文章列表
1.机器学习方法原理及编程实现–01.K近邻法(实现MNIST数据分类).
2.机器学习方法原理及编程实现–02.决策树(实现MNIST数据分类).
3.机器学习方法原理及编程实现–03.朴素贝叶斯分类器(实现MNIST数据分类) .
4.机器学习方法原理及编程实现–04.支持向量机(实现MNIST数据分类) .
5.机器学习方法原理及编程实现–01..
6.机器学习方法原理及编程实现–01..
…
支持矢量机知识谱系比较庞大,可分为3部分,我感觉学的时候还是比较费劲的。首先是支持矢量机理论的发展,SVM一种二分类分类模型,它的基本模型是定义在特征空间上的几何函数间隔最大的线性分类器,几何函数间隔最大使它有别于感知机,随后进一步引入松弛变量实现软间隔优化,引入核技巧实现非线性分类,以及进一步用间隔定量描述置信风险等。其次是凸优化理论部分,支持向量机的学习策略就是间隔最大化,利用拉格朗日函数可转化为一个凸二次优化的对偶问题,通过SMO实现快速求解。第三部分是核技巧部分,感觉学了暂时也用不上,我自己就直接跳过该部分了。
下面我们将从SVM理论模型的发展展开描述,中间穿插一些优化方法及核函数的知识。主要分3部分:
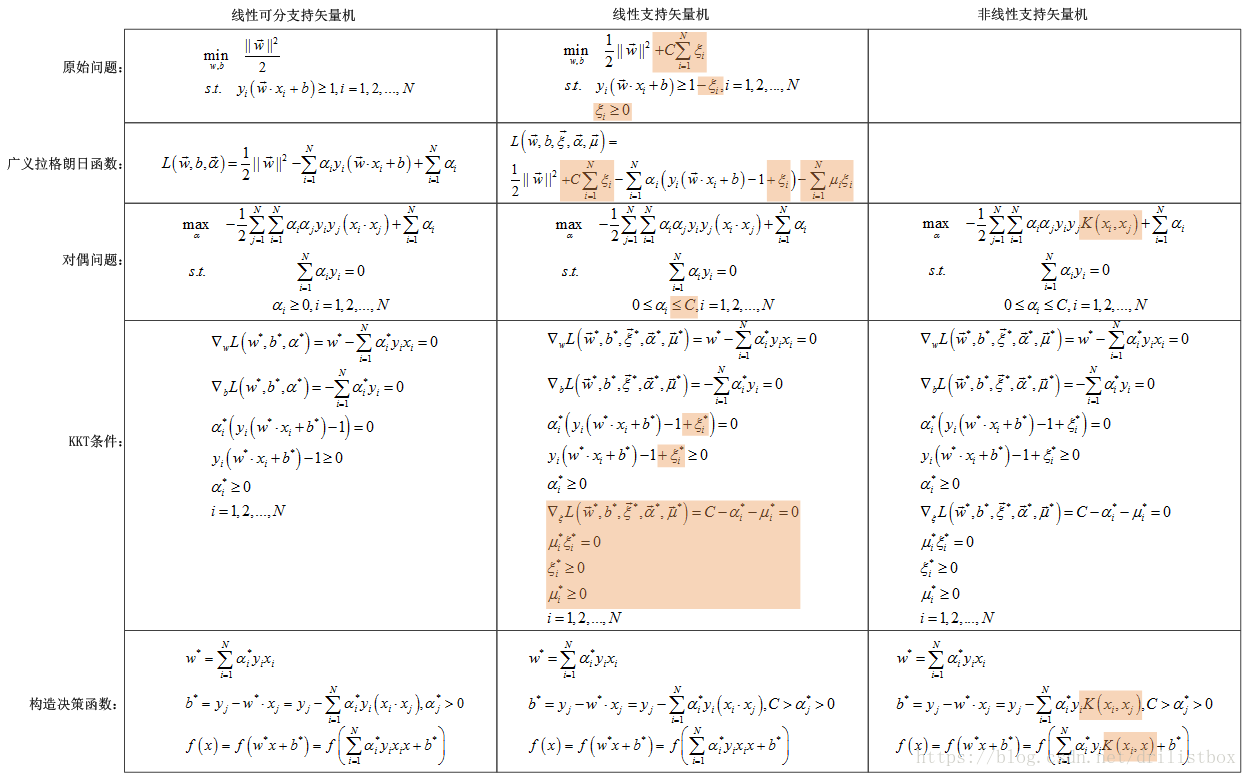
1线性可分支持向量机:针对训练数据线性可分问题,通过硬间隔最大化,学习一个线性的分类器,又称硬间隔支持向量机。
2线性支持向量机:针对训练数据近似线性可分问题,通过软间隔最大化,学习一个线性的分类器,又称软间隔支持向量机。
3非线性支持向量机:针对训练数据线性不可分问题,在核技巧及软间隔最大化的基础上,引入核技巧学习一个非线性的分类器。
对于线性可分或近似可分问题,输入空间与特征空间的元素一一对应,并将输入空间中的输入全等映射为特征空间中的特征向量;对于非线性可分问题,利用一个非线性映射将输入空间中的输入映射为特征空间中的特征向量,但这个过程是通过核技巧隐式实现的,不会被明显感受到。所以支持向量机的学习是在特征空间进行的。
在文章的最后我们会用2种SVM多分类方法实现MNIST数据分类:
一对一多分类方法生成45个SVM按投票表决生成预测输出,2000个训练数据就可以在10000个数据集上的准确率为96.1%
一对多多分类方法生成9个SVM按投票表决生成预测输出,2000个训练数据就可以在10000个数据集上的准确率为79.0%
可以看出SVM真的是一个很好的分类器,仅用2000个训练数据训练出的SVM模型在10000个测试数据集上可以获得96.1%的准确率。
4.1 线性可分支持矢量机(硬间隔支持向量机)
给定线性可分训练数据集,通过几何间隔最大化或等价地求解相应的凸二次规划问题学习得到的分离超平面为:
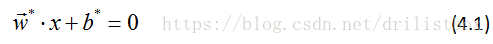
以及相应的分类决策函数
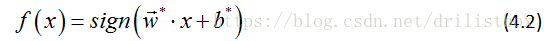
称为线性可分支持向量机。
在介绍为什么要用几何间隔最大化作为学习策略之前,我们先了解一下几何间隔和函数间隔的区别:对于给定的训练数据集T和超平面(w,b),定义超平面(w,b)关于样本点(xi,yi)的函数间隔为:
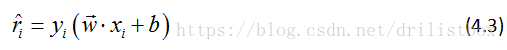
可见对于同一个超平面,如果线性的改变w和b,比如将它们改为2w和2b,超平面并没有改变,但函数间隔却变为原来的2倍,这启发我们对超平面法向量添加某些约束,如法向量除以||w||,使得间隔是确定的,这时的函数间隔变成了几何间隔。
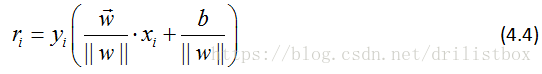
4.1.1 几何间隔最大化
几何间隔最大化的分离超平面求解可表示为如下的约束优化问题:

式中N为训练数据集总点数,用
代替
,上式可整理为:
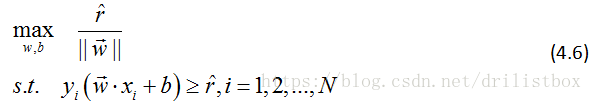
式中
为函数间隔,前面以及说过,函数间隔的取值对约束优化问题没有影响,于是不妨令
,此外最大化
和最小化
是等价的,于是约束优化问题可以进一步转化为:
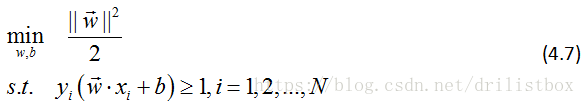
这是一个凸优化问题。
4.1.2 支持向量与间隔边界
在线性可分情况下,训练数据集中与分离超平面距离最近的样本点的实例称为支持向量,支持向量是使上式中约束条件等号成立的点。对 的点,支持向量在超平面 上,对 的点,支持向量在超平面 上,H1和H2称为间隔边界,在间隔边界的点就是支持向量。且H1和H2之间的间距为2/||w||。由于只有间隔边界上的点对分离超平面的解有影响,而间隔边界以外的点对分离超平面的解没有影响,称分离超平面上几个起决定性作用的点为支持向量。
4.1.3 学习的对偶算法


4.2 线性支持向量机(软间隔支持向量机)

4.2.1 学习的对偶算法



4.2.2 支持向量

4.3 非线性支持向量机
4.3.1 核技巧

4.3.2 为什么用核函数
在SVM中,针对对于线性不可分的情况下,可通过升维将输入数据映射到高维特征空间让数据变得线性可分。但这样可能导致维度爆炸,而核函数的引入,巧妙的避免了维度爆炸,核技巧避免了在高维度空间的计算,而只需要在低维度空间进行计算即可。那么核函数是如何进行升维操作的呢,首先看多项式核函数(polynomial kernel):

4.3.3 常用核函数

4.3.4 非线性支持向量机的学习算法

4.4 序列最小最优化算法
上面分析了3中矢量机的理论模型,将其主要学习算法归纳于下表中(表中高亮部分是与前一格不同的地方),可以清晰的看出3种方法的区别,其中非线性支持向量机最具有一般性,那么我们主要分析非线性支持矢量机的求解方法。

4.4.1 选择变量的启发式方法
4.4.1.1 第1个变量的选择

4.4.1.2 第2个变量的选择


4.4.2 计算阈值b
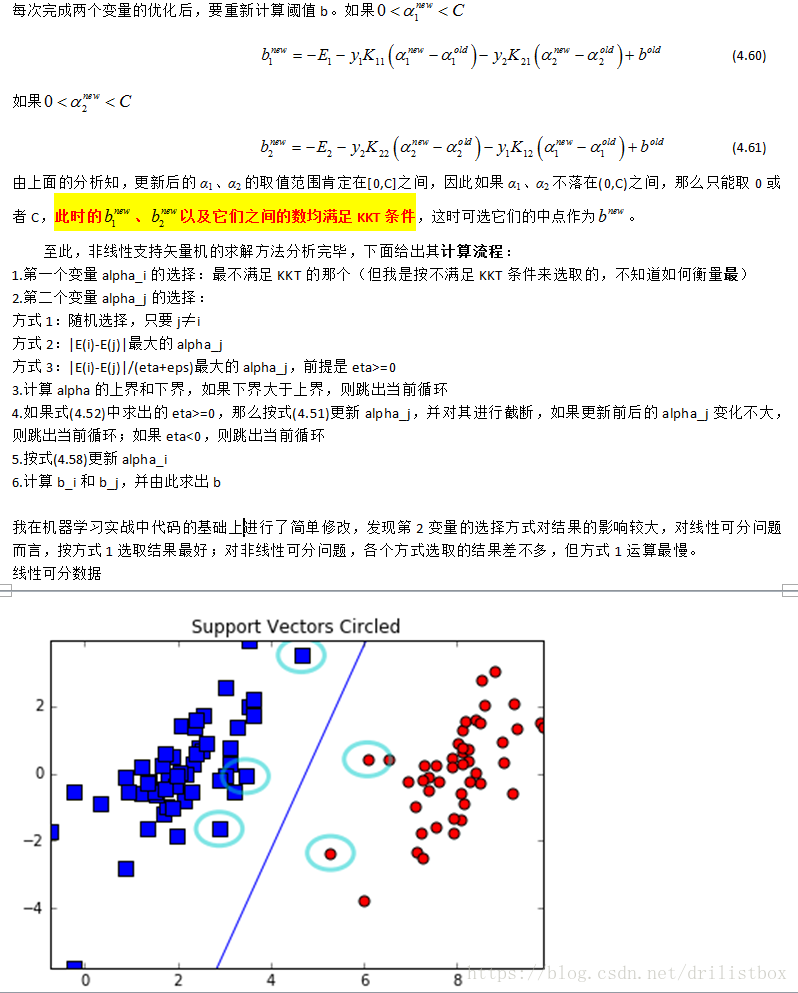
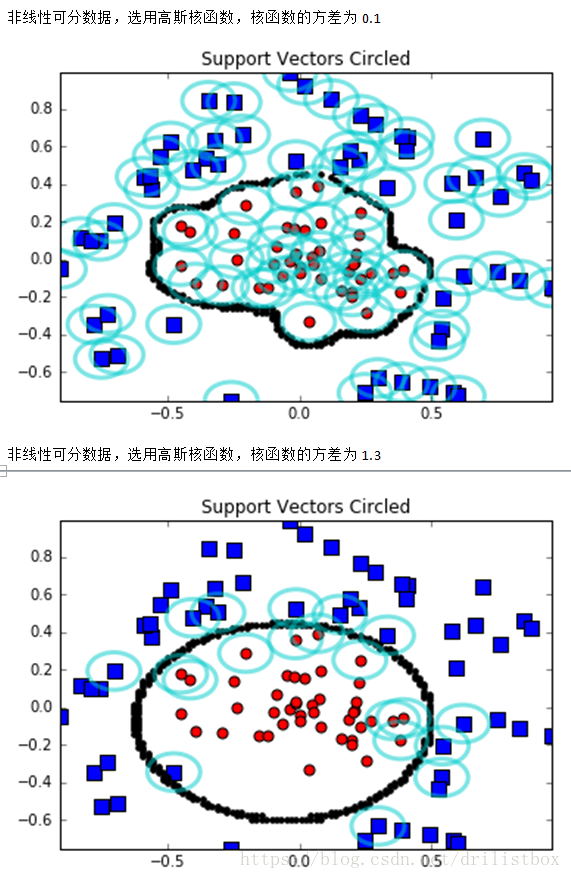
下面给出了上面二维数据分类的实现
from numpy import *
from time import sleep
from imp import reload
import sys
sys.path.append("./EXTRAS/")
import plotSupportVectors
reload(plotSupportVectors)
from plotSupportVectors import plotSV, plotSV2
import numpy as np
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def calcE(i, alphas, labelMat, dataMatrix, b, K):
return float(multiply(alphas,labelMat).T*(K[:,i])) + b - float(labelMat[i])
def kernelTrans(X, A, kTup): #calc the kernel or transform data to a higher dimensional space
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #linear kernel
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
else: raise NameError('kTup输入错误')
return K
def smoSimple(dataMatIn, classLabels, C, toler, maxIter, K):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
validAlpha = mat(zeros((m,1)))
E = mat(zeros((m,2)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
E[i,1] = calcE(i, alphas, labelMat, dataMatrix, b, K)
E[i,0] = 1
#选择第1个变量,要求不满足KKT条件
if validAlpha[i]== 0 or (\
(((alphas[i] > 0) and (alphas[i] < C)) and ((labelMat[i]*E[i,1] > toler) or (labelMat[i]*E[i,1] < -toler))) or\
((alphas[i] == 0) and (labelMat[i]*E[i,1] < -toler)) or ((alphas[i] == C) and (labelMat[i]*E[i,1] > toler))):
#选择第1个变量,要求不满足KKT条件
# if validAlpha[i]== 0 or (\
# (((alphas[i] > 0) and (alphas[i] < C)) and ((labelMat[i]*E[i,1] > toler) or (labelMat[i]*E[i,1] < -toler)))):
validAlpha[i] == 1
# #选择第2个变量,随机
j = selectJrand(i,m)
# 选择第2个变量,要求|Ei-Ej|最大
# if(len(nonzero(alphas[:,0]>0)[0])>=2):
# maxInd = -1
# maxEeer = -1e9
# for ind in nonzero(E[:,0]>0)[0].tolist():
# if(ind != i):
# if(abs(E[i,1] - E[ind,1])>maxEeer):
# maxInd = ind
# maxEeer = abs(E[i,1] - E[ind,1])
# j = maxInd
# else:
# j = selectJrand(i,m)
# 选择第2个变量,要求|(Ei-Ej)/eta|最大
# if(len(nonzero(alphas[:,0]>0)[0])>=2):
# maxInd = -1
# maxEeer = -1e9
# for ind in nonzero(E[:,0]>0)[0].tolist():
# if(ind != i):
# eta = 2.0 * K[i,ind] - K[i,i] - K[ind,ind]
# if eta >= -1e-3: print("eta>=0"); continue
# Eeer = abs((E[i,1] - E[ind,1])/(eta + 1e-3))
# if(Eeer>maxEeer):
# maxInd = ind
# maxEeer = Eeer
# j = maxInd
# else:
# j = selectJrand(i,m)
E[j,1] = calcE(j, alphas, labelMat, dataMatrix, b, K)
E[j,0] = 1
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
#计算alpha的阈值
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L>H: continue;#print("L>H");
eta = 2.0 * K[i,j] - K[i,i] - K[j,j]
if eta >= 0: print("eta>=0"); continue
#更新 alpha1,alpha2
alphas[j] -= labelMat[j]*(E[i,1] - E[j,1])/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
#更新 b
b1 = b - E[i,1]- labelMat[i]*(alphas[i]-alphaIold)*K[i,i] - labelMat[j]*(alphas[j]-alphaJold)*K[i,j]
b2 = b - E[j,1]- labelMat[i]*(alphas[i]-alphaIold)*K[i,j] - labelMat[j]*(alphas[j]-alphaJold)*K[j,j]
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print((E[:,1])[alphas>0])
return b,alphas
def calcWs(alphas,dataArr,classLabels):
X = mat(dataArr); labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i],X[i,:].T)
return w
#if __name__ == '__main__':
# dataArr,labelArr = loadDataSet('testSet.txt')
# m = len(labelArr)
# K = mat(zeros((m, m)))
# kTup = ('lin', 0)
# for i in range(m):
# K[:,i] = kernelTrans(mat(dataArr), (mat(dataArr))[i,:], kTup)
# b, alphas = smoSimple(dataArr,labelArr, 1.0, 1e-3, 30, K)
# print('b:',b)
# print('alphas:',alphas[alphas>0])
# sv = []
# for i in range(alphas.shape[0]):
# if(alphas[i]>0): sv.append(dataArr[i])
# plotSV('testSet.txt', np.array(sv), calcWs(alphas,dataArr,labelArr), b)
if __name__ == '__main__':
dataArr,labelArr = loadDataSet('testSetRBF.txt')
m = len(labelArr)
K = mat(zeros((m, m)))
# ki = 1.30
ki = 0.1
kTup = ('rbf', ki)
for i in range(m):
K[:,i] = kernelTrans(mat(dataArr), (mat(dataArr))[i,:], kTup)
b, alphas = smoSimple(dataArr,labelArr, 10.0, 1e-3, 10, K)
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd] #get matrix of only support vectors
labelSV = labelMat[svInd];
print("there are %d Support Vectors" % shape(sVs)[0])
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print("the training error rate is: %f" % (float(errorCount)/m))
dim = 100
# svArr = datMat[nonzero(alphas.A>0)[0]]
svArr = datMat
minx = min(mat(svArr)[:,0])[0,0]
maxx = max(mat(svArr)[:,0])[0,0]
x = np.arange(minx,maxx,(maxx-minx)/dim)
miny = min(mat(svArr)[:,1])[0,0]
maxy = max(mat(svArr)[:,1])[0,0]
y = np.arange(miny,maxy,(maxy-miny)/dim)
datMat = mat(zeros((dim*dim,2)))
for i in range(dim):
for j in range(dim):
datMat[i*dim+j,:] = [x[i],y[j]]
m,n = shape(datMat)
splitind = []
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', ki))
pred=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if(abs(pred)<0.1): splitind.append(i);#print(pred)
sv = []
for i in range(alphas.shape[0]):
if(alphas[i]>0): sv.append(dataArr[i])
plotSV2('testSetRBF.txt', np.array(sv), calcWs(alphas,dataArr,labelArr), b, datMat[splitind,:])4.5 SVM多分类方法的实现
【转自https://www.cnblogs.com/CheeseZH/p/5265959.html】
SVM本身是一个二值分类器,最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。目前,构造SVM多类分类器的方法主要有两类
4.5.1 直接法
直接在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类。这种方法看似简单,但其计算复杂度比较高,实现起来比较困难,只适合用于小型问题中;
4.5.2 间接法
主要是通过组合多个二分类器来实现多分类器的构造,常见的方法有one-against-one和one-against-all两种。
4.5.2.1 一对多法(one-versus-rest,简称OVR SVMs)
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
假如我有四类要划分(也就是4个Label),他们是A、B、C、D。
于是我在抽取训练集的时候,分别抽取
(1)A所对应的向量作为正集,B,C,D所对应的向量作为负集;
(2)B所对应的向量作为正集,A,C,D所对应的向量作为负集;
(3)C所对应的向量作为正集,A,B,D所对应的向量作为负集;
(4)D所对应的向量作为正集,A,B,C所对应的向量作为负集;
使用这四个训练集分别进行训练,然后的得到四个训练结果文件。
在测试的时候,把对应的测试向量分别利用这四个训练结果文件进行测试。
最后每个测试都有一个结果f1(x),f2(x),f3(x),f4(x)。
于是最终的结果便是这四个值中最大的一个作为分类结果。
评价:
这种方法有种缺陷,因为训练集是1:M,这种情况下存在biased.因而不是很实用。可以在抽取数据集的时候,从完整的负集中再抽取三分之一作为训练负集。
4.5.2.2 一对一法(one-versus-one,简称OVO SVMs或者pairwise)
其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。
当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。
Libsvm中的多类分类就是根据这个方法实现的。
假设有四类A,B,C,D四类。在训练的时候我选择A,B; A,C; A,D; B,C; B,D;C,D所对应的向量作为训练集,然后得到六个训练结果,在测试的时候,把对应的向量分别对六个结果进行测试,然后采取投票形式,最后得到一组结果。
投票是这样的:
A=B=C=D=0;
(A,B)-classifier 如果是A win,则A=A+1;otherwise,B=B+1;
(A,C)-classifier 如果是A win,则A=A+1;otherwise, C=C+1;
…
(C,D)-classifier 如果是A win,则C=C+1;otherwise,D=D+1;
The decision is the Max(A,B,C,D)
评价:这种方法虽然好,但是当类别很多的时候,model的个数是n*(n-1)/2,代价还是相当大的。
4.5.2.3 层次支持向量机
层次分类法首先将所有类别分成两个子类,再将子类进一步划分成两个次级子类,如此循环,直到得到一个单独的类别为止。对层次支持向量机的详细说明可以参考论文《支持向量机在多类分类问题中的推广》(刘志刚,计算机工程与应用,2004)
4.5.2.4 一对一多分类法对MNIST数据进行分类
我后来尝试用SVM一对一多分类法对MNIST数据进行分类,仅用2000个训练数据就可以在10000个测试数据上获得96.1%的准确率。怪不得以前SVM这么火,比lenet强多了。
下面给出一对一多分类法对MNIST数据进行分类的程序实现:【用svm_ MNIST.py算出不同1对1模型下的预测分类,然后再用acc_1to1.py对所有预测结果投票选出出现次数最多的标签】
svm_MNIST.py
from numpy import *
from time import sleep
from imp import reload
import sys
sys.path.append("./EXTRAS/")
import plotSupportVectors
reload(plotSupportVectors)
from plotSupportVectors import plotSV, plotSV2
import numpy as np
sys.path.append("./../../Basic/")
import LoadData as ld
import time
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1]), float(lineArr[2])])
labelMat.append(float(lineArr[3]))
return dataMat,labelMat
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def calcE(i, alphas, labelMat, dataMatrix, b, K):
return float(multiply(alphas,labelMat).T*(K[:,i])) + b - float(labelMat[i])
def kernelTrans(X, A, kTup): #calc the kernel or transform data to a higher dimensional space
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #linear kernel
elif kTup[0]=='rbf':
# for j in range(m):
# deltaRow = X[j,:] - A
# K[j] = deltaRow*deltaRow.T
K = np.mat(sum(np.array(X - A)**2,1).reshape(1,m))
# K = np.mat(sum(np.array(X - A)**2,1).reshape(m,1))
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
# print('K', min(min(K)), ' ',K[0,1], ' ',K[0,2], ' ',K[0,3], ' ',K[0,4])
else: raise NameError('kTup输入错误')
return K
def smoSimple(dataMatIn, classLabels, C, toler, maxIter, kTup):
time1 = time.time()
m = len(trainLabels)
K = mat(zeros((m, m)))
for i in range(m):
# if(i%(int(m/200)) == 0):print("核函数计算进度", 100.0*i/m, '%')
print("核函数计算进度", i, '/', m)
K[i,:] = kernelTrans(mat(trainDataSet), (mat(trainDataSet))[i,:], kTup)
time2 = time.time()
print("核函数计算耗时:", time2 - time1, 's')
print(K[1,1])
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
validAlpha = mat(zeros((m,1)))
E = mat(zeros((m,2)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
# print('__iter:',iter)
for i in range(m):
if(i%200 == 0): print('__iter:',iter,'alphaPairsChanged:',alphaPairsChanged,'__i:',i)
E[i,1] = calcE(i, alphas, labelMat, dataMatrix, b, K)
E[i,0] = 1
#选择第1个变量,要求不满足KKT条件
if validAlpha[i]== 0 or (\
(((alphas[i] > 0) and (alphas[i] < C)) and ((labelMat[i]*E[i,1] > toler) or (labelMat[i]*E[i,1] < -toler))) or\
((alphas[i] == 0) and (labelMat[i]*E[i,1] < -toler)) or ((alphas[i] == C) and (labelMat[i]*E[i,1] > toler))):
#选择第1个变量,要求不满足KKT条件
# if validAlpha[i]== 0 or (\
# (((alphas[i] > 0) and (alphas[i] < C)) and ((labelMat[i]*E[i,1] > toler) or (labelMat[i]*E[i,1] < -toler)))):
validAlpha[i] == 1
# #选择第2个变量,随机
j = selectJrand(i,m)
# 选择第2个变量,要求|Ei-Ej|最大
# if(len(nonzero(alphas[:,0]>0)[0])>=2):
# maxInd = -1
# maxEeer = -1e9
# for ind in nonzero(E[:,0]>0)[0].tolist():
# if(ind != i):
# if(abs(E[i,1] - E[ind,1])>maxEeer):
# maxInd = ind
# maxEeer = abs(E[i,1] - E[ind,1])
# j = maxInd
# else:
# j = selectJrand(i,m)
# 选择第2个变量,要求|(Ei-Ej)/eta|最大
# if(len(nonzero(alphas[:,0]>0)[0])>=2):
# maxInd = -1
# maxEeer = -1e9
# for ind in nonzero(E[:,0]>0)[0].tolist():
# if(ind != i):
# eta = 2.0 * K[i,ind] - K[i,i] - K[ind,ind]
# if eta >= -1e-3: print("eta>=0"); continue
# Eeer = abs((E[i,1] - E[ind,1])/(eta + 1e-3))
# if(Eeer>maxEeer):
# maxInd = ind
# maxEeer = Eeer
# j = maxInd
# else:
# j = selectJrand(i,m)
E[j,1] = calcE(j, alphas, labelMat, dataMatrix, b, K)
E[j,0] = 1
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
#计算alpha的阈值
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L>H: continue;#print("L>H");
eta = 2.0 * K[i,j] - K[i,i] - K[j,j]
if eta >= 0: print("eta>=0"); continue
#更新 alpha1,alpha2
alphas[j] -= labelMat[j]*(E[i,1] - E[j,1])/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
#更新 b
b1 = b - E[i,1]- labelMat[i]*(alphas[i]-alphaIold)*K[i,i] - labelMat[j]*(alphas[j]-alphaJold)*K[i,j]
b2 = b - E[j,1]- labelMat[i]*(alphas[i]-alphaIold)*K[i,j] - labelMat[j]*(alphas[j]-alphaJold)*K[j,j]
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
# print('(E[:,1])[alphas>0]',(E[:,1])[alphas>0])
# print('alphas[alphas>0]',alphas[alphas>0])
return b,alphas
def calcWs(alphas,dataArr,classLabels):
X = mat(dataArr); labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i],X[i,:].T)
return w
#if __name__ == '__main__':
# dataArr,labelArr = loadDataSet('testSet.txt')
# m = len(labelArr)
# K = mat(zeros((m, m)))
# kTup = ('lin', 0)
# for i in range(m):
# K[:,i] = kernelTrans(mat(dataArr), (mat(dataArr))[i,:], kTup)
# b, alphas = smoSimple(dataArr,labelArr, 1.0, 1e-3, 30, K)
# print('b:',b)
# print('alphas:',alphas[alphas>0])
# sv = []
# for i in range(alphas.shape[0]):
# if(alphas[i]>0): sv.append(dataArr[i])
# plotSV('testSet.txt', np.array(sv), calcWs(alphas,dataArr,labelArr), b)
def accuracy(dataArr, labelArr, alphas, b, sVs, labelSV, kTup):
datMat=mat(dataArr)
# svInd=nonzero(alphas.A>0)[0]
# sVs=datMat[svInd] #get matrix of only support vectors
# labelSV = labelMat[svInd];
# print("there are %d Support Vectors" % shape(sVs)[0])
Wx_b = []
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
# print('sum=',sum(datMat[i,:]), '__kernelEval:', sum(kernelEval))
predict=kernelEval * multiply(labelSV,alphas[svInd]) + b
# predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
# print(' ',predict)
Wx_b.append(predict[0,0])
return (float(errorCount)/m, Wx_b)
if __name__ == '__main__':
labelInd = 0
# dataArr,labelArr = loadDataSet('testSetRBF.txt')
trainDataSet,trainLabels = loadDataSet('testSetRBF2.txt')
iTrainNum = 2000
iTestNum = 10000
# iTrainNum = 10000
# iTestNum = 10000
trainDataSet = ld.getImageDataSet('./../../MNISTDat/train-images-idx3-ubyte', iTrainNum, 1, 784)
trainDataSet = trainDataSet.tolist();
trainLabels = ld.getLabelDataSet('./../../MNISTDat/train-labels-idx1-ubyte', iTrainNum)
trainLabels[trainLabels!=labelInd]=-1
trainLabels[trainLabels==labelInd]=1
trainLabels = trainLabels.tolist()
print("read data finished")
time1 = time.time()
ki = 2300
# ki = 0.01
kTup = ('rbf', ki)
b, alphas = smoSimple(trainDataSet,trainLabels, 10.0, 1e-3, 1, kTup)
# b, alphas = smoSimple(trainDataSet,trainLabels, 0.2, 1e-3, 3, kTup)
svInd=nonzero(alphas.A>0)[0]
datMat=mat(trainDataSet); labelMat = mat(trainLabels).transpose()
sVs=datMat[svInd] #get matrix of only support vectors
labelSV = labelMat[svInd];
print("there are %d Support Vectors" % shape(sVs)[0])
acc, Wx_b = accuracy(trainDataSet, trainLabels, alphas, b, sVs, labelSV, kTup)
print("the training error rate is: %f" %(acc))
time2 = time.time()
print('training cost ',time2 - time1,' second','\n')
#测试数据
testDataSet = ld.getImageDataSet('./../../MNISTDat/t10k-images-idx3-ubyte', iTestNum, 1, 784)
testDataSet = testDataSet.tolist();
testLabels = ld.getLabelDataSet('./../../MNISTDat/t10k-labels-idx1-ubyte', iTestNum)
testLabels[testLabels!=labelInd]=-1
testLabels[testLabels==labelInd]=1
testLabels = testLabels.tolist()
time1 = time.time()
acc, Wx_b = accuracy(testDataSet, testLabels, alphas, b, sVs, labelSV, kTup)
print("the testing error rate is: %f" %(acc))
time2 = time.time()
print('testing cost ',time2 - time1,' second','\n')
np.savetxt('data/Wx_b%s.txt' % (labelInd), Wx_b, fmt='%1.4f')
# numpy.loadtxt('data/Wx_b1.txt')
acc_1to1.py
sys.path.append("./../../Basic/")
import LoadData as ld
import numpy as np
Num = 10000
acc = np.zeros((Num,45))
ind = 0
for i in range(10):
for j in range(i):
if(i != j):
acc[:,ind] = np.loadtxt('data/preLabel%s_%s.txt' % (j, i))
ind = ind + 1
testLabels = ld.getLabelDataSet('./../../MNISTDat/t10k-labels-idx1-ubyte', iTestNum)
preLabel = []
for i in range(Num):
temp = np.array(list(set(acc[i].tolist())))
maxNum = 0
for i in temp:
if(i == -1):continue
if(sum(temp == i)>maxNum):
maxNum = sum(temp == i)
preLabel_temp = i
preLabel.append(preLabel_temp)
acc = (np.array(preLabel) == np.array(testLabels).T)
print(sum(acc)/Num)