深入研究IPR(积分姿态回归)
ICLR2022
论文链接
摘要: IPR 将隐式热图结合端到端训练,用于姿态估计和手势估计。基于检测的热图法使用不可微的 argmax 解码关节位置,而积分回归使用可微的期望操作。本文深入研究积分姿态回归的推理和反向传播,来更好地理解其与检测法在性能和训练方面的差异。
对于推理,我们给出了为何期望总比 argmax 好(即积分回归总是优于检测)的理论说明。但实践中这很难观察到,因为回归的热图激活很容易就收缩了。然后我们通过实验表明激活收缩是导致积分回归性能较差的主要原因之一。
对于反向传播,我们理论联系实验分析梯度,以解释积分回归训练速度慢的原因。基于这些发现,我们加入了一个空间先验监督来加速训练并提高性能。
文章目录
1 INTRODUCTION
检测法和积分法都学习一张热图来表示关键点位置的像素级似然,但检测法明确学习热图,而积分回归法隐式学习热图。将热图解码为关节坐标时,检测法使用 argmax,而积分回归法采用期望值。尽管检测法的准确性貌似更高,但由于期望运算可微,因此积分回归法具有端到端学习的优点。
[Removing the bias of integral pose regression——ICCV2021]表明,积分回归和检测方法之间存在奇怪的性能差异:通过细分评估集,发现存在较少关键点的hard样本(存在较高遮挡度和较低bbox分辨率)情况下,积分回归优于检测。 检测和积分回归都使用完全卷积的 feed-forward 架构,那么自然会产生疑问:① 这种性能差异背后的原因是什么?② 积分回归法的整体性能似乎不如检测法,但为何积分回归能够在 hard 情况下表现出色? 这些问题是我们进一步研究和分析积分姿态回归的动机。
检测法和积分回归法在 forward 和 backward 上都有所不同(如图1所示)。forward 过程中,检测法使用argmax解码热图,而积分回归使用一个 softmax normalization 和期望解码热图。

backward 过程中,检测法由以 gt 关节为中心明确定义的高斯热图监督,而积分回归由关节坐标直接监督。通过对解码和反向传播过程的详细理论分析和实验,我们的贡献如下:
- 我们提出了一个统一热图模型来解释并比较积分回归方法。我们通过实验验证了模型,随着样本从hard到easy的转变,检测法和积分回归法的热图激活区域都会缩小。
- 实验表明,退化的小激活区域会降低检测法和积分回归法的准确性。
- 与使用 argmax 解码的检测方法相比,使用期望解码热图的积分回归法应该会导致更低的预期 end-point 误差。实际上,由于热图激活区域的收缩,这只能在 hard 样本中观察到。
- 积分回归使用关节坐标直接监督,尽管是端到端的,但会受梯度消失的影响,且学习热图的空间线索也更少。因此,积分回归训练比检测法效率更低,收敛速度更慢。
我们的发现为具有更好理论性能的积分姿态回归提供了见解,并表明热图的密度对热图解码至关重要。
2 RELATED WORK
数值回归法的精度不高,为了提高精度,积分回归法试图通过“潜在”热图隐式结合热图的空间知识。积分回归常用于手势估计中,在姿态估计任务中用的少。
最近有两个平行的工作分别分析检测法和积分回归方法。对于基于检测的方法,[The devil is in the details: Delving into unbiased data processing for human pose estimation——cvpr 2020] 确定了由坐标系变换的不一致性引起的热图偏差,并通过在数据处理过程中重新设计变换来消除偏差。此外,由于推理过程中预测的热图可能不遵循高斯假设从而降低性能,[The devil is in the details]提出基于预测找到最佳高斯位置,而 [Distribution-aware coordinate representation for human pose estimation——cvpr2020] 调制预测的高斯分布进行解码。
对于积分回归方法,[Numerical coordinate regression with convolutional neural networks] 通过实验比较了不同的热图 regularizers、热图 normalization schemes和损失函数,并发现,在运用softmax normalization 和 L1 损失的热图上使用 JensenShannon regularization 可以实现积分回归的最佳性能。最近,Gu等人系统比较了 backbone 相同的检测法和积分回归法,并发现积分回归法在 “hard” 样本上性能更优越。此外,Gu等人揭示了因在 softmax normalization 后采用期望值会产生偏差,因此,他们提出了一种补偿方案来减轻偏差从而提高积分回归法的整体性能。
3 Preliminaries on HPE
本工作基于 top-down 方法,且重点在于对一个 cropped 人体图片 I 中估计出人体的 K 个关节。姿态估计模型输出一张热图 H ^ ∈ R M × N \hat{H}∈R^{M×N} H^∈RM×N,M N 是热图的空间大小且一般为图像I大小的1/4。热图 H ^ \hat{H} H^表示一个离散的空间似然 P ( J ∣ I ) , J ∈ R 1 × 2 P(J|I), J∈R^{1×2} P(J∣I),J∈R1×2 表示关节的2D坐标。网络一次性预测K张热图,每张热图表示一个关节点,检测法和回归法都从 H 中解码 J,只是两方法在解码方式(见3.1节)和监督形式上有所不同
3.1 Heatmap decoding: Max vs Ecpected value
检测法对热图上索引为p的位置运用argmax来估计关节坐标:

假设热图与似然成比例,取argmax相当于在热图上取了一个最大似然。实践中,考虑到 H ^ \hat{H} H^是离散热图的一种量化方式,最终的 J ^ d e \hat{J}_{de} J^de 实际为 H ^ \hat{H} H^ 上最高和次高响应的线性组合。最近的一个工作 DARK 通过在热图的最大激活处采用泰勒级数来逼近真实预测来提高准确性。
积分姿态回归计算 H ^ \hat{H} H^的期望值,以给出关节坐标的平均估计。先对热图应用归一化(常用 softmax normalization) 使其和为1,然后对归一化后的热图(位置P的值为 h ^ P \hat{h}_{P} h^P)取期望来确定具有x, y 分量 J ^ x 、 J ^ y \hat{J}_x、\hat{J}_y J^x、J^y 的关节点坐标 J ^ r e \hat{J}_{re} J^re:

请注意,softmax归一化会为 H ^ \hat{H} H^ 中的所有像素分配一个非零值,这些非0值都会对期望值做贡献,就会导致 J ^ r e \hat{J}_{re} J^re出现偏差。β越小,偏差越大,为了进行分析,我们假设β足够大以忽略偏差的影响。
3.2 Supervision: Explicit heatmap vs GT coordinates
检测法通过热图来监督。以 gt 关节点坐标为中心生成高斯热图作为GT热图,并对GT热图和预测热图应用 pixel-wise MSE loss:
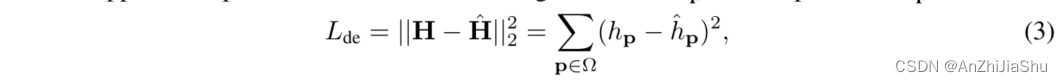
Ω是热图区域。由于 loss 是根据热图而非预测关节坐标来定义的,因此基于检测的方法并非端到端的。
积分姿态回归对预测关节坐标和GT关节坐标应用 L1 loss:
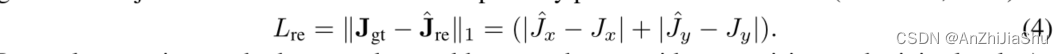
积分回归方法是端到端的,。由于只是隐式学习热图,因此一些工作将热图称为“潜在”热图。
3.3 Performance differences
Gu等人使用相同的 backbone 更系统、详细的进行了比较,并且他们还基于3个主要因素对数据集进行了更详细的划分:① 场景存在的关节数量、② 遮挡百分比、③边界框输入分辨率。“hard” 样本指存在1-5个关节、>50%遮挡或32-64px输入的样本。对于这些样本,积分回归的 end-point error(EPE)平均比检测低15%。“easy” 样本指11-17个关节、<10%的遮挡或>128px的输入,这些情况下,检测方法稍微好一些。介于两种样本之间的称为 ”medium“ 样本,在该情况下,两方法的性能相当。
4 Analysis on heatmap decoding

4.1 Localized heatmap model
为了更好的分析差异,先对热图做以下假设:首先,假设模型生成的热图 h ^ P \hat{h}_P h^P 在 J ^ \hat{J} J^ 的局部 support 区域 Φ 有显著或大值,Φ外区域的值接近0(见图2(a))。
具体而言,normalized 热图 H ^ \hat{H} H^ 由一些密度分布 P \mathcal{P} P 建模,我们不假设 P \mathcal{P} P的形式,但假设它完全捕获了Φ内关节位置的support,并且Φ以区域 (2s+1, 2s+1) ,位置 µ=(µx,µy) 上的 P \mathcal{P} P 的期望值为中心,即:
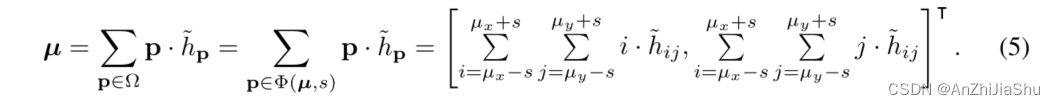
局部热图模型的实验验证: 对检测法而言,局部激活的假设是合理的,因为检测法明确学习热图来匹配GT Gaussian。我们基于 3.3节规定的 easy/medium/hard 分割的数据,通过计算检测法和回归法的 normalized 热图激活来验证模型。
具体而言,我们基于 SBL(ResNet-50) backbone 分别采用检测法和回归法训练姿态估计网络,并将网络应用于划分easy、medium、hard样本的COCO数据集。对于每张生成的64×48大小的热图,通过对gt 关节坐标 ( J x , J y ) (J_x,J_y) (Jx,Jy)周围(2s+1)×(2s+1)的方形区域求和来估计激活和 A:

由图2(b)所示,当s足够大时(例如9),激活和超过95%。
4.2 Extreme localization as a cause for performance differences
Expected End-Point Error (EPE). 对于检测法,假设每个位置 P 是最大激活值的概率 w(μ,s) 相等,即 a r g m a x ( P ) Φ ( μ , s ) ∼ w ( μ , s ) argmax(\mathcal{P})_{Φ(μ,s)}\sim w(μ,s) argmax(P)Φ(μ,s)∼w(μ,s)。w(μ,s) 表示以 µ 为中心的一个放射状对称分布,所有非零 support 都包含在Φ内。因此,检测法的一个样品的预期EPE可以定义为:

对于积分回归法,估计的关节坐标与Φ的中心对齐,即 J ^ = μ \hat{J}=\mu J^=μ,因此单个样本的预期EPE如下:

这一结果表明,对于一些固定的(µ,s),回归的预期EPE应该总是优于检测,但3.3节的结果并非如此。通过以下两个实验可以更好理解这种不一致性。
Experimental Verification: Integral Regression Methods Are “More” Localized than Detection. 图2(b) 的曲线图表明,回归法似乎比检测方法更 Localized,特别当 s 较小时,检测法的A小于积分回归法。为进一步验证,我们将热图与具有不同标准差σ的理想化高斯热图进行了比较,并绘制了给出最低 Pearson Chi-square 统计σ,即图2(c)中不同难度级别的最高相似性。正如预期那样,随着样本从 hard 到 easy,最佳σ会降低;这一结果与图2(b)一致,这表明对 easy 样本,热图更局部化。但我们也观察到,对于 medium 和 easy ,积分回归的最优 σ 要小得多。我们推测,产生这种差异是因为检测方法是用 σ=2 的高斯热图训练的,而积分回归方法没有这样明确的监督,因此对局部化程度没有限制。
Experimental Verification: Extremely Localized Heatmaps Degrade Performance. 较小的假设σ,即更 localized 热图,是否会降低性能呢? 我们通过应用 σ 变化的 GT 高斯热图来训练网络,并使用平均精度(AP)评估网络性能,来验证检测方法。图2(d)可以看出σ=2最优,较小的σ会略微降低性能,当σ=0.5的极端情况下性能会显著下降。
为了验证 σ 对回归方法的影响,我们给热图添加了一个分布先验,以防止 support 区域Φ的收缩。具体而言,我们在 non-normalized H ^ \hat{H} H^和具有变化σ的高斯热图之间应用了一个 Kullback-Leibler Divergence (KLDiv) loss。 表1中可以看出,回归 baseline 差于检测 baseline。但当我们在热图分布上添加先验以鼓励足够大的 Φ,即(+σ=1,2,3)时,性能会提高。在最优+σ=2时,积分回归相比于具有最优σ的检测 baseline 不相上下。最重要的是,极端σ值会导致性能退化,尤其在极小+σ=0.5的情况下。
我们还通过AP和激活和A(s=2)验证了 easy/medium、hard的性能和 localization程度。在加先验(例如,+σ=2)后,A(s=2)e/m从0.65下降到0.54,表明热图 less localized,more APe/m。

5 Analysis of supervision and learning
给定相同热图,不同的热图解码方法不仅会影响最终坐标,还会影响产生损失的梯度。梯度反过来会影响学习,从而改变热图的生成。本节探讨了应用检测和积分回归方法损失函数的热图的梯度,并指出拖慢积分回归学习的特定梯度分量。
5.1 Heatmap Gradients
检测法: L d e L_{de} Lde相对于估计热图 h ^ P \hat{h}_P h^P 中的每个像素的梯度直接可以求:

公式9的梯度特征化了预测热图值 h ^ P \hat{h}_P h^P 和 gt 热图值 h P h_P hP。它明确监督每个像素,通过减少wrong high likelihoods 来惩罚False Poseitives,通过提高 incorrect low likelihoods 来惩罚False Negatives。对于热图中的每个位置 P ,若预测热图小于gt热图,则梯度为负,且在下一次迭代中按比例增加该值,反之亦然。
积分回归: 损失 L r e L_{re} Lre 的梯度(eq(4))相对于 h ^ P \hat{h}_P h^P 可以基于链式规则估计为:

Eq.10 的梯度被划分为两部分:value fator 和 location factor,二者的性质能很好的表明积分回归法的学习过程。首先,梯度与 value fator 中给定的 normalized 预测热图值 h ^ P \hat{h}_P h^P 成比例,使其易于在位置P具有小热图预测的地方发生梯度消失。第二, location factor 是 i 和 j 的线性组合,表现为线性平面;像角这样的远点更有可能具有较大的 magnitude。尽管这两个 factor 并不能阻止学习过程中损失的减少,但它们会减缓训练。
5.2 积分回归热图的详细分析
当提到热图的区域 Ω 时,使用原点在左上角的坐标系,并将坐标增加到右下角(图2(a))。为了简化讨论,假设 J g t J_{gt} Jgt 位于Ω的右下象限,另外三种情况类似。

我们的分析一致假设:更大 magnitude 的梯度对网络权重的影响更大,并会在下一次迭代中在位置p处引起更大的变化,即:

其中 γ 表示步长或学习率,n表示更新迭代。由于 value fator 和 location factor 对 Eq.10 中的梯度有不同的贡献,而它们反过来又受 Φ的大小s和位置µ的影响,我们可以定义Φ的四个特征情况,并讨论在每种情况下学习如何被影响。
(1) s is large, Φ has uniformly random values,例如在训练开始时随机初始化的热图。由于对于所有的 P , h ^ P \hat{h}_P h^P 都在相似的范围内,因此所有像素的 value fator 近似相似,因此,一个像素梯度和另一个像素梯度间的区别由 location factor 决定。 假设 gt 坐标 ( J x , J y ) (J_x, J_y) (Jx,Jy) 位于右下象限,只要 ( J x , J y ) (J_x, J_y) (Jx,Jy) 都大于预测坐标 ( J ^ x , J ^ y ) (\hat{J}_x, \hat{J}_y) (J^x,J^y) ,则梯度朝右下角逐渐增加。一般来说简而言之,location factor 将热图激活推向正确象限的角落,location factor的合成线性平面中角落具有最大的梯度。
(2) s is small, µ is far from the ground truth J, 例如,µ位于Ω的左上角而 J g t J_{gt} Jgt在右下角。一种典型的情况是,对于gt右脚踝,热图在左脚踝周围激活。这种情况下,对于Φ外的像素,value fator 接近零,即 h ^ P \hat{h}_P h^P→ 0,并将梯度推向零,因此像素的梯度更新非常有限。对于 Φ 中的像素,值逐渐减小,直到Φ外的 value factor 不再占主导地位,即它们达到相同的 scale,此时热图返回到情况(1)。
(3) s is small, µ is in the corner of the same quadrant as the ground truth J g t J_{gt} Jgt. 这种情况最开始与情况(2)类似。在所有元素变成相同 scale 的过程中,所有的激活都朝对角线一侧移动,且预测趋近 gt 坐标。
(4) s is small, µ close to ground truth J g t J_{gt} Jgt. 当模型经过合理训练且可以粗略定位关节时,就会出现这种情况。gt 像素 J g t J_{gt} Jgt 处的梯度总<=0(non-positive),即:

这个 non-positive 值引导网络在 gt 位置预测一个大的热图响应,即,一个大的 h ^ ( J x , J y ) \hat{h}_{(J_x,J_y)} h^(Jx,Jy),这反过来又增加了梯度。这种特性使网络更有可能预测几个异常大的像素,从而缩小 support 区域Φ,并导致第4.1节中的σ非常小。
对于基于检测的方法,gt 热图已经明确指出了热图中是否应激活某像素。结合其有效的 pixel-wise 损失,该网络比回归法学习得更快;这将在下一节中得到验证。
5.3 Experimental Verification
Idealized Sample. 我们先考虑单个关节的一个样本的情况,并可视化被Eq.11更新的一个 (64,48)热图的进展。我们在Pytorch中使用autograd来获得梯度。5.2节中的四种情况是随机初始化的,一个对称高斯(σ=2) 以左上角某点为中心,其线性平面位于右下象限,以及一个以 gt 为中心的对称高斯(σ=2)。图3 可以观察到不同初始化热图的进展。
从数学上讲, Eq.2 可以清楚看出,即使潜在热图不遵循局部热图模型,积分回归得到的关节坐标位置也可以与 gt 关节对齐。5.2节中讨论的前三种情况也说明了这一点。然而,根据许多 epoch 中观察到的数千个训练样本,我们推测,在 real-world 训练过程中,只有学习热图 H ^ \hat{H} H^ 来表示P(J|I),网络损失才能始终如一地降低。因此,激活区域Φ将被正确定位在图像相应的语义区域上。相反,Φ的学习会拖慢收敛,或者更确切地说,缺乏根据检测法生成的正确Φ的直接指导会拖慢收敛。对于相同的四种情况,我们根据 Eq.9 中的检测 loss 定义的梯度来可视化 Eq.11的更新热图。
Real World Samples. 5.2节中列出的四种情况在真实世界的训练中并不那么明显,因为输出是基于真实网络中 batch-wise 训练的优化结果。为了验证结果,我们比较了4.1节所述的实验设置下检测和积分回归网络的训练进度。图4(b)比较了检测和积分回归的训练速度,可以看出积分回归的收敛速度较慢。
我们对MSCOCO val set 的一个样本在 epoch=1和10的热图进行可视化,以比较检测和积分回归的训练进展。图4(a)显示了“左眼”和“右脚踝”关节热图。对于回归,在一个epoch后,激活分布在热图的1/4——1/2。这大致与Case1和Case3的混合一致,其中激活处于正确的象限,但尚未局限于一个小的support 区域。经过10个epoch的训练后,对左眼(实际上被遮挡,为“hard”样本)的预测被定位为几个近似相同值的激活(均显示为红色)。对于右脚踝(“easy”样本),该网络预测在空间上已经塌陷并在一个或两个像素位置处占主导地位的热图值。
相反,检测法仅在一个epoch的训练后就呈现出一个 well-localized 的热图。虽然在epoch 1中左脚踝有一些激活,但这不太可能导致argmax解码错误。在10个 epoch 之后,所有的激活都集中在正确的右脚踝周围。

6 CONCLUSION
本文通过比较检测法和积分回归法之间热图激活和梯度的差异,深入研究了积分姿态回归。我们的理论分析和实验结果表明,与检测相比,积分回归方法的热图收缩是其性能较低的主要原因。此外,我们通过给出理论证据、toy problem 和真实世界例子来研究积分回归的梯度,以表明隐含的监督信号导致积分回归的学习收敛较慢。为了缓解收敛缓慢和性能不佳的问题,我们在现有框架的基础上提出了一个简单的空间监督。