
9a 启动计算资源(连接到对应的资源所在NodeManager)
9b 启动YARN Child
10 从文件系统中获取完整的Job信息
11 启动对应的Maptask或者ReduceTask 进程,执行计算。