前言
本节继续学习循环神经网络
- GRU
- LSTM
- 双向循环神经网络
1、门控循环单元(GRU)
- 当时间步数较大或者时间步较小时,循环神经⽹络的梯度较容易出现衰减或爆炸
- 裁剪梯度可以应对梯度爆炸,但无法解决梯度衰减
- 门控循环神经网络(gated recurrent neural network)的提出,正是为了更好地捕捉时间序列中时间步距离较大的依赖关系
- 有GRU和LSTM两种
GRU引入重置门和更新门

重置门和更新门
- 重置⻔有助于捕捉时间序列⾥短期的依赖关系
- 更新⻔有助于捕捉时间序列⾥⻓期的依赖关系

候选隐藏状态 - 当前时间步重置⻔的输出与上⼀时间步隐藏状态做按元素乘法(符号为⊙)
- 将按元素乘法的结果与当前时间步的输⼊连结
- 再通过含激活函数tanh的全连接层计算出候选隐藏状态

隐藏状态
- 上一时间步的隐藏状态和当前候选隐藏状态做个组合
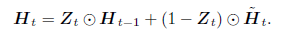
实现
import d2lzh as d2l
from mxnet import nd
from mxnet.gluon import rnn
"""实现GRU"""
# 数据,周杰伦歌词
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
# 模型参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
ctx = d2l.try_gpu()
def get_params():
def _one(shape):
return nd.random.normal(scale=0.01, shape=shape, ctx=ctx)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
nd.zeros(num_hiddens, ctx=ctx))
W_xz, W_hz, b_z = _three() # 更新门参数
W_xr, W_hr, b_r = _three() # 重置门参数
W_xh, W_hh, b_h = _three() # 候选隐藏状态参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = nd.zeros(num_outputs, ctx=ctx)
# 附上梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.attach_grad()
return params
# 模型
def init_gru_state(batch_size, num_hiddens, ctx):
return (nd.zeros(shape=(batch_size, num_hiddens), ctx=ctx), )
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = nd.sigmoid(nd.dot(X, W_xz) + nd.dot(H, W_hz) + b_z)
R = nd.sigmoid(nd.dot(X, W_xr) + nd.dot(H, W_hr) + b_r)
H_tilda = nd.tanh(nd.dot(X, W_xh) + nd.dot(R * H, W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = nd.dot(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
# 训练
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开'] #每过40个迭代周期便根据当前训练的模型创作一段歌词。
d2l.train_and_predict_rnn(gru, get_params, init_gru_state, num_hiddens,
vocab_size, ctx, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)2、长短期记忆(LSTM)
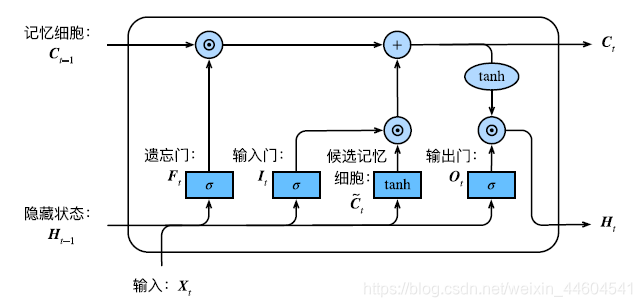
LSTM 中引⼊了3个⻔,即输⼊⻔(input gate)、遗忘⻔(forget gate)和输出⻔(output gate),
以及与隐藏状态形状相同的记忆细胞
三个门
- 遗忘⻔控制上⼀时间步的记忆细胞中的信息是否传递到当前时间步
- 输⼊⻔则控制当前时间步的输⼊通过候选记忆细胞如何流⼊当前时间步的记忆细胞
- 如果遗忘⻔⼀直近似1且输⼊⻔⼀直近似0,过去的记忆细胞将⼀直通过时间保存并传递⾄当前时间步。这设计可以应对循环神经⽹络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较⼤的依赖关系
- 通过输出门来控制从记忆细胞到隐藏状态的信息的流动
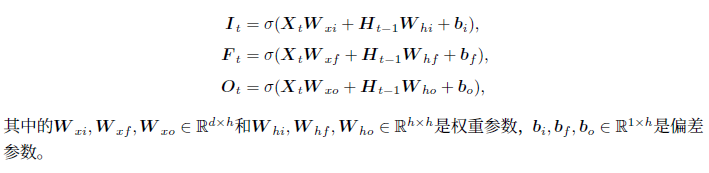
候选记忆细胞
类似于GRU的候选隐藏状态

记忆细胞
类似于GRU的隐藏状态,做个组合
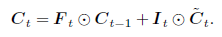
隐藏状态
- tanh函数确保隐藏状态元素值在-1到1之间
- 当输出⻔近似1时,记忆细胞信息将传递到隐藏状态供输出层使⽤
- 当输出⻔近似0时,记忆细胞信息只⾃⼰保留
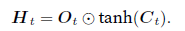
实现
import d2lzh as d2l
from mxnet import nd
from mxnet.gluon import rnn
"""实现LSTM"""
# 数据,周杰伦歌词
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
# 模型参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
ctx = d2l.try_gpu()
def get_params():
def _one(shape):
return nd.random.normal(scale=0.01, shape=shape, ctx=ctx)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
nd.zeros(num_hiddens, ctx=ctx))
W_xi, W_hi, b_i = _three() # 输入门参数
W_xf, W_hf, b_f = _three() # 遗忘门参数
W_xo, W_ho, b_o = _three() # 输出门参数
W_xc, W_hc, b_c = _three() # 候选记忆细胞参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = nd.zeros(num_outputs, ctx=ctx)
# 附上梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.attach_grad()
return params
# 模型
def init_lstm_state(batch_size, num_hiddens, ctx):
return (nd.zeros(shape=(batch_size, num_hiddens), ctx=ctx),
nd.zeros(shape=(batch_size, num_hiddens), ctx=ctx))
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = nd.sigmoid(nd.dot(X, W_xi) + nd.dot(H, W_hi) + b_i)
F = nd.sigmoid(nd.dot(X, W_xf) + nd.dot(H, W_hf) + b_f)
O = nd.sigmoid(nd.dot(X, W_xo) + nd.dot(H, W_ho) + b_o)
C_tilda = nd.tanh(nd.dot(X, W_xc) + nd.dot(H, W_hc) + b_c)
C = F * C + I * C_tilda
H = O * C.tanh()
Y = nd.dot(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H, C)
# 训练
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开'] #每过40个迭代周期便根据当前训练的模型创作一段歌词。
d2l.train_and_predict_rnn(lstm, get_params, init_lstm_state, num_hiddens,
vocab_size, ctx, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)3、双向循环神经网络
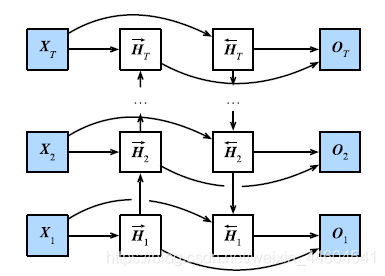
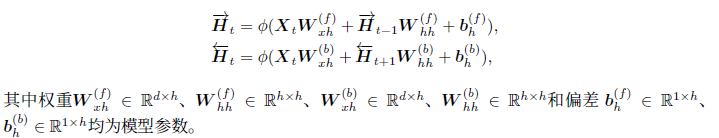
输出层
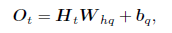
结语
进一步学习了RNN