一、预热篇
参考链接:http://colah.github.io/posts/2015-08-Backprop/
要理解的主要点:路径上所有边相乘,所有路径相加
反向传播算法(Backpropagation)已经是神经网络模型进行学习的标配。但是有很多问题值得思考一下:
反向传播算法的作用是什么? 神经网络模型的学习算法一般是SGD。SGD需要用到损失函数C关于各个权重参数的偏导数
。一个模型的参数w,b是非常多的,故而需要反向传播算法快速计算
。也就是说反向传播算法是一种计算偏导数的方法。
为什么要提出反向传播算法? 在反向传播算法提出之前人们应该想到了使用SGD学习模型,也想到了一些办法求解网络模型的偏导数,但这些算法求解效率比较低,所以提出反向传播算法来更高效的计算偏导数。(那时的网络模型还比较浅只有2-3层,参数少。估计即便不适用反向传播这种高效的算法也能很好的学习。一旦有人想使用更深的网络自然会遇到这个偏导数无法高效计算的问题,提出反向传播也就势在必行了)
反向传播怎么样实现高效计算偏导数的? 请先回顾一下当初我们学习微积分时是如何计算偏导数的? (链式法则,具体看下面)
1 用计算图来解释几种求导方法:
1.1 计算图
式子 可以用如下计算图表达:
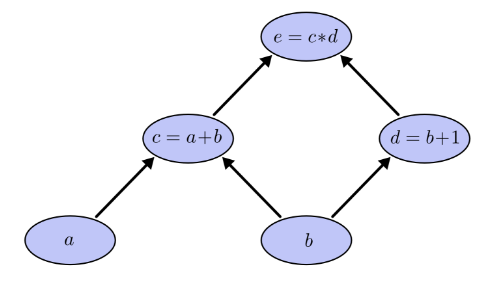
令a=2,b=1则有:
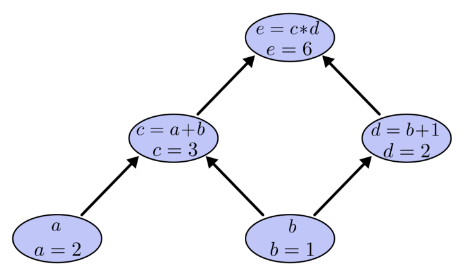
如何在计算图上表达“求导”呢? 导数的含义是 因变量随自变量的变化率,例如 表示当x变化1个单位,y会变化3个单位。 微积分中已经学过:加法求导法则是
乘法求导法则是
。 我们在计算图的边上表示导数或偏导数:
如下图:
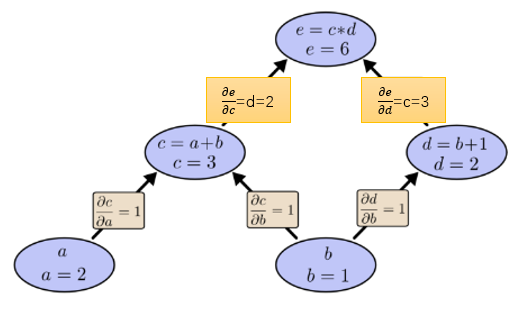
那么 如何求呢?
告诉我们1个单位的b变化会引起1个单位的c变换,
告诉我们 1 个单位的c变化会引起2个单位的e变化。所以
吗? 答案必然是错误。因为这样做只考虑到了下图橙色的路径,所有的路径都要考虑:
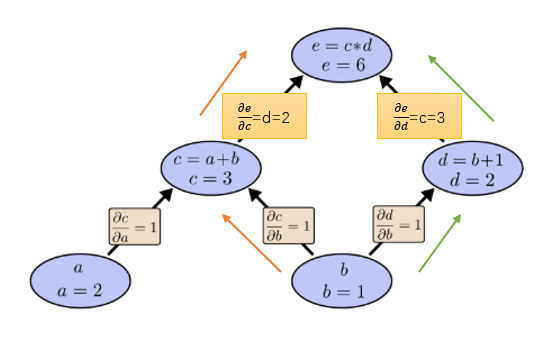
所以上面的求导方法总结为一句话就是: 路径上所有边相乘,所有路径相加。不过这里需要补充一条很有用的合并策略:
例如:下面的计算图若要计算就会有9条路径:
如果计算图再复杂一些,层数再多一些,路径数量就会呈指数爆炸性增长。但是如果采用合并策略: 就不会出现这种问题。这种策略不是 对每一条路径都求和,而是 “合并同类路径”,“分阶段求解”。先求X对Y的总影响
再求Y对Z的总影响
最后综合在一起。
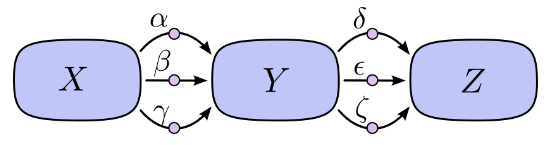
1.2 两种求导模式:前向模式求导( forward-mode differentiation) 反向模式求导(reverse-mode differentiation)
上面提到的求导方法都是前向模式求导( forward-mode differentiation) :从前向后。先求X对Y的总影响 再乘以Y对Z的总影响
。
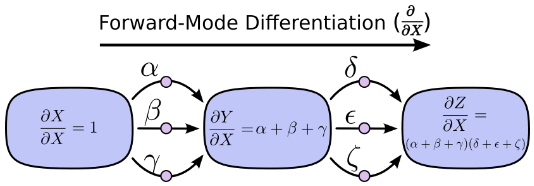
另一种,反向模式求导(reverse-mode differentiation) 则是从后向前。先求Y对Z的影响再乘以X对Y的影响。

1.3 反向求导模式(反向传播算法)的重要性:
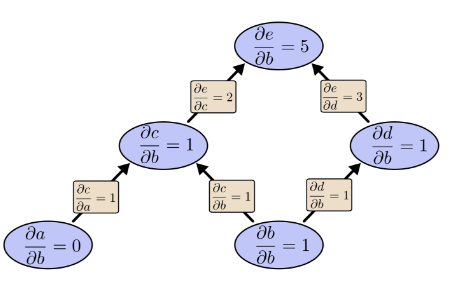
让我们再次考虑前面的例子:

如果用前向求导模式:关于b向前求导一次
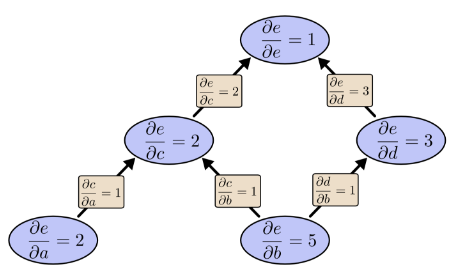
如果用反向求导模式:向后求导
前向求导模式只得到了关于输入b的偏导 ,还需要再次求解关于输入a的偏导
(运算2遍)。而反向求导一次运算就得到了e对两个输入a,b的偏导
(运算1遍)。上面的比较只看到了2倍的加速。但如果有1亿个输入1个输出,意味着前向求导需要操作1亿遍才得到所有关于输入的偏导,而反向求导则只需一次运算,1亿倍的加速。
当我们训练神经网络时,把“损失“ 看作 ”权重参数“ 的函数,需要计算”损失“关于每一个”权重参数“的偏导数(然后用梯度下降法学习)。 神经网络的权重参数可以是百万甚至过亿级别。因此 反向求导模式(反向传播算法)可以极大的加速学习。
二、理论推导
转载文章:https://zhuanlan.zhihu.com/p/25416673
神经网络结构图:
示例网络图
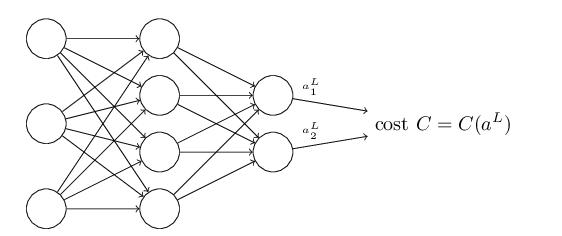
其中C是损失函数,例如C可以取:

梯度下降(SGD)进行学习时,核心问题是求解损失函数C关于所有网络参数的偏导数
。 我们已经知道用反向传播算法可以“一次反向计算”得到损失函数C关于网络中所有参数的偏导数。我们首先画出上面网络图的详细计算图:再看看具体怎么样反向传播求偏导数。
神经网络计算图
对应计算图如下:(只展开了最后两层的计算图):
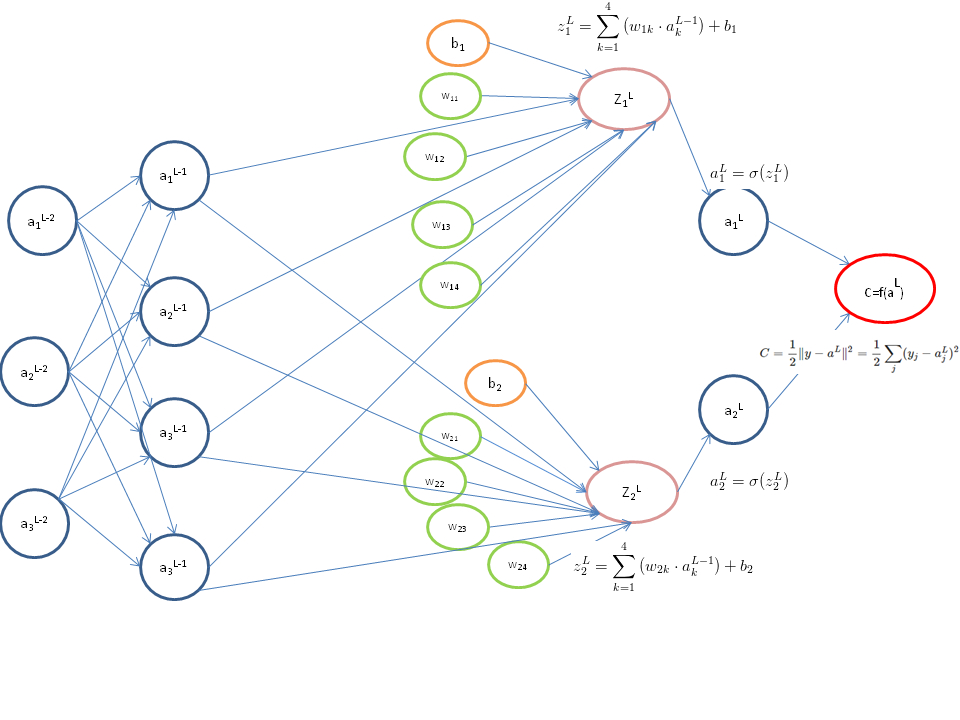
绿色代表权重参数,橙色代表基底参数
。可见虽然网络图上只是简单几条线,计算图还是蛮复杂的。
现在我们在计算图箭头上标出对应的偏导数(只标出了一部分)。
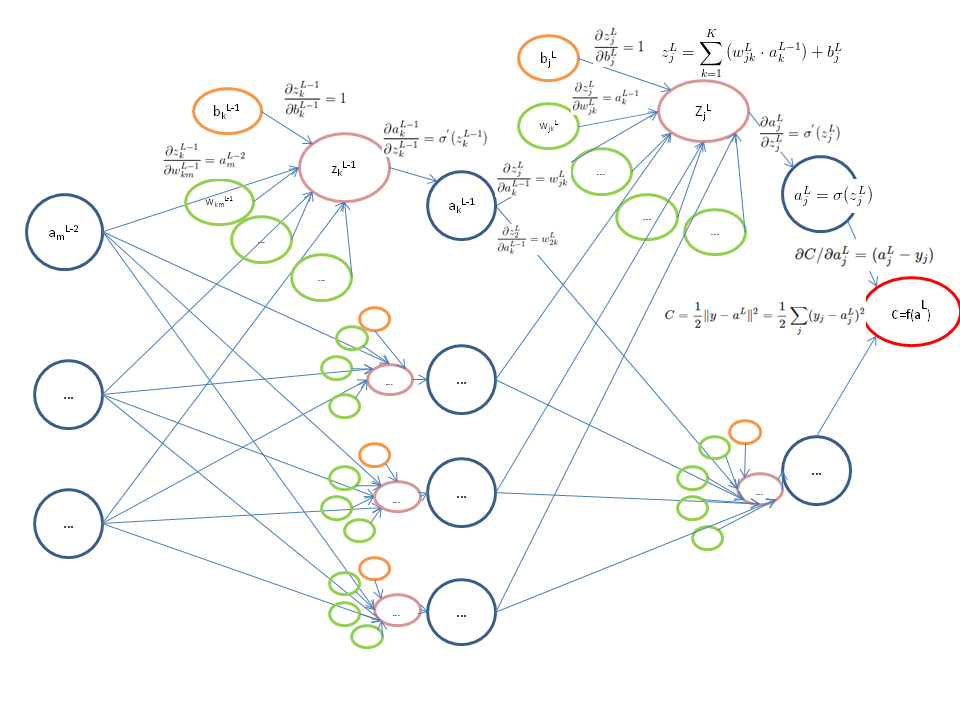
反向传播四公式
变量定义:
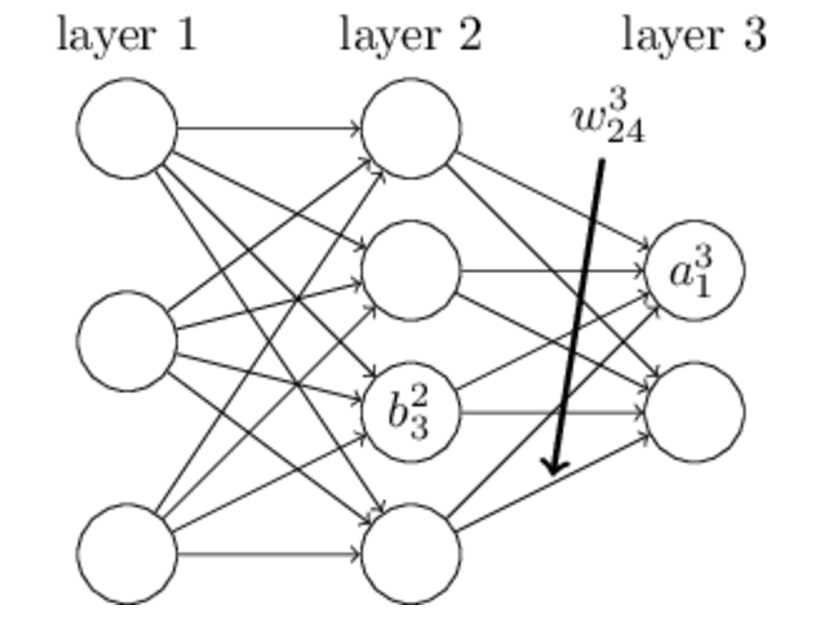
上图是一个三层人工神经网络,layer1至layer3分别是输入层、隐藏层和输出层。如图,先定义一些变量:
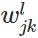
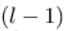
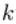
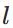

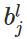
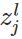
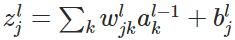
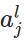
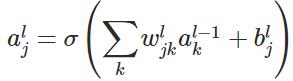
其中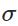
上面计算图上每一个节点关于前一个节点的偏导数都可以求得,根据求导的链式法则,想要求损失函数C关于某一节点的偏导数,只需要“把该节点每条反向路径上的偏导数做乘积,再求和”即可。(分别对应绿色和橙色的节点)
现在我们已经可以在计算图上求得损失函数C关于模型参数的偏导数。但是还不够优雅,反向传播算法要优雅的很多,它通过定义一个损失(
),先逐层向后传播得到每一层节点的损失(
),再通过每一个节点的损失(
)来求解该节点的
。
首先记损失函数C关于层的第j个元素的偏导为:
,
最后一层
对于最后一层(L层)的元素j会有:
向量化为:
(BP1)
其中的操作是把两个向量对应元素相乘组成新的元素。
后一层传播到前一层
由前面计算图中L和L-1层所标注的偏导数,可得到倒数第一层(L-1)元素j的损失为:(请仔细对照前面的计算图)
向量化:
这启发我们后一层(层)的损失
如何传播到前一层(
层)得到
。(只需要把L用
替换,
用
替换)就得到了逐层传播损失的公式
(BP2)
关于的偏导数
(BP3)
向量化:
关于的偏导数
(BP4)
向量化:
至此就得到了反向传播的4个公式:

三 理论推导(向量化推导)
转载:https://blog.csdn.net/u014313009/article/details/51039334
公式1(计算最后一层神经网络产生的错误):
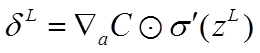
其中,表示Hadamard乘积,用于矩阵或向量之间点对点的乘法运算。公式1的推导过程如下:
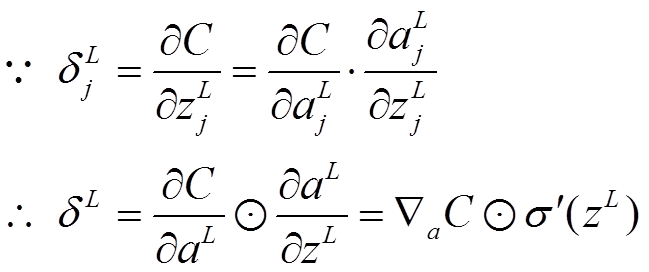
公式2(由后往前,计算每一层神经网络产生的错误):
推导过程:
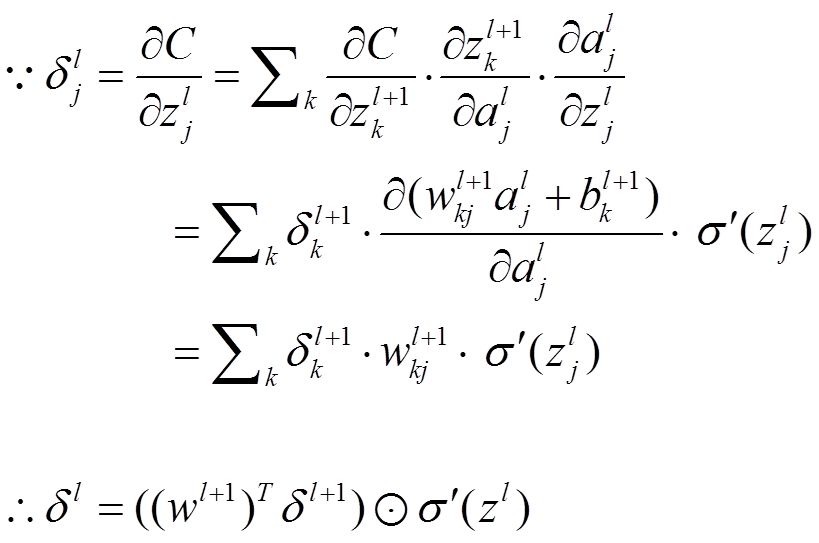
公式3(计算权重的梯度):
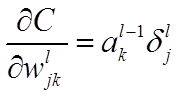
推导过程:
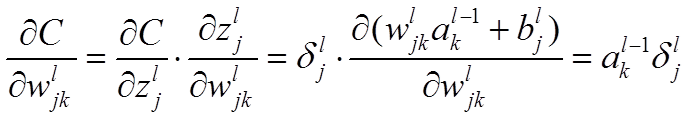
公式4(计算偏置的梯度):
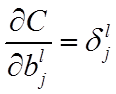
推导过程:
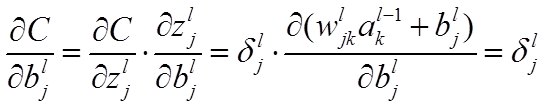
4. 反向传播算法伪代码
输入训练集
对于训练集中的每个样本x,设置输入层(Input layer)对应的激活值:
前向传播:
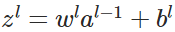
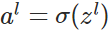
计算输出层产生的错误:
反向传播错误:
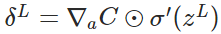
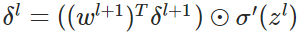
使用梯度下降(gradient descent),训练参数:
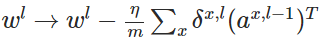
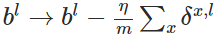
---------------------