文章列表
1.机器学习方法原理及编程实现–01.K近邻法(实现MNIST数据分类).
2.机器学习方法原理及编程实现–02.决策树.
3.机器学习方法原理及编程实现–03.朴素贝叶斯分类器(实现MNIST数据分类) .
4.机器学习方法原理及编程实现–04.支持向量机 .
5.机器学习方法原理及编程实现–05.提升方法..
6.机器学习方法原理及编程实现–01..
…
首先认识一下3个概念:
1.强可学习:在概率近似正确问题中,如果存在一个多项式的学习算法能够学习它,并且准确率很高。
2.弱可学习:在概率近似正确问题中,如果存在一个多项式的学习算法能够学习它,并且准确率只比随机猜测要好。
3.在概率近似正确问题中,强可学习与弱可学习是等价的。
不难知道,弱可学习方法是比较好得到的,而强可学习方法不好得到,但是弱可学习与强可学习是等价的。提升方法就是用多个弱分类器的线性组合来构建一个强分类器,从而将弱学习算法提升为强学习算法的统计学习方法,可简单理解为3个臭皮匠胜过诸葛亮。
根据个体学习器的生成方式,提升方法大致可分为两大类:一是个体学习器间不存在强依赖关系、必须串行化生成的序列化方法,比如AdaBoost、提升树;还有课同时生成的并行化方法,比如bagging和随机森林(random forest)。
5.1 Bagging和Boosting的概念与区别
集成学习分为bagging和boosting
5.1.1 Bagging(套袋法)
bagging的算法过程如下:
从原始样本集中使用Bootstraping方法随机抽取n个训练样本,共进行k轮抽取,得到k个训练集。(k个训练集之间相互独立,元素可以有重复)
对于k个训练集,我们训练k个模型(这k个模型可以根据具体问题而定,比如决策树,knn等)
对于分类问题:由投票表决产生分类结果;对于回归问题:由k个模型预测结果的均值作为最后预测结果。(所有模型的重要性相同)
5.1.2 Boosting(提升法)
boosting的算法过程如下:
对于训练集中的每个样本建立权值wi,表示对每个样本的关注度。当某个样本被误分类的概率很高时,需要加大对该样本的权值。
进行迭代的过程中,每一步迭代都是一个弱分类器。我们需要用某种策略将其组合,作为最终模型。(例如AdaBoost给每个弱分类器一个权值,将其线性组合最为最终分类器。误差越小的弱分类器,权值越大)
5.1.3 Bagging,Boosting的主要区别
样本选择上:Bagging采用的是Bootstrap随机有放回抽样;而Boosting每一轮的训练集是不变的,改变的只是每一个样本的权重。
样本权重:Bagging使用的是均匀取样,每个样本权重相等;Boosting根据错误率调整样本权重,错误率越大的样本权重越大。
预测函数:Bagging所有的预测函数的权重相等;Boosting中误差越小的预测函数其权重越大。
并行计算:Bagging各个预测函数可以并行生成;Boosting各个预测函数必须按顺序迭代生成。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
5.2 串行化生成的序列化方法
5.2.1 AdaBoost算法
用多个弱分类器和多个实例来构建一个强分类器。AdaBoost是adaptive boosting(自适应boosting)的缩写,可认为AdaBoost是模型为加法模型、损失函数为指数函数、学习算法为前向分步算法时的二分类学习方法。为什么这么说呢,由于AdaBoost算法中的分类模型是多个基本分类器的线性组合,所以学习的模型是加法模型。在给定训练数据且损失函数为指数函数的条件下,利用前向分步算法的思想,每步只学一个基函数及其系数,并更新训练数据集的权重分布(权重更新方式是由指数损失函数决定的),逐步逼近优化目标。
上面给出了AdaBoost算法概述及由来,下面对其由来过程进行详细推导。首先将AdaBoost的学习模型定义为:
式中 , 为基函数, 为基函数的系数。对给定训练数据集T={(x1,y1), (x2,y2),…, (xN,yN)},xi∈Rn,yi∈{1,-1},令损失函数为 ,但该损失函数的导数不好求导,因此将损失函数改为 但即便这样,直接求解最小化损失函数的最优解仍有困难, 因为我们不知道基函数的参数及其系数,也不知道取多少个基函数才合适。而 前向分步算法可以有效的解决这个问题,引入前向分步算法后,每步仅需要求解单个基函数的参数及其系数,不用关注基函数的个数,基函数的个数由前向分步算法的步数来决定,我们会不断的求解新的单个基函数的参数及其系数,直到学习模型在训练数据集上的误差满足指定阈值。下面描述单步求解基函数参数及其系数的方法。假设经过了m-1步前向计算得到了加法模型:
那么当前的目标是求得使得损失函数最小最小的基函数及其系数:
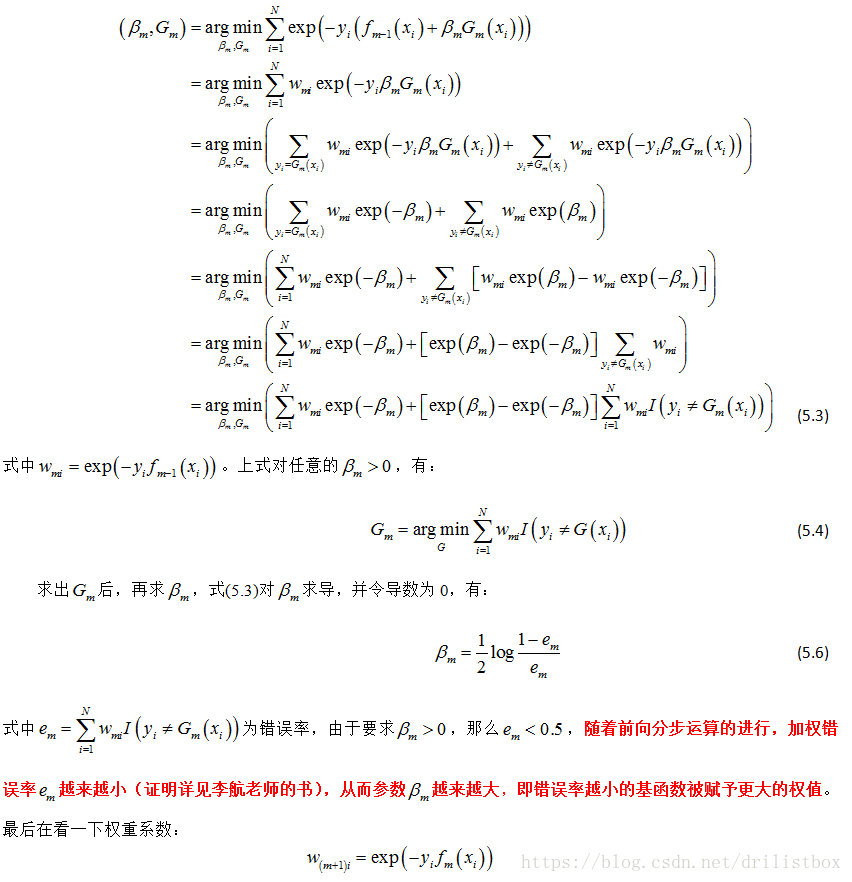

5.2.2 AdaBoost编程实现
算法流程:
Do
{
1.初始化误差权值分布(均匀分布)
2.从所有可选弱分类器中,选出错误率最低的分类器G,并算出误差率e及基函数系数alpha
3.if e>0.5: continue
3.更新权重系数
}
while(分类器sign(f(x))在数据集上误分类点数>阈值)
决策树桩
下面程序实现了李航老师统计信息方法例8.1
import numpy as np
import math
x = np.array(range(10))
y = np.array([[1,1,1,-1,-1,-1,1,1,1,-1]])
inputData = np.vstack((x,y))
weight = 0.1*np.ones(y.shape)
E = lambda x,y: 1 if(x!=y) else 0
sign = lambda x: 1 if(x>0) else -1
def adaBoost(inputData, weight, epsList):
G1 = lambda x,eps: 1 if(x<eps) else -1
G2 = lambda x,eps: -1 if(x<eps) else 1
# print(epsList)
emin = 1e5
for G in [G1,G2]:
for eps in epsList:
e0 = np.array([E(G(inputData[0,i],eps),inputData[1,i]) for i in range(inputData.shape[1])]).reshape([1,inputData.shape[1]])
e = (e0*weight).sum()
if(e<emin):
emin = e
epsmin = eps
GMin = G
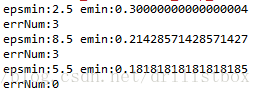
print('epsmin:%s emin:%s' %(epsmin, emin))
if(epsmin in epsList):
epsList.remove(epsmin)
else:
epsList
alpha = 0.5*math.log((1-emin)/emin)
weightNew = weight*np.exp(-alpha*inputData[1,:]*np.array([GMin(inputData[0,i],epsmin) for i in range(inputData.shape[1])]).reshape([1,10]))
weightNew = weightNew/weightNew.sum()
f = lambda x:GMin(x,epsmin)
return alpha, f, weightNew, emin, epsmin
epsList = np.arange(-0.5,11.5).tolist()
errNum = 135;
alphaList = []
fList = []
while(errNum>2):
alpha, f, weight, emin, epsmin = adaBoost(inputData, weight, epsList)
fList.append(f)
alphaList.append(alpha)
errNum = 0
for i in range(inputData.shape[1]):
out = 0.0
for ind in range(len(fList)):
out += alphaList[ind]*fList[ind](inputData[0,i])
if sign(out) != inputData[1,i]:
errNum += 1
print('errNum:%d' %(errNum))
5.2.3 提升树
以分类树或回归树为基本分类器的提升方法称为提升树(AdaBoost虽然也是正负1分类,但其基本分类器不限定于分类树或回归树),对分类问题决策树是二叉分类树;对回归问题的决策树是二叉回归树。提升树采用加法模型与前向分步算法来进行学习。不同问题的提升树的学习方法主要区别是损失函数的不同,回归问题采用的是平方误差损失函数;分类问题采用的是指数损失函数;一般决策问题采用的是一般损失函数。
5.2.3.1 分类问题的提升树方法
对于分类问题,提升树算法只需将上面讲述的AdaBoost算法中的计算分类器限制为二类分类树即可,可以说这时的分类提升树是AdaBoost算法的特殊情况。
5.2.3.2 回归问题的提升树方法
在给定训练数据集T={(x1,y1), (x2,y2),…, (xN,yN)},xi∈Rn为输入空间,yi为输出空间。如果将输入空间氛围J个互不重叠的区域R1、R2、…、RJ,J为回归树的复杂度即叶节点数,并且在每个给定区域上确定输出的常量cj。那么树可以表示为:

5.2.3.3 梯度提升
当损失函数是平方损失和指数损失是,每一步前向分步运算都很简单,但对一般损失函数而言,每一步优化并不容易,这时可引入梯度提升算法:利用损失函数对当前提升树的负梯度作为回归问题提升树算法中的残差近似。【为啥我也不懂^_^,后面在学吧】
5.3 同时生成的并行化方法
5.3.1 随机森林
随机森林是一种基于Bagging的集成学习方法,可用来分类、回归,它有许多优点:
具有极高的准确率
随机性的引入,使得随机森林不容易过拟合
随机性的引入,使得随机森林有很好的抗噪声能力
能处理很高维度的数据,并且不用做特征选择
既能处理离散型数据,也能处理连续型数据,数据集无需规范化
训练速度快,可以得到变量重要性排序
容易实现并行化
随机森林的缺点:
当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大
随机森林模型还有许多不好解释的地方,有点算个黑盒模型
与上面介绍的Bagging过程相似,随机森林的构建过程大致如下:
从原始训练集中使用Bootstraping方法随机有放回采样选出m个样本,共进行k次采样,生成k个训练集
对于k个训练集,我们分别训练k个决策树模型
对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/基尼指数选择最好的特征进行分裂
每棵树都一直这样分裂下去,直到该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝
将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果