一、Hadoop的优势
(1)高可靠性:
因为Hadoop假设计算元素和存储会出现故障,它维护多个工作数据副本,故障时可以对失败的节点重新分布处理。
(2)高可扩展性
在集群间分配任务数据,可方便的扩展数以千计的节点。
(3)高效性
在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
(4)高容错性
自动保存多份副本数据,并且能够自动将失败的任务重新分配。
二、Hadoop组成
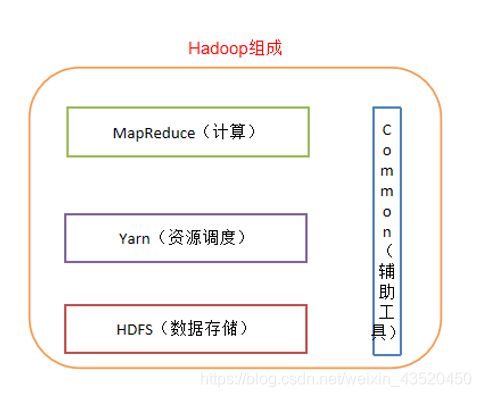
(1)Hadoop HDFS:
一个高可靠、高吞吐量的分布式文件系统
(2)Hadoop MapReduce:
一个分布式的离线并行计算框架
(3)Hadoop YARN:
作业调度与集群资源管理的框架
(4)Hadoop Common:
支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)
三、HDFS 架构概述
(1)Namenode:
存储元数据
(2)Datanode:
存储数据的节点,会对数据进行校验
(3)Secondarynamenode:
监控namenode 的元数据,每隔一定的时间进行元数据的合并
四、YARN架构概述
(1) ResourceManager(rm):
处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度
(2)NodeManager(nm):
单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令
(3)ApplicationMaster:
数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错
(4)Container:
对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息
五、MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
