1.论文信息
1.1论文标题:Visual Saliency Transformer (VST)
Nian Liu, Ni Zhang, Kaiyuan Wan, Junwei Han, and Ling Shao
1.2 Github源代码地址:https://github.com/nnizhang/VST
1.3论文下载链接:http://openaccess.thecvf.com/content/ICCV2021/papers/Liu_Visual_Saliency_Transformer_ICCV_2021_paper.pdf
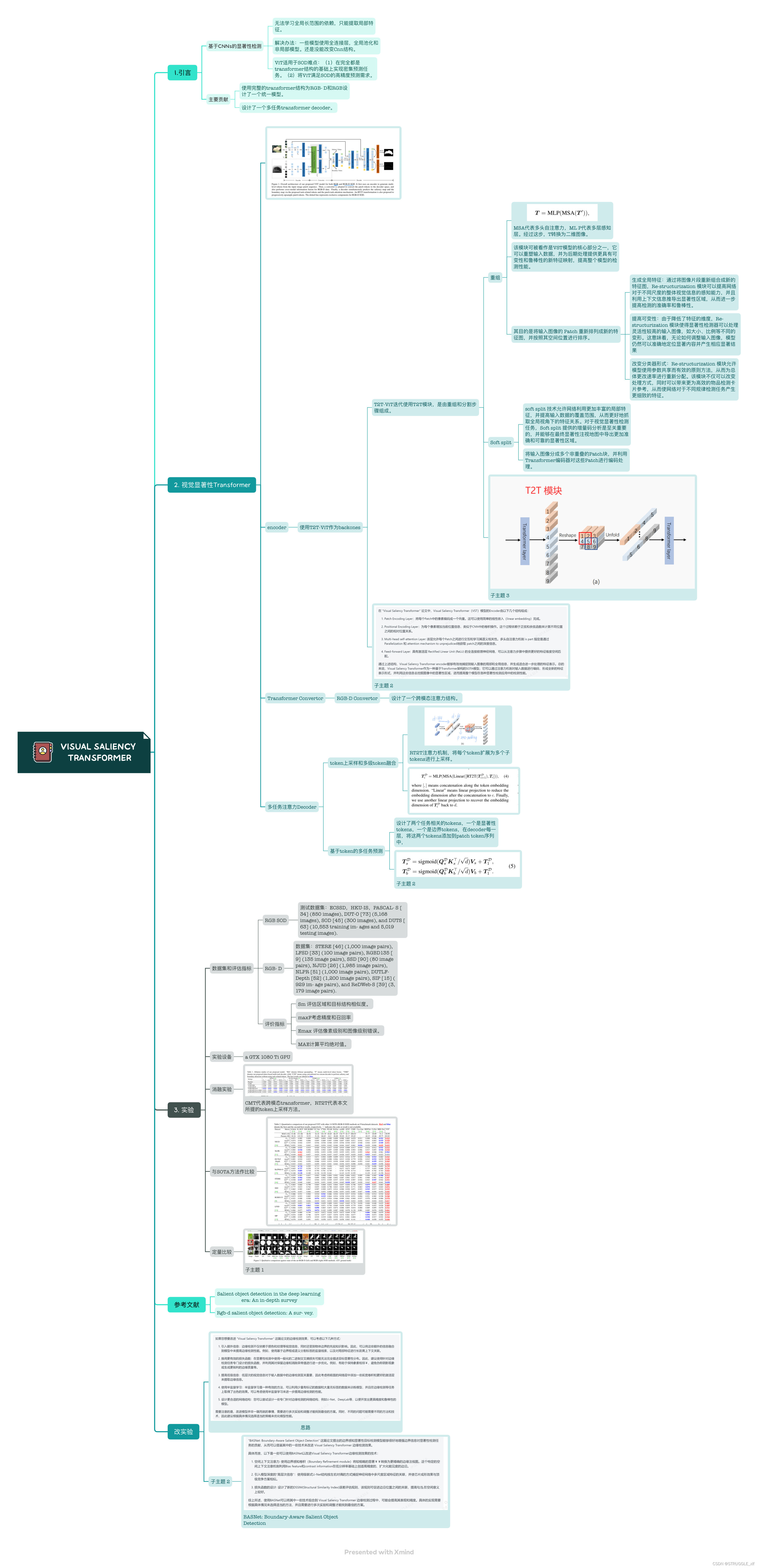
2.论文解读
Xmind源文件下载:Visual Saliency Transformer (VST)
3.源代码实现
3.1云服务器平台
启智社区:
您的好友正在邀请您加入OpenI启智AI协作平台,畅享充沛的普惠算力资源(GPU/NPU/GCU/GPGPU/MLU)。现在使用国产算力参与打榜任务,奖金+算力积分+礼品盲盒等你来拿哦~
注册地址:https://openi.pcl.ac.cn/user/sign_up?sharedUser=STRUGGLE
推荐人:STRUGGLE
这里可以每天登录领取积分,免费训练模型。
3.2 训练步骤
在启智社区新创建一个项目,把源代码上传到启智社区,可以使用Git工具进行远程仓库同步。
将代码上传完成之后,上传对应的模型和数据集。然后就可以先进行调试,在项目中创建一个调试环境,根据自己的需要选择对应的镜像,我的调试环境如下:
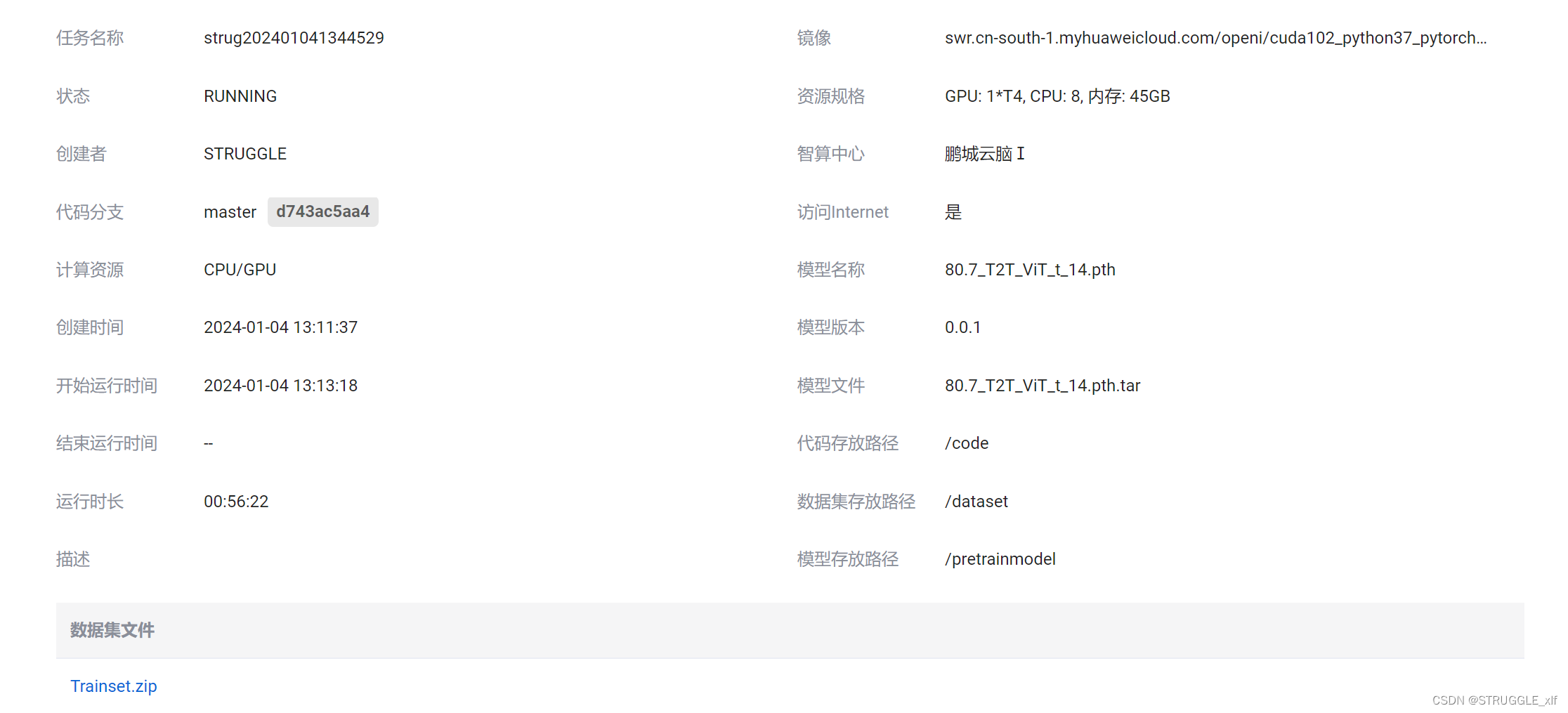
因为调试任务只能维持四个小时,所以我们可以先在调试环境中配置好实验所需要的依赖包,测试一下能否顺利训练,然后将调试的镜像提交一下,如下图:
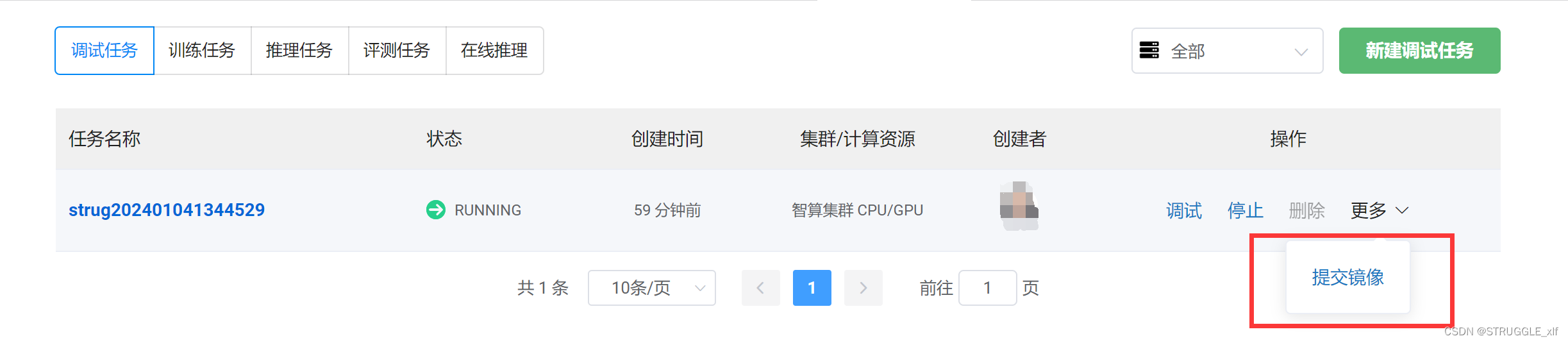
提交好的镜像,我们可以在后续创建训练任务的时候选中这个镜像,这样我们就可以直接开始训练模型了。需要注意到是,我们的源代码是放在
/code路径,数据集放在 /dataset,模型存放路径 /pretrainmodel,在训练代码中要注意修改路径如下:

调试好了代码之后,可以创建训练任务,这里要注意训练任务中,预训练权重的默认参数是–ckpt_url,所以要在train_test_eval.py中修改:
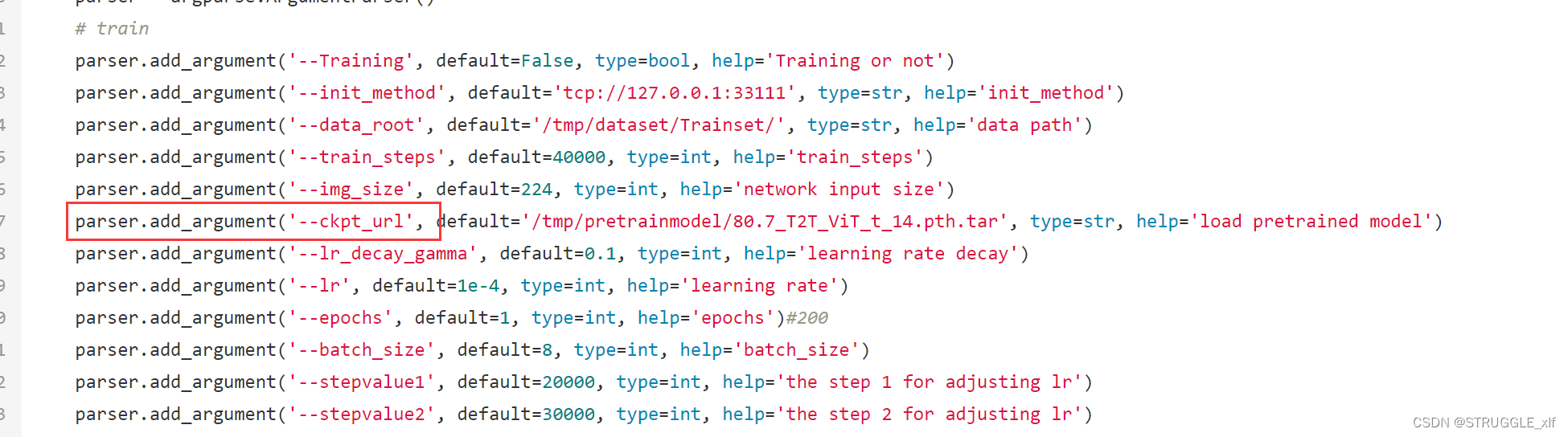
并在其他使用到这个参数的地方修改:
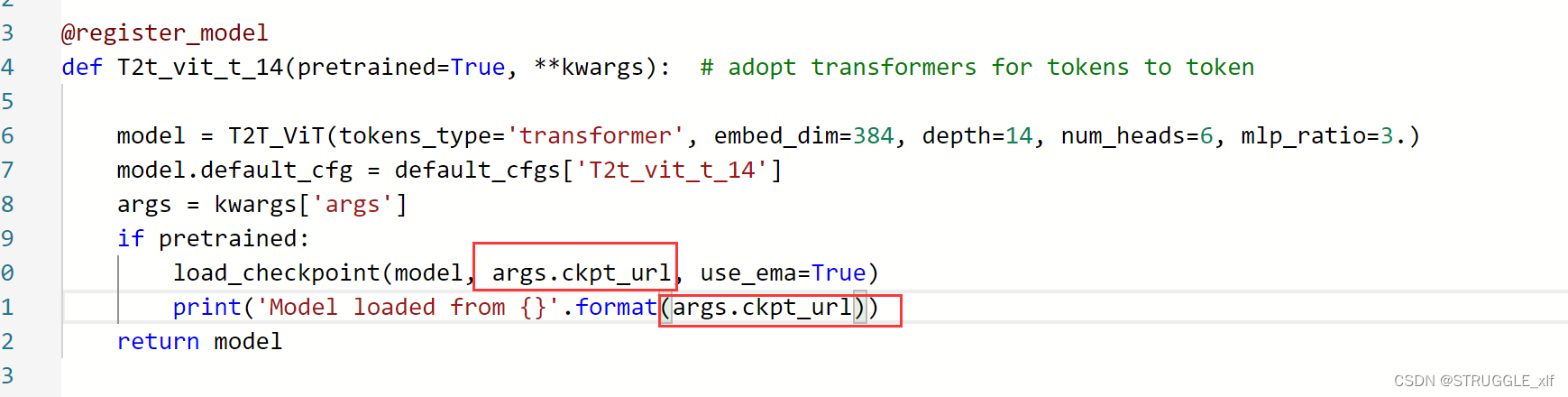
在保存模型的时候也要注意,直接保存在/tmp/output/ 文件夹下,不要以args参数的形式,如下:

4.源代码解读
论文的核心是ImageDepthNet.py文件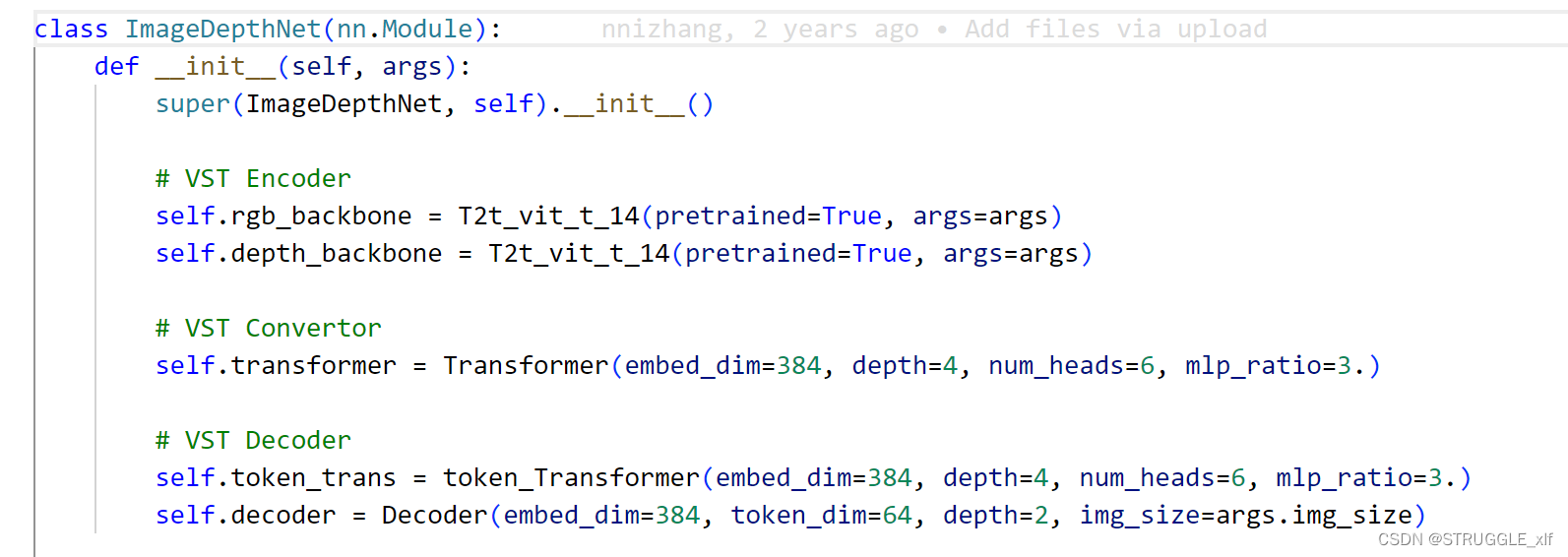
模型结构定义: 模型包括三个主要部分,分别是 VST Encoder、VST Convertor 和 VST Decoder。
VST Encoder: 使用 T2t_vit_t_14 模型(Transformer-based Vision Transformer with token size 14)分别对输入的图像(image_Input)和深度信息(depth_Input)进行编码,提取不同层次的特征表示(rgb_fea_1_16、rgb_fea_1_8、rgb_fea_1_4、depth_fea_1_16)。
VST Convertor: 使用 Transformer 模块将编码后的图像和深度特征进行转换,得到新的特征表示(rgb_fea_1_16、depth_fea_1_16)。
VST Decoder: 使用 Token-based Transformer 模块和 Decoder 模块对转换后的特征进行解码,得到最终的输出(outputs)。
下面分别介绍这三个部分
4.1VST Encoder

Encoder中使用T2t_vit_t_14作为backbone提取RGB和Depth图像进行编码,源代码如下:

4.2 VST Convertor

这里调用Transformer.py文件的Transformer类。
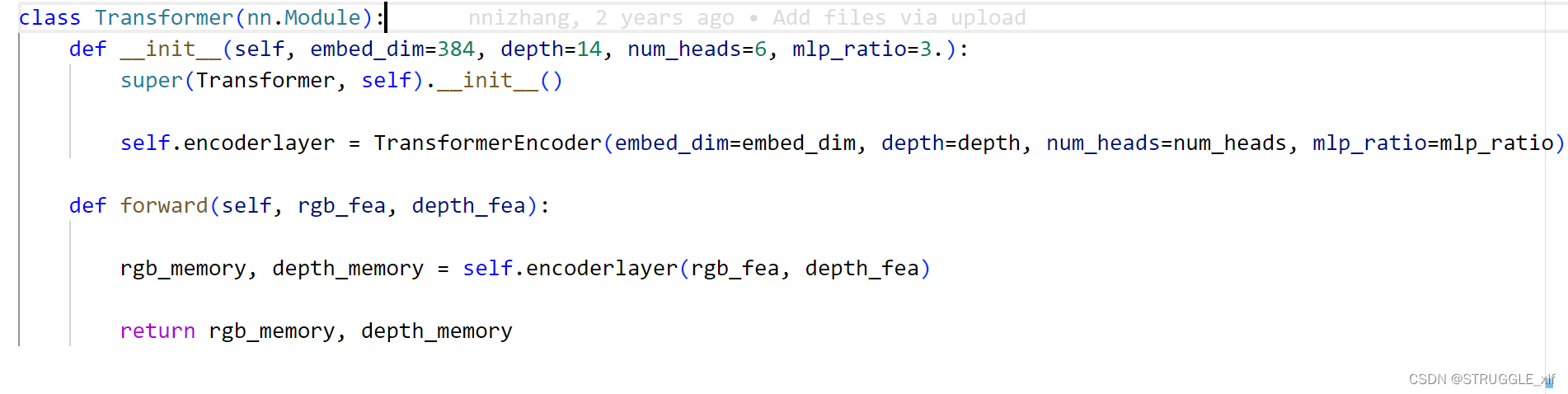
该模块的主要作用是通过调用内部的 TransformerEncoder 进行特征的编码。
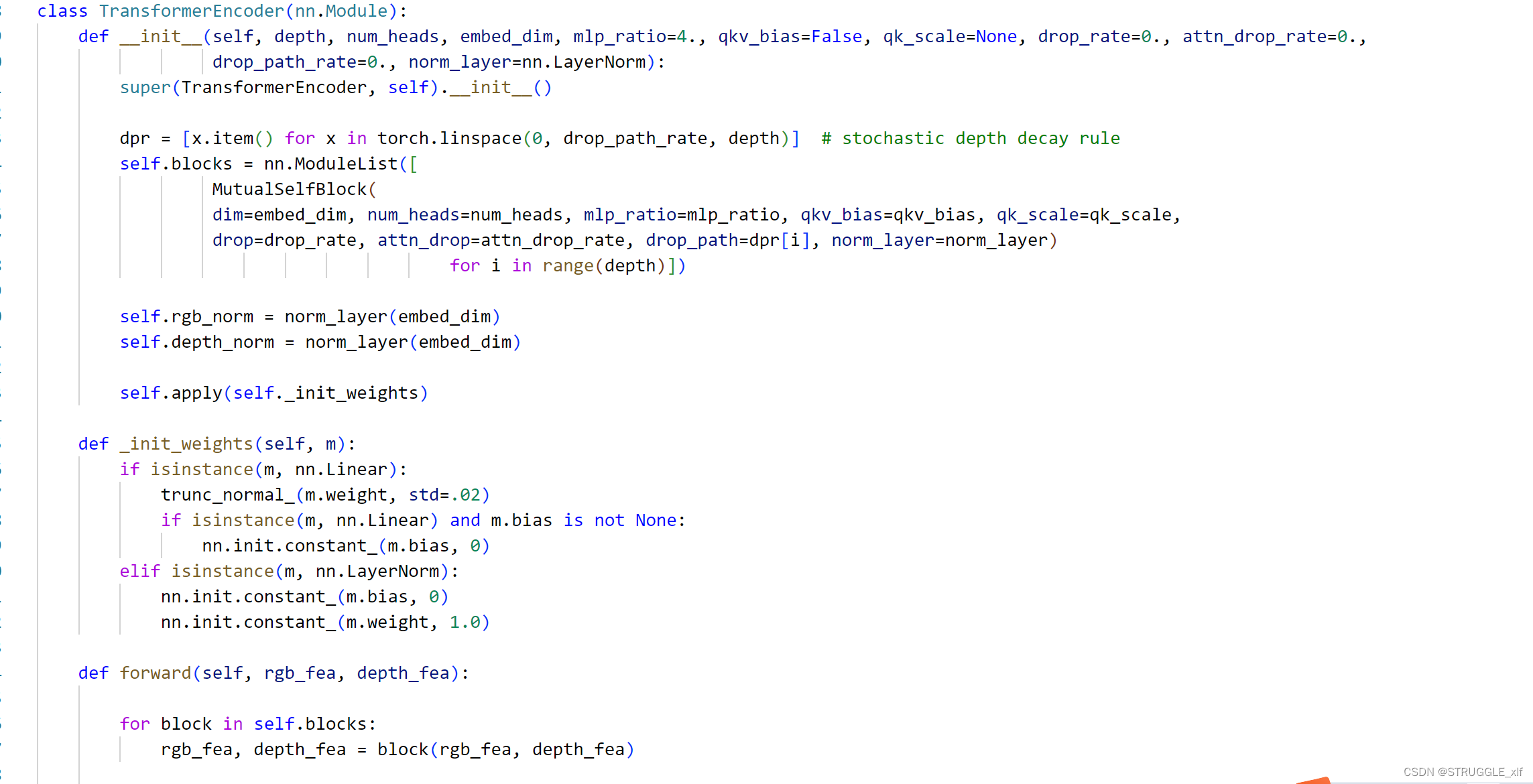
该类主要作用是通过多个互相交互的 Transformer 模块对输入的 RGB 特征和深度特征进行编码。
4.3 VST Decoder

这里先使用self.token_trans 对输入特征进行处理,包括自注意力机制(Attention)、多层感知机(MLP)等操作。代码如下:

该模块通过学习输入特征的非线性映射,生成了经过自注意力机制处理的特征表示。
接着使用Decoder解码模块:
首先是初始化函数:
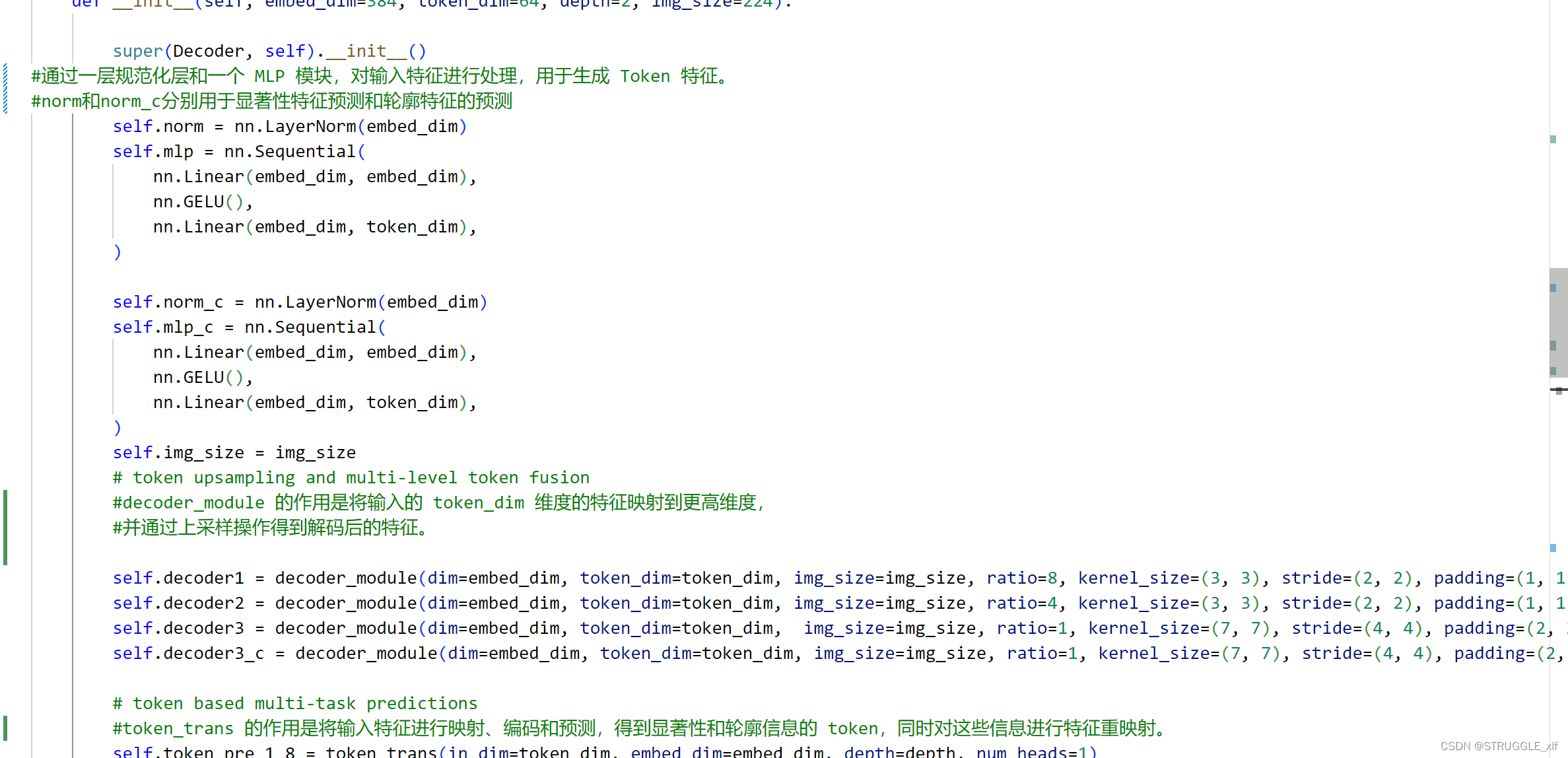
接下来是前向传播处理逻辑:
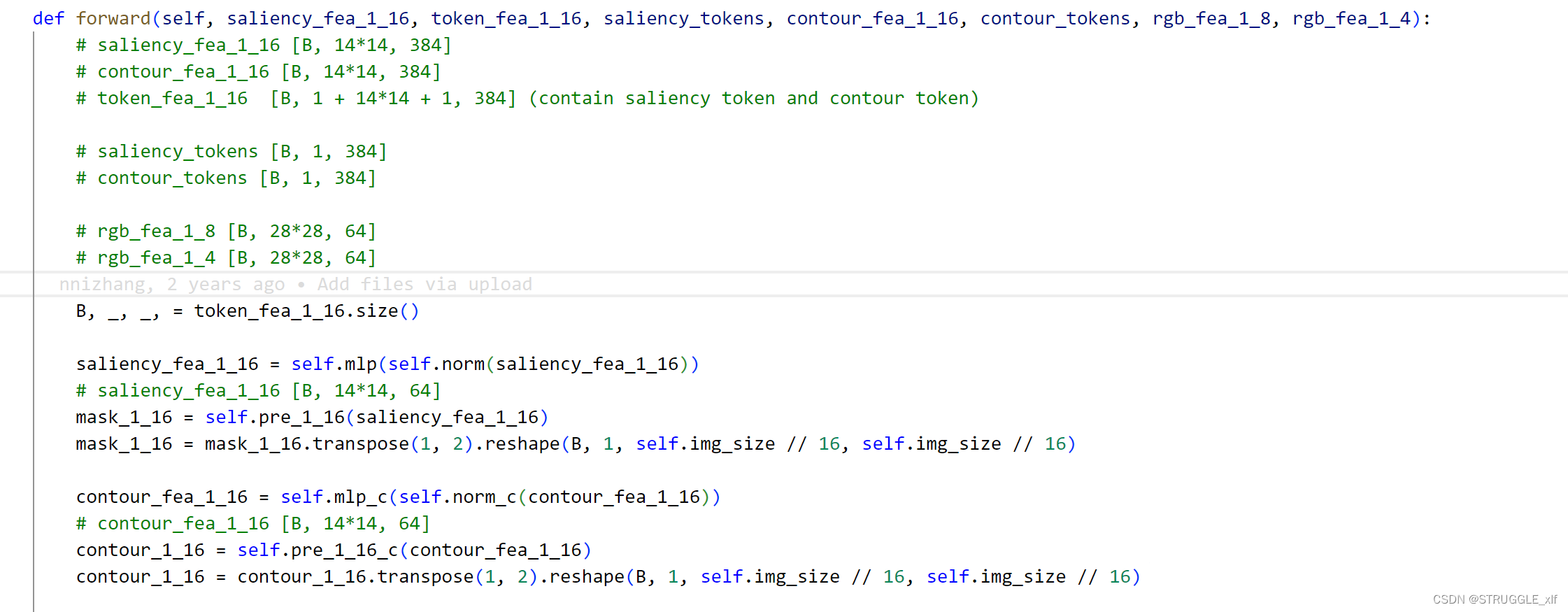
这段代码描述了一个类的前向传播逻辑,该类的作用是进行一系列的特征处理、解码和预测,最终生成不同分辨率下的显著性和轮廓图。以下是每个步骤的解释:
-
特征处理:
saliency_fea_1_16和contour_fea_1_16是对输入的显著性和轮廓特征进行处理后的结果。token_fea_1_16包含显著性 token 和轮廓 token,以及对应的特征。rgb_fea_1_8和rgb_fea_1_4是高层级特征,用于解码低层级特征。
-
显著性特征处理:
- 对
saliency_fea_1_16进行处理,通过线性层和激活函数 (mlp)。 - 针对处理后的
saliency_fea_1_16,通过线性层 (pre_1_16) 得到显著性图mask_1_16。
- 对
-
轮廓特征处理:
- 对
contour_fea_1_16进行处理,通过线性层和激活函数 (mlp_c)。 - 针对处理后的
contour_fea_1_16,通过线性层 (pre_1_16_c) 得到轮廓图contour_1_16。
- 对
-
1/16 到 1/8 解码:
- 使用
decoder1模块对token_fea_1_16进行解码,得到fea_1_8。 - 对
fea_1_8进行显著性、轮廓和 token 预测。
- 使用
-
1/8 到 1/4 解码:
- 使用
decoder2模块对token_fea_1_8进行解码,得到fea_1_4。 - 对
fea_1_4进行显著性、轮廓和 token 预测。
- 使用
-
1/4 到 1 解码:
- 使用
decoder3模块对saliency_fea_1_4进行解码,得到saliency_fea_1_1。 - 使用
decoder3_c模块对contour_fea_1_4进行解码,得到contour_fea_1_1。 - 对
saliency_fea_1_1和contour_fea_1_1进行预测,得到分辨率为 1 的显著性图和轮廓图。
- 使用
最终,返回了显著性图和轮廓图在不同分辨率下的预测结果。