思路

数据说明
kaggle平台数据,人力资源分析数据集汇聚了对大量员工的信息数据统计,包括企业因素(如部门)、员工行为相关因素(如参与过项目数、每月工作时长、薪资水平等)、以及工作相关因素(如绩效评估、工伤事故),这些因素都有很好的分析价值。

代码
读取数据,更换中文列名,将“是否离职”列放在最后,方便观察
data = pd.read_csv('./HR_comma_sep.csv',encoding='gb18030')
data.head(1)
data= data[['satisfaction_level', 'last_evaluation', 'number_project',
'average_montly_hours', 'time_spend_company', 'Work_accident',
'promotion_last_5years', 'sales', 'salary', 'left']]
columns={'satisfaction_level':'满意程度',
'last_evaluation':'绩效评估',
'number_project':'项目数',
'average_montly_hours':'每月平均工作时长',
'time_spend_company':'工龄',
'Work_accident':'是否出过工作事故',
'promotion_last_5years':'5年内是否升职',
'sales':'部门',
'salary':'薪资水平',
'left':'是否离职'
}
data.rename(columns=columns,inplace=True)
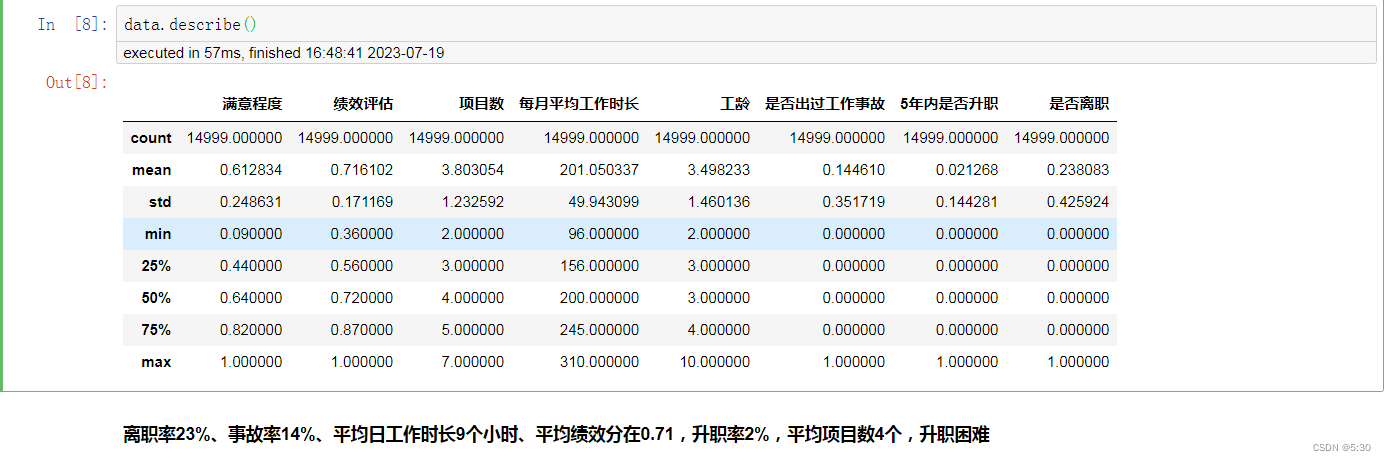
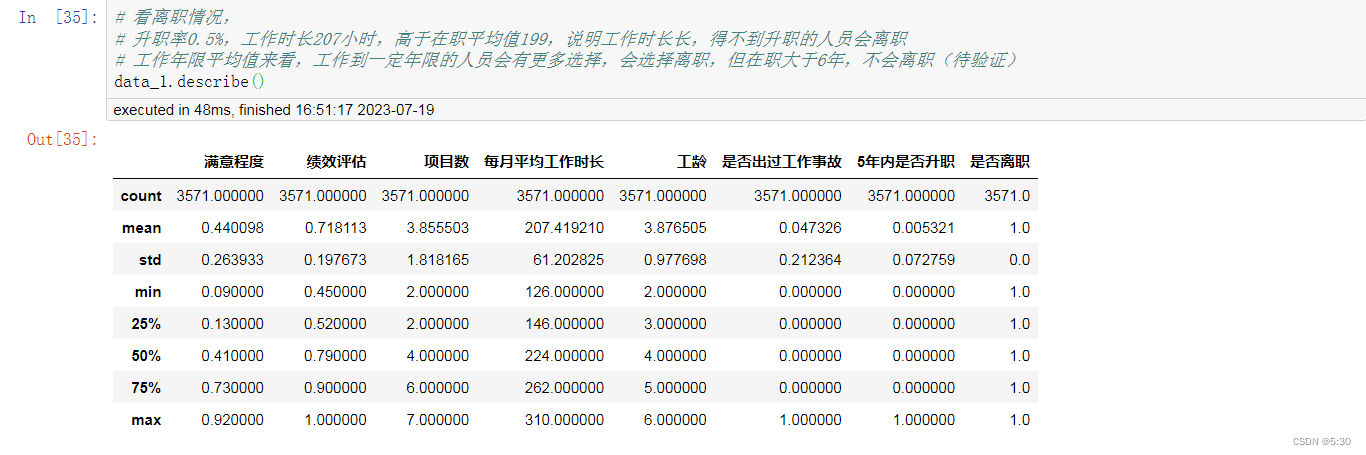
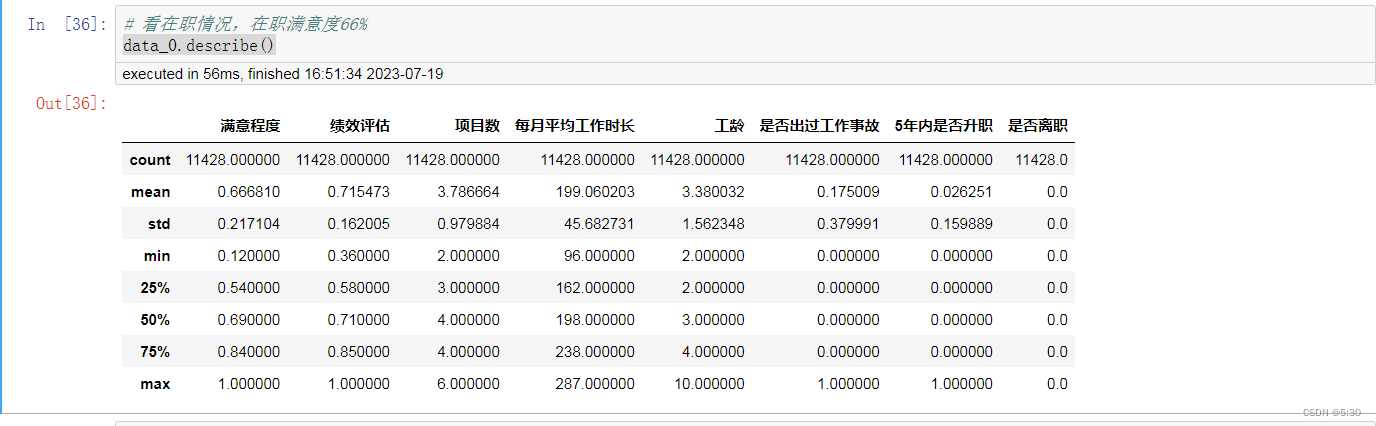
划分数据集,data_0在职数据集,data_1离职数据集
data_0 = data[data['是否离职']==0] #在职
data_1 = data[data['是否离职']==1] #离职
数据概况
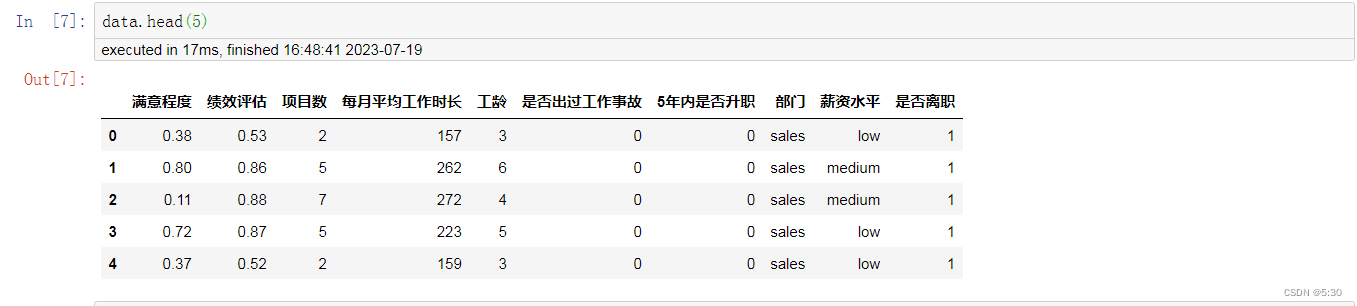
离职率23%、事故率14%、平均日工作时长9个小时、平均绩效分在0.71,升职率2%,平均项目数4个,升职困难
data.describe()
data_1.describe()
data_0.describe()
相关性矩阵
与满意度呈现负相关,其余变量线性相关性较弱
# 计算相关性矩阵
correlation_matrix = data.corr()
# 创建布尔矩阵用于遮挡
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool))
# 使用seaborn绘制相关性热力图
plt.figure(figsize=(12, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='Blues',mask=mask)
# 显示图形
plt.show()
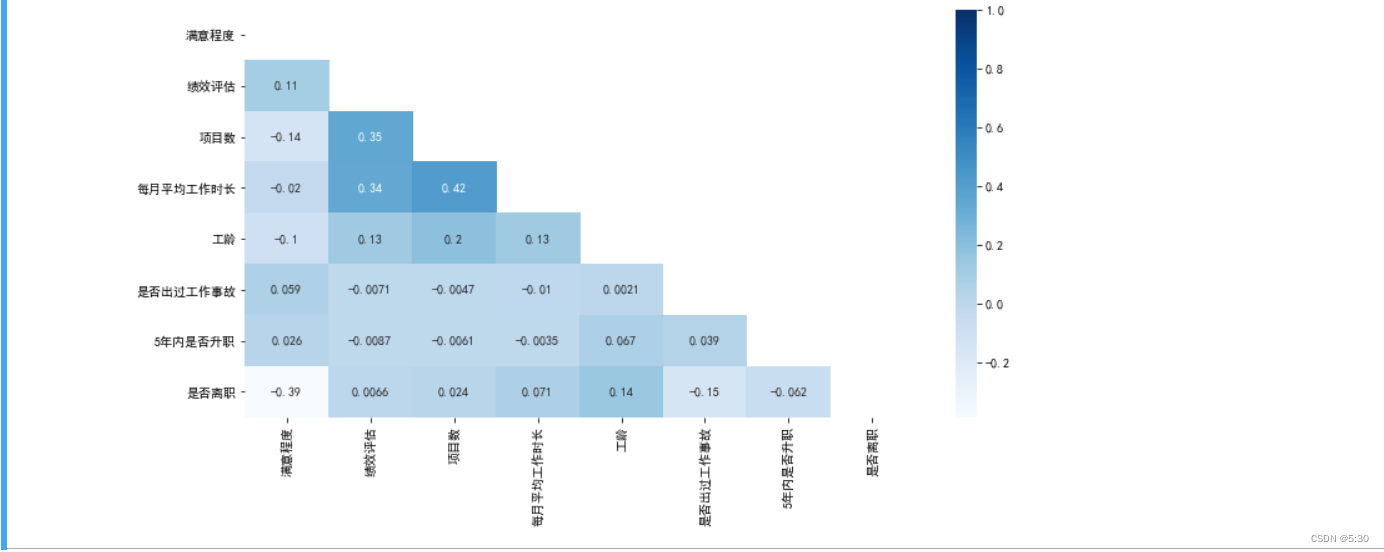
高相关变量
绩效评估与工作时长高相关,说明工作时长应该是作为绩效评估比较重要的点,但是与升职相关性不高,说明工作时长越长,并不代表升职概率大
threshold = 0.3
high_correlation_pairs = []
for i in range(len(correlation_matrix.columns)):
for j in range(i+1, len(correlation_matrix.columns)):
if abs(correlation_matrix.iloc[i, j]) >= threshold:
high_correlation_pairs.append((correlation_matrix.columns[i], correlation_matrix.columns[j]))
print("High correlation pairs:")
for pair in high_correlation_pairs:
print(pair)
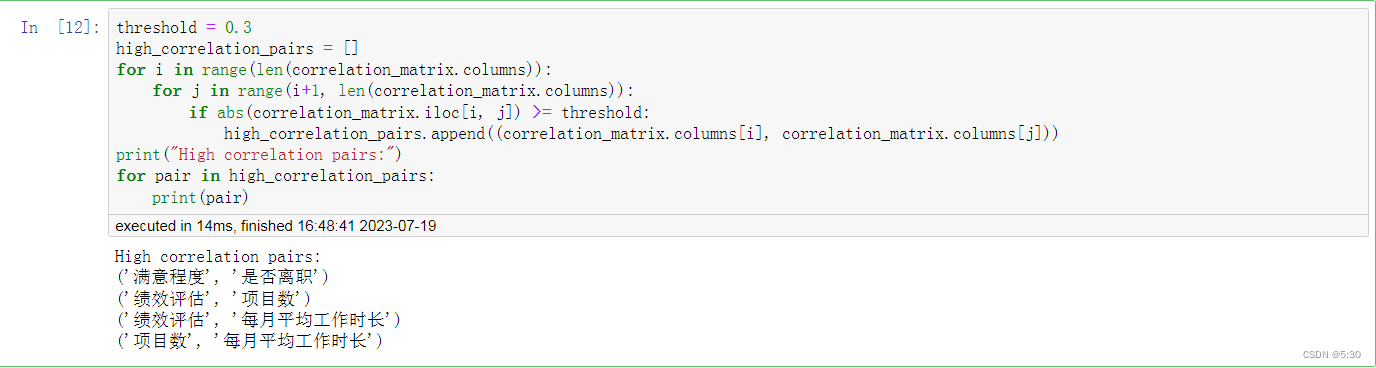
满意度
在不在职,满意度差距比较大
#满意度和是否离职之间的关系
plt.figure(figsize=(8,5),dpi=80)
sns.boxplot(x='是否离职',y='满意程度',data=data,width=0.45,palette='Blues',linewidth=3)
plt.show()
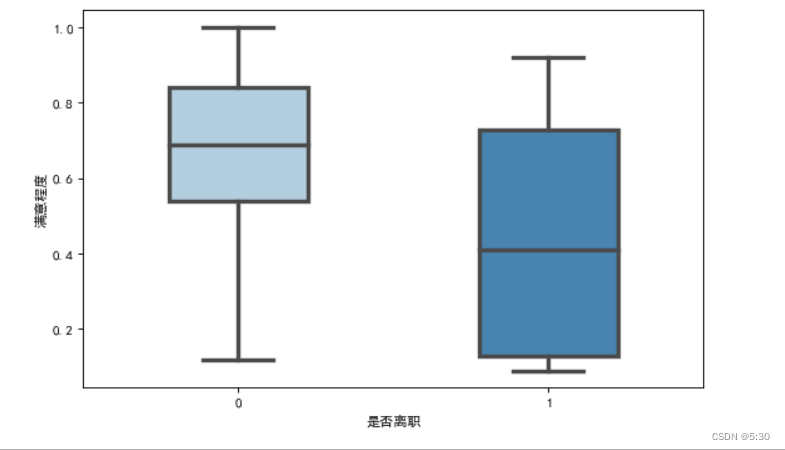
工龄与离职率
五年是个转折点,在职五年离职率56%
# 稳定的人群为刚入公司2年以内,或7年以上,基本稳定
# 5年有一半人会离职
df = data.groupby(['工龄'])['是否离职'].agg({'离职率':'mean'}).applymap(lambda x:format(x,'.2%'))
df

# 创建一个数据集
x_data = df.index.tolist()
y_data = df['离职率'].tolist()
y_data = [round(value * 100,0) for value in y_data]
# 创建柱形图对象
bar = (
Bar({"theme": ThemeType.MACARONS})
.add_xaxis(x_data)
.add_yaxis("", y_data,
itemstyle_opts=opts.ItemStyleOpts(color='#003366')
)
.set_series_opts(
label_opts=opts.LabelOpts(
position="top",
formatter='{c}%' # 设置标签显示为百分比形式)
)
)
)
# 设置全局配置项
bar.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=15)),
yaxis_opts=opts.AxisOpts(
name="离职率",
axislabel_opts=opts.LabelOpts(formatter='{value}%')
# 设置y轴标签显示为百分比形式
),
title_opts=opts.TitleOpts(title="工龄与离职率"),
)
bar.render_notebook()
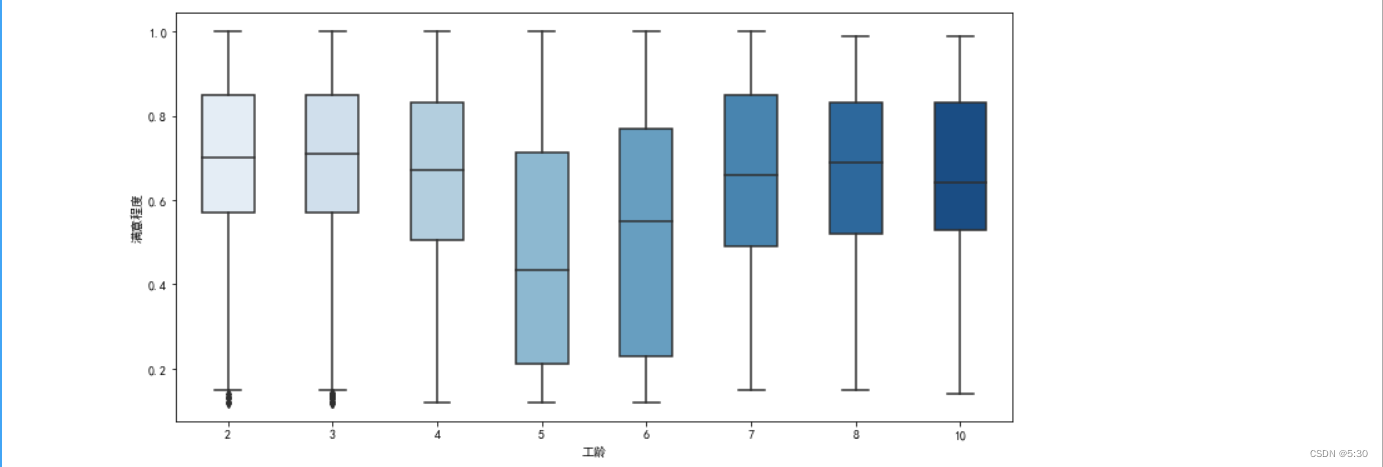
工龄与在职满意度
在职5-6年,对公司满意度最低,可能与是否得到合适的回报升职有关,与公司整体情况对比,升职率并没有异常,5-6年应该对公司业务已经能熟练掌握,猜测是这家公司升职率低于行业水平,导致的离职
# 工龄满意度的关系
# 使用Seaborn绘制箱形图
plt.figure(figsize=(12, 6))
sns.boxplot(x="工龄", y="满意程度", data=data_0, palette='Blues',width=0.5)
# 显示图形
plt.show()
data_0[data_0['工龄'].isin([5,6])].groupby('工龄').agg({'5年内是否升职':'mean'}).applymap(lambda x:format(x,'.2%'))

项目数
不劳也走,操劳过度也得离开
工作接的项目太多,导致没法升职?
df1 = data.groupby(['项目数'])['是否离职'].agg({'离职率':'mean'}) .applymap(lambda x:format(x,'.2%'))
df1

# 创建一个数据集
x_data = df1.index.tolist()
y_data = df1['离职率'].tolist()
y_data = [round(value * 100,0) for value in y_data]
# 创建柱形图对象
bar = (
Bar({"theme": ThemeType.MACARONS})
.add_xaxis(x_data)
.add_yaxis("", y_data,
itemstyle_opts=opts.ItemStyleOpts(color='#C8B2F4')
)
.set_series_opts(
label_opts=opts.LabelOpts(
position="top",
formatter='{c}%' # 设置标签显示为百分比形式)
)
)
)
# 设置全局配置项
bar.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=15)),
yaxis_opts=opts.AxisOpts(
name="离职率",
axislabel_opts=opts.LabelOpts(formatter='{value}%')
# 设置y轴标签显示为百分比形式
),
title_opts=opts.TitleOpts(title="项目数与离职率"),
)
bar.render_notebook()
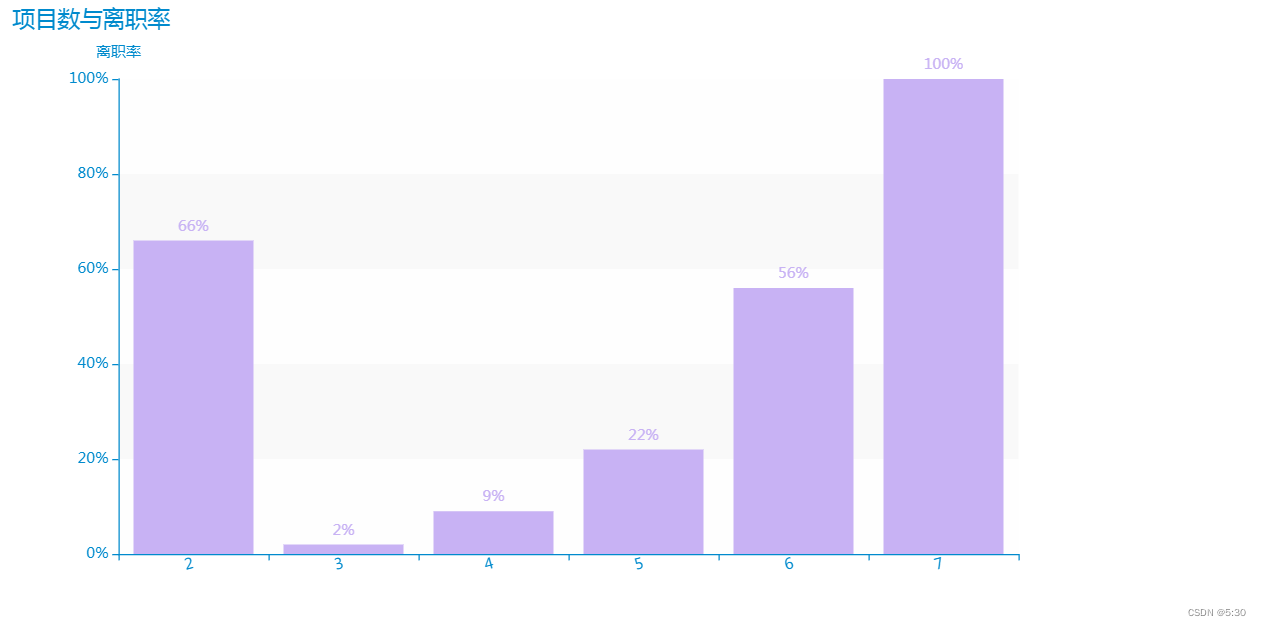
# 项目数7个人员都没有升职,所以选择离职
data[data['项目数']>=7]['5年内是否升职'].unique()

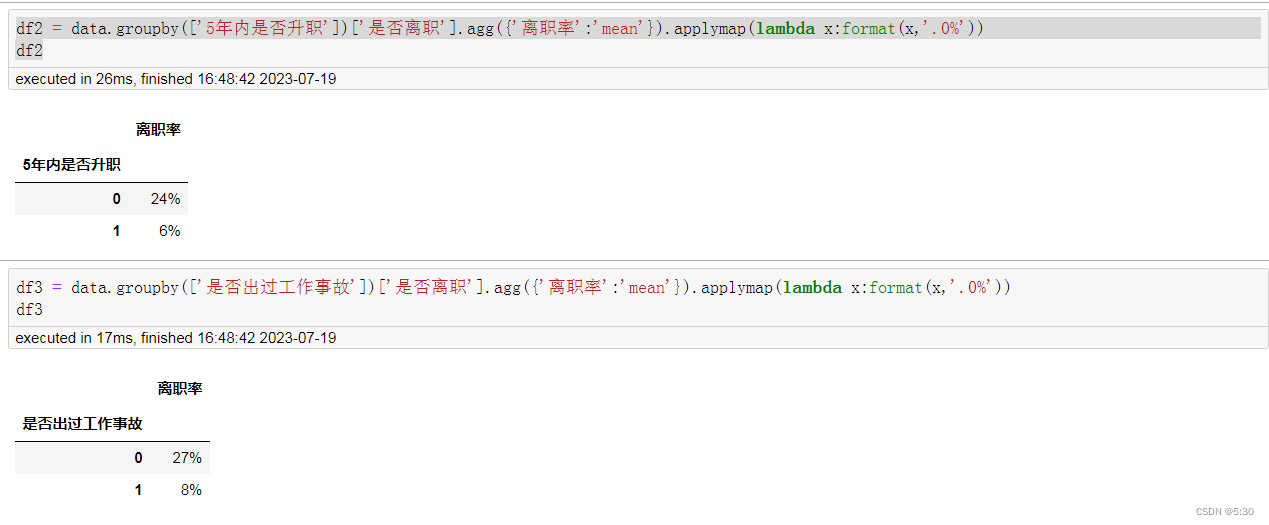
升职、事故
df2 = data.groupby(['5年内是否升职'])['是否离职'].agg({'离职率':'mean'}).applymap(lambda x:format(x,'.0%'))
df3 = data.groupby(['是否出过工作事故'])['是否离职'].agg({'离职率':'mean'}).applymap(lambda x:format(x,'.0%'))
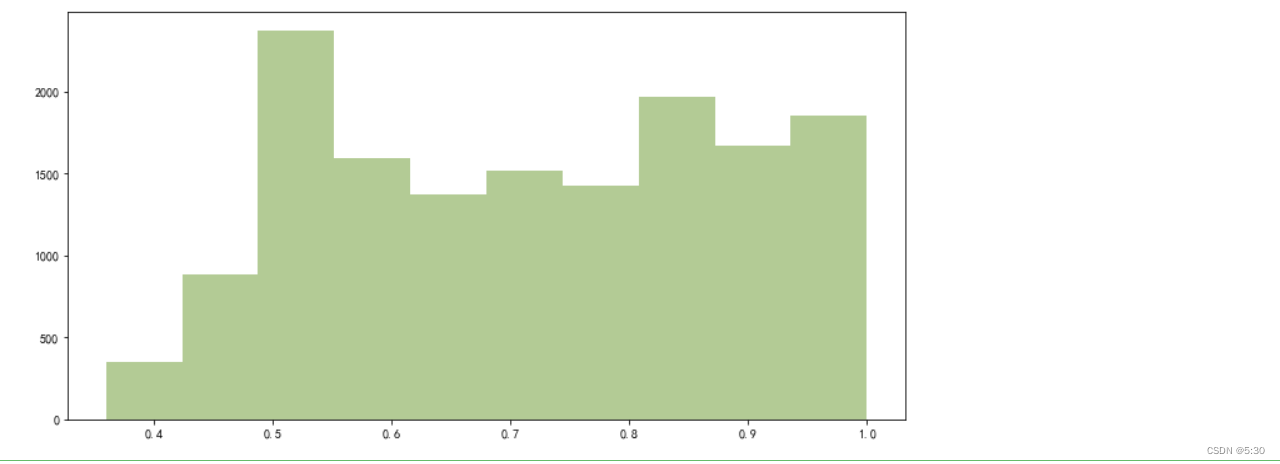
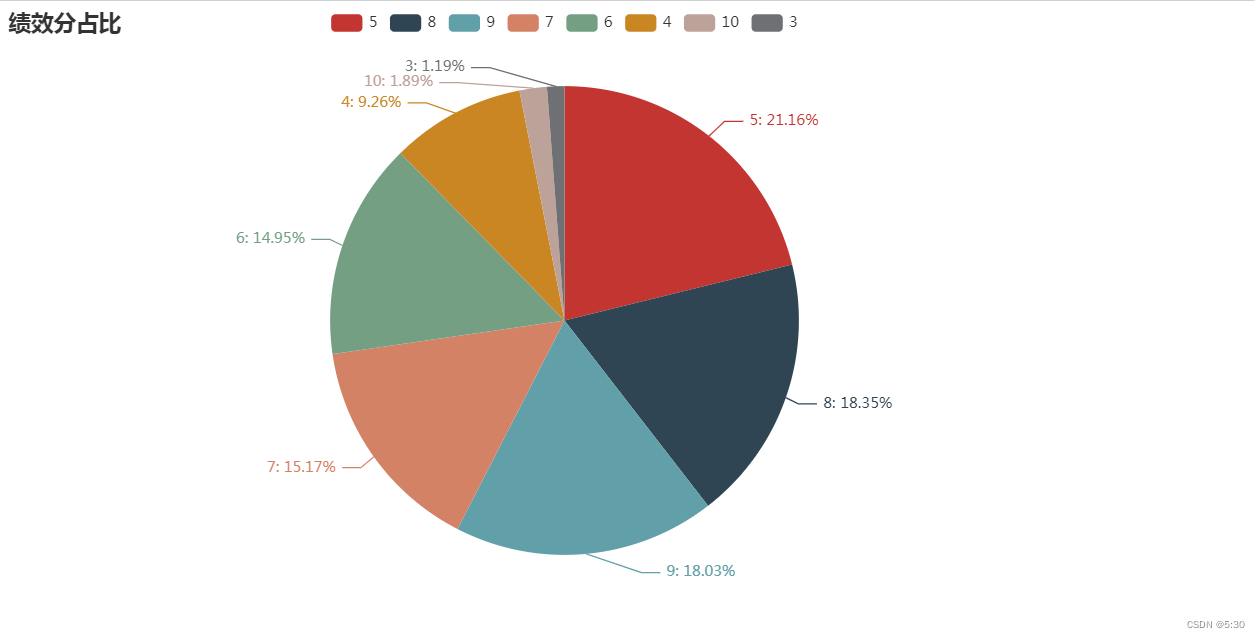
绩效评分
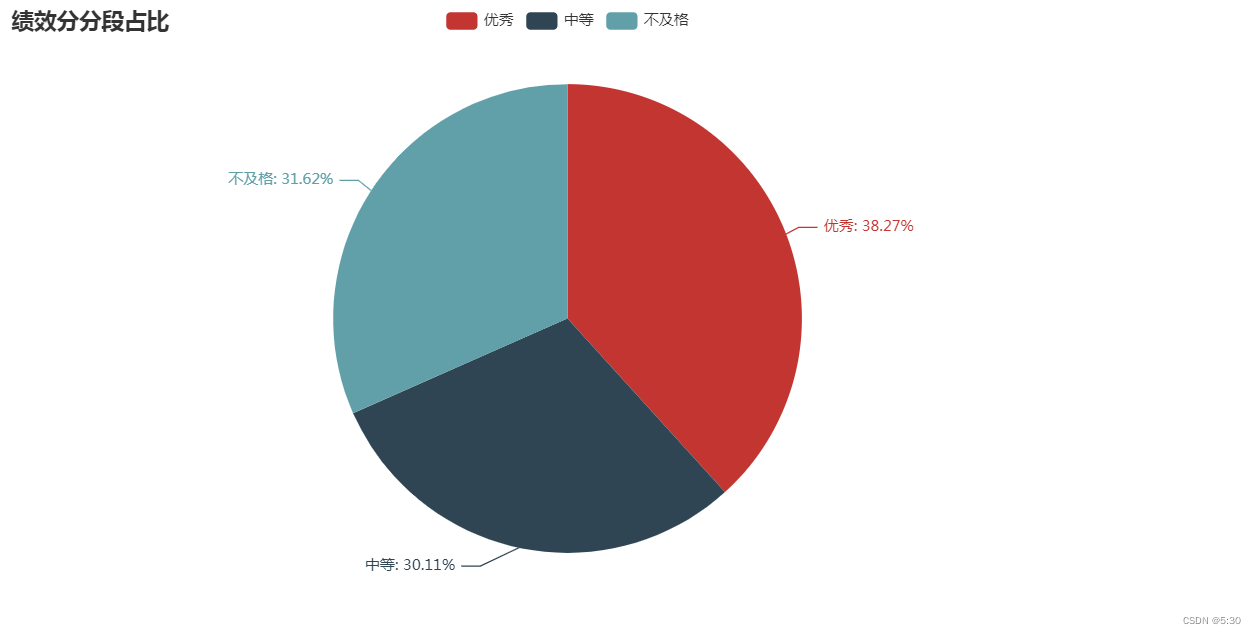
9分以上人员接近20%,优秀(8-10)、中等(6-8)、不及格(3-6),呈现三等分
评分3分的人,反而没人离职
plt.figure(figsize=(12, 6))
plt.hist(data['绩效评估'], color='#B3CB95')
plt.show()
对绩效评分进行分层
bins = range(3, 12, 1) # 定义分组区间
labels = range(3, 11) # 定义标识值
data['group'] = pd.cut(data['绩效评估'].apply(lambda x:x*10), bins=bins, labels=labels,right=False)
评分与离职率
df4 = data.groupby(['group'])['是否离职'].agg({'离职率':'mean'}).applymap(lambda x:format(x,'.0%'))
df4


x = data['group'].value_counts().index.tolist()
y = data['group'].value_counts().values.tolist()
pie = (
Pie()
.add("", [z for z in zip(x, y)],)
.set_global_opts(title_opts=opts.TitleOpts(title="绩效分占比"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
pie.render_notebook()
x = ['优秀','中等','不及格']
y1 = data[data['绩效评估']>=0.8]['绩效评估'].count()
y2 = data[data['绩效评估']<0.6]['绩效评估'].count()
y3 = data['绩效评估'].count() - y1 -y2
total_count = data['绩效评估'].count()
proportions = [y1 / total_count, y3 / total_count, y2 / total_count]
pie = (
Pie()
.add("", [z for z in zip(x, proportions)])
.set_global_opts(title_opts=opts.TitleOpts(title="绩效分分段占比"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
pie.render_notebook()
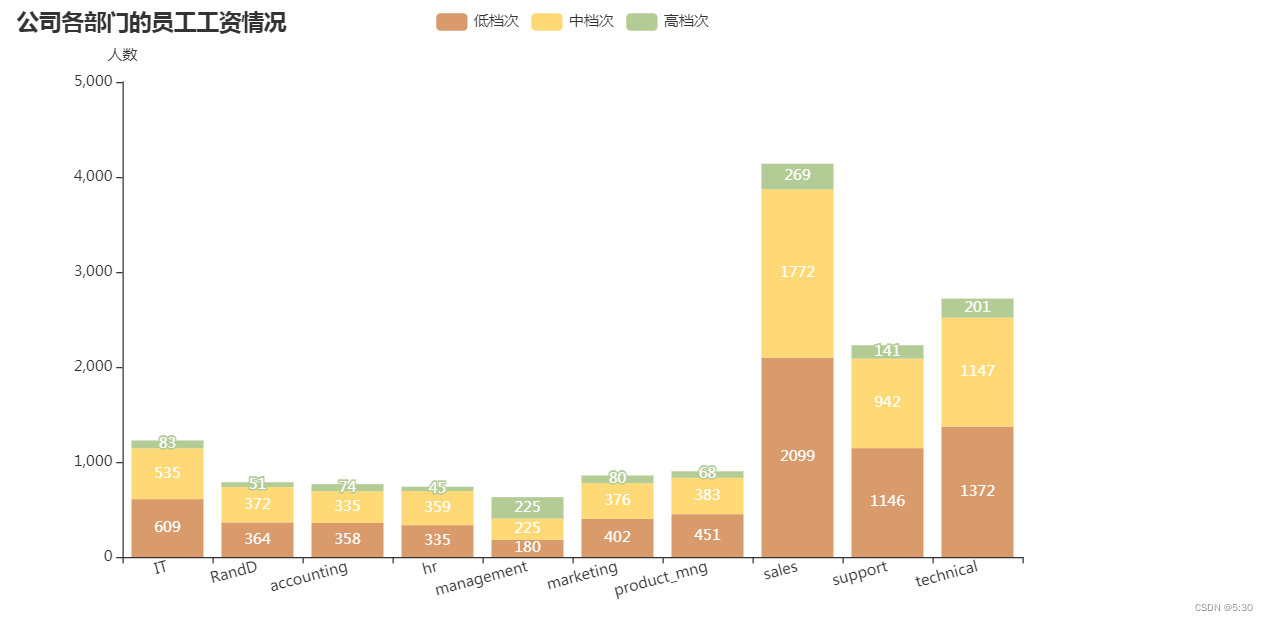
部门、薪资水平
人事部门(hr)离职率最高29%,销售部门(sales)离职人数最多,有1014人,其次为技术部门(technical),离职与工资低有关
销售部门(sales)低工资水平(low salary)的最多,有2099人,其次是技术部门(technical)与后勤部门(support),分别为1372人与1146人
df5 = data.groupby(['部门'])['是否离职'].agg({'离职率':'mean'}).sort_values(by=['离职率'],ascending=False).applymap(lambda x:format(x,'.0%'))
df5

# 计算离职率
df5 = data.groupby(['部门'])['是否离职'].agg({'离职率':'mean'}).applymap(lambda x:round(x,2)).reset_index()
# 创建 Line 实例
line = Line()
# 添加数据
line.add_xaxis(df5['部门'].tolist())
line.add_yaxis(
series_name="离职率",
y_axis=(df5['离职率'] * 100).tolist(), # 将离职率转换为百分比形式
is_smooth=False, # 是否平滑连接数据点
symbol="circle", # 数据点的形状,这里使用圆形
symbol_size=8, # 数据点的大小
linestyle_opts=opts.LineStyleOpts(width=2), # 线条样式,这里设置线宽为 2
label_opts=opts.LabelOpts(
is_show=True,
formatter=JsCode("function (params) {return params.value[1] + '%'}"), # 将数据标签格式化为百分比形式,保留两位小数
position="top", # 数据标签显示在数据点的上方
),
)
# 设置全局配置项
line.set_global_opts(
title_opts=opts.TitleOpts(title="部门离职率直线图"),
xaxis_opts=opts.AxisOpts(name="部门"),
yaxis_opts=opts.AxisOpts(
name="离职率",
axislabel_opts=opts.LabelOpts(formatter="{value}%"), # 将 y 轴标签格式化为百分比形式
),
)
line.render_notebook()

df6 = data.groupby(['部门','薪资水平']).agg({'薪资水平':'count'}).unstack()
df6

# 部门与薪资水平的关系
# 定义数据
departments = df6.index.tolist() # 部门列表
high_counts = df6[('薪资水平','high')].tolist() # 高档次人数
medium_counts = df6[('薪资水平','medium')].tolist() # 中档次人数
low_counts = df6[('薪资水平','low')].tolist() # 低档次人数
# 创建 Bar 实例
bar = Bar()
# 添加数据系列
bar.add_xaxis(departments)
bar.add_yaxis('低档次', low_counts, stack='stack1')
bar.add_yaxis('中档次', medium_counts, stack='stack1')
bar.add_yaxis('高档次', high_counts, stack='stack1')
# 设置颜色风格
colors = ['#D99A6C', '#FED976', '#B3CB95'] # 棕色、黄色、绿色
bar.set_colors(colors)
# 设置全局配置项
bar.set_global_opts(
title_opts=opts.TitleOpts(title='公司各部门的员工工资情况'),
legend_opts=opts.LegendOpts(),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=15)),
yaxis_opts=opts.AxisOpts(name='人数'),
)
# 设置系列配置项
bar.set_series_opts(label_opts=opts.LabelOpts(position='inside'),bar_width='5%')
bar.render_notebook()
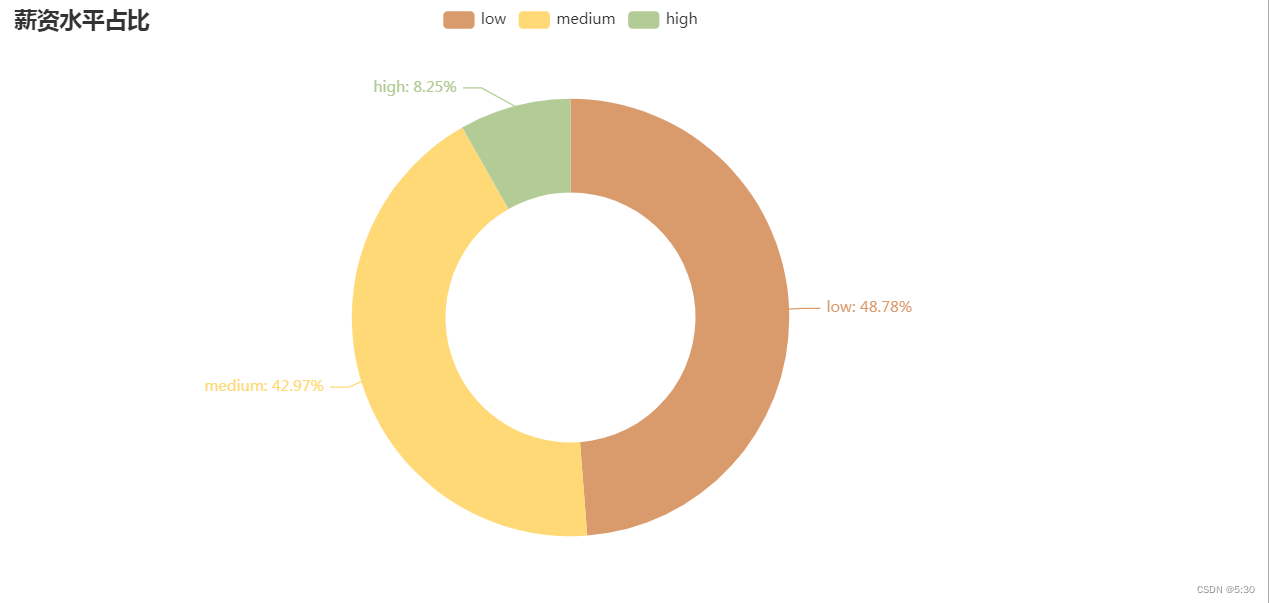
# 薪资水平离职率
df6 = data.groupby(['薪资水平'])['是否离职'].agg({'离职率':'mean'}).applymap(lambda x:format(x,'.0%'))
df6

df7 = data['薪资水平'].value_counts()
labels = df7.index.tolist() # 薪资水平标签列表
values = df7.values.tolist() # 薪资水平对应的值列表
# 创建 Pie 实例
pie = Pie()
# 添加数据
pie.add(
series_name='薪资水平占比',
data_pair=list(zip(labels, values)),
radius=["40%", "70%"], # 设置饼图的内外半径,可以根据需要进行调整
label_opts=opts.LabelOpts(formatter="{b}: {d}%"), # 显示标签,显示格式为 "标签: 百分比%"
)
# 设置颜色风格
colors = ['#D99A6C', '#FED976', '#B3CB95'] # 棕色、黄色、绿色
pie.set_colors(colors)
# 设置全局配置项
pie.set_global_opts(title_opts=opts.TitleOpts(title="薪资水平占比"))
pie.render_notebook()
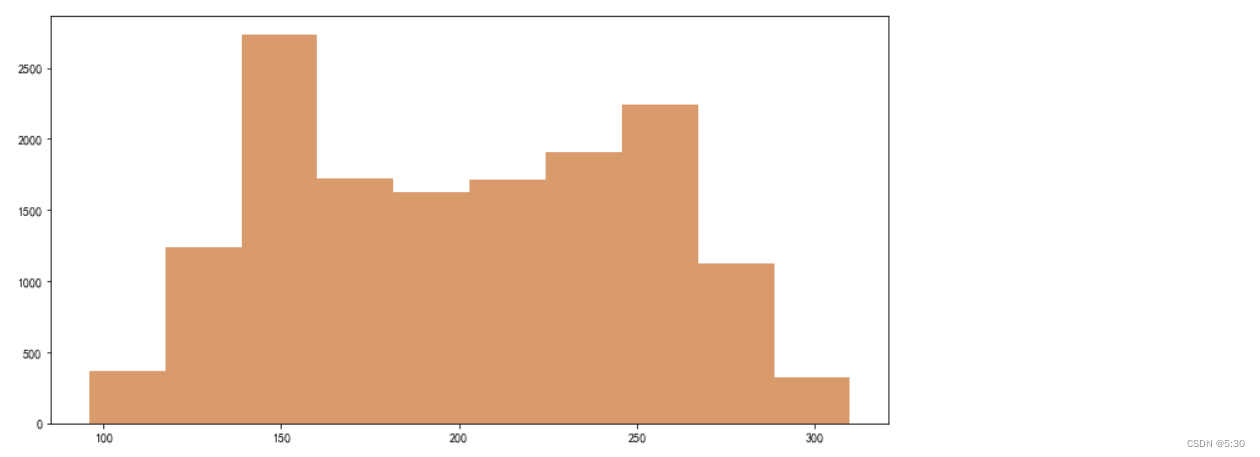
工作时长
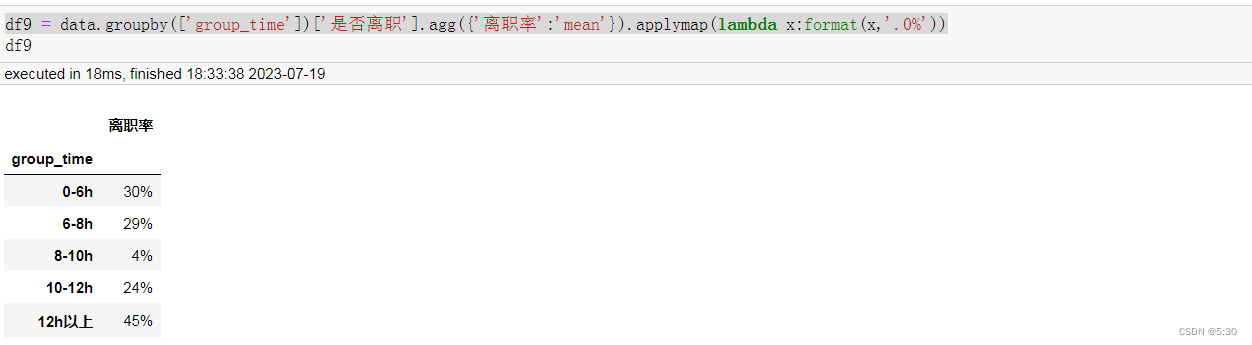
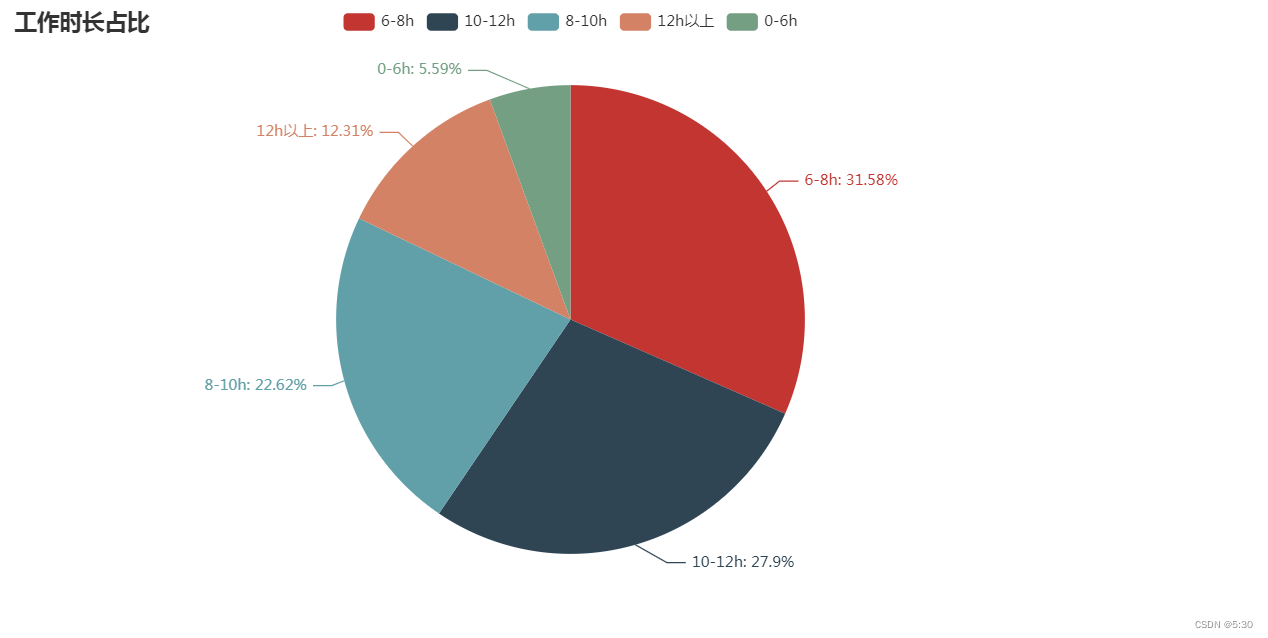
主要分布还是每天工作6-8小时,12小时以上的离职率最高
plt.figure(figsize=(12, 6))
plt.hist(data['每月平均工作时长'],color='#D99A6C')
plt.show()
# 对工作时长进行分层,按每天6/8/10/12小时进行划分,(132/176/220/264)/月
bins = [0,132,176,220,264,np.inf] # 定义分组区间
labels = ['0-6h','6-8h','8-10h','10-12h','12h以上'] # 定义标识值
data['group_time'] = pd.cut(data['每月平均工作时长'],bins=bins, labels=labels,right=False)
df9 = data.groupby(['group_time'])['是否离职'].agg({'离职率':'mean'}).applymap(lambda x:format(x,'.0%'))
x = data['group_time'].value_counts().index.tolist()
y = data['group_time'].value_counts().values.tolist()
pie = (
Pie()
.add("", [z for z in zip(x, y)],)
.set_global_opts(title_opts=opts.TitleOpts(title="工作时长占比"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
pie.render_notebook()
总结
综合分析显示,离职员工呈现以下主要特征:
- 绩效水平较高,这是因为离职员工承担了更多的项目和较长的工作时间,然而即便绩效较好,公司回报不足成为离职的问题所在。
- 薪资普遍处于中低水平、在职主要集中在3-5年、晋升机会有限。
- 员工离职率较高的职位主要包括销售和技术领域。
综上所述,公司在员工为其创造价值时(项目繁多),应及时给予奖励(例如项目奖金)或者反馈(升职机会),特别是在职业生涯关键阶段(3-5年)内,应给予员工更多资源,让他们感受到对公司的贡献和价值,从而提高满意度和归属感,减少人才流失。在提供适当的薪资和晋升机会的同时,也要重视员工的综合发展,使他们在公司中实现个人价值,从而建立更紧密的员工与公司的联系。