Hadoop 生态是指围绕 Hadoop 大数据处理平台形成的一系列开源软件和工具,用于支持大规模数据处理、存储、管理、分析和可视化等应用场景。暂时将其核心技术分为9类:
- 数据采集技术框架: Flume、Logstash、FileBeat;Sqoop和Datax; Cannal和Maxwell
- 数据存储技术框架: HDFS、HBase、Kudu、Kafka
- 分布式资源管理框架: YARN、Kubernetes和Mesos
- 数据计算技术框架
- 离线数据计算 : MapReduce、Tez、Spark
- 实时数据计算:Storm、Flink、Spark中的SparkStreaming
- 数据分析技术框架: Hive、Impala、Kylin、Clickhouse、Druid、Doris
- 任务调度技术框架:Azkaban、Ooize、DolphinScheduler
- 大数据底层基础技术框架:Zookeeper
- 数据检索技术框架:Lucene、Solr和Elasticsearch
- 大数据集群安装管理框架:HDP、CDH、CDP
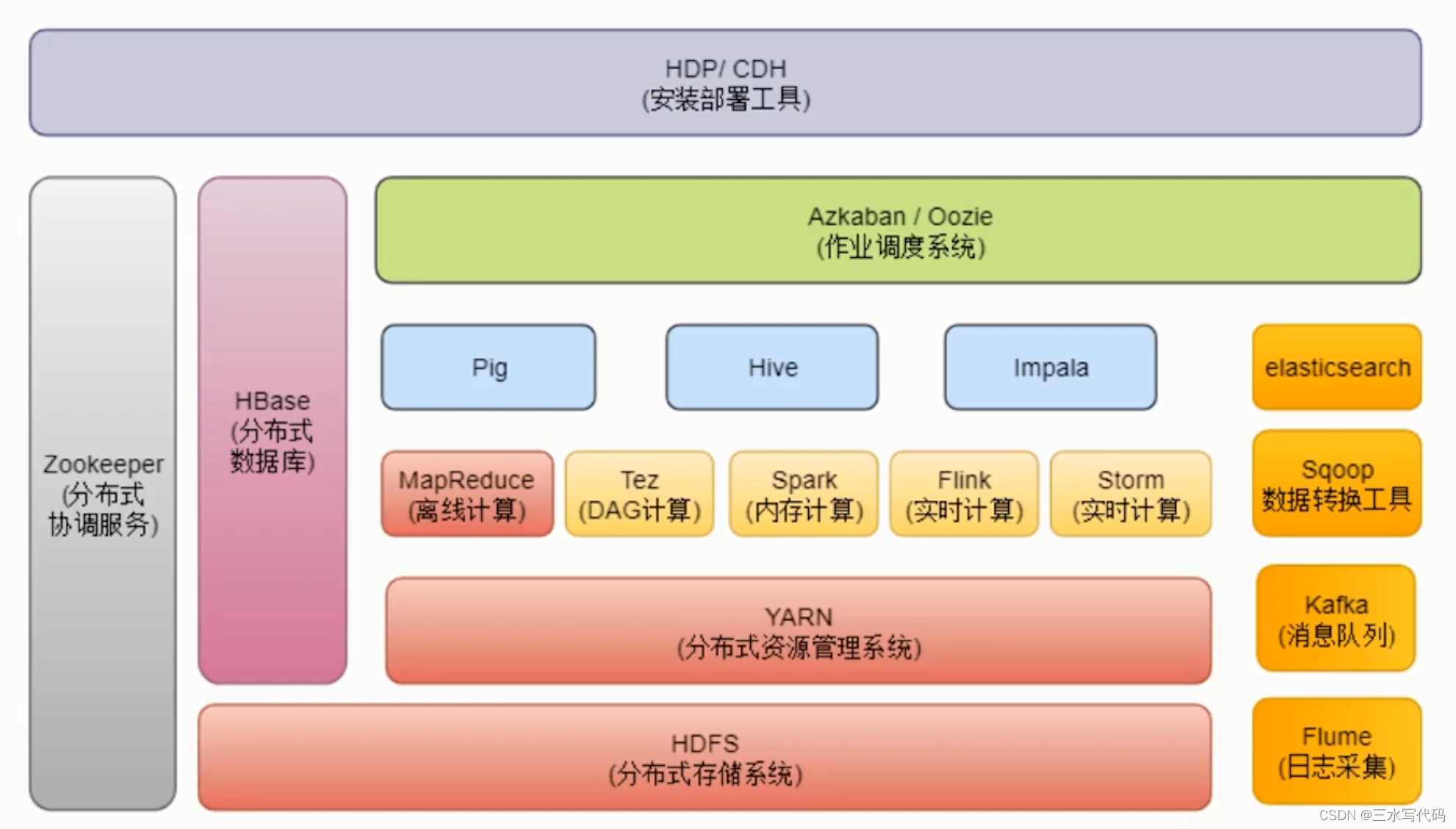 目前常用的Hadoop 生态包括:
目前常用的Hadoop 生态包括:
- HDFS: Hadoop Distributed File System(HDFS)是 Hadoop 的分布式文件系统,用于存储大规模数据集,提供了高容错性、高吞吐量的数据访问。
- MapReduce: Hadoop 的分布式计算框架,用于处理大规模数据集,可实现分布式计算、数据清洗、批处理等任务。
- YARN:Yet Another Resource Negotiator(YARN)是 Hadoop 的资源管理框架,用于将计算和存储分离,实现集群资源的统一管理与调度。
- Hive:Hadoop 中的数据仓库工具,类似于传统的 SQL 数据库,可通过 HiveQL 进行数据存储、查询和分析等操作。
- HBase:Hadoop 中的分布式数据库,基于 HDFS 构建,支持高速查询和随机读写。
- Pig:Pig 是基于 Hadoop 的数据流语言,用于在 Hadoop 平台上执行复杂的数据处理任务。
- Sqoop:Hadoop 的数据导入和导出工具,用于在 Hadoop 平台和关系型数据库之间进行数据传输。
- Flume:Hadoop 的数据收集和汇聚工具,用于将数据从多个源收集到 Hadoop 中进行处理。
- Spark: Spark虽然不是Hadoop的一部分,但与Hadoop生态系统紧密集成。Spark提供了更快的数据处理和分析能力,具备批处理、流处理、机器学习和图计算等功能。
- Zeppelin: Hadoop 的数据分析和可视化工具,将数据存储、查询、分析、展示等功能都聚合在一个交互式的笔记本中。
下满我们简单对比一下这9类技术中各个技术栈的差异。
1、数据采集技术框架
数据分析的前提是先要采集数据,因此数据采集是大数据的基础。
数据采集的技术框架有以下几种:
1.1 Flume、Logstash和FileBeat常用于日志数据实时监控采集
| 对比项 | Flume | logstash | Filebeat |
|---|---|---|---|
| 来源 | Apache | Elastic | Elastic |
| 开发语言 | Java | jruby | go |
| 内存消耗 | 高 | 高 | 低 |
| CPU消耗 | 高 | 高 | 低 |
| 容错性 | 高,内部事务机制 | 高,内部持久化队列 | 无 |
| 负载均衡 | 支持 | 支持 | 支持 |
| 插件 | 丰富的输入输出插件 | 丰富的输入输出插件 | 只支持文件数据采集 |
| 数据过滤 | 提供拦截器 | 强大过滤能力 | 弱有过滤能力 |
| 二次开发 | 对java程序员容易 | 难 | 难 |
1.2 Sqoop和Datax常用于关系型数据库离线数据采集
| 对比项 | Sqoop | DataX |
|---|---|---|
| 来源 | Apache | 阿里 |
| 开发语言 | Java | Java |
| 运行模式 | MapReduce | 单进程多线程 |
| 分布式 | 支持 | 不支持 |
| 执行效率 | 高 | 中 |
| 数据源类型 | 仅支持关系型数据库和Hadoop相关存储系统 | 支持20多种 |
| 扩展性 | 一般 | 高 |
1.3 Cannal和Maxwell常用于关系型数据库实时数据采集
| 对比项 | canal | Maxwell |
|---|---|---|
| 来源 | 阿里 | zendesk |
| 开发语言 | Java | Java |
| 数据格式 | 自由 | json格式 |
| HA | 支持 | 不支持 |
| bootstrap | 不支持 | 支持 |
| 分区 | 支持 | 支持 |
| 随机读 | 支持 | 支持 |
2.数据存储技术框架
数据存储技术框架包括HDFS、HBase、Kudu、Kafka等
- HDFS: 解决海量数据存储问题, 但是不支持数据修改
- HBase: 是一个基于HDFS的分布式NoSQL数据库, 它可以利用HDFS的海量数据存储能力,并支持修改操作。
- Kudu: 介于HDFS和HBase 之间的技术组件, 及支持数据修改,也支持基于SQL的数据分析。也因此它的定位比较尴尬,属于一个折中的方案,实际应用有限。
- kafka: 常用语海量数据的临时缓冲存储,对外提供高吞吐量的读写能力。
3、分布式资源管理框架
企业的服务器资源(内存、CPU等)是有限的,也是固定的。但是,服务器的应用场景却是灵活多变的,随着大数据时代的到来,临时任务的需求量大增,这些任务往往需要大量的服务器资源。因此服务器资源的分配,入股完全依赖运维人员人工对接,太过耗时耗力。因此需要分布式资源管理系统, 常见的有YARN、Kubernetes、Mesos。
- YARN主要应用与大数据领域
- Kubernetes主要应用与云计算领域
- Mesos主要应用与云计算领域
4、数据计算技术框架
数据计算分为离线数据计算和实时数据计算
4.1 离线数据计算
- MapReduce 大数据行业的第一代离线数据计算引擎,主要用于解决大规模数据集的分布式并行计算。它是将计算逻辑抽象成map和reduce两个阶段进行处理。
- Tez计算引擎在大数据生态圈中使用的比较少
- Spark最大的特点是内存计算,任务执行阶段的中间结果全部会放在内存中,不需要读写磁盘,提高了数据的计算性能。且spark提供了很多高阶函数,可以实现各种复杂逻辑的迭代计算,适用于海量数据的快速且复杂计算。
4.2 实时数据计算
- Storm 主要应用与实现实时数据分布式计算,适用于小型、独立的实时项目
- Flink 新一代实时数据分布式计算引擎,计算性能和生态圈都优于Storm,高吞吐低延迟。
- Spark的SparkStreaming组件也可以提供基于秒级的实时数据分布式计算
| 比较项 | storm | SparkStreaming | Flink |
|---|---|---|---|
| 计算模型 | Native | Micro-Batch | Native |
| API类型 | 组合式 | 声明式 | 声明式 |
| 语义级别 | At-Least-Once | Exectly-Once | Exectly-Once |
| 容错机制 | Ack | Checkpoint | checkpoint |
| 状态管理 | 无 | 有 | 有 |
5、数据分析技术框架
数据分析技术框架包括Hive、Impala、Kylin、Clickhouse、Druid、Drois等
Hive、Impala、Kylin 属于离线OLAP数据分析引擎:
- Hive 执行效率一般,但稳定性极高
- Impala 基于内存可以提供很高的执行效率, 但是稳定性一般
- Kylin通过预计算可以提供PB级别数据ms级响应
| 比较项 | Hive | Impala | Kylin |
|---|---|---|---|
| 计算引擎 | MapReduce | 自研app | MapReduce/Spark |
| 计算性能 | 中 | 高 | 高 |
| 稳定性 | 高 | 低 | 高 |
| 数据规模 | TB级别 | TB级别 | TB、PB级别 |
| SQL支持度 | HQL |
兼容HQL | 标准SQL |
Clickhouse、Druid、Doris 属于实时OLAP数据分析引擎:
- Druid支持高并发,SQL支持有限,目前成熟度较高
- Clickhouse并发能力有限,支持非标准SQL。目前成熟度较高
- Doris 支持高并发,支持标准SQL,还处于高速发展阶段
| 比较项 | Druid | ClickHouse | Doris |
|---|---|---|---|
| 查询性能 | 高 | 高 | 高 |
| 高并发 | 高 | 低 | 高 |
| 实时数据插入 | 支持 | 支持 | 支持 |
| 实时数据更新 | 不支持 | 弱 | 中 |
| join 操作 | 有限 | 有限 | 支持 |
| SQL支持 | 有限 | 非标准SQL | 较好 |
| 成熟度 | 高 | 高 | 中 |
| 运维复杂度 | 中 | 高 | 低 |
6、任务调度技术框架:
任务调度技术框架包括Azkaban、ooiz、DolPhinScheduler等。 主要适用于普通定时任务执行,以及包含复杂依赖关系的多级任务进行调度,支持分布式,保证调度系统的性能和稳定性。
| 比较项 | Azkaban | ooiz | DolphinScheduler |
|---|---|---|---|
| 任务类型 | shell脚本及大数据任务 | shell脚本及大数据任务 | shell脚本及大数据任务 |
| 任务配置 | 自定义DSL语法配置 | XML文件配置 | 页面拖拽配置 |
| 任务暂停 | 不支持 | 支持 | 支持 |
| 高可用(HA) | 通过DB支持 | 通过DB支持 | 支持( 多master 多worker ) |
| 多租户 | 不支持 | 不支持 | 支持 |
| 邮件告警 | 支持 | 支持 | 支持 |
| 权限控制 | 粗粒度 | 粗粒度 | 细粒度 |
| 成熟度 | 高 | 高 | 中 |
| 易用性 | 高 | 中 | 高 |
| 所属公司 | Linkedln | Cloudeara | 中国易观 |
7、大数据底层技术框架
大数据底层技术框架只要指zookeeper。
大数据生态圈中的hadoop、HBase、Kafka等技术组件的运行都会用到zookeeper, 它主要提供基础功能,如:命名空间、配置服务等
8、数据检索技术框架
数据检索主流的技术是Elasticseacrch, 其它的还有Lucene、Solr等。
| 对比项 | Lucene | Solr | Elasticsearch |
|---|---|---|---|
| 易用性 | 低 | 高 | 高 |
| 扩展性 | 低 | 中 | 高 |
| 稳定性 | 中 | 高 | 高 |
| 集群运维难度 | 不支持集群 | 高 | 低 |
| 项目集成度 | 高 | 低 | 低 |
| 社区活跃度 | 中 | 中 | 高 |
9、大数据集群安装管理框架
如果企业想从传统的数据处理转型到大数据处理, 首先要做的就是搭建一个稳定可靠的大数据平台。 而一个完整的大数据平台包含数据采集、数据存储、数据计算、数据分析、集群监控等,这些组件要部署到上百台甚至上千台机器中。 如果完全依靠运维人员追个安装,工作量太大,且各个技术栈之间还会有版本匹配的问题。
基于上面的问题, 大数据集群安装管理工具便诞生了。目前常见的包括CDH、HDP、CDP, 他们对大数据组件进行了封装,提供了一体化的大数据平台,可以快速安装大数据组件。
- HDP,全称Hortonworks Data Platform, 基于Hadoop进行了封装,借助Ambari工具提供界面化安装和管理,且集成了大数据的常见组件,可以提供一站式集群管理。完全开源免费,没有商业化服务,但是从3.x版本后就停止了更新。
- CDH,全称Cloudera Distribution Including Apache Hadoop 。借助于Cloudera Manager 工具提供界面化安装和管理,且集成了大部分大数据组件,可以提供一站式集群管理。属于商业化收费大数据平台,6.x版本后停止更新。
- CDP, Cloudera Data Center, 与CDH来自同一家公司,且它的版本号延续了之前的CDH的版本号。 从7.0开始,CDP支持Private Cloud (私有云) 和 Hybrid Cloud (混合云) . CDP将HDP和CDH中比较优秀的组件进行了整合,且增加了一些新的组件。
文章转载自,做个部分修改和补充: 一文看懂大数据生态圈完整知识体系