RMSProp算法
提出动机
在AdaGrad的每次迭代中,因为调整学习率时分母上的变量 s t s_t st一直在累加按元素平方的小批量随机梯度,所以目标函数自变量每个元素的学习率在迭代过程中一直在降低(或不变)。因此,如果AdaGrad算法没有在前期找到较优解,在迭代后期由于学习率过小更难趋近最优解。
RMSProp算法通过融合指数加权移动平均对这一点进行了改良。简单来说,RMSProp融合了动量法和AdaGrad的优点。
算法
对每次迭代做如下改动
s t = γ s t − 1 + ( 1 − γ ) g t ∘ g t x t = x t − 1 − η s t + ϵ ∘ g t s_t = \gamma s_{t-1} + (1-\gamma) g_t \circ g_t \\\\ x_t = x_{t-1} - \frac{\eta}{\sqrt{s_t+\epsilon}} \circ g_t st=γst−1+(1−γ)gt∘gtxt=xt−1−st+ϵη∘gt
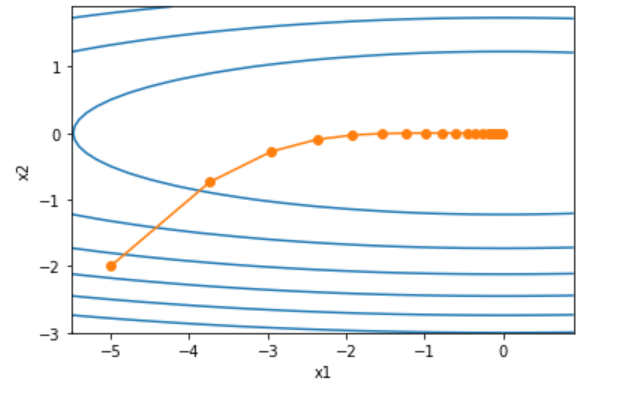
我们仍然用动量法中用来举例的目标函数观察迭代轨迹。
def rmsprop_2d(x1, x2, s1, s2, eta=0.4, eps=1e-6):
g1, g2 = 0.2 * x1, 4 * x2
s1 = gamma * s1 + (1 - gamma) * g1 ** 2
s2 = gamma * s2 + (1 - gamma) * g2 ** 2
x1 -= eta / math.sqrt(s1 + eps) * g1
x2 -= eta / math.sqrt(s2 + eps) * g2
return x1, x2, s1, s2
学习率为0.4的时候效果已经非常好了。
代码实现
def init_rmsprop_states(dim=2):
s_w = np.zeros((dim, 1))
s_b = np.zeros(1)
return (s_w, s_b)
def rmsprop(params, states, hyperparams, eps=1e-6):
gamma = hyperparams['gamma']
for p, s in zip(params, states):
s[:] = gamma * s + (1 - gamma) * p.grad * p.grad
p[:] -= hyperparams['lr'] * p.grad / math.sqrt(s + eps)