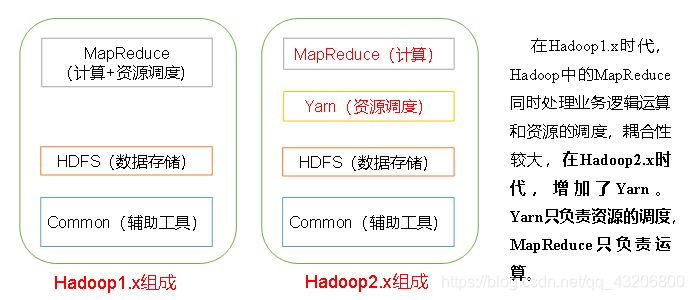
Hadoop的组成:
hadoop 1.x : HDFS(存) + MapReduce(算+资源(内存、CPU、磁盘、网络…)调度)
hadoop 2.x/3.x : HDFS(存) + MapReduce(算) + Yarn(资源调度)
HDFS的架构:
HDFS: Hadoop分布式文件系统, 文件系统是用于对文件进行存储和管理。
分布式可以理解为由多台机器共同构成一个完整的文件系统。
NameNode(nn): 负责管理HDFS中所有文件的元数据信息.
元数据: 用于描述真实数据的数据就是所谓的元数据
例如: 一个真实的数据文件 a.txt,它的元数据为: 文件名 文件大小 文件权限 文件的目录结构 文件对应的块 在哪个dn存
注意: 要想找到HDFS的真实数据必须通过NameNode所维护的元数据才能定位到DataNode中存储的真实数据
DataNode(dn) : 负责管理HDFS的所有的真实文件数据
SecondaryNameNode(2nn): 辅助NameNode工作. 分担NameNode一些工作,减轻NameNode的压力.
注意: 2nn 不是 nn的热备.顶多算nn的秘书.
在一个集群中(非高可用集群): NN(1个) DN(多个) 2NN(1个)
Yarn的架构:
Yarn: 资源调度和管理的框架。 管理和调度的资源就是整个Hadoop集群的资源
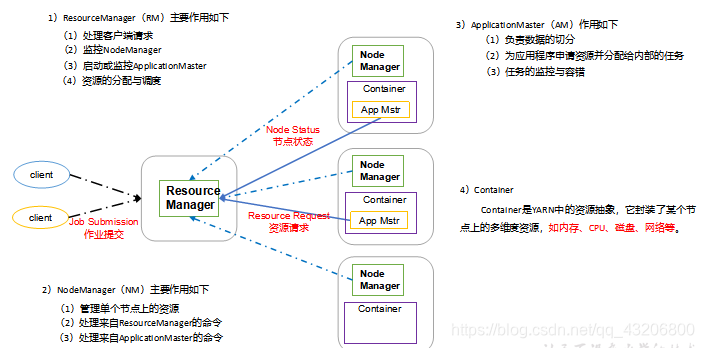
ResourceManager(RM): 是Yarn的大哥. 负责管理和调度整个集群的资源. 负责处理客户端的请求.
负责为Job启动ApplicationMaster。
NodeManager(NM): 是每台机器资源的管理者。实际上只是将本机器的资源对ResourceManager做一个汇报.
对于资源的分配必须听从ResourceManager的指令.
ApplicationMaster(AM):对应每一个Job(MapReduce程序),负责为Job向ResourceMananger去申请资源,
申请到资源以后,负责告诉NodeManager去运行对应的任务. 并且负责监控任务的
运行状态和任务的容错.
Container: 对多维度资源的封装. 方便管理资源及防止资源被侵占.
简单模拟一个任务的提交过程和资源调度过程:
首先有一个Job(MapReduce程序): 包含2个MapTask 和 1 个ReduceTask
1. 客户端提交Job到ResourceManager
2. ResourceManager 为 Job 启动 ApplicationMaster , ApplicationMaster的运行也需要资源,因此ApplicationMaster
启动起来以后,就会有一个Container封装ApplicationMaster运行所用的资源. 因为资源都是在NodeManager上,所以ApplicationMaster是运行在某一个NodeManager上.
3. ApplicationMaster 会根据Job的情况向 ResourceManager申请资源来运行每个Task,当前Job总共有3个Task, 每个Task都是单独运行,因此需要申请3份资源, 也就意味着又有3个Container运行.
4. 所有的资源的分配都是ResourceManager下达指令给NodeManager进行分配的.
5. ApplicationMaster为Job成功申请到资源以后,会告诉NodeManager去运行对应的Task,每个Task可能运行到不同的机器,也有可能多个Task运行到同一个机器. 要看当时集群的资源情况.
6. 当Job的每个Task都开始运行,ApplicationMaster负责监控整个Job的状态. 要负责容错相关的事情.
7. 当Job的每个Task都执行成功后,意味着Job运行完成,此时ApplicationMaster会找ResourceMananger
申请注销自己,所有为当前Job申请的资源得到释放.
申请程序员(申请资源)
<------ NodeManager (运行不同的Task)
客户端(甲方)—> 找你们做项目(提交Job)—> 项目总监(RM) -------> 交给项目经理(AM) -----> 做项目(程序员负责不同的模块) ---->项目完成(项目经理找项目总监归还程序员)
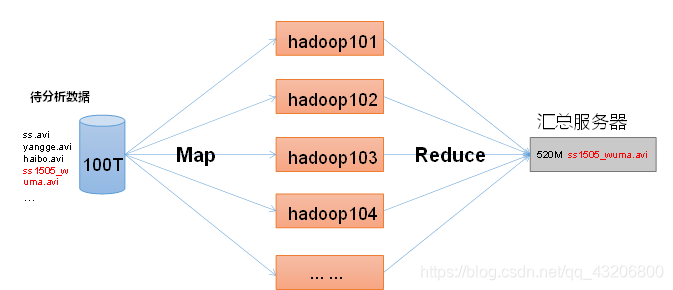
MapReduce的架构:
Map阶段(MapTask): 负责将数据分到多台机器中,进行并行计算
Reduce阶段(ReduceTask): 负责将多台机器在map阶段中计算出来的数据,进行整体的汇总.
大数据生态平台
