KNN算法思想就不多说了,很简单,基于欧氏距离或者Mahantta距离进行计算,然后投票决定你的类别。
这里用三个文件;
simplepreprocessor.py
import cv2
class SimplePreprocessor:
def __init__(self, width, height, inter=cv2.INTER_AREA):
self.width = width
self.height = height
self.inter = inter
# 设置输入进来的图片统一到一个尺寸
def preprocess(self, image):
return cv2.resize(image, (self.width, self.height), interpolation=self.inter)
if __name__ == '__main__':
s = SimplePreprocessor(300, 400)
img = cv2.imread('beauty.jpg')
# print(img)
cv2.imshow('src', img)
cv2.imshow("resize", s.preprocess(img))
cv2.waitKey(0)
# cv2.destroyallWindows()simpledatasetloader.py
import numpy as np
import cv2
import os
'''
class SimplePreprocessor:
def __init__(self, width, height, inter=cv2.INTER_AREA):
self.width = width
self.height = height
self.inter = inter
@staticmethod
def preprocess(self, image):
return cv2.resize(image, (self.width, self.height), interpolation=self.inter)
'''
class SimpleDatasetLoader:
def __init__(self, preprocessors=None):
self.preprocessors = preprocessors
if self.preprocessors is None:
self.preprocessors = []
def load(self, imagePaths, verbose=-1):
'''
data_cat = []
data_dog = []
labels_dog = []
labels_cat = []
'''
# 接收图像数据(像素值)和相对应的label
data = []
labels = []
for (i, imagePath) in enumerate(imagePaths):
image = cv2.imread(imagePath)
# 根据文件夹的分类进行获取label
# 文件夹应该对应
# dog_... cat_...
label = imagePath.split(os.path.sep)[-2]
if self.preprocessors is not None:
for p in self.preprocessors:
image = p.preprocess(image)
data.append(image)
labels.append(label)
# 每处理500张就输出信息
if verbose > 0 and i > 0 and (i + 1)%verbose == 0:
print('[INFO] processed {}/{}'.format(i+1, len(imagePaths)))
# print(data_cat)
# print(data_dog)
# print(labels_cat)
# print(labels_dog)
return (np.array(data), np.array(labels))
if __name__ == '__main__':
s = SimpleDatasetLoader()
imagePaths = '/home/king/test/python/train/data/all/train'
s.load(imagePaths)knn.py
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from simplepreprocessor import SimplePreprocessor
from simpledatasetloader import SimpleDatasetLoader
from imutils import paths
import argparse
if __name__ == '__main__':
# 命令行参数设置
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True, help="path to input dataset")
ap.add_argument("-k", "--neighbors", type=int, default=1, help="of nearest neighbors for classification")
ap.add_argument("-j", "--jobs", type=int, help="of jobs for K-NN distance (-1 uses all variables cores)")
args = vars(ap.parse_args())
print("[INFO] loading images...")
# 加载数据集的文件路径
imagePaths = list(paths.list_images(args["dataset"]))
# 对数据集文件夹下的图片进行预处理,统一到32x32的尺寸
sp = SimplePreprocessor(32, 32)
sdl = SimpleDatasetLoader(preprocessors=[sp])
# 从RGB三颜色通道flat到1维矩阵
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.reshape((data.shape[0], 3072))
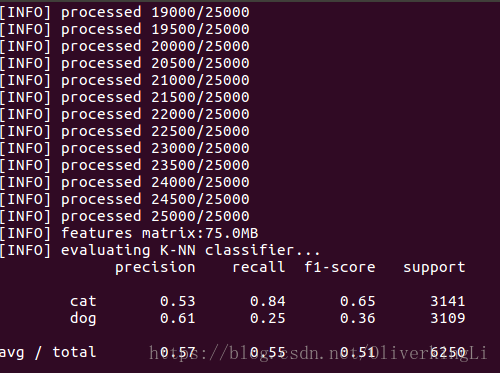
print("[INFO] features matrix:{:.1f}MB".format(data.nbytes / (1024*1000.0)))
# 对类别进行编码,比如dog-0,cat-1
le = LabelEncoder()
labels = le.fit_transform(labels)
# print(labels)
# 训练集70%用来训练,25%用来测试,其实也是相当于validation
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.25, random_state=42)
# print(trainX)
# print(trainY)
print("[INFO] evaluating K-NN classifier...")
# 构建KNN分类器
model = KNeighborsClassifier(n_neighbors=args["neighbors"], n_jobs=args["jobs"])
# 模型训练
model.fit(trainX, trainY)
print(classification_report(testY, model.predict(testX), target_names=le.classes_))