
摘要
特征工程一直是许多预测模型成功的关键。然而这个过程是重要的,而且经常需要手动进行特征工程或遍历搜索。DNN可以自动地学习特征地交互作用,然而,它们隐式地的生成所有的特征交互,这对于学习所有类型的交叉特征不一定有效。在本文中,我们提出了一种能够保持深度神经网络良好收益的深度交叉网络(DCN),除此之外,它还引入了一个新的交叉网络,更有效地学习在一定限度下的特征相互作用,更有甚,DCN在每一层确切地应用交叉特征而不需要人工特征工程,这相比于DNN模型增加地额外地复杂度可以忽略不计。我们的实验证明它在CTR预测数据机和稠密分类数据机上具有优越性能。
1 介绍
点击率(CTR)预测是一个大规模问题,对于数十亿美元的广告业来说至关重要,在广告业,广告商付钱给出版商,以便在它们的网站上发布广告,一种流行的付费模式是单次点击付费(CPC)模型,广告商只在用户点击时收取费用,因此,出版商的收入在很大程度上依赖于准确预测CTR的能力。
识别频繁的预测特征,同时探索隐式的或罕见的交叉特征是做好预测的关键,然而,Web规模推荐系统的数据大多是离散的和分类的,导致大量和稀疏的特征空间,这是具有挑战性的特征探索,这也限制了大多数大型系统的线性模型,如logistic回归。
线性模型简单、可解释、容易扩展,但限制了模型的表达能力,另一方面,交叉特征在提高模型表达能力方面具有重要意义,不幸的是,它常常需要人工特征工程或遍历搜索来识别这些特征;此外,泛化到隐式的特征交互是困难的。
在本文中,我们的目标是通过引入一种新的神经网络结构(跨网络)来避免特定于任务的特征工程,它以自动方式显式地应用特征交叉。交叉网络由多个层组成,其中层的深度可以证明交互作用的最高程度,每个层基于现有的层产生高阶交互,并保持与先前层的交互,我们跨网联合深层神经网络(DNN)进行训练[ 10, 14 ],DNN已经捕捉到非常复杂的相互作用的有限元分析,然而,相比我们的跨网络需要近一个数量级以上的参数,无法形成明确的交叉特征,可能无法有效地学习特征相互作用的类别。联合训练的交叉网络和DNN的组分能够有效地捕获预测特征的关系,并在Criteo CTR数据集上获得优越性能。
1.1 相关工作
由于数据集规模和维数的急剧增加,已经提出了许多方法,用来避免大规模特定任务的特征工程,主要是基于嵌入技术和神经网络。
因子机(FMs)[ 11, 12 ]将稀疏特征投射到低维稠密向量上,学习向量内积的特征相互作用,场意识的分解机(FFMs)[ 7, 8 ]进一步允许每个特征向量,每个向量学习的几个与字段关联,遗憾地是,浅层低结构的FMS和FMMs限制他们的表达能力,已经有工作扩展FMS到更高的等级[ 1, 18 ],但缺点在于他们大量的参数会产生更大的计算成本。深度神经网络(DNN)能够学习不平凡的高程度特征相互作用由于嵌入载体和非线性激活函数,最近非常成功的残差网络[5]使非常深网络的训练成为可能,DCN[ 15 ]扩展了残差网络,通过叠加所有类型的输入实现自动的特征学习。
深度学习的显著成功,引发了对其表达能力上的理论分析,已经有研究[ 16, 17 ]表明DNN能够逼近任意函数的某些平滑假设下的任意的精度,给出了足够多的隐藏单元或隐藏层,此外,在实践中,已发现DNNs工作以及可行的参数个数。其中一个关键原因在于实际兴趣的大部分功能并不是任意的。
然而,还有一个问题是,DNN是否真的表达出实际利益最有效的功能。在kaggle竞赛中,人工生成的特征在许多获奖的解决方案中处于低程度,具有显式格式和有效性,了解到DNN的特点是内隐的、高度非线性的,这揭示了一个模型能够比通用的DNN设计更能够有效地学习的有界度特征相互作用。
W&D网络[ 4 ]是这种精神的典范。它以交叉特征作为一个线性模型的输入,与一个DNN模型一起训练线性模型,然而,W&D网络的成功取决于正确的交叉特征的选择,这是一个至今还没有明确有效的方法解决的指数问题。
1.2 主要贡献
在本文中,我们提出了深度交叉网络(DCN)模型,使网络规模的自动进行稀疏和密集输入的特征学习,DCN有效地捕获有限度的有效特征的相互作用,学会高度非线性的相互作用,不需要人工特征工程或遍历搜索,并具有较低的计算成本。
论文的主要贡献包括:
- 我们提出了一种新的交叉网络,在每个层上明确地应用特征交叉,有效地学习有界度的预测交叉特征,并且不需要手工特征工程或穷举搜索。
- 跨网络简单而有效。通过设计,各层的多项式级数最高,并由层深度决定。网络由所有的交叉项组成,它们的系数各不相同。
- 跨网络内存高效,易于实现。
- 我们的实验结果表明,交叉网络(DCN)在LogLoss上与DNN相比少了近一个量级的参数量。
本文的结构如下:第2节描述了深层和交叉网络的体系结构。第3部分详细分析了交叉网络。第4节给出了实验结果。
2 深度交叉网络(DCN)
在本节中我们介绍深度交叉网络的体系结构(DCN)模型。一个DCN模型从嵌入和堆积层开始,接着是一个交叉网络和一个与之平行的深度网络,之后是最后的组合层,它结合了两个网络的输出。完整的网络模型如图1所示。
2.1 嵌入和堆叠层
我们考虑具有稀疏和密集特征的输入数据。在网络规模推荐系统中,如CTR预测,输入主要是分类特征,如“country=usa”。这些特征通常是编码为独热向量如“[ 0,1,0 ]”;然而,这往往导致过度的高维特征空间大的词汇。
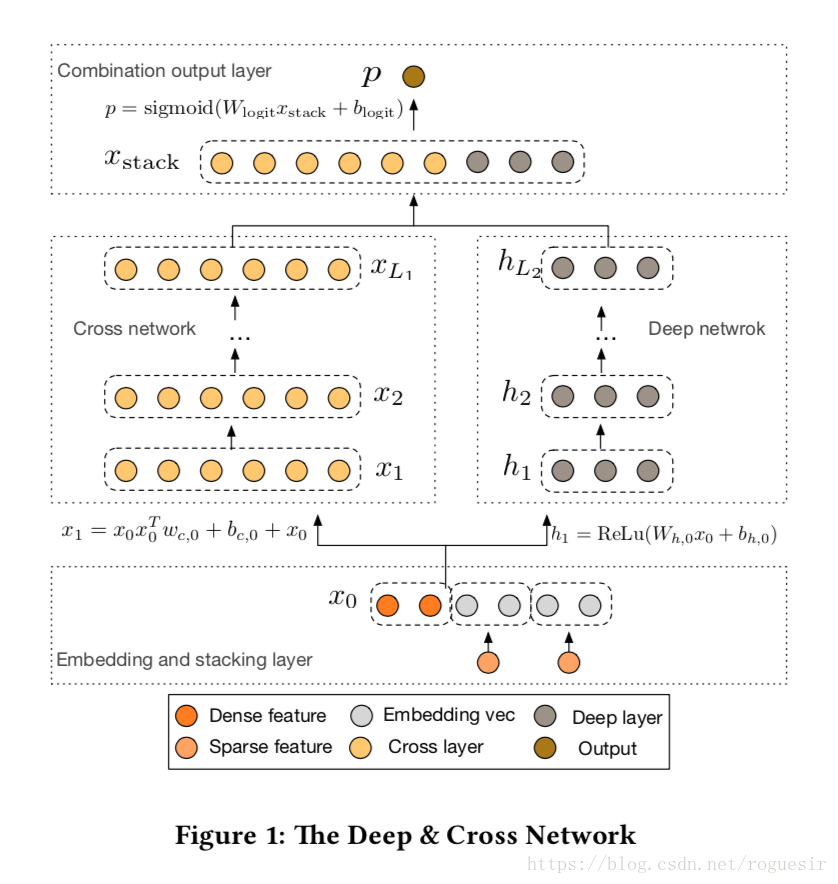
为了减少维数,我们采用嵌入过程将这些二进制特征转换成实数值的稠密向量(通常称为嵌入向量):
2.2 交叉网络
我们的交叉网络的核心思想是以有效的方式应用显式特征交叉。交叉网络由交叉层组成,每个层具有以下公式:
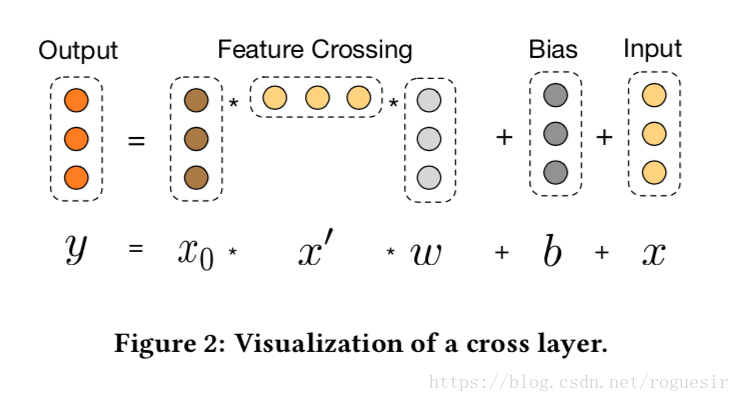
交叉特征高度交互。交叉网络的特殊结构使交叉特征的程度随着层深度的增加而增大。多项式的最高程度(就输入X0而言)为L层交叉网络L + 1。事实上,交叉网络包含了从1到L1的所有交叉项。详细分析见第3节。
复杂度分析。 表示交叉层数, 表示输入维度。然后,参数的数量参与跨网络参数为:
交叉网络的少数参数限制了模型容量。为了捕捉高度非线性的相互作用,我们并行地引入了一个深度网络。
深度网络
深度网络就是一个全连接的前馈神经网络,每个深度层具有如下公式:
复杂度分析。简单起见,我们假设所有的深层都是一样大小的。 表示层的深度, 表示深层尺寸。在深度网络中,参数量为:
这块公式太多,快要打吐了,先翻译后面的
4 实验结果
本节中,我们在一些主流分类数据集上评估了DCN的效果。
4.1 Criteo广告展现数据
Criteo展示广告的数据集是为了预测广告点击率,它有13个整数特征和26个分类特征,每个类别都有很高的基数。在这个数据集上,logloss具有0.001的提升都具有实际意义,当考虑到大量的用户群时,预测精度的微小提高可能会导致公司收入的大幅度增加。数据包含7天11 GB的用户日志(约4100万记录)。我们使用前6天的数据进行培训,并将第7天的数据随机分成相等大小的验证和测试集
4.2 实施详细
DCN在Tensorflow上实现,我们简要讨论DCN的一些实现细节。
数据处理与嵌入。实值特性通过应用对数变换进行标准化。对于分类特征,我们嵌入密集向量的特征维度:
。在一个1026维的向量连接所有嵌入的结果。
优化。我们使用Adam优化器进行小批量随机优化,batch size设置为512,在深度网络中设置批标准化,梯度剪切标准化设置为100。
正则化。使用早停止,因为我们发现
正则或使用dropout并没有效果。
超参数。我们展示了基于网格搜索的隐藏层数量、隐藏层大小、初始学习速率和跨层层数等结果。隐藏层的数量从2到5不等,隐藏层大小从32到1024。DCN,交叉层数从1到6。初始学习率进行了调整,从0.0001到0.001,增量为0.0001。所有的实验应用早期停止训练的150000步,超过150000就会出现过拟合。
4.3 模型比较
我们将DCN和以下5中模型进行比较:不带交叉网络的DCN结构(DNN)、逻辑回归(LR)、因子机(FMs)、宽而深模型(W&D)、深度交叉模型(DC)。
深度神经网络。嵌入层、输出层和超参数微调过程与DCN相同。唯一的变化是没有交叉层。
逻辑回归。我们用Sybil[ 2 ] ——一种大规模机器学习系统实现的分布式逻辑回归。在对数刻度上离散整数特征。交叉特征是由一个复杂的特征选择工具选择的,所有的单一功能都被使用了。
因子机。我们使用基于FM的模型,具有专有的细节。
W&D。不同于DCN,其广泛的组件需要输入原始稀疏的特点,以及依赖于遍历搜索和选择预测跨领域知识的特点。我们跳过了比较,因为没有已知好的方法来选择交叉特征。
DC。相比于DCN,DC并没有形成明确的交叉特征。它主要依靠堆叠和残差单位来创建隐式交叉点。我们采用相同的嵌入(堆叠)层的DCN,紧接着又热鲁层生成输入序列的残差单元。剩余单元数从1到5调整,输入尺寸和交叉尺寸从100到1026。