1)全连接神经网络(FC)
全连接神经网络是一种最基本的神经网络结构,英文为Full Connection,所以一般简称FC。
FC的准则很简单:神经网络中除输入层之外的每个节点都和上一层的所有节点有连接。例如下面这个网络结构就是典型的全连接:

神经网络的第一层为输入层,最后一层为输出层,中间所有的层都为隐藏层。在计算神经网络层数的时候,一般不把输入层算做在内,所以上面这个神经网络为2层。其中输入层有3个神经元,隐层有4个神经元,输出层有2个神经元。
更多关于神经网络的基本介绍,请参考此链接:https://www.zybuluo.com/hanbingtao/note/476663
2)三层FC实现MNIST手写数字分类
我们定义了三个不层次的神经网络模型:简单的FC,加激活函数的FC,加激活函数和批标准化的FC。
# !/usr/bin/python
# coding: utf8
# @Time : 2018-08-04 19:09
# @Author : Liam
# @Email : [email protected]
# @Software: PyCharm
# .::::.
# .::::::::.
# :::::::::::
# ..:::::::::::'
# '::::::::::::'
# .::::::::::
# '::::::::::::::..
# ..::::::::::::.
# ``::::::::::::::::
# ::::``:::::::::' .:::.
# ::::' ':::::' .::::::::.
# .::::' :::: .:::::::'::::.
# .:::' ::::: .:::::::::' ':::::.
# .::' :::::.:::::::::' ':::::.
# .::' ::::::::::::::' ``::::.
# ...::: ::::::::::::' ``::.
# ```` ':. ':::::::::' ::::..
# '.:::::' ':'````..
# 美女保佑 永无BUG
from torch import nn
class simpleNet(nn.Module):
"""
定义了一个简单的三层全连接神经网络,每一层都是线性的
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(simpleNet, self).__init__()
self.layer1 = nn.Linear(in_dim, n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1, n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
class Activation_Net(nn.Module):
"""
在上面的simpleNet的基础上,在每层的输出部分添加了激活函数
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Activation_Net, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
"""
这里的Sequential()函数的功能是将网络的层组合到一起。
"""
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
class Batch_Net(nn.Module):
"""
在上面的Activation_Net的基础上,增加了一个加快收敛速度的方法——批标准化
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Batch_Net, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.BatchNorm1d(n_hidden_1), nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.BatchNorm1d(n_hidden_2), nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
接下来导入一些必要的包,除了之前常用的torch, nn, Variable之外,还导入了DataLoader用于加载数据,使用了torchvision进行图片的预处理,然后,导入了上面所定义的三个模型。
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 之前所定义的神经网络模型
import net然后定义一些超参数。
# 定义一些超参数
batch_size = 64
learning_rate = 0.02
num_epoches = 20在torchvision中提供了transforms用于帮我们对图片进行预处理和标准化。其中我们需要用到的有两个:ToTensor()和Normalize()。前者用于将图片转换成Tensor格式的数据,并且进行了标准化处理。后者用均值和标准偏差对张量图像进行归一化:给定均值: (M1,...,Mn) 和标准差: (S1,..,Sn) 用于 n 个通道, 该变换将标准化输入 torch.*Tensor 的每一个通道。其处理公式为:
而Compose函数可以将上述两个操作合并到一起执行。
# 数据预处理。transforms.ToTensor()将图片转换成PyTorch中处理的对象Tensor,并且进行标准化(数据在0~1之间)
# transforms.Normalize()做归一化。它进行了减均值,再除以标准差。两个参数分别是均值和标准差
# transforms.Compose()函数则是将各种预处理的操作组合到了一起
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])])PyTorch提供了一些常用数据集,所以我们定义数据集下载器如下:
# 数据集的下载器
train_dataset = datasets.MNIST(
root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)然后选择相应的神经网路模型来进行训练和测试,我们这里定义的神经网络输入层为28*28,因为我们处理过的图片像素为28*28,两个隐层分别为300和100,输出层为10,因为我们识别0~9十个数字,需要分为十类。损失函数和优化器这里采用了交叉熵和梯度下降。
# 选择模型
model = net.simpleNet(28 * 28, 300, 100, 10)
# model = net.Activation_Net(28 * 28, 300, 100, 10)
# model = net.Batch_Net(28 * 28, 300, 100, 10)
if torch.cuda.is_available():
model = model.cuda()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)下面是训练阶段,和之前大同小异。
# 训练模型
epoch = 0
for data in train_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
print_loss = loss.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
if epoch%50 == 0:
print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))然后测试一下我们的模型:
# 模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item()*label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))之前我们定义了三个不同层次的神经网络,选择不同的网络进行训练和测试,都可以看到类似于下面这样的程序执行结果:
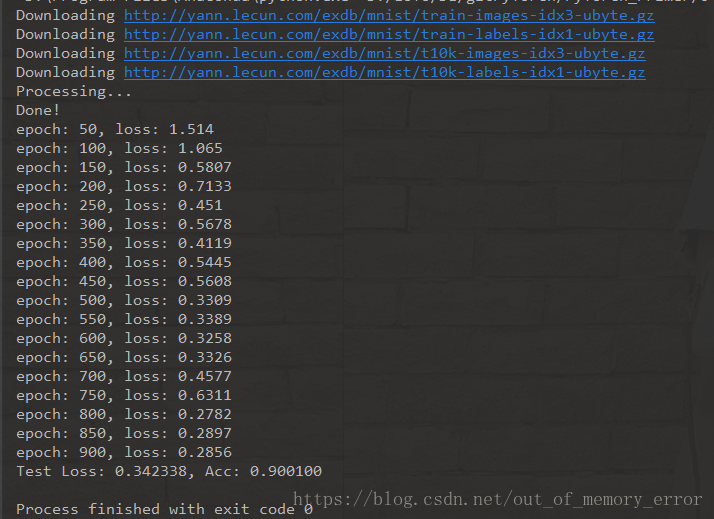
完整代码请移步我的GitHub