与分类一样,回归也是预测目标值的过程。回归与分类的不同点在于,前者预测连续性变量,而后者预测离散型变量。
1、用线性回归找到最佳拟合曲线
回归的目的是预测数值型的目标值。针对一个回归方程,求取回归系数的过程就是回归。一旦有了回归系数,再给定输人,做预测就非常容易了。具体的做法是用回归系数乘以输人值,再将结果全部加在一起,就得到了预测值。
假定输入数据存放在矩阵X中,而回归系数存放在向量w中,那么对于给定的数据X1,预测结果将会通过


2、局部加权线性回归
线性回归会出现欠拟合现象,因为它求的是最小均方误差的无偏估计。可以在估计中引入一些偏差,从而降低预测的均方误差。由此引入局部加权线性回归(Locally Weighted Linear Regression,LWLR),该算法中给待测点附近的每个点赋予一定的权重,然后在这个子集上基于最小均方差来进行普通的回归。与kNN一样,此算法每次预测均需事先选取出对应的数据子集。该算法解出的回归系数的形式如下:

其中w是一个矩阵,用来给每个数据点赋予权重。LWLR使用“核”(与支持向量机中的核类似)来对附近的点赋予更高的权重。核的类型可以自由选择,最常用的是高斯核,高斯核对应的权重如下:

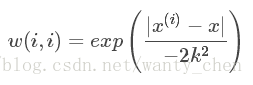
这样就构建了一个只含对角元素的权重矩阵W,并且点x与x(i,i)越近,w(i,i)将会越大,公式中的k需要用户指定,它决定了对附近的点赋予多大的权重。要注意区分权重W和回归系数w,与kNN一样,该加权模型认为样本点距离越近,越可能符合同一个线性模型。
局部加权线性回归存在一个问题,即增加了计算量,因为它对每个点做预测时都必须使用整个数据集。
3、缩减系数来“理解”数据
3.1、岭回归

岭回归最先用来处理特征数多于样本数的情况,现在也用于在估计中加入偏差,从而得到更好的估计。这里引入λ来限制所有w之和,通过引入该惩罚项,能够减少不重要的参数,这在统计学中也叫作缩减(shrinkage)。
可通过预测误差最小化得到λ:数据获取之后,首选抽取一部分数据用于测试,剩余的作为训练集用于训练参数w。训练完毕后在测试集上测试预测性能。通过选取不同的λ来重复上述测试过程,最终得到一个使预测误差最小的λ。
3.2 lasso
在增加如下约束时,普通的最小二乘法回归会得到与岭回归一样的公式:
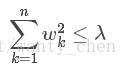
上式限定了所有回归系数的平方和不能大于λ。使用普通的最小二乘法回归在当两个或者多个特征相关时,可能会得到一个很大的正系数和一个很大的负系数。正是此限制条件,使岭回归可避免这个问题。
与岭回归类似,lasso缩减方法也对回归系数做了限定,其约束条件是:
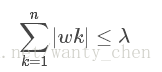
此约束条件使用绝对值取代了平方和。在λλ足够小的时候,一些系数会因此缩减到0。
3.3 前向逐步回归
前向逐步回归算法与lasso效果差不多,属于贪心算法,即每一步都尽可能减少误差。一开始,所有的权重都设为1,然后每步所做的决策是对某个权重增加或减少一个很小的值。该算法的伪代码如下:
数据标准化,使其分布满足0均值和单位方差
在每轮迭代过程中:
设置当前最小误差lowestError为正无穷
对每个特征:
增大或减小:
改变一个系数得到一个新的W
计算新W下的误差
如果误差Error小于当前最小误差lowerError:设置Wbest等于当前的W
将W设置为新的Wbest
逐步线性回归算法的优点在于他可以帮助人们理解现有模型并作出改进。当构建一个模型后,可运行该算法找出重要特征,这样就可以及时停止那些不重要特征的收集。最后,如果用于测试,该算法每100次迭代后就可以构建一个模型,可使用类似于10折交叉验证的方法比较这些模型,最终选择使误差最小的模型。当应用缩减方法(逐步线性回归或岭回归)时,模型也就增加了偏差(bias),与此同时却减小了模型的方差。
4、权衡偏差与误差
训练误差和测试误差均有三部分组成:偏差、测量误差和随机噪声。局部加权线性回归通过引入越来越小的核来不断增大模型的方差。缩减法可以将一些系数缩减成很小的值或直接缩减为0,增大模型偏差。方差是模型之间的差异,而偏差指的是模型预测值与数据之间的差异。偏差与方差折中的概念在机器学习中十分流行。
在回归方程里,求得特征对应的最佳回归系数的方法是最小化误差的平方和。给定输人矩阵X,如果X的逆存在并可以求得的话,回归法都可以直接使用。数据集上计算出的回归方程并不一定意味着它是最佳的,可以便用预测值yHat和原始值y的相关性来度量回归方程的好坏。
