项目总体目录
├── pytorch_dogsVScats
│ ├── datas
│ │ ├── Dataset
│ │ ├── train
│ │ │ ├── dog
│ │ │ └── cat
│ │ └── valid
│ │ ├── dog
│ │ └── cat
│ ├── data
│ │ └── dataset.py
│ │
│ ├── models
│ │ ├── VGG.py
│ │ └── AlexNet.py
│ │
│ ├── utils
│ │ └── get_mean_std.py
│ │
│ ├── config.py
│ ├── redistributionImgs.py
│ └── main.py
1. 数据集下载和预览
1.1 数据集下载
到Kaggle官网下载猫狗分类的数据集。该数据集的训练集共有25000张猫和狗的图片,测试集共有12500张猫和狗的图片。
在实验中,我们不会直接使用测试数据集对搭建的模型进行训练和优化,而是在训练数据集中划出 一部分作为验证集,来评估在每个批次的训练后模型的泛化能力。这样做的 原因是如果我们使用测试数据集进行模型训练和优化,那么模型最终会对测试数据集产生拟合倾向,换而言之,我们的模型只有在对测试数据集中图片的类别进行预测时才有极强 的准确率,而在对测试数据集以外的图片类别进行预测时会出现非常多的错误,这样的模型缺少泛化能力。所以,为了防止这种情况的出现,我们会把测试数据集从模型的训练和优化过程中隔离出来,只在每轮训练结束后使用。如果模型对验证数据集和测试数据集的 预测同时具备高准确率和l低损失值,就基本说明模型的参数优化是成功的 , 模型将具备极强的泛化能力。
新建项目名为pytorch_dogsVScats,并在项目根目录下创建如下所示的目录结构:
├── datas
│ ├── Dataset
│ ├── train
│ │ ├── dog
│ │ └── cat
│ └── valid
│ │ ├── dog
│ │ └── cat
datas为项目存放数据的根目录,将下载的所有图片共都放置到Dataset目录下,train和valid目录分别用于存储训练图片和验证图片,本次实验将训练集中20%的图片(猫狗分别2500张,共5000张)用来组成验证数据集。
新建redistributionImgs.py文件,编写redistributionImgs函数来将图片分别移动到相应的目录下。具体实现如下:
import os
import shutil
from config import Config
def redistributionImgs():
'''
redistributing all pictures(in './data/Dataset') to the corresponding directory
'''
print('Redistribution start...')
# 调用配置文件
conf = Config()
# 如果图片还未分配则进行分配
if not os.listdir(os.path.join(conf.data_train_root, 'cat/')):
# 返回所有图片的名字列表
file_datas = os.listdir(os.path.join(conf.data_root, 'Dataset/'))
# 使用filter()从有标签的25000张图片中过滤图片
# 使用匿名函数lambda处理筛选条件
# 返回标签为狗的图片
file_dogs = list(filter(lambda x: x[:3] == 'dog', file_datas))
# 返回标签为猫的图片
file_cats = list(filter(lambda x: x[:3] == 'cat', file_datas))
# 有标签的狗图和猫图的个数
d_len, c_len = len(file_dogs), len(file_cats)
# 80%的图片用于训练,20%的图片用于验证
val_d_len, val_c_len = d_len * 0.8, c_len * 0.8
# 分配狗图片
for i in range(d_len):
pre_path = os.path.join(conf.data_root, 'Dataset', file_dogs[i])
# 80%的数据作为训练数据集
if i < val_d_len:
new_path = os.path.join(conf.data_train_root, 'dog/')
# 20%的数据作为验证数据集
else:
new_path = os.path.join(conf.data_valid_root, 'dog/')
# 调用shutil.move()移动文件
shutil.move(pre_path, new_path)
# 分配猫图片
for i in range(c_len):
pre_path = os.path.join(conf.data_root, 'Dataset', file_cats[i])
# 80%的数据作为训练数据集
if i < val_c_len:
new_path = os.path.join(conf.data_train_root, 'cat/')
# 20%的数据作为验证数据集
else:
new_path = os.path.join(conf.data_valid_root, 'cat/')
# 调用shutil.move()移动文件
shutil.move(pre_path, new_path)
print('Redistribution completed!')
新建config.py文件用于配置实验中的经常使用变量。
class Config:
# 文件路径
# 数据集根目录
data_root = './datas/'
# 训练集存放路径
data_train_root = './datas/train/'
# 验证集存放路径
data_valid_root = './datas/valid/'
# 测试集存放路径
data_test_root = './datas/test/'
# 测试结果保存位置
result_file = './result.csv'
# 常用参数
# batch size
batch_size = 32
# mean and std
# 通过抽样计算得到图片的均值mean和标准差std
mean = [0.470, 0.431, 0.393]
std = [0.274, 0.263, 0.260]
# 预训练模型路径
path_vgg16 = './models/vgg16-397923af.pth'
get_mean_std用于计算原数据的均值和方差。
def get_mean_std(data_images):
'''
:param data_images: 加载好的数据集
:return: mean,std
'''
times, mean, std = 0, 0, 0
data_loader = {x: torch.utils.data.DataLoader(dataset=data_images[x],
batch_size=1000,
shuffle=True)
for x in ['train', 'valid']}
for imgs, labels in data_loader['train']:
# imgs.shape = torch.Size([32, 3, 64, 64])
times += 1
mean += np.mean(imgs.numpy(), axis=(0, 2, 3))
std += np.std(imgs.numpy(), axis=(0, 2, 3))
print('times:', times)
mean /= times
std /= times
return mean, std
1.2 数据加载和预览
在项目根目录下新建data目录,并在data目录下新建dataset.py文件,用于实现数据的加载。
在代码中对数据的变换和导入都使用了字典的形式,因为我们需要分别对训练数据集和验证数据集的数据载入方法进行简单定义,所以使用字典可以简化代码,也方便之后进行相应的调用和操作。
在加载完数据后,并对一个批次的数据进行预览。
dataset.py中的代码如下:
# 调用配置文件
conf = Config()
class Dataset:
def __init__(self, train=True):
# 图片预处理
# Compose用于将多个transfrom组合起来
# ToTensor()将像素从[0, 255]转换为[0, 1.0]
# Normalize()用均值和标准差对图像标准化处理 x'=(x-mean)/std,加速收敛
self.transform = transforms.Compose([transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(conf.mean, conf.std)])
self.train = train
# 加载训练数据集和验证数据集
if train:
# 数据加载
# 这里使用通用的ImageFolder和DataLoader数据加载器
# 数据类型 data_images = {'train': xxx, 'valid': xxx}
self.data_images = {x: datasets.ImageFolder(root=os.path.join(conf.data_root, x),
transform=self.transform)
for x in ['train', 'valid']}
self.data_images_loader = {x: torch.utils.data.DataLoader(dataset=self.data_images[x],
batch_size=conf.batch_size,
shuffle=True)
for x in ['train', 'valid']}
# 图片分类 ['cat', 'dog']
self.classes = self.data_images['train'].classes
# 图片分类键值对 {'cat': 0, 'dog': 1}
self.classes_index = self.data_images['train'].class_to_idx
# 加载测试数据集
else:
images = [os.path.join(conf.data_test_root, img) for img in os.listdir(conf.data_test_root)]
self.images = sorted(images, key=lambda x: int(x.split('.')[-2].split('/')[-1]))
# 重载专有方法__getitem__
def __getitem__(self, index):
img_path = self.images[index]
label = int(self.images[index].split('.')[-2].split('/')[-1])
data_images_test = Image.open(img_path)
data_images_test = self.transform(data_images_test)
return data_images_test, label
# 重载专有方法__len__
def __len__(self):
return len(self.images)
main.py中的代码:
from data.dataset import Dataset
dst = Dataset()
# 预览其中一个批次的数据
imgs, labels = iter(dst.data_images_loader['train']).next()
print(imgs.shape)
print(labels)
print(labels.shape)
打印结果:
torch.Size([32, 3, 224, 224])
tensor([0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0,
1, 0, 0, 1, 1, 0, 1, 0])
torch.Size([32])
imgs和labels都是Tensor数据类型的变量。因为我们对图片的大小进行了缩放变换,所以图片现在的大小都是64 × 64,因此imgs的维度就是(32, 3, 64, 64),32表示这个批次中有32张图片;3表示色彩通道数,因为原始图像是彩色的,因此使用了R、G、B三个通道;64表示图片的宽和高。
labels中的元素全部是0和1,因为在进行数据装载时已经对dog文件夹和cat文件夹下的内容进行了独热编码(One-Hot-Encoding),因此这时的0和1不仅是每张图片的标签,还分别对应猫的图片和狗的图片。这里做一个简单的打印输出,来验证这个独热编码的对应关系,代码如下:
classes_index = data_images['train'].class_to_idx
print(classes_index)
打印结果:
{'cat': 0, 'dog': 1}
相较于使用文字作为图片的标签而言,使用 0和l也可以让之后的计算方便很多。
为了增加之后绘制的图像标签的可识别性,将原始标签的结果存储在名为classes的变量中。
classes = data_images['train'].classes
print(classes)
输出结果:
['cat', 'dog']
使用opencv的cv2库来预览图片,代码如下:
# 图片预览
imgs, labels = iter(dst.data_images_loader['train']).next()
# 制作雪碧图
# 类型为tensor,维度为[channel, height, width]
img = torchvision.utils.make_grid(imgs)
# 转换为数组并调整维度为[height, width, channel]
img = img.numpy().transpose([1, 2, 0])
# 通过反向推导标准差交换法计算图片原来的像素值
mean, std = conf.mean, conf.std
img = img * std + mean
# 打印图片标签
print([dst.classes[i] for i in labels])
# 显示图片
cv2.imshow('img', img)
# 等待图片关闭
cv2.waitKey(0)
输出结果:
['cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'dog', 'dog', 'dog', 'dog', 'cat', 'cat', 'dog', 'dog', 'dog', 'cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'dog', 'cat', 'dog', 'dog', 'cat', 'dog', 'dog']
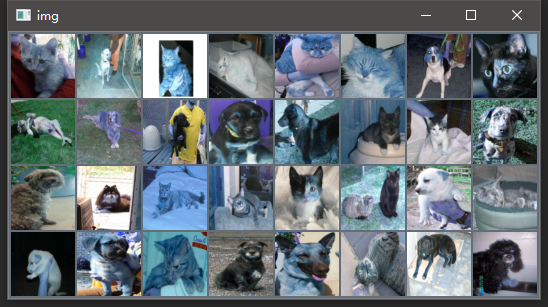
2. 搭建网络模型
我们开始搭建卷积神经网络模型,考虑到硬件环境和训练花费的时间成本,本次实验我们采用简化版的VGG-16网络模型。标准的VGG-16模型中要求的输入图片大小为224×224,模型中共有有13层卷积层和5层池化层。我们的模型将输入的图片大小全部缩放为64×64,同时删除了原模型最后的3个卷积层和池化层,并且改变了全连接层中的连接参数,原模型中全连接层的输入维度为7×7×512,因为我们的输入图片大小为64×64,因此通过计算得出的全连接层的输入维度为4×4×512。通过调整模型的大小和参数,大幅度减少了整个模型参与训练的参数数量。
简化后的VGG模型的代码如下:
import torch.nn as nn
# 需继承torch.nn.Module类
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
# 定义卷积层和池化层,共13层卷积,5层池化
self.conv = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
# nn.ReLU(),
# nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
# nn.ReLU(),
# nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
# nn.ReLU(),
# nn.MaxPool2d(kernel_size=2, stride=2),
)
# 简化版全连接层
self.classes = nn.Sequential(
nn.Linear(4 * 4 * 512, 1024),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1024, 1024),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1024, 2)
)
# VGG-16的全连接层
# self.classes = nn.Sequential(
# nn.Linear(7 *7 *512, 4096),
# nn.ReLU(),
# nn.Dropout(p=0.5),
# nn.Linear(4096, 4096),
# nn.ReLU(),
# nn.Dropout(p=0.5),
# nn.Linear(4096, 2)
# )
# 定义每次执行的计算步骤
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 4 * 4* 512)
x = self.classes(x)
return x
3. 模型训练
定义模型的损失函数和对参数进行优化的优化函数,这里损失函数采用交叉熵torch.nn.CrossEntropyLoss,优化函数采用torch.optim.Adam。代码如下:
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器,优化模型上的所有参数和学习率,默认lr=1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
将在模型训练的过程中需要计算的参数全部迁移至GPUs上,这个过程非常简单和方便,只需重新对这部分参数进行类型转换就可以了。但在启用GUPs前需要检查GPUs硬件是否可用,代码如下:
# 如果GPUs可用,则将模型上需要计算的所有参数复制到GPUs上
if torch.cuda.is_available():
model = model.cuda()
将需要计算的参数迁移至GPUs上,代码如下:
if torch.cuda.is_available():
X, y = X.cuda(), y.cuda()
main.py中的完整代码如下:
# 数据类实例
dst = Dataset()
# 模型类实例
model = VGG16()
# 配置类实例
conf = Config()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器,优化模型上的所有参数和学习率,默认lr=1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 定义超级参数
epoch_n = 10
# 如果GPUs可用,则将模型上需要计算的所有参数复制到GPUs上
if torch.cuda.is_available():
model = model.cuda()
# 代码执行时间装饰器
def timer(func):
def wrapper(*args, **kw):
begin = time.time()
# 执行函数体
func(*args, **kw)
end = time.time()
# 花费时间
cost = end - begin
print('本次一共花费时间:{:.2f}秒。'.format(cost))
return wrapper
# 训练
@timer
def train():
for epoch in range(1, epoch_n + 1):
print('Epoch {}/{}'.format(epoch, epoch_n))
print('-'*20)
for phase in ['train', 'valid']:
if phase == 'train':
print('Training...')
# 打开训练模式
model.train(True)
else:
print('Validing...')
# 关闭训练模式
model.train(False)
# 损失值
running_loss = 0.0
# 预测的正确数
running_correct = 0
# 让batch的值从1开始,便于后面计算
for batch, data in enumerate(dst.data_images_loader[phase], 1):
# 实际输入值和输出值
X, y = data
# 将参数复制到GPUs上进行运算
if torch.cuda.is_available():
X, y = X.cuda(), y.cuda()
# outputs.shape = [32,2] -> [1,2]
outputs = model(X)
# 从输出结果中取出需要的预测值
# axis = 1 表示去按行取最大值
_, y_pred = torch.max(outputs.detach(), 1)
# 将累积的梯度置零
optimizer.zero_grad()
# 计算损失值
loss = loss_fn(outputs, y)
if phase == 'train':
# 反向传播求导
loss.backward()
# 更新所有参数
optimizer.step()
running_loss += loss.detach().item()
running_correct += torch.sum(y_pred == y)
if batch % 500 == 0 and phase == 'train':
print('Batch {}/{},Train Loss:{:.2f},Train Acc:{:.2f}%'.format(
batch, len(dst.data_images[phase])/conf.batch_size, running_loss/batch, 100*running_correct.item()/(conf.batch_size*batch)
))
epoch_loss = running_loss*conf.batch_size/len(dst.data_images[phase])
epoch_acc = 100*running_correct.item()/len(dst.data_images[phase])
print('{} Loss:{:.2f} Acc:{:.2f}%'.format(phase, epoch_loss, epoch_acc))
通过10次训练后,打印输出如下:
Epoch 1/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.69,Train Acc:50.52%
train Loss:0.69 Acc:51.07%
Validing...
valid Loss:0.70 Acc:50.12%
Epoch 2/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.69,Train Acc:51.04%
train Loss:0.69 Acc:51.74%
Validing...
valid Loss:0.72 Acc:58.90%
Epoch 3/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.63,Train Acc:63.59%
train Loss:0.62 Acc:64.86%
Validing...
valid Loss:0.56 Acc:72.38%
Epoch 4/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.53,Train Acc:73.36%
train Loss:0.53 Acc:73.89%
Validing...
valid Loss:0.48 Acc:77.00%
Epoch 5/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.46,Train Acc:79.17%
train Loss:0.45 Acc:79.68%
Validing...
valid Loss:0.40 Acc:81.36%
Epoch 6/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.38,Train Acc:83.01%
train Loss:0.38 Acc:83.14%
Validing...
valid Loss:0.35 Acc:84.24%
Epoch 7/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.33,Train Acc:85.78%
train Loss:0.32 Acc:86.11%
Validing...
valid Loss:0.38 Acc:83.56%
Epoch 8/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.27,Train Acc:88.37%
train Loss:0.27 Acc:88.36%
Validing...
valid Loss:0.33 Acc:86.54%
Epoch 9/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.23,Train Acc:90.61%
train Loss:0.23 Acc:90.61%
Validing...
valid Loss:0.29 Acc:87.92%
Epoch 10/10
--------------------
Training...
Batch 500/625.0,Train Loss:0.19,Train Acc:92.36%
train Loss:0.19 Acc:92.41%
Validing...
valid Loss:0.26 Acc:89.16%
本次一共花费时间:947.35秒。
4. 模型测试
# 测试
def test():
dst = Dataset(train=False)
data_loader_test = torch.utils.data.DataLoader(dst,
batch_size=conf.batch_size,
shuffle=False)
# 保存测试结果
results = []
# tqdm模块用于显示进度条
for imgs, path in tqdm(data_loader_test):
if torch.cuda.is_available():
X = imgs.cuda()
outputs = model(X)
# pred表示是哪个对象,0=cat,1=dog
# probability表示是否个对象的概率
probability, pred = torch.max(F.softmax(outputs, dim=1).detach(), 1)
# 通过zip()打包为元组的列表,如[(1001, 23%, 'cat')]
batch_results = [(path_.item(), str(round(probability_.item()*100, 2))+'%', 'dog'if pred_.item() else 'cat')
for path_, probability_, pred_ in zip(path, probability, pred)]
results += batch_results
write_csv(results, conf.result_file)
# 随机预览
# 预览图片张数
size = 20
for i in range(size):
index = math.floor(random.random() * len(results))
# 图片名称
file_name = str(results[index][0]) + '.jpg'
# 图片是否个对象的概率
score = results[index][1]
# 'cat' or 'dog'
name = results[index][2]
# 获取图片
img = cv2.imread(os.path.join(conf.data_test_root, file_name))
title = score + ' is ' + name
# 设置图片大小
plt.rcParams['figure.figsize'] = (8.0, 8.0)
# 默认间距
plt.tight_layout()
# 行,列,索引
plt.subplot(4, 5, i + 1)
plt.imshow(img)
plt.title(title, fontsize=14, color='blue')
plt.xticks([])
plt.yticks([])
plt.show()
# 保存测试结果
def write_csv(results, file_name):
import csv
with open(file_name, 'w') as f:
writer = csv.writer(f)
writer.writerow(['id', 'label', 'pred'])
writer.writerows(results)
测试结果:
100%|██████████| 391/391 [00:45<00:00, 8.55it/s]



迁移学习-迁移VGG16
迁移学习其基本思路是冻结卷积神经网络中全连接层之前的全部网络层次,让这些被冻结的网络层次中的参数在模型的训练过程中不进行梯度更新,能够被优化的参数仅仅是没有被冻结的全连接层的全部参数。
下面看看迁移学习的实施过程,首先需要下载己经具备最优参数的模型,这需要 对我们之前使用的 model = Models()代码部分进行替换,因为我们不需要再自己搭建和定义训练的模型了,而是通过代码自动下载模型并直接调用,具体代码如下 :
# pretrained=True表示下载训练好的模型
# 由于下载速度太慢,这里设置为False
model = models.vgg16(pretrained=False)
# 加载预先下载好的预训练参数到vgg16
model.load_state_dict(torch.load(conf.path_vgg16))
for param in model.parameters():
param.requires_grad = False
model.classifier = nn.Sequential(
nn.Linear(7*7*512, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 2)
)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.classifier.parameters(), lr=1e-5)
首先,迁移过来的VGG16架构模型在最后输出的结果是1000个,在我们的问题中只需两个输出结果,所以全连接层必须进行调整。
其次,对原模型中的参数进行遍历操作,将参数中的parma.requires_grad全部设置为 False,这样对应的参数将不计算梯度,当然也不会进行梯度更新了,这就是之前说到的冻结操作。然后,定义新的全连接层结构并重新赋值给model.classifier。在完成了新的全连接层定义后,全连接层中的parma.requires_grad参数会被默认重置为True,所以不需要再次遍历参数来进行解冻操作。损失函数的loss值依然使用交叉熵进行计算 ,但是在优化函数中负责优化的参数变成了全连接层中的所有参数, 即对 model.classifier.parameters 这部分参数进行优化。
问题及错误处理
1.1 CUDA out of memory

从问题中看出是因为GPU的内存不足。通过查阅资料找到了一些解决方案:
- 修改
batch_size的大小 - 简化训练模型
- 释放你不需要的张量和变量
- 修改输入图片的大小
1.2 numpy中axis的取值问题
官方文档中描述:
axis : None或int或tuple of ints,可选
沿一个或多个轴执行逻辑AND规约。 默认值(axis = None)是对输入数组的所有维度执行逻辑AND。轴可以是负数,这种情况下,它从最后一个轴开始索引。
版本1.7.0中的新功能。
如果这是一个整数元组,则在多个轴上进行规约操作,而不是像以前那样在单个轴或所有轴上进行行规约操作。
在本实验中我们需要求出R、G、B三个通道上像素的均值和标准差。
因为传入的图像维度为[16, 3, 64, 64],其中16表示一个批次的16张图片,3表示通道数为3,两个64分别表示图片的宽和高的大小。
因此在求三个通道的像素的均值和标准差时传入的axis=(0, 2, 3)。代码如下:
for imgs, labels in data_loader['train']:
# imgs.shape = torch.Size([16, 3, 64, 64])
mean += np.mean(imgs.numpy(), axis=(0, 2, 3))
std += np.std(imgs.numpy(), axis=(0, 2, 3))
查看项目完整代码请移驾至github。
