这一系列博客,记录我在deep learning上的理解和认知。
首先介绍神经网络的基本结构。如下图
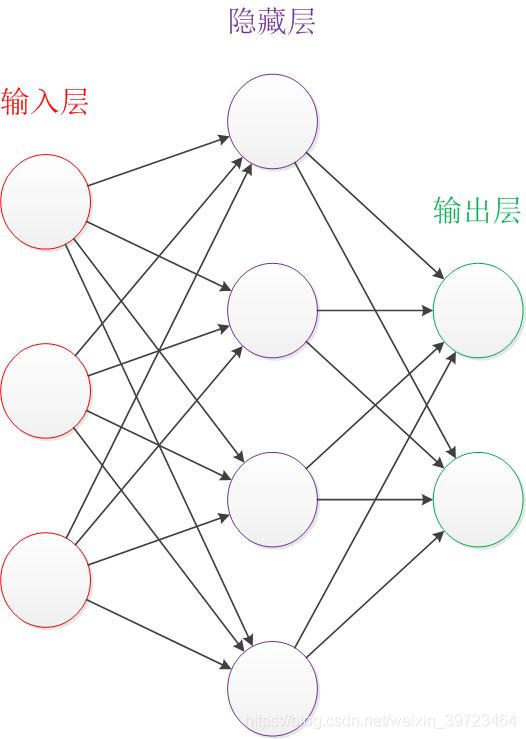
基本的结构:输入层(样本数据),隐藏层(隐藏层的层数和每层的神经元数目需要自己给定),输出层(预测目标)
神经元
神经元的结构如下图所示
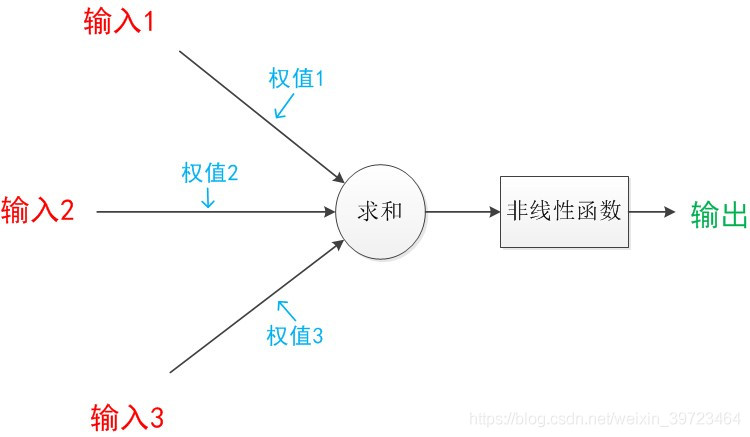
神经元是上一层的输入与权重相乘后求和,在经过非线性函数转换。得到下一层的输出。如:之前网络结构图中,从输入层到隐藏层的神经元的数目为4个。
非线性函数(激活函数)
如果把神经元的非线性函数去掉的话,那么这个神经元可以写成:输出=输入*权值+偏置。这个就是线性回归方程,所以如果把神经网络的非线性函数去掉,那么整个网络就是由多个线性回归组成的。线性回归是线性方程,只能解决线性可分的问题。多个线性回归组成的结果无论经过多少的层的神经网络,其本质上也是线性方程。但现实中的很多需要解决的问题都是线性不可分的(异或问题)。所以为了解决这些线性不可分的问题,我们引入了非线性方程g,那么输出就变为了g(w*X+b)。
目前主流的非线性函数主要有:
sigmoid函数:![]()
下图是sigmoid函数图像
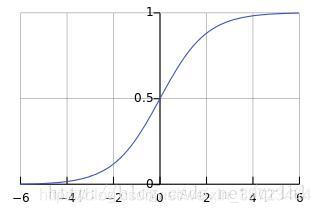
sigmoid把求和的结果都变为(0,1)之间的值。
tanh函数:![]()
下图是tanh函数与Sigmoid函数的函数曲线:
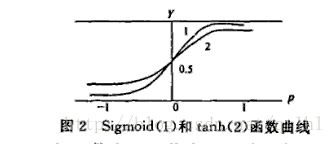
在具体应用中,tanh函数相比于Sigmoid函数往往更具有优越性,这主要是因为Sigmoid函数在输入处于[-1,1]之间时,函数值变化敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态,影响神经网络预测的精度值。主要体现在计算梯度时。
relu函数:

下图是relu函数的曲线:
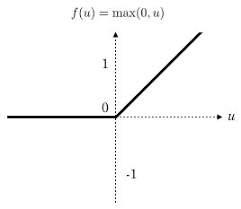
relu函数并未像tanh函数和sigmoid函数一样,将求和的值限制在(0,1)之间。其阈值是[0,+∞]。
上面3个激活函数主要是用在从输入层到隐藏层以及隐藏层到隐藏层之间。
对于最后一层隐藏层到输出层之间,一般选用softmax函数进行归一化。
softmax函数:
由于在用神经网络解决的问题大部分都是多分类问题,softmax是将多分类转化为概率的一个函数。如果预测的目标是二分类,则使用sigmoid进行二分类的概率转化。
上面表达式中的zj=隐藏层的输入*权重+偏置,K为预测目标的分类数量。
基本结构已讲完,希望对大家有所帮助。