RMSprop
- 相较于gradient descent with momentum,RMSprop的思想是,对于梯度震动较大的项,在下降时,减小其下降速度;对于震动幅度小的项,在下降时,加速其下降速度。
- 通过使用指数加权平均计算得到
Sdw, Sdb
;使用他们来更新参数(如下图所示)
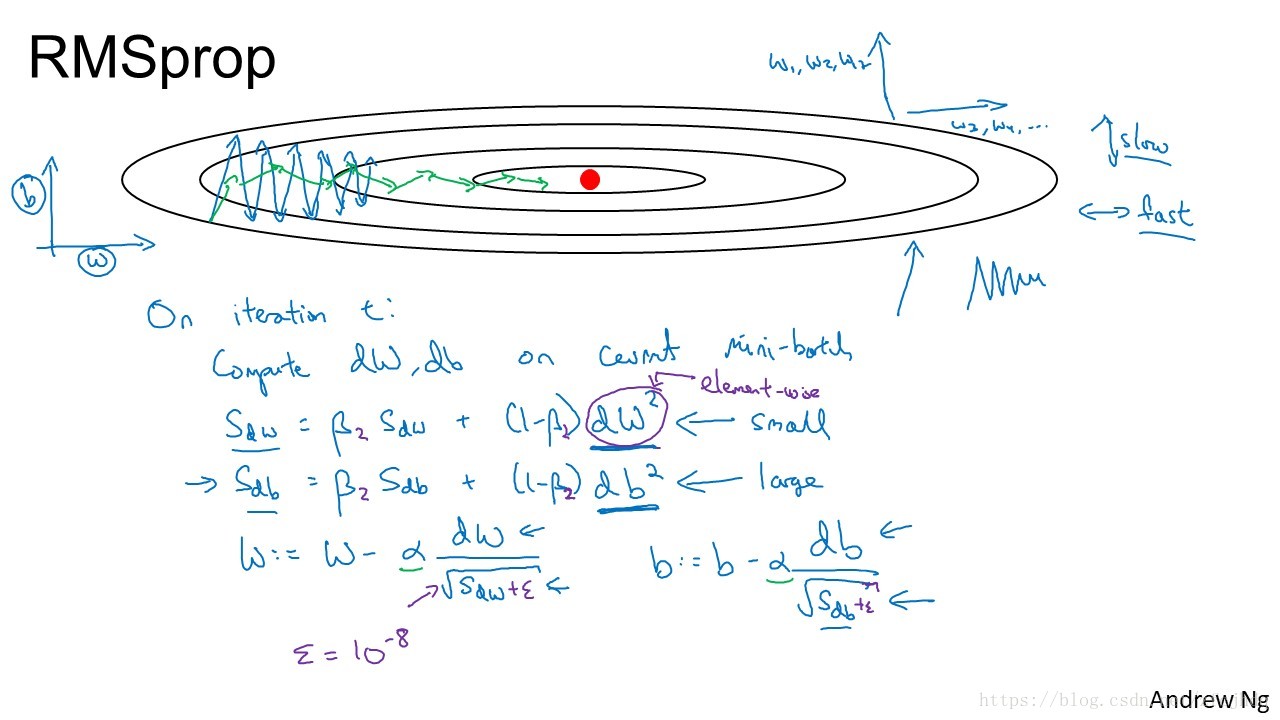
Sdw=βSdw+(1−β)dw2
Sdb=βSdb+(1−β)db2
w:=w−αdwSdw−−−√+ϵ
b:=b−αdbSdb−−−√+ϵ
-
ϵ=10−8
,是为了保证分母不为零;
dw2
和
db2
指的是element-wise