转眼间,一年又悄然而逝,时光荏苒,岁月如梭。当回首这段光阴,不禁感叹时间的匆匆,仿佛只是一个眨眼的瞬间,一年的旅程已成为过去,而如今又到了画饼的时刻了 !
基于 Hadoop 生态的大数据技术架构:
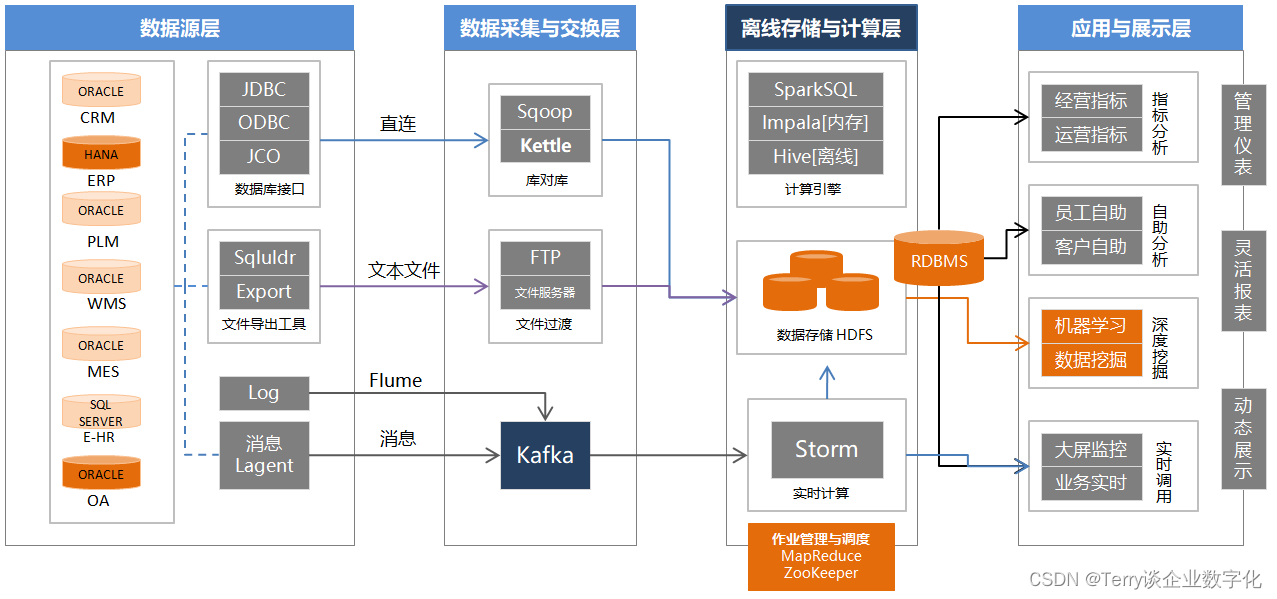
1. 从应用层面看,除了应用在互联网行业以外( 马*说,未来没有一个行业叫互联网行业,所有的传统行业都将是互联网技术的使用行业 ),一般在零售行业使用居多,也要看企业的营收和人效,适不适合搭建这样一套应用体系,比如,之前服务过的一家贸易企业,营收在 20 - 30 亿之间,也在建设大数据,它的技术架构是 :中间库 + BI的展示工具 ,通过ETL工具从业务系统库中把数据抽取到中件库,然后在中间库上架设BI展示工具,为什么是这样的一套架构呢,原因之一是天花板的问题,IT部门的负责人的待遇决定了,只能是中间库 + BI展示工具,也就是说,不可能请一位比自己的待遇还高不少的工程师来搭建大数据技术平台吧 !所以说要建设牛逼的系统,先把IT部门的负责人的待遇提高上去 ,才能请到更牛的人(来解决离线存储与计算层的工作);最后还是要回归应用的价值和老板的满意度上 !
2. 从技术层面看,全面掌握每个技术点,并且应用于实战,一般需要3年以上,一线城市市场价格在 30 - 40 W ,不过当前所看到的消息,都在 开“猿”节流,降本增“笑” ,市场情况堪忧 ?
3. 从技术层面看,每个技术点的概念与原理:
为什么要去描述每个技术点的概念与原理呢,实际上是解释给非技术出生的IT负责人或者是老板来听,体现出项目负责人对方案的的把握程度 ,达到说服立项的效果 !
数据源层面:
数据源层一般是企业的业务系统,一般会有几个领域的视角,ERP负责业务财务一体化,SCM 负责供应链可视化,CRM负责营销社会化,PLM负责产品生命周期的管理...等等。
JDBC(Java Database Connectivity)是一种Java编程语言访问关系型数据库的标准方法。它提供了一组用于执行SQL语句、处理结果集以及管理数据库连接的接口和类。通过JDBC,Java应用程序可以与各种关系型数据库进行通信,包括MySQL、Oracle、Microsoft SQL Server。
ODBC(Open Database Connectivity)是一种开放的数据库连接标准,它允许应用程序通过SQL来访问不同的数据库管理系统(DBMS)。ODBC提供了一个统一的接口,使得应用程序能够使用相同的代码连接和查询不同的数据库。
JCO(Java Connector)通常指的是SAP的Java连接器,它是用于在Java应用程序和SAP系统之间建立联接的技术。
SQLULDR Oracle 数据库中的 SQLLoader。SQLLoader 是 Oracle 提供的用于高效加载大量数据的实用程序
Kafka Agent ,消息代理,Message Broker): Kafka 被称为消息代理,因为它充当了消息的中介,负责接收、存储和转发消息。Kafka 提供了一个分布式的、高可用的消息传递平台,允许生产者将消息发布到特定的主题(Topic),而消费者可以订阅这些主题来接收和处理消息。消息代理负责确保消息在分布式环境中的可靠传递,支持消息的持久化存储,同时提供了水平扩展性,允许在多个节点上部署 Kafka 集群。
Kafka Log 在 Kafka 中,每个主题的消息被持久化存储在一个或多个分区中,形成了一个有序的消息日志。这个消息日志的设计是基于日志结构的,即消息被追加到日志末尾,而不是覆盖或插入。这种日志结构的设计带来了高吞吐量和快速的读写性能。每个分区的消息日志被分割成多个日志段,当一个日志段达到一定的大小或时间限制时,它会被关闭,并创建一个新的日志段。这种机制支持高效的消息追加和数据压缩。
数据采集与交换层:
数据采集交换层,连接数据源层与离线存储与计算层,一般有三种传输方式:
1 对于结构化的数据采集使用库对库的方式;
2 对于文本类型的数据采用FTP文件服务器,过渡到数据存储NDFS计算池中;
3 对于“实时流数据的采集”,一般有可以从5个层面来看 ,网页端、应用程序生成日志文件、网络层面、应用程序生成实时事件和日志数据、数据库层面:
来自网页端的用户行为、点击事件、可利用JavaScript,来实时发送这些事件到 Kafka 主题。这通常涉及在网页端嵌入 Kafka 生产者的逻辑。
来自应用程序生成日志文件,日志文件中包含了系统状态、事件等信息。利用 Logstash、Fluentd 等日志采集工具可以监控日志文件,并将其发送到 Kafka主题。
来自网络层面的网络监听、抓包等方式捕获实时数据流。一些网络设备或工具可以捕获网络流量,并将捕获的数据发送到 Kafka 主题。
来自应用程序层面的应用程序生成实时事件和日志数据,这些数据可以直接由应用程序发布到 Kafka 主题中。Kafka 生产者 API 提供了发送消息到 Kafka 主题的接口,应用程序可以使用这些 API 将实时生成的数据发送到 Kafka。
来自数据库层面, 数据库中的变更数据捕获(Change Data Capture,CDC)是一种常见的数据库层面的技术,用于捕获数据库中发生的变更。一些工具和技术(如Debezium)可以监控数据库中的变更,并将这些变更转换为 Kafka 消息。
离线存储与计算层:
SparkSQL:
Spark SQL是Apache Spark项目中的一个模块,它提供了用于处理结构化数据的编程接口。具体而言,Spark SQL使得可以使用SQL查询语言来查询结构化的数据,这包括使用Spark的DataFrame API和执行SQL查询
Impala:
mpala是Cloudera开发的一种开源的、分布式的SQL查询引擎,用于在Apache Hadoop存储系统中执行交互式SQL查询。Impala的设计目标是提供快速的查询性能,允许用户通过SQL语句直接查询存储在Hadoop分布式文件系统(HDFS)中的数据,而无需将数据移动到其他存储或计算系统
Hive:
Hive是一个建立在Hadoop上的数据仓库工具,提供了类似SQL的查询语言(称为HiveQL)来查询和分析存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。Hive最初由Facebook开发,并且后来成为Apache软件基金会的一个开源项目
Storm:
Storm通常指的是Apache Storm,它是一个开源的、分布式实时计算系统。
Storm被设计用于处理实时流式数据,提供了一个强大的框架,可用于构建实时数据处理应用程序。
MapReduce:
MapReduce是一种用于处理和生成大规模数据集的编程模型和处理框架。它最初由Google提出,并在后来成为Apache Hadoop项目的一部分,成为处理大数据的标准方法之一
Zookeeper:
ZooKeeper是一个分布式的开源协调服务,旨在提供分布式系统中的协作和同步服务
应用与展示:
从售前 售中 售后,来看BI指标体系的搭建
