论文:
《EEG-TCNet: An Accurate Temporal Convolutional Network for Embedded Motor-Imagery
Brain–Machine Interfaces》
对以上论文中的EEG-TCNet模型进行pytorch复现,并使用BCI IV2a数据进行测试,观察到目前全网缺少EEG-TCNet的pytorch实现代码,实质是缺少TCN块的pytorch代码,原因是:
之前pytorch中有torch.nn.CausalConv2d可直接实现二维因果卷积,来搭建TCN块,但是目前这个在pytroch中已被删除,现在大多数人想用因果卷积都是直接使用TCN块中的卷积+修改尺寸结构,但是还可以使用平移、权重归一化来实现二维因果卷积。而在Tensorflow编写框架中可以直接调用
CausalConv2d卷积来搭建TCN。
1、TCN基础:
1、TCN:
TCN(Temporal Convolutional Network),时序卷积网络,是在2018年提出的一个卷积模型,但是可以用来处理时间序列
2、因果卷积:
-
因果卷积是在wavenet这个网络中提出的,之后被用在了TCN中。
-
因果卷积应为就是:Causal Convolutions。
3、TCN结构:
1.卷积结束后会因为padding导致卷积之后的新数据的尺寸B>输入数据的尺寸A,所以只保留输出数据中前面A个数据;
2.卷积之后加上个ReLU和Dropout层
3.每两次扩大一倍dilation
总之TCN中的基本组件:TemporalBlock()类是两个dilation相同的卷积层,卷积+修改数据尺寸+relu+dropout+卷积+修改数据尺寸+relu+dropout,之后弄一个Resnet残差连接来避免梯度消失,结束!
2、论文简单解读:
2.1 TCN
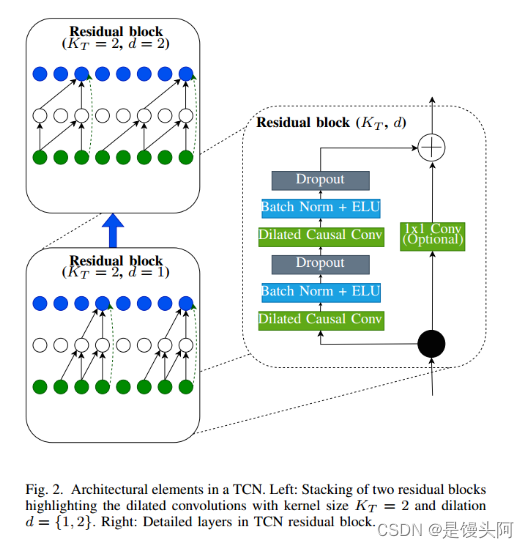
1、因果卷积:tcn产生与输入相同长度的输出。为此,tcn使用1D全卷积网络(FCN)架构,其中每个隐藏层的大小与输入层相同,此外,因果循环被用来阻止信息流从未来流向过去。简单地说,时刻t的输出只取决于时刻t和更早的输入。
2、空洞卷积:一个规则的因果卷积只能在网络的深度上线性地增加它的接受域大小。这是一个主要的缺点,因为要么需要一个非常深的网络,要么需要一个巨大的内核大小来获得一个大的接受域大小。为了解决这个问题,tcn使用扩展卷积,这允许网络通过增加扩张因子d,以指数方式增加其接受野的大小,与网络深度成正比。
3、残差块(Residual Blocks): TCN的残差块由两层扩展卷积组成,具有批处理归一化、Relu和卷积之间的dropout层。尽管tcn只具有1D卷积的特征,但它们仍然能够处理二维特征图。跳过连接将输入添加到输出特征映射,并检查如果输入和输出的深度不同,则将1x1卷积放置。
通过堆叠残差块,感受野大小随着每个残差成指数增长,因为每个后续堆叠块膨胀因子d成指数增长,TCN感受野变化为:
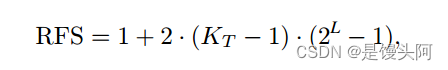
其中,Kt = TCN核大小,L=残差块数。
2.2 注:
1、在卷积之间使用批归一化而不是权值归一化,因为在各种大规模网络上,批归一化已被证明比权值归一化具有更高的精度。
2、我们使用指数线性单元(ELU)激活而不是非线性单元(ReLU)。这是因为EEG-TCNET在使用ELU激活函数时表现出比使用ReLU更好的性能。
3、使用正常dropout代替空间dropout。由于TCN是在各种卷积之后应用的,特征映射内的相邻帧不是强相关的,因此删除单个元素而不是整个1D特征映射来正则化激活是有益的。
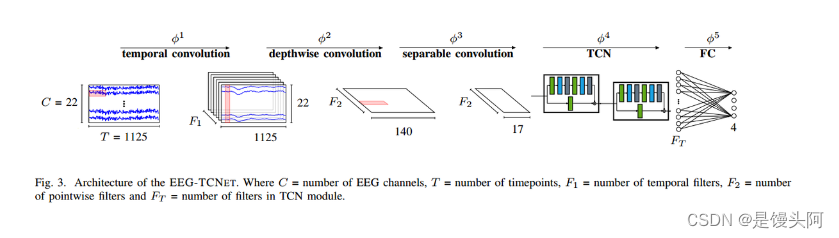
EEG-TCNet
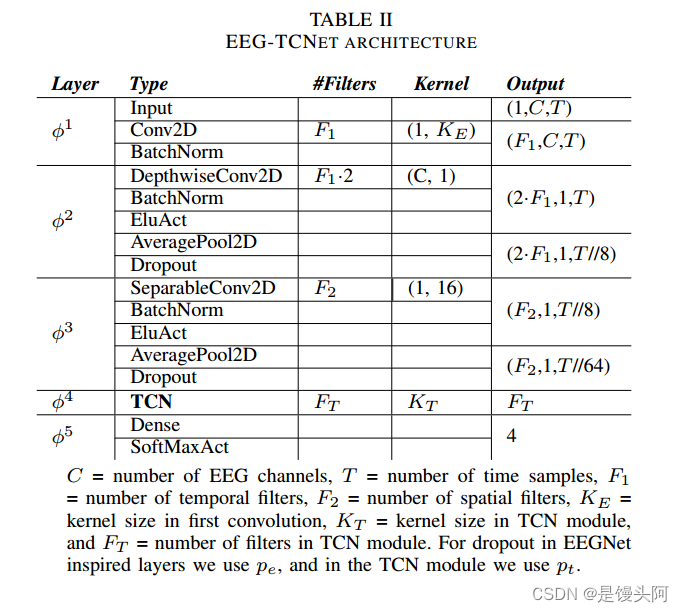
EEG-TCNet结构
2.3 模型主旨思想:
1、BCI IV2a数据以4维数据输入,shape=(288,1,22,1000)
2、数据先经过一个完整的EEGNet结构,来处理这个4维数组
3、数据从EEGNet出来,进入到TCN块之前进行降维处理(TCN只能处理1维数组,具体为啥请详细阅读我写的TCN代码!!!)
完事
2.4 核心的核心:
数据从EEGNet出来之后,其中的22个通道,经过EEGNet的深度卷积核(C,1)的处理,22通道压缩为1个通道,最重要的来了,我们降维度,摒弃的维度就是这个压缩为1的通道维度!
此时EEGNet模型block3出来的data.shape=(batch_size,F2,1,T//64),经过torch.squeeze(data,dim=2)后,压缩为shape=(batch_size,F2,T//64)输入到TCN中处理。
2.5 模型选定最优参数组合问题:
至于,怎样选定最佳的TCN块的参数和其他超参数,以确定最优模型问题:
在BCI IV2a中,EEGNet在9个被试中的acc = 54% ~88% 之间,不同被试个体之间差异很大,这可能是刚性网络(固化网络)和训练方式的问题,即对每个被试使用相同的网络并优化超参数的原因。
解决:
在每个单独的个体被试上使用交叉验证网格搜索法,来找到最佳的特定网络参数(核大小、滤波器设置等)以及训练模型的超参数(dropout)。
网格搜索:把超参数的值,以字典形式进行传递进行最优选
sklearn.model_selection.GridSearchCV:暴力搜索,选出最优 参数+模型(一般用这个)
sklearn.model_selection.cross_val_score:选出最优模型
2.6 训练策略:
CrossEntropyLoss()
Adam,Lr=0.001
batch_size=64
epochs=750
2.7 结果:
2.7.1 论文结果:
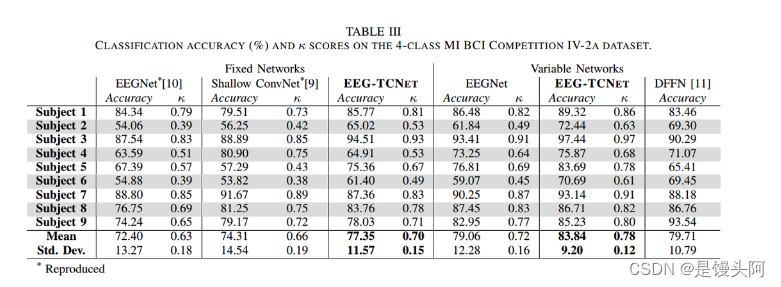
2a数据集结果
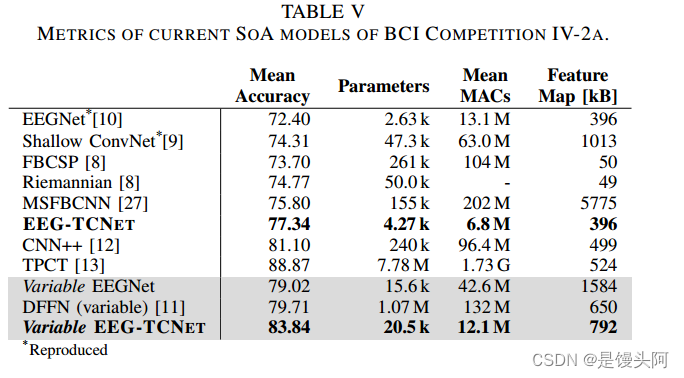
与其他SOTA模型对比
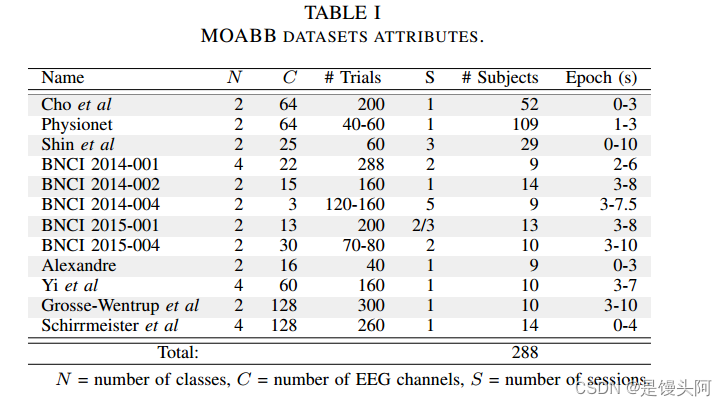
EEG-TCNet在所有脑机接口基准之母(MOABB)上展示了通用性,MOABB是一个包含12个不同脑机接口数据集的大规模测试基准。EEG-TCNET成功地泛化了单个数据集之外的数据,在MOABB上优于当前最先进(SoA)的元效应为0.25
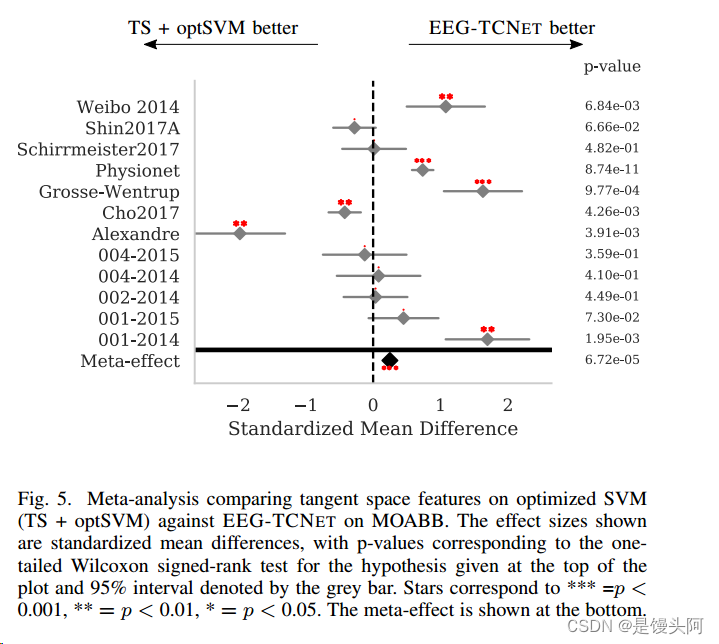
meta分析比较优化支持向量机(TS + optSVM)和EEG-TCNET在MOABB上的切线空间特征。所示的效应大小是标准化的平均差异,p值对应于图顶部给出的假设的单尾Wilcoxon符号秩检验,95%区间由灰色条表示。星号对应*** =p < 0.001, ** =p < 0.01, * =p < 0.05。元效应显示在底部。
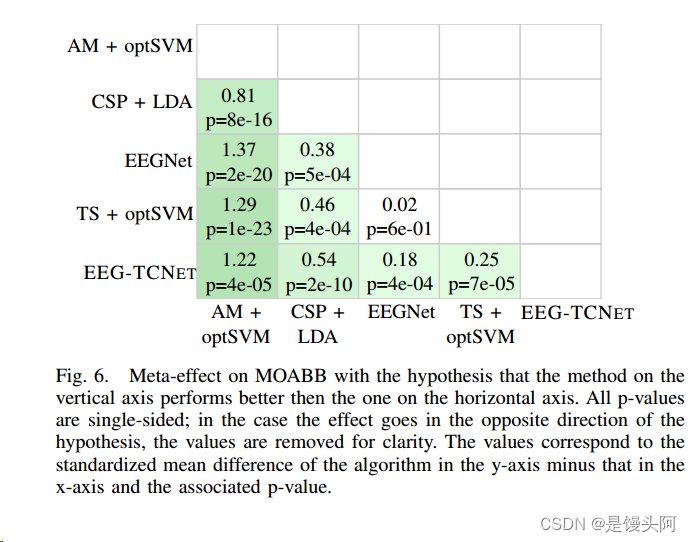
假设纵轴上的方法优于横轴上的方法,对MOABB的元效应。所有p值都是单面的;在这种情况下,效果与假设的方向相反,为了清晰起见,这些值被删除。这些值对应于算法在y轴上的标准化均值差减去在x轴上的标准化均值差和相关的p值。
2.7.2 自己复现BCI IV2a结果:
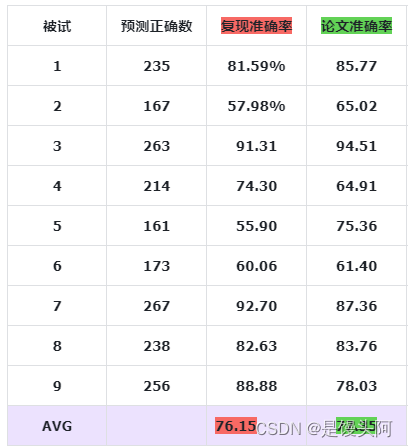
被试1:
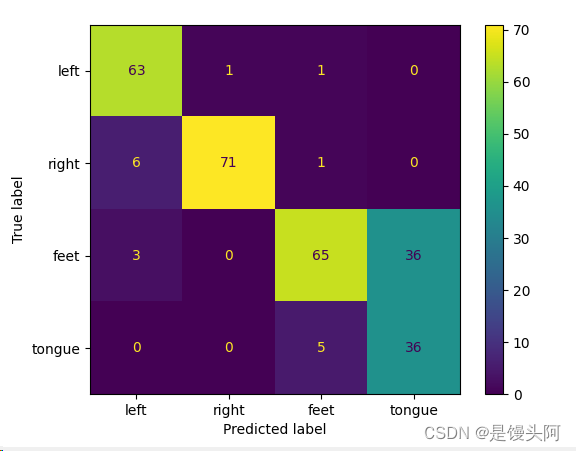
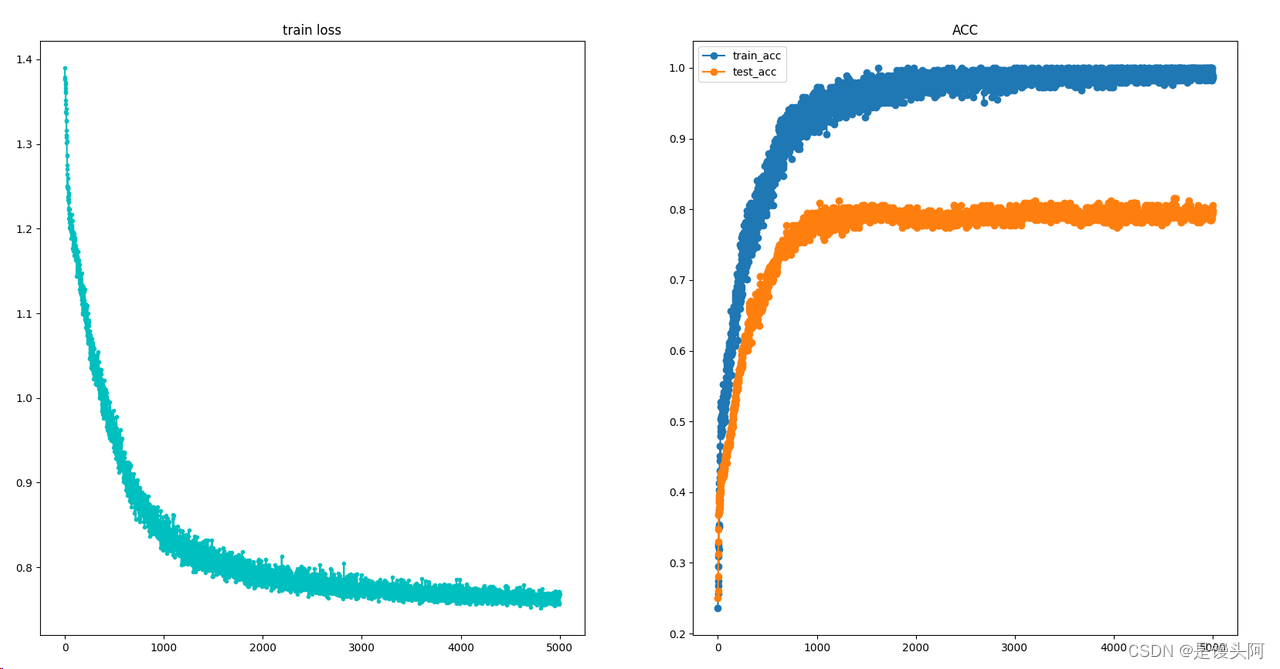
训练速度较快(每个epoch用时少),但模型拟合速度慢(需要的epoch多)
sub4:
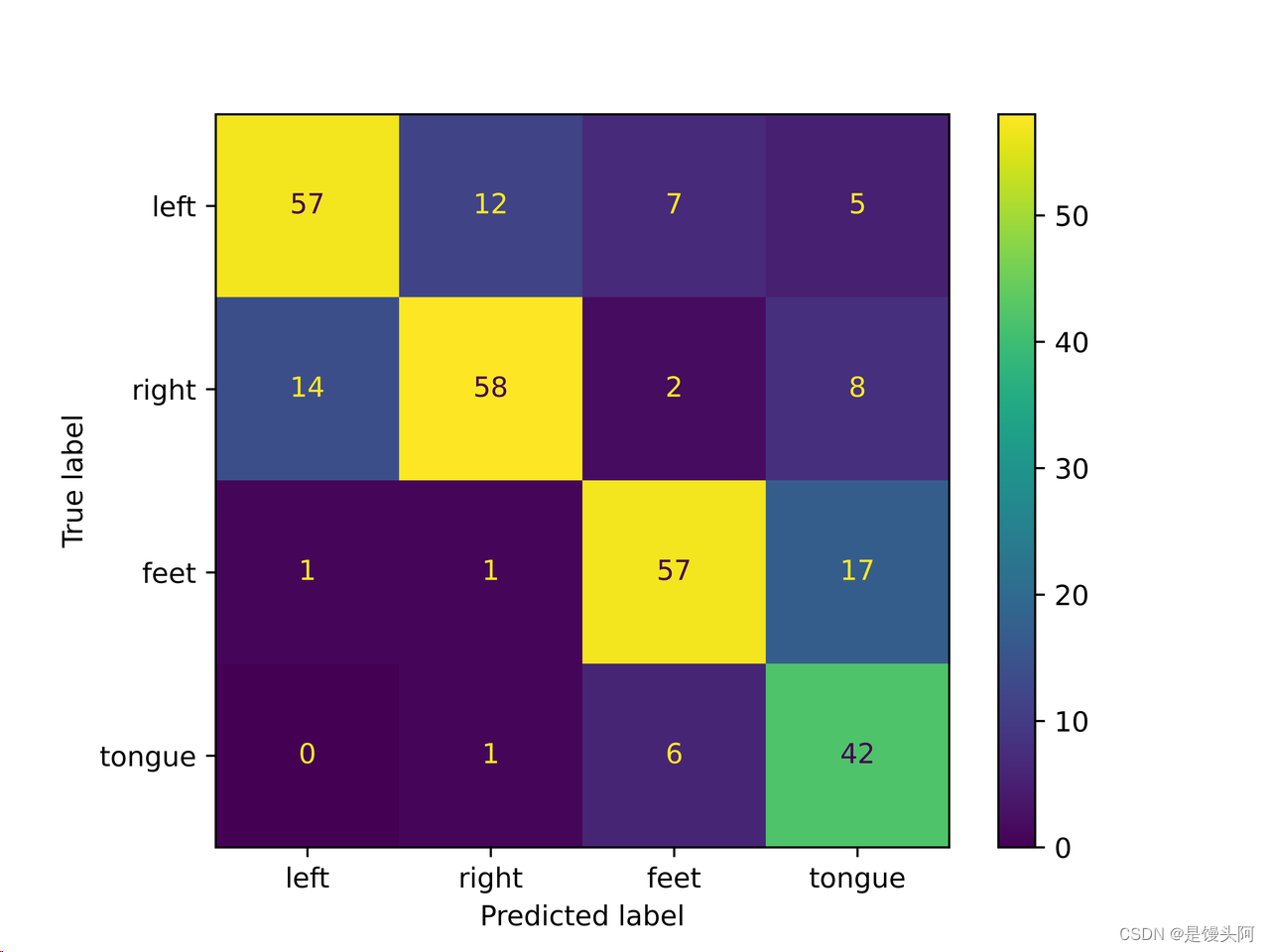
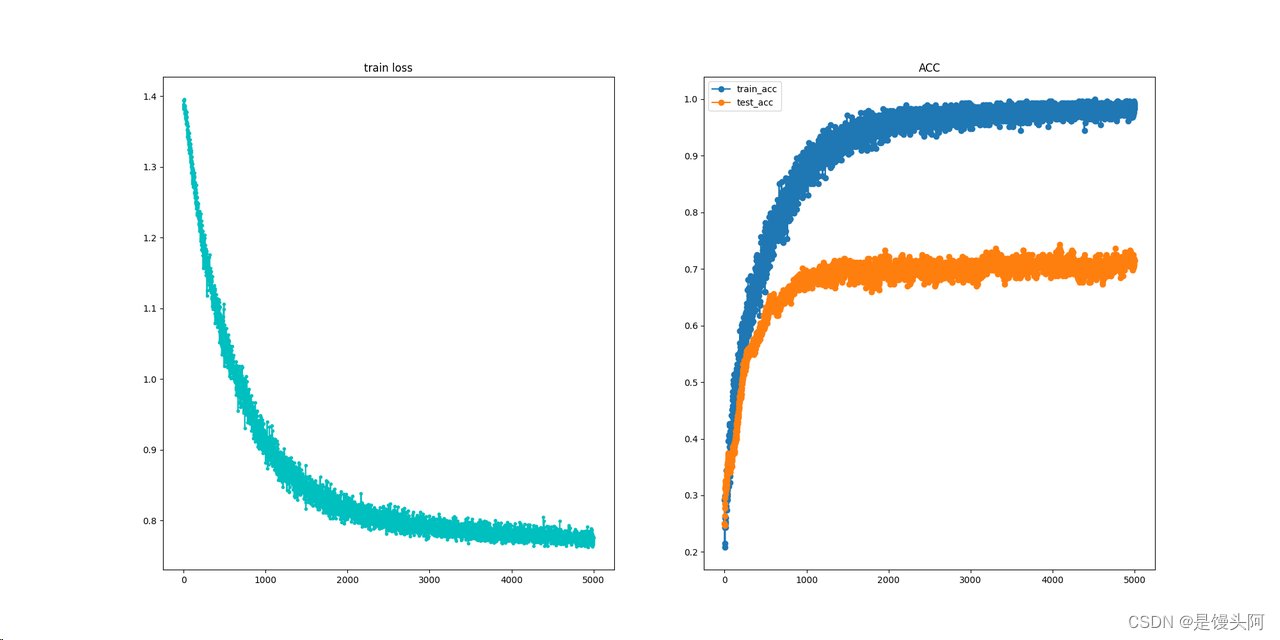
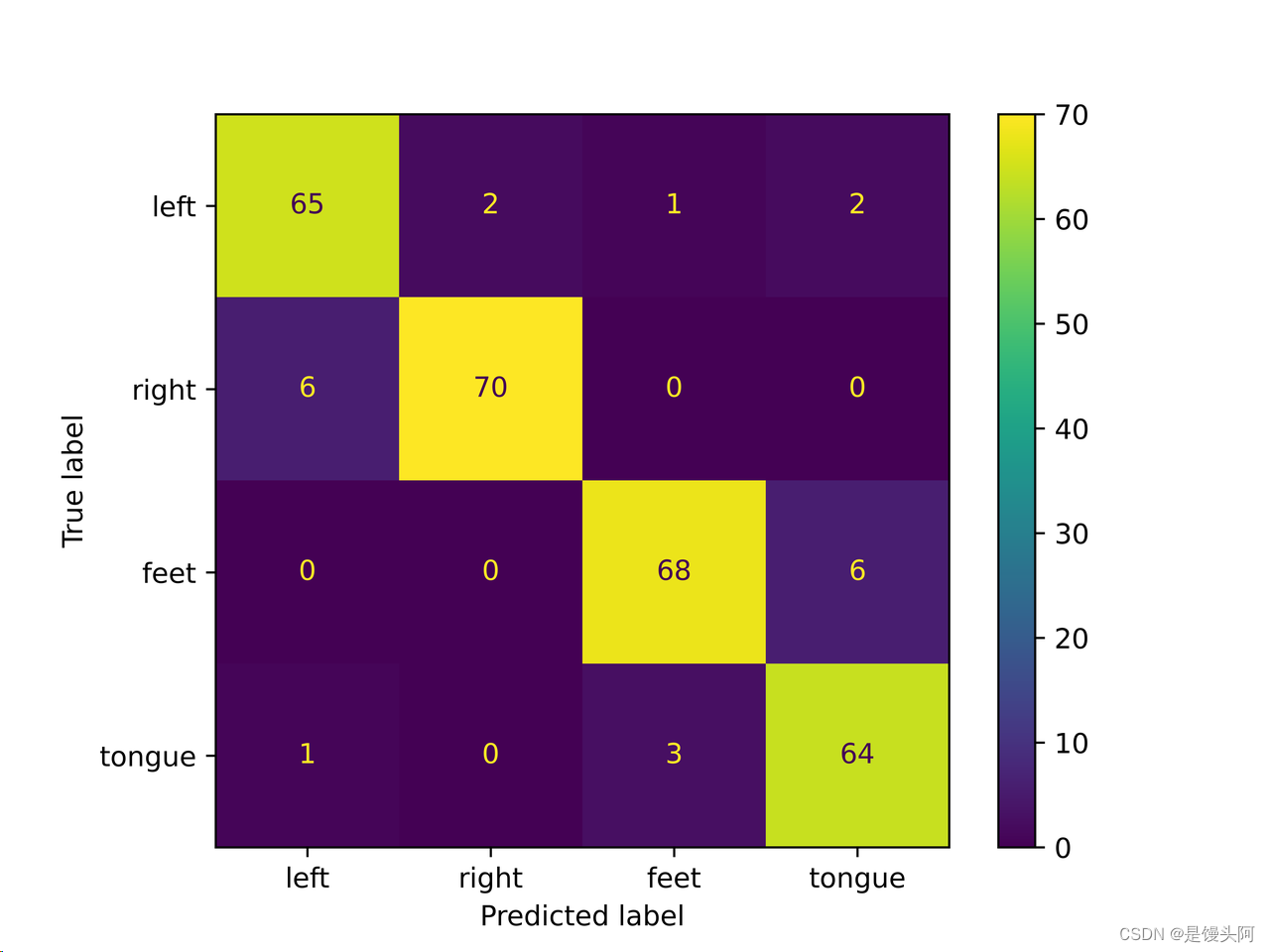
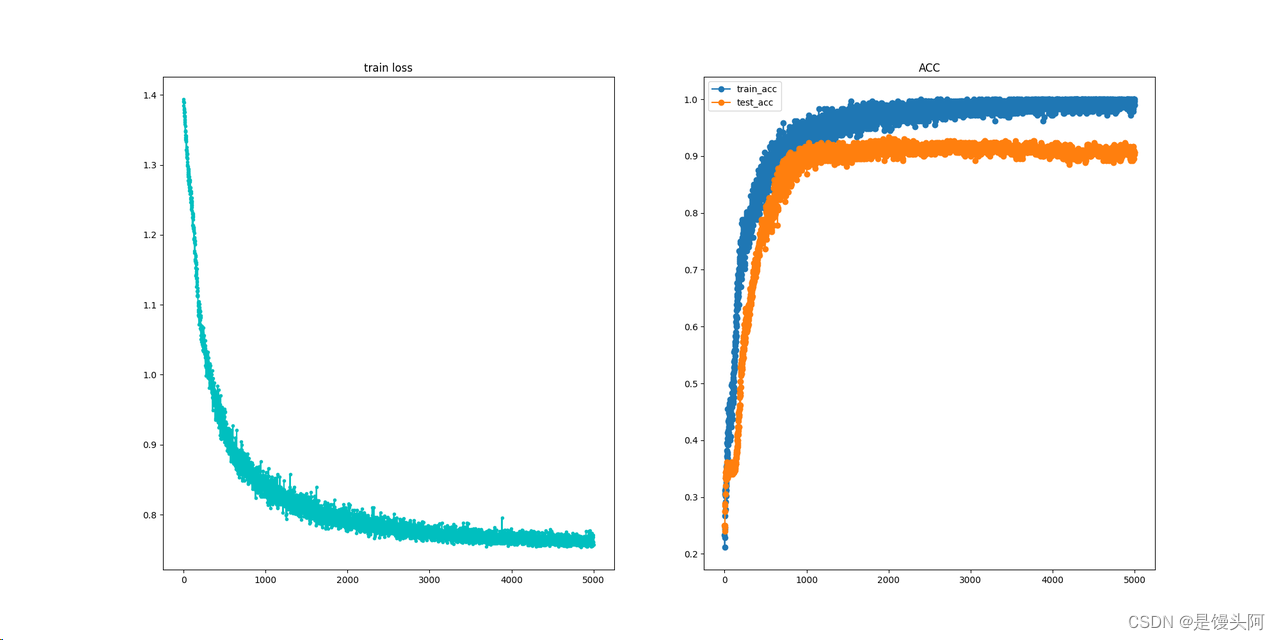
sub7:
3、EEG-TCNet pytorch实现代码:
1、 TCN_util.py
import torch
import torch.nn as nn
from torch.nn.utils import weight_norm
# from util import Conv1dWithConstraint
from util import Conv1dWithConstraint
#%%
class Chomp1d(nn.Module):
def __init__(self, chomp_size):
super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
def forward(self, x):
return x[:, :, :-self.chomp_size].contiguous()
#%%
class TemporalBlock(nn.Module):
def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2, bias=False, WeightNorm=False, max_norm=1.):
super(TemporalBlock, self).__init__()
self.conv1 = Conv1dWithConstraint(n_inputs, n_outputs, kernel_size, stride=stride, padding=padding,
dilation=dilation, bias=bias, doWeightNorm=WeightNorm, max_norm=max_norm)
self.chomp1 = Chomp1d(padding)
self.bn1 = nn.BatchNorm1d(num_features=n_outputs)
self.relu1 = nn.ELU()
self.dropout1 = nn.Dropout(dropout)
self.conv2 = Conv1dWithConstraint(n_outputs, n_outputs, kernel_size, stride=stride, padding=padding,
dilation=dilation, bias=bias, doWeightNorm=WeightNorm, max_norm=max_norm)
self.chomp2 = Chomp1d(padding)
self.bn2 = nn.BatchNorm1d(num_features=n_outputs)
self.relu2 = nn.ELU()
self.dropout2 = nn.Dropout(dropout)
self.net = nn.Sequential(self.conv1, self.chomp1, self.bn1, self.relu1, self.dropout1,
self.conv2, self.chomp2, self.bn2, self.relu2, self.dropout2)
self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None
self.relu = nn.ELU()
# self.init_weights()
# def init_weights(self):
# self.conv1.weight.data.normal_(0, 0.01)
# self.conv2.weight.data.normal_(0, 0.01)
# if self.downsample is not None:
# self.downsample.weight.data.normal_(0, 0.01)
def forward(self, x):
out = self.net(x)
res = x if self.downsample is None else self.downsample(x)
out = out+res
out = self.relu(out)
return out
class TemporalConvNet(nn.Module):
def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2, bias=False, WeightNorm=False, max_norm=1.):
super(TemporalConvNet, self).__init__()
layers = []
num_levels = len(num_channels)
for i in range(num_levels):
dilation_size = 2 ** i
in_channels = num_inputs if i == 0 else num_channels[i-1]
out_channels = num_channels[i]
layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size, padding=(kernel_size-1) * dilation_size,
dropout=dropout, bias=bias, WeightNorm=WeightNorm, max_norm=max_norm)]
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
#%%
###============================ Initialization parameters ============================###
channels = 22
samples = 250
###============================ main function ============================###
def main():
input = torch.randn(32, 1, samples)
TCN = TemporalConvNet(
num_inputs=1,
num_channels=[2],
kernel_size=4,
)
out = TCN(input)
print('===============================================================')
print('out', out.shape)
if __name__ == "__main__":
main()
2、util.py
import torch
import torch.nn as nn
from torch.autograd import Function
#%%
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
#%%
class Conv2dWithConstraint(nn.Conv2d):
'''
Lawhern V J, Solon A J, Waytowich N R, et al. EEGNet: a compact convolutional neural network for EEG-based brain–computer interfaces[J]. Journal of neural engineering, 2018, 15(5): 056013.
'''
def __init__(self, *args, doWeightNorm=True, max_norm=1, **kwargs):
self.max_norm = max_norm
self.doWeightNorm = doWeightNorm
super(Conv2dWithConstraint, self).__init__(*args, **kwargs)
# if self.bias:
# self.bias.data.fill_(0.0)
def forward(self, x):
if self.doWeightNorm:
self.weight.data = torch.renorm(
self.weight.data, p=2, dim=0, maxnorm=self.max_norm
)
return super(Conv2dWithConstraint, self).forward(x)
def __call__(self, *input, **kwargs):
return super()._call_impl(*input, **kwargs)
class Conv1dWithConstraint(nn.Conv1d):
'''
Lawhern V J, Solon A J, Waytowich N R, et al. EEGNet: a compact convolutional neural network for EEG-based brain–computer interfaces[J]. Journal of neural engineering, 2018, 15(5): 056013.
'''
def __init__(self, *args, doWeightNorm=True, max_norm=1, **kwargs):
self.max_norm = max_norm
self.doWeightNorm = doWeightNorm
super(Conv1dWithConstraint, self).__init__(*args, **kwargs)
if self.bias:
self.bias.data.fill_(0.0)
def forward(self, x):
if self.doWeightNorm:
self.weight.data = torch.renorm(
self.weight.data, p=2, dim=0, maxnorm=self.max_norm
)
return super(Conv1dWithConstraint, self).forward(x)
#%%
class LinearWithConstraint(nn.Linear):
def __init__(self, *args, doWeightNorm=True, max_norm=1, **kwargs):
self.max_norm = max_norm
self.doWeightNorm = doWeightNorm
super(LinearWithConstraint, self).__init__(*args, **kwargs)
if self.bias is not None:
self.bias.data.fill_(0.0)
def forward(self, x):
if self.doWeightNorm:
self.weight.data = torch.renorm(
self.weight.data, p=2, dim=0, maxnorm=self.max_norm
)
return super(LinearWithConstraint, self).forward(x)
#%%3、model.py
import numpy as np
import os
import sys
current_path = os.path.abspath(os.path.dirname(__file__))
rootPath = os.path.split(current_path)[0]
sys.path.append(current_path)
sys.path.append(rootPath)
import torch
import torch.nn as nn
from torchsummary import summary
from torchstat import stat
# from utils.TCN_util import TemporalConvNet
# from utils.util import Conv2dWithConstraint, LinearWithConstraint
from TCN_util import TemporalConvNet
from util import Conv2dWithConstraint, LinearWithConstraint
#%%
class TemporalInception(nn.Module):
def __init__(self, in_chan=1, kerSize_1=(1,3), kerSize_2=(1,5), kerSize_3=(1,7),
kerStr=1, out_chan=4, pool_ker=(1,3), pool_str=1, bias=False, max_norm=1.):
super(TemporalInception, self).__init__()
self.conv1 = Conv2dWithConstraint(
in_channels=in_chan,
out_channels=out_chan,
kernel_size=kerSize_1,
stride=kerStr,
padding='same',
groups=out_chan,
bias=bias,
max_norm=max_norm
)
self.conv2 = Conv2dWithConstraint(
in_channels=in_chan,
out_channels=out_chan,
kernel_size=kerSize_2,
stride=kerStr,
padding='same',
groups=out_chan,
bias=bias,
max_norm=max_norm
)
self.conv3 = Conv2dWithConstraint(
in_channels=in_chan,
out_channels=out_chan,
kernel_size=kerSize_3,
stride=kerStr,
padding='same',
groups=out_chan,
bias=bias,
max_norm=max_norm
)
self.pool4 = nn.MaxPool2d(
kernel_size=pool_ker,
stride=pool_str,
padding=(round(pool_ker[0]/2+0.1)-1,round(pool_ker[1]/2+0.1)-1)
)
self.conv4 = Conv2dWithConstraint(
in_channels=in_chan,
out_channels=out_chan,
kernel_size=1,
stride=1,
groups=out_chan,
bias=bias,
max_norm=max_norm
)
def forward(self, x):
p1 = self.conv1(x)
p2 = self.conv2(x)
p3 = self.conv3(x)
p4 = self.conv4(self.pool4(x))
out = torch.cat((p1,p2,p3,p4), dim=1)
return out
#%%
class My_Model(nn.Module):
def __init__(self, F1=32, D=2, kerSize=32, eeg_chans=22, poolSize=8, kerSize_Tem=4, dropout_dep=0.5, dropout_temp=0.5,
dropout_atten=0.3, tcn_filters=64, tcn_kernelSize=4, tcn_dropout=0.3, n_classes=4):
super(My_Model, self).__init__()
self.F2 = F1*D
self.sincConv = nn.Conv2d(
in_channels = 1,
out_channels= F1,
kernel_size = (1, kerSize),
stride = 1,
padding = 'same',
bias = False
)
self.bn_sinc = nn.BatchNorm2d(num_features=F1)
self.conv_depth = Conv2dWithConstraint(
in_channels = F1,
out_channels= F1*D,
kernel_size = (eeg_chans,1),
groups = F1,
bias = False,
max_norm = 1.
)
self.bn_depth = nn.BatchNorm2d(num_features=self.F2)
self.act_depth = nn.ELU()
self.avgpool_depth = nn.AvgPool2d(
kernel_size=(1,poolSize),
stride=(1,poolSize)
)
self.drop_depth = nn.Dropout(p=dropout_dep)
self.incept_temp = TemporalInception(
in_chan = self.F2,
kerSize_1 = (1,kerSize_Tem*4),
kerSize_2 = (1,kerSize_Tem*2),
kerSize_3 = (1,kerSize_Tem),
kerStr = 1,
out_chan = self.F2//4,
pool_ker = (3,3),
pool_str = 1,
bias = False,
max_norm = .5
)
self.bn_temp = nn.BatchNorm2d(num_features=self.F2)
self.act_temp = nn.ELU()
self.avgpool_temp = nn.AvgPool2d(
kernel_size=(1,poolSize),
stride=(1,poolSize)
)
self.drop_temp = nn.Dropout(p=dropout_temp)
self.tcn_block = TemporalConvNet(
num_inputs = self.F2,
num_channels = [tcn_filters, tcn_filters], #[64,64] 与滤波器数量一致
kernel_size = tcn_kernelSize,#4
dropout = tcn_dropout,
bias = False,
WeightNorm = True,
max_norm = .5
)
self.flatten = nn.Flatten()
self.liner_cla = LinearWithConstraint(
in_features= tcn_filters,
out_features=n_classes,
max_norm=.25
)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
if len(x.shape) is not 4:
x = torch.unsqueeze(x, 1) #升维度
x = self.sincConv(x)
x = self.bn_sinc(x)
x = self.conv_depth(x)
x = self.drop_depth(self.avgpool_depth(self.act_depth(self.bn_depth(x))))
x = self.incept_temp(x)
x = self.drop_temp(self.avgpool_temp(self.act_temp(self.bn_temp(x)))) # (batch, F1*D, 1, 15)
x = torch.squeeze(x, dim=2) # (batch, F1*D, 15)
x = self.tcn_block(x)
x = x[:, :, -1]
x = self.flatten(x)
x = self.liner_cla(x) # (batch, n_classes)
out = self.softmax(x)
return out
#%%
###============================ Initialization parameters ============================###
channels = 22
samples = 1000
###============================ main function ============================###
def main():
input = torch.randn(32, channels, samples)
# input = np.random.rand(32,channels,samples)
# input = torch.tensor(np.array(input,np.float32))
model = My_Model(eeg_chans=22, n_classes=4)
out = model(input)
print('===============================================================')
print('out', out.shape)
print('model', model)
print('===============================================================')
summary(model=model, input_size=(channels,samples), device="cpu")
#stat(model, (1, channels, samples))
if __name__ == "__main__":
main()
完事家人们,可以的话关注我吧~