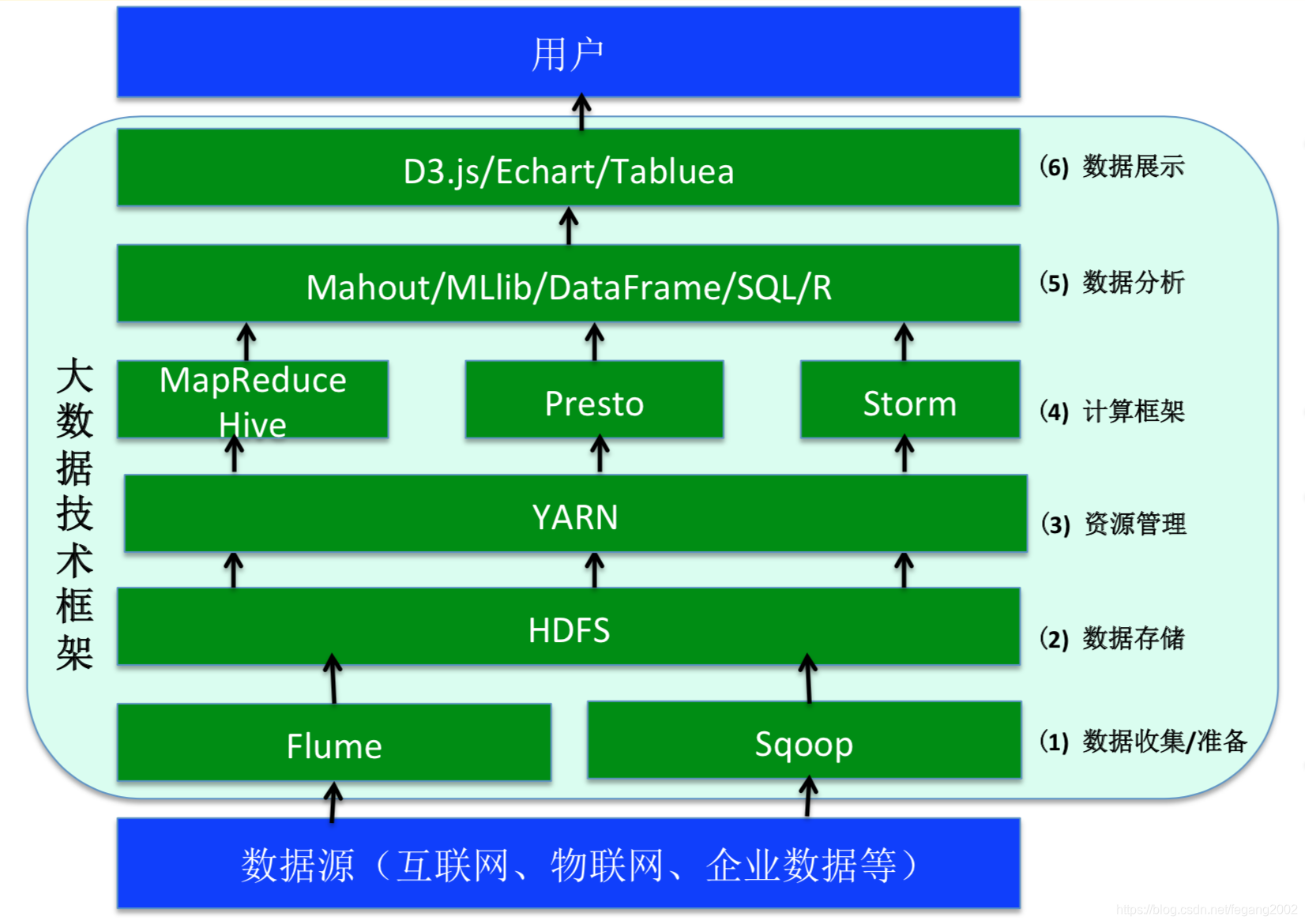
大数据技术框架

Hadoop生态系统
Hadoop是目前得到企业界验证的大数据框架,包括以下特点:
- 源代码开源
- 社区活跃、参与者众多
- 涉及分布式存储和计算的方方面面
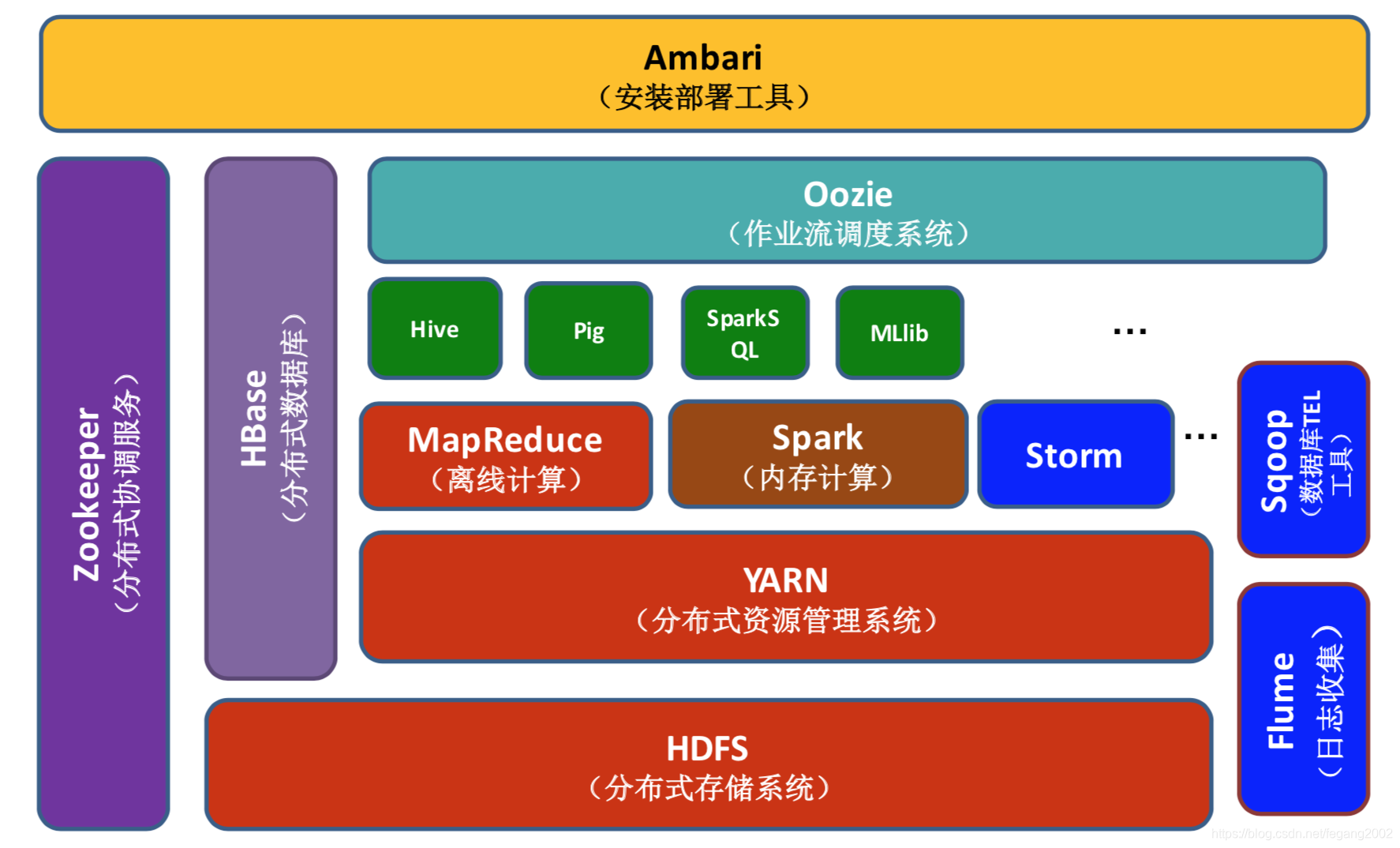
Flume(非结构化数据收集)
Cloudera开源的日志收集系统,用于非结构化数据收集。具有以下特点:
- 分布式
- 高可靠性
- 高容错性
- 易于定制和扩展
Sqoop(结构化数据收集)
Sqoop是SQL to Hadoop的简称,是连接传统关系型数据库和Hadoop的桥梁,包括把关系型数据库的数据导入到Hadoop系统(如HDFS、HBase和Hive中),以及把数据从Hadoop系统抽取并导出到关系型数据库中。利用批处理方式进行数据传输,并且可以利用MapReduce加快数据传输速度。
HDFS(分布式文件系统)
HDFS来源于Google在2003年10月发表的GFS论文,HDFS是GFS的克隆版。HDFS具有以下特点:
- 良好的扩展性,在分布式系统中可以随时添加机器节点,增加存储容量
- 高容错性,因为数据有多副本备份,所以挂掉几台机器后不会丢失数据
- 适合PB级以上海量数据的存储
HDFS将文件切分成等大的数据块,存储到多台机器上,它可以将数据的切分、容错和负载均衡等功能透明化。所以可以将HDFS看成一个容量巨大,具有高容错性的磁盘。HDFS可以做为海量数据的可靠性存储和数据归档。
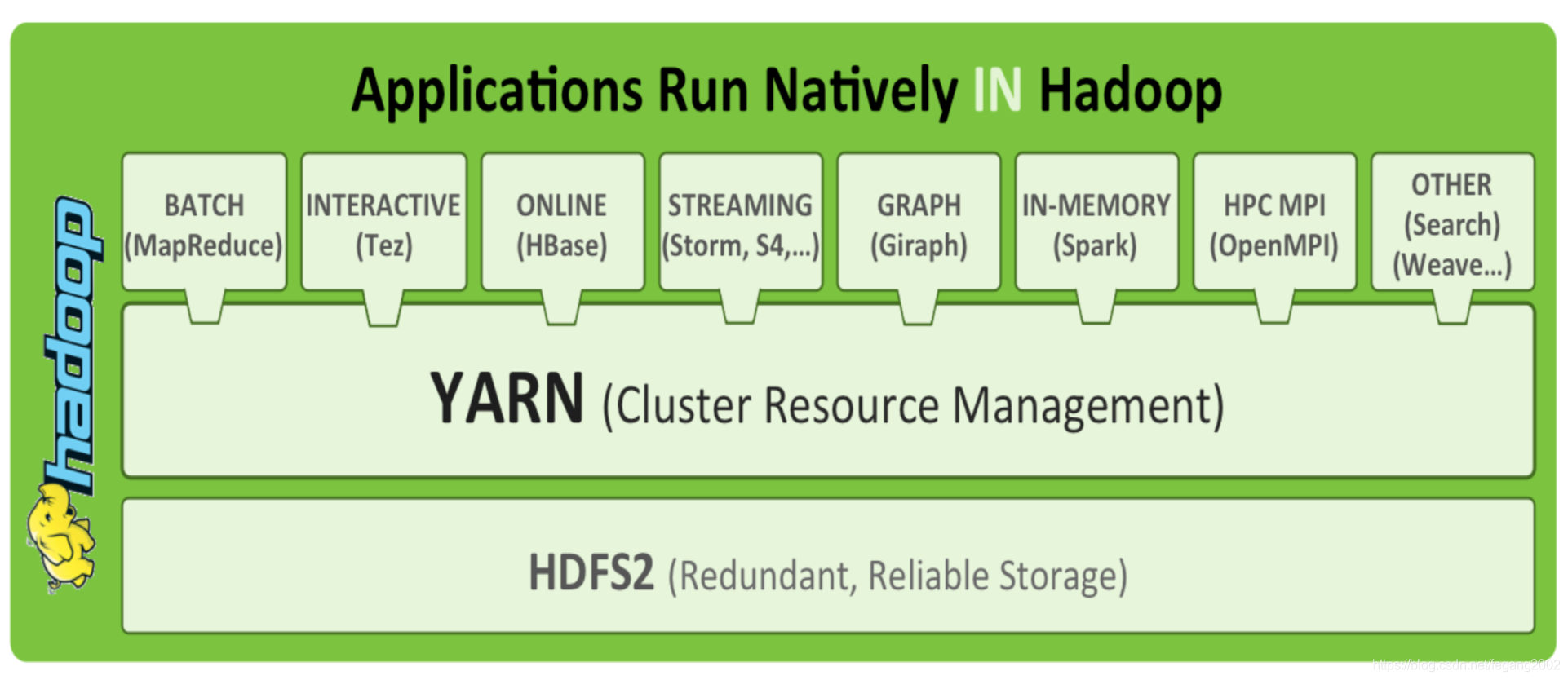
YARN(资源管理系统)
YARN是Hadoop2.0新增的系统,负责集群的资源管理和调度,使得多种计算框架运行在一个集群中,可以看做一个分布式操作系统,类似于WINDOWS或LINUX。
YARN具有以下特点:
- 良好的扩展性和高可用性
- 对多种类型的应用程序进行统一管理和调度
- 自带了多种多用户调度器,适合共享集群环境
YARN上可以运行各种应用。
MapReduce(分布式计算框架)
MapReduce源自于Google发表于2004年12月的MapReduce论文,Hadoop MapReduce是Google MapReduce的克隆版。MapReduce具有以下特点:
- 良好的扩展性
- 高容错性
- 适合PB级以上海量数据的离线处理
MapReduce是分布式计算框架,可以拆成Map和Reduce两个阶段。

Hive(基于MR的数据仓库)
Hive是由Facebook开源,最初用于解决海量结构化的日志数据统计问题,是构建在Hadoop之上的数据仓库,数据计算使用MapReduce,数据存储使用HDFS,Hive定义了一中类似SQL的查询语言HQL,通常用于进行离线数据处理,支持多维度数据分析,可以看做是一个HQL和MapReduce的语言翻译器。Hive可以进行海量结构化数据的离线分析,可以在不编写MapReduce的情况下低成本的进行数据分析,大部分互联网公司都使用Hive进行日志分析。