Language-based Action Concept Spaces Improve Video Self-Supervised Learning
基于语言的动作概念空间改善视频自我监督学习
备注: 最近研究需要,先将翻译概括内容放这里
论文地址:论文
https://arxiv.org/pdf/2307.10922v3.pdf
摘要
最近的对比语言图像预训练已经导致学习高度可转移和鲁棒的图像表示。 然而,在最少的监督下将这些模型适应视频领域仍然是一个悬而未决的问题。 我们朝这个方向探索了一个简单的步骤,使用语言绑定的自我监督学习将图像 CLIP 模型适应视频领域。 针对时间建模修改的主干在自蒸馏设置下进行训练,训练目标在动作概念空间中运行。 使用相关文本提示从语言编码器中提取的各种动作概念的特征向量构建了这个空间。 一个了解动作及其属性的大型语言模型会生成相关的文本提示。 我们引入了两个训练目标,即概念蒸馏和概念对齐,它们保留了原始表示的通用性,同时加强了动作及其属性之间的关系。 我们的方法提高了三个动作识别基准上的零样本和线性探测性能。
介绍
视频中的动作由单个对象、它们的关系和交互来定义 [1, 2]。 视频自监督学习专注于在没有人类监督的情况下直接从视频内容中发现了解此类动作属性的表示[3]。 特别是在视频的情况下,人工注释可能既昂贵又嘈杂,这种自我监督的方法是无价的。
最近的一种自我监督变体探索了使用松散配对的图像标题对进行学习,从而产生高度可转移且稳健的表示,例如 CLIP [4]。 这些方法获得的零样本性能通常可与完全监督的方法相媲美。 然而,它们在视频领域的对应物[5,6,7,8,9,10,11]却没有表现出相同的通用性。 事实上,一些在视频上训练 CLIP 的方法 [11, 12] 在零样本设置下的表现低于图像 CLIP(见表 2)。 这种行为可归因于标记(或配对字幕)视频数据集的可用性较低和噪声较大[3]。 这激发了对自监督学习(SSL)技术的探索,该技术可以在较少监督的情况下从视频中学习,同时利用现有的图像 CLIP [4] 等表示。 现有最先进的视频 SSL 方法 [13, 14] 从视频中学习高度可转移的表示,但将这些表示与图像 CLIP 表示相结合并不简单。 事实上,尽管像 SVT [13] 这样的方法能够利用图像 SSL 表示 [15] 进行权重初始化以获得更好的性能,但使用图像 CLIP 表示代替权重初始化会导致性能低于图像 CLIP(参见表 4)。 这提出了与 CLIP(如图像表示)兼容的替代视频 SSL 方法的必要性,也是我们的主要动机。
在这项工作中,我们探索自我监督学习技术,在完全自我监督的设置下使图像 CLIP 模型 [4] 适应视频领域,不依赖于任何形式的视频级别标签或字幕。 在这种情况下,自然语言仍然可以提供有关构成动作类别的属性的强烈提示[16, 17]。 我们利用这个想法提出了一种新颖的基于语言的自我监督的学习目标。 遵循标准的自蒸馏和基于多视图的 SSL 公式 [15, 13],我们引入了语言对齐的特征空间、动作概念空间,这是我们的 SSL 目标运作的地方。 大语言模型(LLM)[18]鉴于其广泛的世界知识[19, 20],可以作为为这些空间生成必要的文本概念的理想工具。 我们还引入了适合我们语言的 SSL 目标的正则化,以防止训练期间崩溃。 我们最终的框架被称为基于语言的自我监督(LSS)。
与现有的视频自监督学习方法 [13, 14] 相比,我们提出的 LSS 更好地保留并提高了图像 CLIP 表示的可转移性(参见表 1 和表 4)。 此外,我们的语言对齐学习框架允许对下游任务进行直接零样本操作。 此外,与具有类似零样本功能[5、6、7、8、9、10、11]的视频 CLIP 方法不同,视频 CLIP 方法利用每个视频标签/字幕进行学习,我们提出的 LSS 仅需要视频进行训练。
我们将我们的主要贡献总结如下:
• 自监督学习范式能够保留和提高 CLIP 的优势,例如视频域操作的图像表示
• 视频特定的自监督学习目标,即概念蒸馏和概念对齐,加强动作类别与其视觉属性之间的关系
• 新颖的基于语言的视频自监督学习框架,可在下游动作分类任务上进行零样本操作,无需每个视频标签/字幕进行训练
动作识别数据集的实验显示了我们学习的表示在线性探测、标准零样本和传导零样本设置下的最先进的性能。
Language-based Self-Supervision (LSS)基于语言的自监督
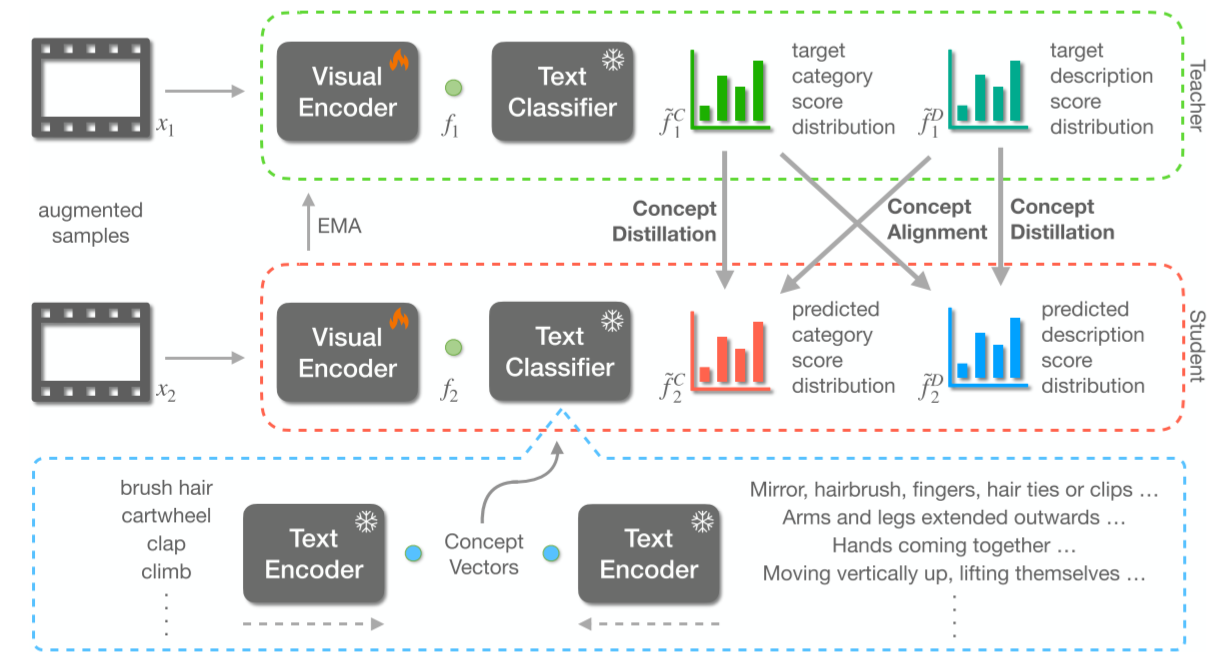
在本节中,我们提出我们的建议:基于语言的自我监督(LSS)。 共享图像语言表示空间(例如 CLIP [4])的通用性和鲁棒性允许使用语言对视觉表示进行有趣的操作。 我们在专注于视频理解的视觉自监督学习的背景下探索此类操作。 自我监督的目标可以在由语言构建的潜在空间内运行,保持所学视觉表征的语言对齐。 这可以更好地解释表示以及零样本推理。 我们讨论我们方法的四个关键组成部分:主干架构、概念蒸馏目标、避免崩溃的修改以及概念对齐目标。
—Backbone Architecture
我们的方法将文本分类器引入基于自蒸馏的 SSL 作品 [15, 13],代替投影仪网络。 给定数据样本 x,令 x1, x2 ∈ R(C,T,H,W) 是使用以下 [13] 的视频特定变换生成的两个增强视图,其中 C = 3, T = 8,H = W = 224分别是通道、时间和空间维度。
Visual Encoder:视觉编码器 θv 处理 xi 以产生特征 fi ∈ R768。 我们利用 CLIP [4] 的预训练图像编码器,使用因子化时空注意力进行时间建模。 选择 CLIP 的视觉变换器变体是为了允许我们分解时空注意力。 特别是,我们使用 ViT-B/16 架构作为图像编码器,其中对于给定的 H = W = 224 和 T = 8 的增强视图,每个变换器块按顺序分别处理 8 个时间标记和 196 个空间标记, 每个token的嵌入维数为R768。 除了来自数据样本的输入标记之外,一个分类标记 [64, 65] 充当网络输出的最终特征向量,即 fi,这是 CLIP 图像编码器所共有的。 该分类标记按照[66]进行适当的膨胀和处理,以适应我们对分解时空注意力的修改。 我们按照[66]对附加时间注意参数进行零初始化,在开始时实现与预训练的 CLIP 图像编码器相同的输出的培训。
文本分类器:受[67]的启发,从 CLIP 文本编码器中提取的一组 n 语言嵌入 θt,用于构造线性层的权重参数(没有偏差项),我们将其称为文本分类器 θc 。 该文本分类器的作用是将视觉特征 fi 投影到由这 n 个嵌入定义的向量空间,产生f~i ∈ Rn。 接下来我们讨论这些向量空间(称为动作概念空间)和文本分类器模块的详细信息。
—Action Concept Spaces
遵循基于指数移动平均 (EMA) 的自蒸馏 [68,15,13] 的自监督学习方法利用投影网络 (MLP) 在更高维的特征空间中运行。 这有望最大限度地减少训练-测试域差距,处理嘈杂的正样本对,并更好地区分细微的特征差异[69]。 围绕这些概念,我们提出了一个替代概念空间,该空间由一组由基于语言的动作概念定义的基本向量组成。 我们基于语言的自我监督目标在这样的概念空间内运作。
概念空间:基于文本编码器功能捕获不同动作类别之间的细微差异的假设,我们假设这些动作之间必要的细微差别将在我们提出的概念空间中更好地捕获。 概念空间的定义参数是它们的基向量 bi。 归一化嵌入(从文本编码器中提取,θt)与动作类别相关的各种自然语言描述(ci)的数量被用作这些基本向量。
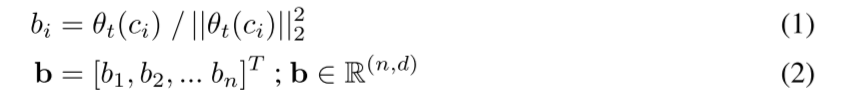
类别概念空间:我们探索了 3 种不同的策略来构建类别概念空间。 基本设置使用来自 Kinetics-400 [70]、UCF-101 [71] 和 HMDB-51 [72] 数据集的动作标签,产生一组 530 个(400 + 101 + 51,忽略重叠)基本向量。 我们的下一个目标是将法学硕士与其行动意识联系起来,发生在后两个策略中。 我们利用 LLM [18] 和视觉 LLM [73] 来提取大量动作类别标签。 当我们在第 4 节中探索使用基于 LMM 的附加动作标签来扩展基本向量集的想法时,包含适度的 530 个类别的基本设置足以提高下游任务性能。
描述 概念空间:该空间是以先前类别概念空间为条件构建的。 对于后者使用的每个动作标签,我们使用大型语言模型 (LLM) 提取 4 个不同的描述和一组与该动作标签相关的视觉特征。 法学硕士的作用是将其世界知识(即对视频、动作及其属性的认识)注入到我们在自我监督学习过程中学到的表征中。 详细地说,我们提示 GPT-3 [18] 使用附录 A 中概述的程序生成此类描述和特征。我们强调 GPT-3 在这里用作包含视频和动作的世界知识的智能 LLM,以便创建自然的 给定操作类别标签的语言描述。 为每个动作标签生成的文本输出由我们的文本编码器处理,为单个动作标签生成多个嵌入。 这些嵌入被平均以产生描述概念空间的相应基向量。 请注意这如何导致两个概念空间之间的公共维度以及空间的基本向量之间的一对一对应关系,这我们利用自我监督目标。
结论
我们引入了一种新颖的基于语言的自监督学习(SSL)视频方法,称为 LSS,能够将强大的语言对齐图像表示(CLIP [4])适应视频领域。 特别是,我们提出了两个基于自蒸馏的 SSL 目标:概念蒸馏和概念对齐。 我们的方法在训练时没有视频级别标签或配对字幕,类似于之前的视频 SSL 工作原理,但保留了图像 CLIP 的语言对齐,从而实现直接零样本推理。 我们通过下游任务的学习表示在线性探测方面展示了最先进的性能。 对于零样本操作,LSS 在标准和传导设置下都表现出强大的性能,这表明视频 SSL 的一个有前途的方向。
局限性、未来的工作和更广泛的影响:LSS 的语言对齐可能主要限于每帧静态信息,因为对齐是从图像 CLIP 派生的 [4]。 LSS 无法区分基于运动的类别,例如“从左到右移动对象”。 此外,虽然在图像级别包含高度区分性和通用信息,但 CLIP 特征缺乏对象级别的空间感知[75]。 我们提出的模型建立在这些表示的基础上,在理解视频中的对象级运动和交互方面本质上受到限制。 然而,本地化感知 CLIP 模型 [75,97,98] 的最新进展为利用以对象为中心或像素级表示来更好地建模此类视频运动模式开辟了途径,从而开辟了有趣的未来方向。 就更广泛的影响而言,我们使用的数据集和预训练模型可能包含偏差,这可能会反映在 LSS 中。 然而,我们减少对人类注释的依赖可能会减少额外的偏见。
可重复性声明:我们构建了一个源自 SVT [13] 和 CLIP [4] 源代码的代码库,并使用 https://github.com/openai 中预先训练的 CLIP 权重。 所有实验均使用公开可用的数据集。 我们的操作描述将与我们的代码库一起公开发布。