The learning of "Visual Saliency Detection Based on Multiscale Deep CNN Features" (G.-B. Li, Y.-Z. Yu. IEEE Transactions on Image Processing, Nov, 2016, pp. 5012-5024)
The saliency map is obtained by a random forest regressor using the multiscale high level features and the low level features of artificial selection.
1 Model overview
-
- Segment image using graph-based segmentation, and modify the area according to the bounding box idea.
- High-level feature vector is extracted at three different scales from three CNNs (Alexnet) fed into the two fully connected layers.
- Low-level feature (color and texture) vector is extracted by comparing with boundary background and entire image.
-
Training a random forest regressor over the hybrid feature vector to get initial saliency map. - Use energy minimization to improve spatial coherence so that get final saliency image.
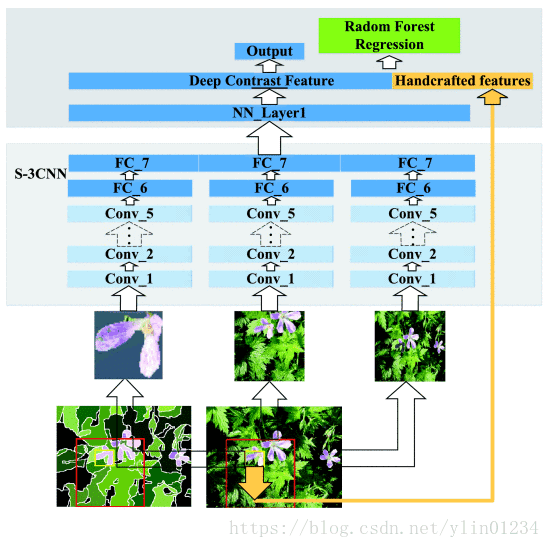
In fact, this paper is the combination of “Visual saliency detection based on multiscale deep features” and “Deep contrast learning for salient object detection”. The former produces high-level features, the latter provides the method for obtaining low-level features and improving saliency maps. The novel work of this article is to train random forests and select low-level features.
2 Highlights
2.1 Bounding box
 |
The bounding box method returns the minimum enclosing rectangle whose shape and its sub shape are closely enclosed. This paper uses this method to correct the problem of uneven shape after SLIC segmentation. The feature of the filling is the average feature of the training set.
2.2 Multiscale problem
Apply the graph-based segmentation algorithm to generate 15 levels of segmentations using different parameter settings. Then a sub saliency map is generated by multi-resolution on each segmentation graph. Finally, fuse 15 saliency maps to get initial saliency map.
3 Problem
In this paper, the number of regions divided is 20-300, but when the number of segmentation is too small, the high-level sub feature B and C is likely to be the same, which results in the duplication of computation.
The number of regions that cannot be split is too small, or, when a single area has been very large, the high-level features B or C can be selected only one for computation.