一、论文简述
1. 第一作者:Xiaoxiao Long
2. 发表年份:2020
3. 发表期刊:ECCV
4. 关键词:多视图深度估计,法线约束,遮挡感知策略,深度学习
5. 探索动机:现有深度学习方法大多未能保留突出的特征3D形状,如拐角,锋利的边缘和面,因为它们只使用深度进行监督,因此它们的损失函数不是用来保存这些结构的。当使用人造物体或规则形状重建室内场景时,这个问题尤其有害。另一个问题是被遮挡区域的深度模糊导致的性能下降,这是大多数现有工作所忽略的。
- However, most of these works fail to preserve prominent features of 3D shapes, such as corners, sharp edges and planes, because they use only depth for supervision and their loss functions are therefore not built to preserve these structures.
- This problem is particularly detrimental when reconstructing indoor scenes with man-made objects or regular shapes. Another problem is the performance degradation caused by the depth ambiguity in the occluded region, which has been ignored by most of the existing works.
6. 工作目标:提出了一种利用单个移动彩色相机进行深度估计的新方法,该方法旨在保留重要的局部特征(边缘、角、高曲率特征)和平面区域。它以一帧视频作为参考图像,以其他帧作为源图像在参考帧中估计深度。
7. 核心思想:采用一种新的遮挡感知策略,将这些初始深度图与遮挡概率图合并成最终的参考视图深度图。
- Our first main contribution is a new structure preserving constraint enforced during training. We therefore propose a new Combined Normal Map (CNM) constraint, attached to local features for both local high-curvature regions and global planar regions. For training our network, we use a differentiable least squares module to compute normals directly from the estimated depth and use the CNM as ground truth in addition to the standard depth loss.
- Our second contribution is a new neural network that combines depth maps predicted with individual source images into one final reference-view depth map, together with an occlusion probability map. It uses a novel occlusion-aware loss function which assigns higher weights to the non-occluded regions. Importantly, this network is trained without any occlusion ground truth.
8. 实验结果:
We experimentally show that our method significantly outperforms the stateof-the-art multi view stereo from monocular video, both quantitatively and qualitatively. Furthermore, we show that our depth estimation algorithm, when integrated into a fusion-based handheld 3D scene scanning approach, enables interactive scanning of man-made scenes and objects in much higher shape quality
9.论文及代码下载:
https://arxiv.org/abs/2004.00845
https://github.com/xxlong0/CNMNet
二、实现过程
1. 总体网络结构
如图所示,将视频中的局部时间窗口中的帧作为输入,视频帧速率为30 fps,以10帧的间隔采样视频帧,假设时间窗口大小为3,将中间帧作为参考图像Iref,相邻的两幅图像作为两幅源图像,应该与参考图像有足够的重叠,的目标是从参考图像的视角计算出精确的深度图。
首先通过可微的单应性操作,形成初始3D代价体。接下来,将代价聚合应用于初始代价体以纠正任何不正确的代价值,然后从聚合代价体中提取初始深度图。除了对初始深度图进行像素级深度监督外,还执行了一种新的局部和全局几何约束,即组合法线图(CNM),用于训练网络以产生更好的结果。然后,通过应用一种新的遮挡感知策略,将来自不同相邻视图的深度预测聚合到一个深度图中以供参考,从而进一步提高深度估计的准确性遮挡概率图。

2. 代价体构建
以往的工作使用图像对提取的特征图构建4D代价体,本文直接使用图像对,避免了在4D代价体上进行大量内存和耗时的3D卷积操作。
3. 用于初始深度预测的DepthNet
从图像对得到代价体Ci后,首先使用神经网络DepthNet对每个Ci进行聚合,通过聚合相邻像素值来纠正不正确的值。为了利用更详细的上下文信息,Ci与源图像Is一起堆叠输入到DepthNet中。接下来,使用2D卷积层从聚合代价体Vi中检索初始深度图Dref i。注意,两个初始深度图,Dref1和Dref2 ,是为参考视图Iref生成的。
用深度监督训练网络。只有深度监督,从估计深度转换的点云不能保留规则特征,如尖锐边缘和平面区域。因此,建议也执行法线约束以进一步改进。使用的不是局部表面法线或全局虚拟法线,而是所谓的组合法线图(combined normal Map, CNM),它以一种自适应的方式结合了局部表面法线和全局平面结构特征。
像素深度损失。使用标准的像素深度图损失如下:

式中,Q为真值深度中所有有效像素的集合,D^(q)为像素q的真值深度值,Di(q)为像素q的初始估计深度值。
组合法线图。为了同时保留场景的局部和全局结构,引入了组合法线图(Combined Normal Map, CNM)作为具有法线约束的监督的真值。为了获得法线图,首先使用PlaneCNN提取平面区域,如墙壁、桌子和地板。然后,将局部表面法线应用于非平面区域,并使用平面区域中表面法线的平均值作为该区域的分配。局部法线图和组合法线图的视觉比较如下。
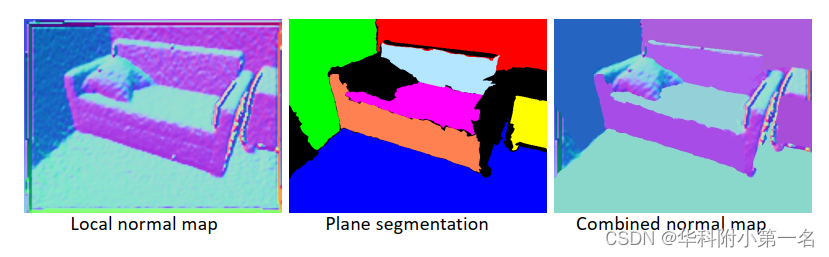
这里的关键观点是使用局部表面法线来捕获高曲率区域中丰富的局部几何特征,并使用平均法线来过滤平面区域表面法线中的噪声,以保留全局结构。通过这种方式,与仅使用局部或全局正常监督相比,CNM显著提高了场景的深度预测和良好3D结构的恢复。
组合法线损失。CNM定义为:

其中,Q为有效的真像素集合,N^(Q)为像素q的组合法线,Ni(q)为像素q对应的三维点的表面正切法线,均归一化为单位向量。为了获得准确的深度图并保留几何特征,将逐像素深度损失和组合法线损失结合在一起来监督网络输出。总损失为:

其中λ为权衡参数,在所有实验中均设为1。
4. 遮挡感知RefineNet
下一步是结合不同图像对预测的参考图像的初始深度图Dref 1和Dref 2得到最终的深度图Df in。设计了一个基于遮挡概率图的遮挡感知网络,即RefineNet。遮挡是指在Iref中无法在Is1或Is2中观察到的区域。
在计算损失时,将较低的权重分配给被遮挡的区域,而将较高的权重分配给未遮挡的区域,这将网络的焦点转移到未遮挡的区域,因为非遮挡区域的深度预测更可靠。此外,网络预测的遮挡概率图可以用来过滤掉不可靠的深度样本,如图所示,这在融合深度图进行三维重建时非常有用。

RefineNet根据两个代价体的平均代价体和两个初始深度图来预测最终深度图和遮挡概率图。RefineNet有一个编码器和两个解码器。第一个解码器基于平均代价体V¯和初始深度图中编码的遮挡信息估计遮挡概率。直观地说,对于非遮挡区域的像素,它的响应最强(峰值)在深度dn为平均代价体V¯的第n层,并且该像素点的Dref 1和Dref 2具有相似的深度值。然而,对于遮挡区域中的一个像素,它在V¯的深度层上具有分散的响应,并且在该像素的初始深度图上具有非常不同的值。另一个解码器使用深度约束和CNM约束预测精细的深度图。为了训练RefineNet,设计了一个新的遮挡感知损失函数,如下所示:

其中Dr(q)为像素q处的改进估计深度,Nr(q)为q对应的三维点的表面法线,D^(q)为q的真值深度,N^(q)为q的组合法线,P(q)为q的遮挡概率值(当q被遮挡时P(q)较高)。权值α设为0.2,β为1。
5. 损失函数
给定预测深度D和真实深度D~,损失可描述为:

其中LSI为尺度不变损失,LVNL为虚拟法向损失[42,43],β为权重因子,设为4。由于有单目深度Dmono和最终深度预测Dt,因此最终损失Lfinal为

6. 限制
首先,该方法的性能依赖于基于全局平面区域分割的CNM的质量。已有的平面分割方法对所有场景的鲁棒性不强。一种可能的解决方案是联合学习分割标签和深度预测。其次,对于基于视频的3D重建任务,可以通过设计端到端网络,直接从视频中生成3D重建,而不必调用使用TSDF融合来整合估计深度图的显式步骤。