前言:
好的,这篇开始,我们首先以08年BCI国际大赛4分类运动想象的数据作为入门项目,本篇讲的是该数据集的预处理工程,BCI领域有很多研究方向的数据,比如运动想象,睡眠,癫痫,眼动,肌电等等,而我是比较推荐把该数据作为入门的数据,官方介绍简单易懂,并且做的是分类。
1.什么是预处理工程?
定义:数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程
问题:数据类型不同,比如有的是文字,有的是数字,有的含时间序列,有的连续,有的间断。也可能,数据的质量不行,有噪声,有异常,有缺失,数据出错,量纲不一,有重复,数据是偏态,数据量太大或太小
目的:让数据适应模型,匹配模型的需求
(来源于Garcia-zhang)
这是较为官方的介绍,其实就是经过一些“工序”把数据质量提高,使得模型最终得到更好的结果。在这里不得不说的是,预处理工程比模型更为重要,项目的最终的目的是尽可能地得到较高的结果,数据是得到这个结果的根基,而模型的调节只是为了逼近这个结果。所以我们要做好预处理。
2.预处理工程=数据分析+数据预处理
2.1 数据分析
当我们拿到一个新的数据,我们需要首先对他做数据分析,第一步要做的是查看官方对该数据的说明文档,重点关注数据集的实验范式(计算样本量等参数用)和做了哪些预处理工作。以本数据集为例,以下是官方说明。
数据集地址:
官方地址:BCI Competition IV (bbci.de)
Github地址:新建标签页 (github.com)
Kaggle地址:BCI-IV-2a | Kaggle
其中官方给出了两种数据格式:GDF和M文件,需要下一定的功夫去导入数据分析数据,Github有位小哥提供了CSV文件的数据,下面使用CSV格式文件。

官方说明:



书接上表,官方文档共6页,这里给出3页,因为后面的信息用作GDF文件解析,前面3页的信息解析CSV文件已经足够。重要的信息我已经高亮表示。我们可以知道:
(1)9个被试者参与实验采集
(2)1个人做2轮实验,其中1轮实验中做6个runs,1个run中做48次trials(left、right、feet、tougue4种想象动作分别每个做12次,循环4次)
(3)所以,1轮实验的样本量Samples=12*4*6=288个
比如第一个人的数据,无论它是什么类型的数据保存的,官方对于每个被试者给出了两个文件,第一个人的数据为A01T/A01E,两个文件对应着两轮完整的实验,每个文件288个样本,其中T用于train,E用于test。
并且,官方使用250HZ采集数据,CSV文件是4S的数据,也就是Figure2中的2-6s的数据,一共1000个数据点,官方还做了0.5-100HZ的带通滤波和50Hz的工频滤波以消除噪声的干扰。
数据集采用10-20国际标准导联系统,也就是25个通道,其中三个通道未EOG数据,我们对MI信号进行分类,所以预处理工作中需要筛选通道,留22个。
好了,到现在我们把该数据集进行了一个较简单的分析,下面需要做数据清洗,我们拿到一个数据,先要做数据分析,算出它的样本量,找到实验范式和采样率,通道数等关键信息,再去看看他做了哪些预处理,我们分析完了,再去做自己想对它做的工作,也就是数据清洗了。
数据清洗:
数据清洗是整个数据分析过程的最主要的一步,也是整个数据分析项目中最耗费时间的一步。数据清洗的过程决定了数据分析的准确性。随着大数据的越来越普及,数据清洗是必备的技能之一。(
数据清洗步骤:
(1)数据获取,使用read_csv或者read_excel
(2)数据探索,使用shape,describe或者info函数
(3)行列操作,使用loc或者iloc函数
(4)数据整合,对不同数据源进行整理
(5)数据类型转换,对不同字段数据类型进行转换
(6)分组汇总,对数据进行各个维度的计算
(6)处理重复值、缺失值和异常值以及数据离散化
原文链接:https://blog.csdn.net/liumengqi11/article/details/113174269
数据清洗如上,若是数据存在以上问题需要做相关的清洗工作,具体怎样操作请看上面链接,这里不便多说。
2.2 数据预处理
这里给出数据预处理可以做的工作,最后给出本数据的预处理代码
2.2.1 数据无量纲化
数据“无量纲化”就是将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的操作。譬如梯度和矩阵为核心的算法(逻辑回归,支持向量机,神经网络)中,无量纲化可以加快求解速度;而在距离类模型(K近邻,K-Means聚类),无量纲化可以提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。(一个特例是决策树和树的集成算法们,决策树不需要无量纲化,它可以把任意数据都处理得很好。)
数据的无量纲化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化(Zero-centered或者Meansubtraction)处理和缩放处理(Scale)。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理。
2.2.2 数据归一化 preprocessing.MinMaxScaler
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就叫做数据归一化(Normalization,又称Min-Max Scaling)。注意,Normalization是归一化,不是正则化,真正的正则化是regularization,不是数据预处理的一种手段。归一化之后的数据服从正态分布,公式如下:
![]()
在sklearn当中,使用preprocessing.MinMaxScaler来实现这个功能。MinMaxScaler有一个重要参数,feature_range,可以控制把数据压缩到的范围,默认是[0,1]。
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
# data是4行2列的数据
import pandas as pd
print(pd.DataFrame(data))
# 1.实现归一化
scaler = MinMaxScaler() # 实例化
scaler = scaler.fit(data) # fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) # 通过接口导出结果
print(result) # 也是4行2列,data压缩到[0,1]的数据
result_ = scaler.fit_transform(data) # 训练和导出结果一步达成
print(result_)
print(scaler.inverse_transform(result))# 将归一化后的结果逆转
# 2.使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5, 10]) # 依然实例化
result = scaler.fit_transform(data) # fit_transform一步导出结果
print(result)
# 当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了
# 此时使用partial_fit作为训练接口
# scaler = scaler.partial_fit(data)
# 3.使用numpy来实现归一化
import numpy as np
X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
# 归一化
X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) # X.min(axis=0)表示每一列的最小值
print(X_nor)
# 逆转归一化
X_returned = X_nor * (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0)
print(X_returned)
2.2.3 数据标准化preprocessing.StandardScaler
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:
![]()
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler() # 实例化
scaler.fit(data) # fit,本质是生成均值和方差
print(scaler.mean_) #查看均值的属性mean_
print(scaler.var_) # 查看方差的属性var_
x_std = scaler.transform(data) # 通过接口导出结果
print(x_std.mean()) # 导出的结果是一个数组,用mean()查看均值
print(x_std.std()) # 用std()查看方差
scaler.fit_transform(data) # 使用fit_transform(data)一步达成结果
scaler.inverse_transform(x_std) # 使用inverse_transform逆转标准化
对于StandardScaler和MinMaxScaler来说,空值NaN会被当做是缺失值,在fit的时候忽略,在transform的时候保持缺失NaN的状态显示。并且,尽管去量纲化过程不是具体的算法,但在fit接口中,依然只允许导入至少二维数组,一维数组导入会报错。通常来说,输入的X会是特征矩阵,现实案例中特征矩阵不太可能是一维所以不会存在这个问题。
StandardScaler和MinMaxScaler选哪个?
记得前几周我做工作汇报,有位同事问我为何我把STEW数据集做了Min-Max又做Standard,我回答自己试验过,这样做完数据质量会更好一些,Acc能提高1%左右的样子,这是经验之谈,但我的做法不可取,现在对于二者的选取,需要看情况。大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。MinMaxScaler在不涉及距离度量、梯度、协方差计算以及数据需要被压缩到特定区间时使用广泛,比如数字图像处理中量化像素强度时,都会使用MinMaxScaler将数据压缩于[0,1]区间之中。
总之,建议先试StandardScaler,效果不好换MinMaxScaler。
数据缩化方法不止这两种,别的方法在此处不列举
2.2.4 标签独热编码
定义:独热编码即 One-Hot 编码,又称一位有效编码。其方法是使用 N位 状态寄存器来对 N个状态 进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
目的:解决分类器不好处理离散数据的问题。
独热编码就是把一些离散的特征/标签编为从0开始的特征/标签
例:
二分类标签:中国、美国
编码:10、01
三分类标签: 狗、猫、鸟
编码:100、010、001
四分类标签:1000、0100、0010、0001
我们把其他的各种各样的数据编为了计算机读得懂的0和1组成的数据,而在BCI从数据处理中,独热编码通常用在标签编码。
3.BCI IV2a数据处理
import pandas as pd
#读取数据
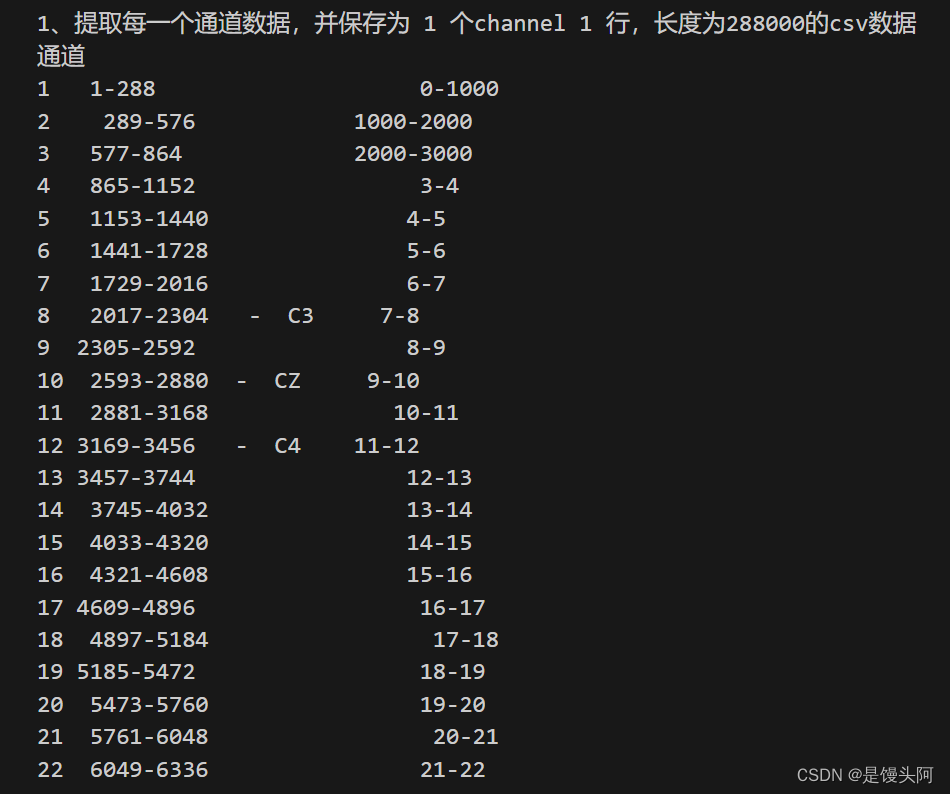
datasets = pd.read_csv(r"C:/Users/19067/Desktop/eegnet/MI-EEG-A01T.csv",header=None)
print(datasets.shape)![]()
第一步读取数据,控制台输出是288,22000。288是样本量不多说,22000=22*1000,22是25-3=22,不包含EOG信号的MI数据,本次加载的数据是Github上的,已经筛选完通道后的数据,保留了22个Channels,那每个通道有250hz*4s=1000的数据。
#得到升维依据
n_samples_train = len(datasets)
print("n_samples_train:", n_samples_train)![]()
这里我准备把数据升维,从2维变为3维,这是找到的升维依据代码,2到3我们不能使用data.reshape()函数进行随便的重塑升维,需要len()函数,这与Dataset类中的def__len__(self)有异曲同工之妙。至于为何升维度,下一篇博客我会详细讲述。
#升维2-3
x_train = x_train.reshape((n_samples_train,22,1000))
print(x_train.shape)
这里我们成功的到了3维,第一维度是样本量,第二维度是channels,第三维度是4s的数据样本。
#数据归一化
from sklearn.preprocessing import StandardScaler, LabelEncoder
scaler = StandardScaler().fit(datasets)
x_train = scaler.transform(datasets)这里进行了数据归一化,并且我导入了LabelEncoder编码,我把它和One-Hot编码对比,发现二者最后得到的编码标签是一样的,所以我们还是使用独热编码把。
#保存为pt文件
import torch
x_train_data = torch.save(x_train, "./A01_train.pt")
#3升4维度
accuracy = torch.load("./A01_train.pt")
print(accuracy.shape)
accuracy_train = accuracy.reshape(288,22,20,50)
print(accuracy_train.shape)
a = torch.save(accuracy_train,'./A01_train4d.pt')这里我继续升维到4,把每个channels的1000数据点分为了20*50,1000有很多公因数,有很多分的方法,1000也可以做填充,填充后的数据可以开根号整除,这就陆续来了一系列问题:
(1)data是直接公因数相乘分开 VS data做填充后再开根号整除
(2)data哪种填充方式好
(2)data 3维 VS data 4维
说到这里,你有可能会晕。这里data 3维=(batch_size,input_channels,len(data))这个是三维度,前面两维是1维的len(data)进入到模型中训练添加的,所以3维的形式对应着4s的1000个1维的数据;同理data 4维=(batch_size,input_channels,H,W)是把1维的4s数据分成了H*W的矩阵,对于数据来讲,从1维度到了2维,扔到CNN中是3维度到了4维。
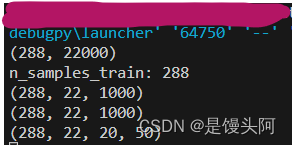
最终控制台输出的data.shape=(288,22,20,50),这里20*50限制了CNN模型卷积核大小,具体下篇讲。数据搞完了,我们对标签进行处理。
# 处理标签
import numpy as np
#读取标签
y_train = pd.read_csv(r"C:/Users/19067/Desktop/eegnet/EtiquetasA01T.csv",header=None)
print(y_train.shape)
#查看做的几分类
n_classes = len(np.unique(y_train))
print("n_classes:", n_classes)
#标签独热编码
from sklearn.preprocessing import OneHotEncoder
from sklearn import preprocessing
import numpy as np
import pandas as pd
encoder = preprocessing.OneHotEncoder(handle_unknown='ignore')
y = np.array(y_train)
y = y.reshape(-1,1)
encoder.fit(y)
y_oh = encoder.transform(y).toarray()
print(y_oh,y_oh.shape)这里我们使用独热编码形式处理
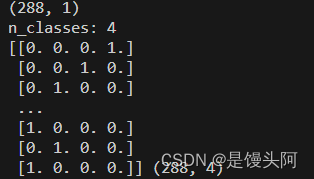
独热编码后label.shape=(288,4),为何变为4维上面已经举例说了,但是288个4维label肯定是不能和data对接上的,所以我们需要对标签再降到1维.,并且要转为Tensor形式,因为后面模型搭建用pytorch编写。并且可以看到我们数据做的是几分类,一行代码就可以搞定,是不是很神奇?
#独热后的标签转Tensor
import torch
import torchvision.transforms as transforms
transf = transforms.ToTensor()
d=transf(y_oh)
label = torch.argmax(d, dim=2).long()
print(label.shape)
#保存标签
import torch
a = torch.save(label,"./A01train_label.pt")
b = torch.load("./A01train_label.pt")
c = b.reshape(288,1)
print(c.shape)
d = torch.save(c,'./A01train_target.pt')
#压缩标签维度288,1 - 288
e = torch.load('./A01train_target.pt')
h = torch.squeeze(e)#表示把x中维度大小为1的所有维都已删除
print(h.shape)
v = torch.save(h,'./A01train-target.pt')
控制台最终输出独热后的288个标签。下面是BCI IV 2a数据集的完整预处理代码。
# 处理数据
import pandas as pd
#读取数据
datasets = pd.read_csv(r"C:/Users/19067/Desktop/eegnet/MI-EEG-A01T.csv",header=None)
print(datasets.shape)
#得到升维依据
n_samples_train = len(datasets)
print("n_samples_train:", n_samples_train)
#数据归一化
from sklearn.preprocessing import StandardScaler, LabelEncoder
scaler = StandardScaler().fit(datasets)
x_train = scaler.transform(datasets)
#升维2-3
x_train = x_train.reshape((n_samples_train,22,1000))
print(x_train.shape)
#保存为pt文件
import torch
x_train_data = torch.save(x_train, "./A01_train.pt")
#3升4维度
accuracy = torch.load("./A01_train.pt")
print(accuracy.shape)
accuracy_train = accuracy.reshape(288,22,20,50)
print(accuracy_train.shape)
a = torch.save(accuracy_train,'./A01_train4d.pt')
# 处理标签
import numpy as np
#读取标签
y_train = pd.read_csv(r"C:/Users/19067/Desktop/eegnet/EtiquetasA01T.csv",header=None)
print(y_train.shape)
#查看做的几分类
n_classes = len(np.unique(y_train))
print("n_classes:", n_classes)
#标签独热编码
from sklearn.preprocessing import OneHotEncoder
from sklearn import preprocessing
import numpy as np
import pandas as pd
encoder = preprocessing.OneHotEncoder(handle_unknown='ignore')
y = np.array(y_train)
y = y.reshape(-1,1)
encoder.fit(y)
y_oh = encoder.transform(y).toarray()
print(y_oh,y_oh.shape)
#独热后的标签转Tensor
import torch
import torchvision.transforms as transforms
transf = transforms.ToTensor()
d=transf(y_oh)
label = torch.argmax(d, dim=2).long()
print(label.shape)
#保存标签
import torch
a = torch.save(label,"./A01train_label.pt")
b = torch.load("./A01train_label.pt")
c = b.reshape(288,1)
print(c.shape)
d = torch.save(c,'./A01train_target.pt')
#压缩标签维度288,1 - 288
e = torch.load('./A01train_target.pt')
h = torch.squeeze(e)#表示把x中维度大小为1的所有维都已删除
print(h.shape)
v = torch.save(h,'./A01train-target.pt')
结语:
本篇主要叙述了对BCI IV 2a数据集的预处理,所做的工作并不多,主要是使用了csv文件,Github给出的这个数据集已经帮我们做了很多的工作了,至少我们不用做通道选择了,若是从GDF中筛选通道,那是比较痛苦的,下面我给出GDF怎样筛选出3个EOG通道,建议把GDF先转为CSV再使用iloc码进行提取,这里不做过多的叙述。下一篇特别重要,我会通过一个消融实验的结果,来讲述SGD和Adam、数据维度、填充方式3各方面的选择原则。