介绍
每年,约有760万个动物到达美国的动物收留所。 许多动物被他们的主人丢弃,而其它一部分是因为走失。 这些动物中的大多数都会找到永远的家庭并把它们带回家,但也有许多动物不那么幸运。 美国每年约有270万只狗和猫被安乐死。
使用奥斯汀动物中心的摄入信息数据集,包括品种,颜色,性别和年龄,我们要求Kagglers预测每只动物的结果。
我们也相信这个数据集可以帮助我们理解动物结果的趋势。 这些见解可以帮助避难所将精力集中在需要额外帮助寻找新家的特定动物身上。
这场比赛就是为了能够更准确的预测出每个动物的未来命运~~~
数据
下面来看下kaggle发布的训练数据吧:
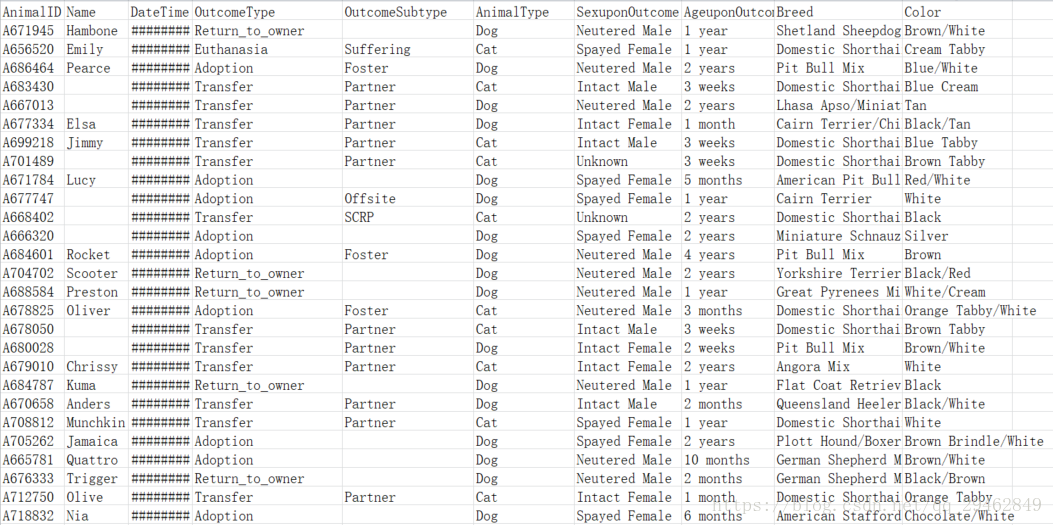
训练数据主要包括每个动物的ID以及品种、类型和颜色等。
下面是测试数据:
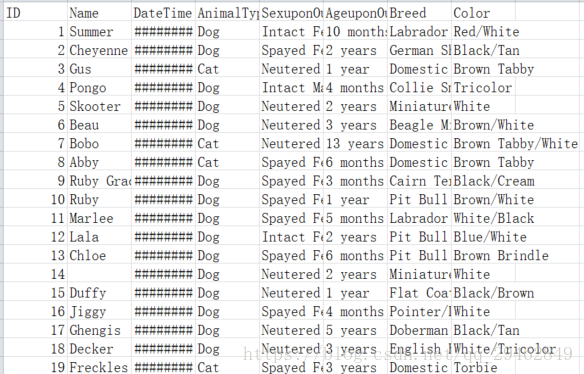
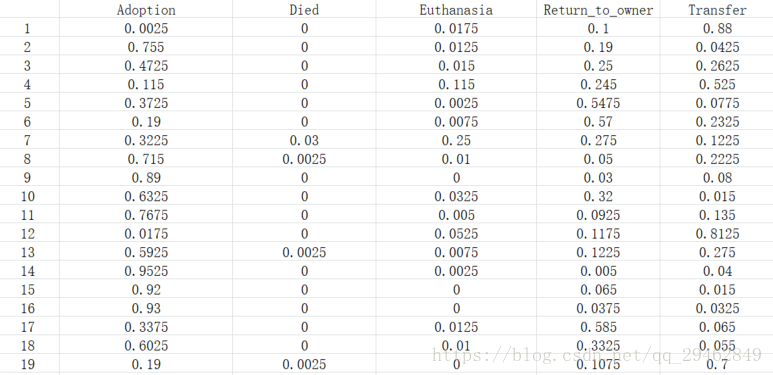
每个Animal ID都有五种可能的结果:收养,死,安乐死,Return_to_owner,转移。这是一个典型的多类分类问题。好了,不多说了,看代码吧(很清楚)~~~
代码
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
import sys
from datetime import datetime
def munge(data, train):
data['HasName'] = data['Name'].fillna(0)
data.loc[data['HasName'] != 0, "HasName"] = 1
data['HasName'] = data['HasName'].astype(int)
data['AnimalType'] = data['AnimalType'].map({'Cat': 0, 'Dog': 1})
if (train):
data.drop(['AnimalID', 'OutcomeSubtype'], axis=1, inplace=True)
data['OutcomeType'] = data['OutcomeType'].map(
{'Return_to_owner': 4, 'Euthanasia': 3, 'Adoption': 0, 'Transfer': 5, 'Died': 2})
gender = {'Neutered Male': 1, 'Spayed Female': 2, 'Intact Male': 3, 'Intact Female': 4, 'Unknown': 5, np.nan: 0}
data['SexuponOutcome'] = data['SexuponOutcome'].map(gender)
def agetodays(x):
try:
y = x.split()
except:
return None
if 'year' in y[1]:
return float(y[0]) * 365
elif 'month' in y[1]:
return float(y[0]) * (365 / 12)
elif 'week' in y[1]:
return float(y[0]) * 7
elif 'day' in y[1]:
return float(y[0])
data['AgeInDays'] = data['AgeuponOutcome'].map(agetodays)
data.loc[(data['AgeInDays'].isnull()), 'AgeInDays'] = data['AgeInDays'].median()
data['Year'] = data['DateTime'].str[:4].astype(int)
data['Month'] = data['DateTime'].str[5:7].astype(int)
data['Day'] = data['DateTime'].str[8:10].astype(int)
data['Hour'] = data['DateTime'].str[11:13].astype(int)
data['Minute'] = data['DateTime'].str[14:16].astype(int)
data['Name+Gender'] = data['HasName'] + data['SexuponOutcome']
data['Type+Gender'] = data['AnimalType'] + data['SexuponOutcome']
data['IsMix'] = data['Breed'].str.contains('mix', case=False).astype(int)
return data.drop(['AgeuponOutcome', 'Name', 'Breed', 'Color', 'DateTime'], axis=1)
def best_params(data):
rfc = RandomForestClassifier()
param_grid = {
'n_estimators': [50, 400],
'max_features': ['auto', 'sqrt', 'log2']
}
CV_rfc = GridSearchCV(estimator=rfc, param_grid=param_grid, cv=5)
CV_rfc.fit(data[0::, 1::], data[0::, 0])
return CV_rfc.best_params_
if __name__ == "__main__":
in_file_train = 'C:/Users/new/Desktop/data/train.csv'
in_file_test = 'C:/Users/new/Desktop/data/test.csv'
print("Loading data...\n")
pd_train = pd.read_csv(in_file_train)
pd_test = pd.read_csv(in_file_test)
print("Munging data...\n")
pd_train = munge(pd_train, True)
pd_test = munge(pd_test, False)
pd_test.drop('ID', inplace=True, axis=1)
train = pd_train.values
test = pd_test.values
print("Calculating best case params...\n")
print(best_params(train))
print("Predicting... \n")
forest = RandomForestClassifier(n_estimators=400, max_features='auto')
forest = forest.fit(train[0::, 1::], train[0::, 0])
predictions = forest.predict_proba(test)
output = pd.DataFrame(predictions, columns=['Adoption', 'Died', 'Euthanasia', 'Return_to_owner', 'Transfer'])
output.columns.names = ['ID']
output.index.names = ['ID']
output.index += 1
print("Writing predictions.csv\n")
print(output)
output.to_csv('C:/Users/new/Desktop/data/predictions.csv')
print("Done.\n")