摘要
ChatGPT的成功引发了一场AI竞赛,研究人员致力于开发新的大型语言模型(LLMs),以匹敌或超越商业模型的语言理解和生成能力。近期,许多声称其性能接近GPT-3.5或GPT-4的模型通过各种指令调优方法出现了。作为文本到SQL解析的从业者,我们感谢他们对开源研究的宝贵贡献。然而,重要的是要带着审查意识去看待这些声明,并确定这些模型的实际有效性。因此,我们将六个流行的大型语言模型相互对比,系统评估它们在九个基准数据集上的文本到SQL解析能力,涵盖了五种不同的提示策略,包括零样本和少样本场景。遗憾的是,开源模型的性能远远低于像GPT-3.5这样的封闭源模型所取得的成绩,这凸显了进一步工作的需要,以弥合这些模型之间的性能差距。
1.简介
文本到 SQL 解析自动将用户输入的问题转换为 SQL 语句,从而能够从数据库中检索相关信息。 通过使用户能够用自然语言表达他们的目标,文本到 SQL 系统可以最大限度地减少非专家用户与关系数据库交互的技术障碍并提高生产力。
BERT(Devlin 等人,2019)和 T5(Raffel 等人,2020)等大型预训练语言模型的引入进一步提高了文本到 SQL 系统的性能。 研究人员一直在利用对这些模型的深刻理解来突破文本到 SQL 功能的界限。
最近,基于解码器的大型语言模型的突破(Brown et al., 2020b; Touvron et al., 2023)进一步彻底改变了 NLP 领域。 一个突出的趋势是追求训练越来越大的语言模型,包含数十亿个参数,并利用大量文本数据。 随后,使用基于指令的技术对这些模型进行微调,使它们能够更好地遵循人类生成的文本提示。
解码器 LLM 的突出应用之一是 ChatGPT,它基于 OpenAI 的 GPT-3.5 和 GPT-4 模型构建。 ChatGPT 在零样本和少样本场景中展示了卓越的能力,正如各种文本到 SQL 评估研究所证明的那样(Rajkumar 等人,2022 年;Liu 等人,2023 年)。 遗憾的是,Chat-GPT 的成功引发了一场人工智能竞赛,导致行业研究实验室停止公开披露其模型参数和训练方法。
因此,研究人员一直在积极寻求新语言模型的开发,这些模型有可能与 Chat-GPT 的功能相媲美。 这些模型包括基于 Pythia 模型构建的 Dolly(Biderman 等人,2023),以及基于 LLaMA 模型的 Vicuna(Chiang 等人,2023)和 Guanaco(Dettmers 等人,2023) (Touvron 等人,2023)。 其中一些声称通过微调技术达到了超过 GPT-4 90% 的性能水平,从而引起了人们的关注。
作为文本到 SQL 的实践者,我们感谢这些模型所做的贡献。 然而,我们仍然不确定这些开源模型是否真正达到了他们声称达到的质量水平。 为了解决这个问题,本文对六种语言模型进行了综合评估:Dolly、LLaMA、Vicuna、Guanaco、Bard 和 ChatGPT,利用五种不同的提示策略,直接比较它们在九个基准数据集上的性能。
我们的主要发现是:
- 在大多数文本到 SQL 数据集中,开源模型的性能明显低于闭源模型。
- 虽然LLM在生成语法上有效的 SQL 语句方面表现出熟练程度,但他们通常很难生成语义上准确的查询。
- 事实证明,LLM 对用于小样本学习( few-shot learning)的示例高度敏感。
2.试验Setup
2.1 LLM介绍
略
2.2 提示策略(Prompting Strategies)
- Informal Schema (IS) :非正式模式 (IS) 策略以自然语言提供表及其关联列的描述。在这种方法中,模式信息以不太正式的方式表达。
- API Docs (AD) :相比之下,Rajkumar (2022)等人进行的评估中概述的 API 文档 (AD) 策略,遵循OpenAI 文档4中提供的默认 SQL 翻译提示。此提示遵循稍微更正式的数据库模式定义。
- Select 3 :Select 3 策略包括数据库中每个表的三个示例行。 此附加信息旨在提供每个表中包含的数据的具体示例,以补充模式描述。
- 1SL:1-Shot Learning (1SL),在提示中提供 1 个黄金示例。
- 5SL :5 Shot Learning (5SL) ,在提示中提供 1 个黄金示例。
2.3 基准数据集
Spider和8大传统数据集
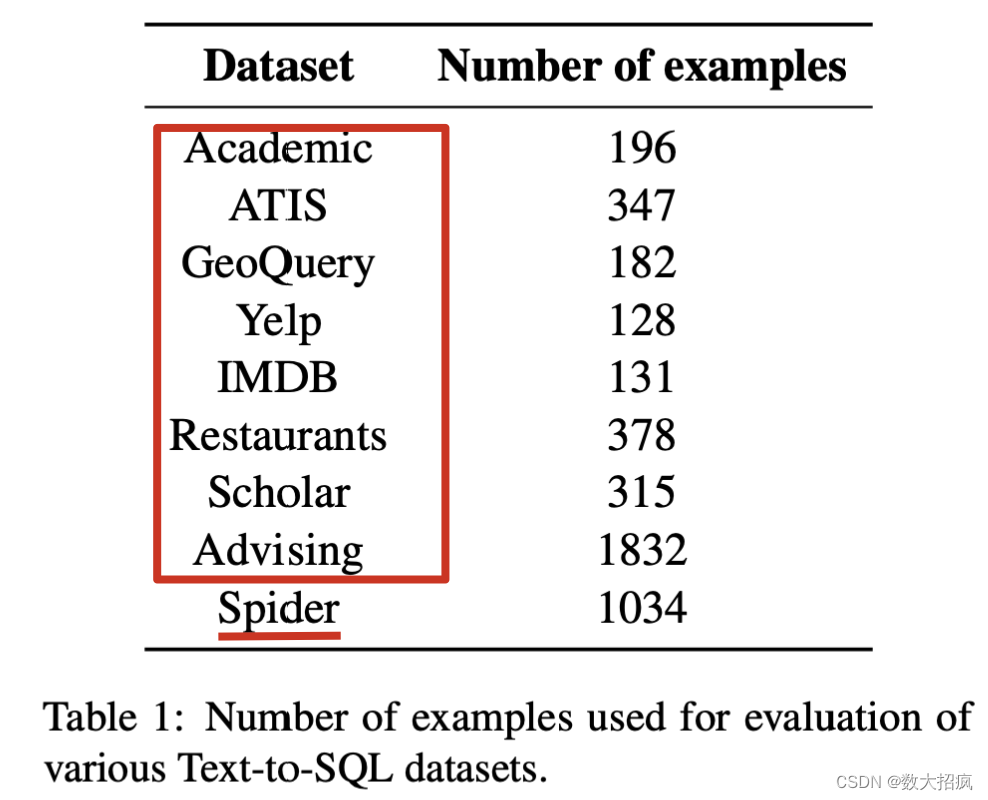
2.4 评估指标
本文采用的主要评估指标是执行准确性 (EX),它衡量生成的 SQL 查询与黄金 SQL 查询的输出精确一致的百分比。 此外,对于Spider数据集,我们还计算了 test suite accuracy(TS),它作为该数据集的官方评估指标。 TS 通过评估一组随机生成的数据库上预测查询的执行准确性,提供语义准确性的上限估计(Zhong 等人,2020)。
与刘等人类似 (2023),我们避免使用精确匹配精度 (Yu et al., 2018) 指标,因为 SQL 查询通常可以用多种等效方式表示来实现相同的目标。 因此,精确匹配的准确性可能会无意中对生成与黄金数据风格不同的 SQL 查询的大型语言模型造成不利影响。
2.5 评估详情
我们在研究中使用了多种模型,包括Dolly 的三种变体(v2-3b、v2-7b 和 v2-12b)、Vicuna 的两种变体(7B 和 13B)、Guanaco 的一种变体(33B)以及 LLaMA 的四种变体(7B、13B、30B 和 65B)。 为了确保一致性,我们的目标是严格遵守每个模型的默认超参数。 我们为 Dolly 设置了 0.92 的 top-p 采样率和 0.8 的温度,为 Vicuna 和guanaco 设置了 0.8 的温度,为 LLaMA 设置了 0.95 的 top-p 采样率和 0.8 的温度。 在评估过程中,我们在配备八个 NVIDIA RTX A6000 GPU 的服务器上进行实验。 对于 Bard,我们开发了一个脚本,可以直接从其 Web 用户界面提取评估输出。 对于 GPT3.5,我们通过 OpenAI 的 API 利用“gpt-3.5-turbo-0301”版本,并遵守温度 1.0 和 top-p 采样率 1.0 的默认超参数。
ChatGPT论文:大语言模型LLM之战:Dolly、LLaMA 、Vicuna、Guanaco、Bard、ChatGPT–在自然语言转SQL(NL2SQL、Text-to-SQL)的比较(二)
论文翻译:Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison