算法原理及YOLOV5实现
YOLOv5是一种面向实时工业应用的开源目标检测算法,受到了广泛的关注。YOLOv5之所以能火爆,并不仅仅是因为其优异的性能。它更多的是关于其库的整体实用性和稳健性。简而言之,YOLOv5的主要特点是:
(1)友好完善的部署支持
(2)训练速度快:300 epoch 情况下的训练时间与大多数 12 epoch 下的一阶段和两阶段算法相似,例如 RetinaNet、ATSS 和 Faster R-CNN。
(3)针对极端情况的丰富优化:YOLOv5 实现了许多优化。功能和文档也更加丰富。
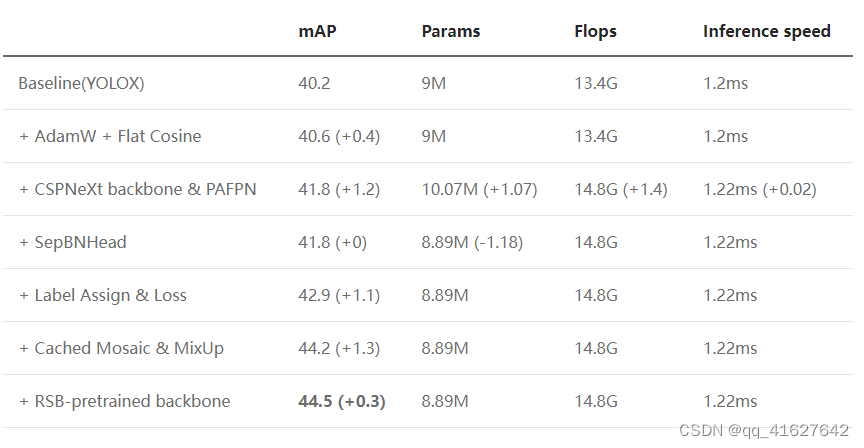
图1和图2显示YOLOv5的P5和P6版本之间的主要区别在于网络结构和图像输入分辨率。其他差异,例如锚点数量和损失权重,可以在配置文件中找到。本文将从YOLOv5算法的原理开始,然后重点分析MMYOLO中的实现。后续部分包括YOLOv5的指南和速度基准。

图1:YOLOv5-l-P5模型结构
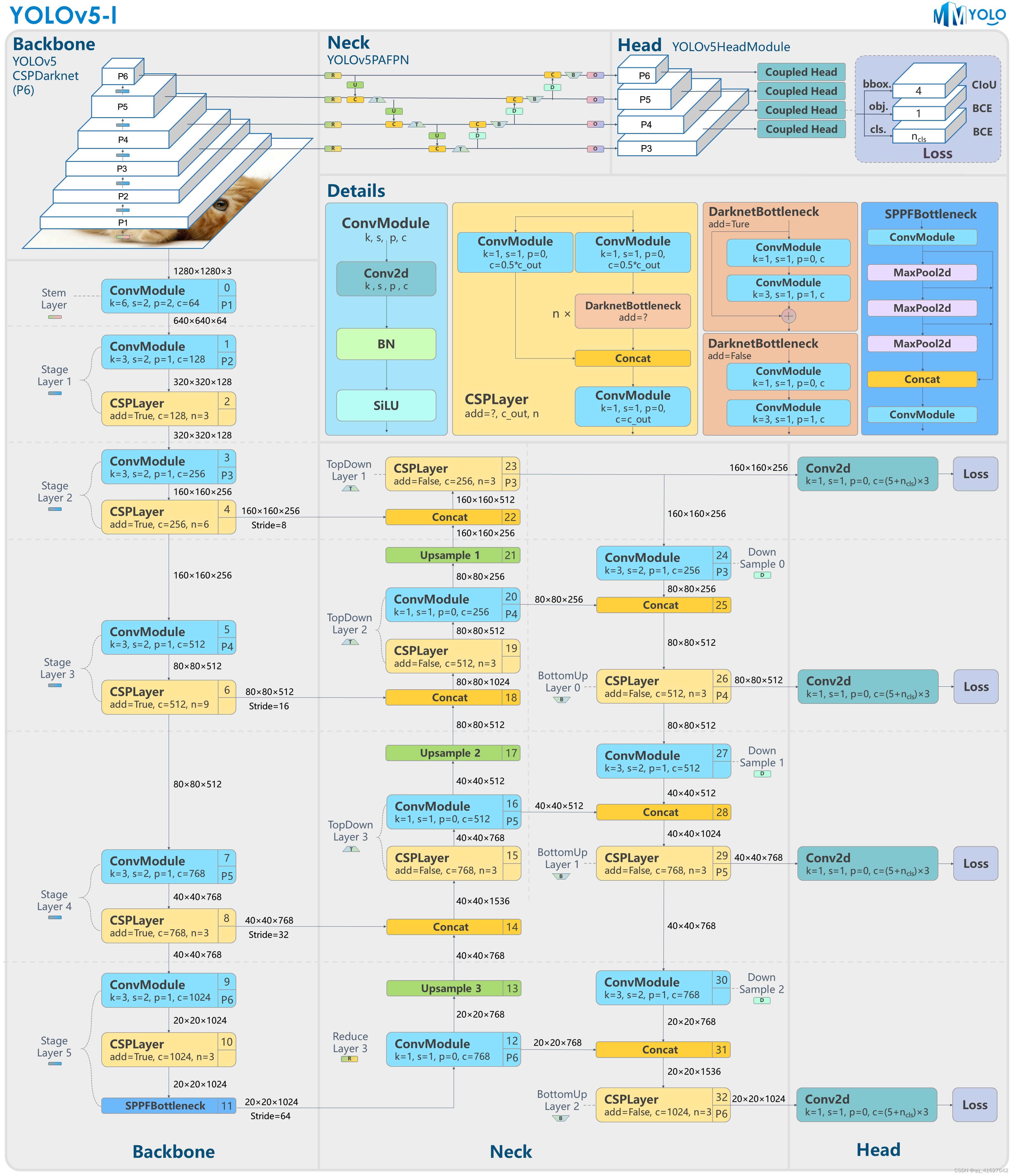
图2:YOLOv5-l-P6模型结构
注意:如无特殊说明,本文档默认描述P5型号。
我们希望本文成为您入门和掌握 YOLOv5 的核心文档。由于YOLOv5还在不断更新,我们也会不断更新这个文档。因此,请始终赶上最新版本。
MMYOLO实现配置:https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/
YOLOv5官方存储库:https://github.com/ultralytics/yolov5
v6.1算法原理及MMYOLO实现分析
OLOv5官方发布:https://github.com/ultralytics/yolov5/releases/tag/v6.1
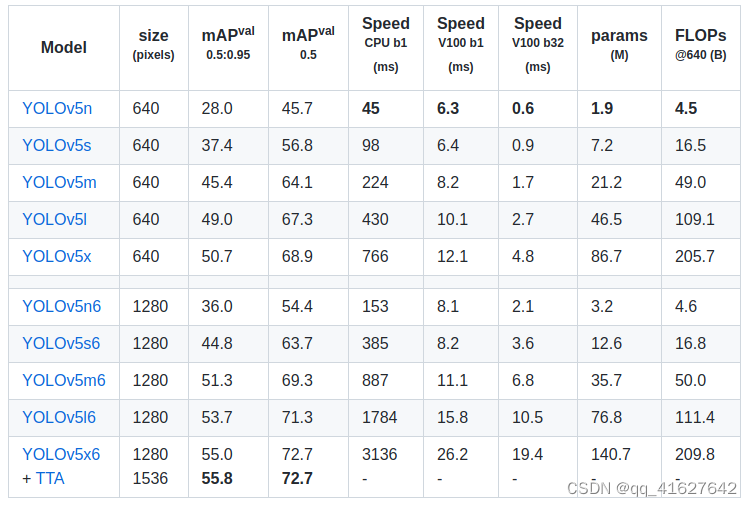
性能如上表所示。YOLOv5有两个不同尺度的模型。P6 较大,输入尺寸为 1280x1280,而 P5 是更常用的模型。本文重点介绍P5模型的结构。
通常,我们将目标检测算法分为不同的部分,例如数据增强、模型结构、损失计算等。与YOLOv5相同:
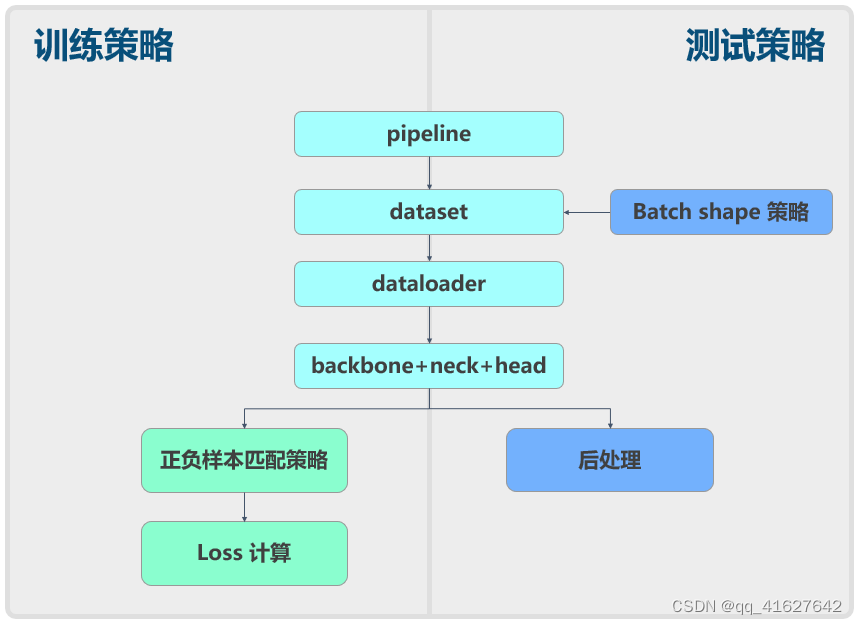
现在我们简单分析一下原理以及我们在MMYOLO中的具体实现。
1.1 数据增强
YOLOv5 中使用了许多数据增强方法,包括:
**
Mosaic马赛克
RandomAffine随机仿射
MixUp混合
Image blur and other transformations using Albu使用 Albu 进行图像模糊和其他变换
HSV color space enhancement HSV 色彩空间增强
Random horizontal flips 随机水平翻转**
mosaic马赛克概率设置为1,因此它会一直被触发。small and nano models没有使用MixUp,概率是0.1其他l/m/x系列模型概率是0.1。由于小模型的能力有限,我们通常不会使用像 MixUp 这样强大的数据增强功能。
yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py
_base_ = './yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
# ========================modified parameters======================
deepen_factor = 0.67
widen_factor = 0.75
lr_factor = 0.1
affine_scale = 0.9
loss_cls_weight = 0.3
loss_obj_weight = 0.7
mixup_prob = 0.1
# =======================Unmodified in most cases==================
num_classes = _base_.num_classes
num_det_layers = _base_.num_det_layers
img_scale = _base_.img_scale
model = dict(
backbone=dict(
deepen_factor=deepen_factor,
widen_factor=widen_factor,
),
neck=dict(
deepen_factor=deepen_factor,
widen_factor=widen_factor,
),
bbox_head=dict(
head_module=dict(widen_factor=widen_factor),
loss_cls=dict(loss_weight=loss_cls_weight *
(num_classes / 80 * 3 / num_det_layers)),
loss_obj=dict(loss_weight=loss_obj_weight *
((img_scale[0] / 640)**2 * 3 / num_det_layers))))
pre_transform = _base_.pre_transform
albu_train_transforms = _base_.albu_train_transforms
mosaic_affine_pipeline = [
dict(
type='Mosaic',
img_scale=img_scale,
pad_val=114.0,
pre_transform=pre_transform),
dict(
type='YOLOv5RandomAffine',
max_rotate_degree=0.0,
max_shear_degree=0.0,
scaling_ratio_range=(1 - affine_scale, 1 + affine_scale),
# img_scale is (width, height)
border=(-img_scale[0] // 2, -img_scale[1] // 2),
border_val=(114, 114, 114))
]
# enable mixup
train_pipeline = [
*pre_transform, *mosaic_affine_pipeline,
dict(
type='YOLOv5MixUp',
prob=mixup_prob,
pre_transform=[*pre_transform, *mosaic_affine_pipeline]),
dict(
type='mmdet.Albu',
transforms=albu_train_transforms,
bbox_params=dict(
type='BboxParams',
format='pascal_voc',
label_fields=['gt_bboxes_labels', 'gt_ignore_flags']),
keymap={
'img': 'image',
'gt_bboxes': 'bboxes'
}),
dict(type='YOLOv5HSVRandomAug'),
dict(type='mmdet.RandomFlip', prob=0.5),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
'flip_direction'))
]
train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
default_hooks = dict(param_scheduler=dict(lr_factor=lr_factor))
下图演示了该过程。Mosaic + RandomAffine + MixUp
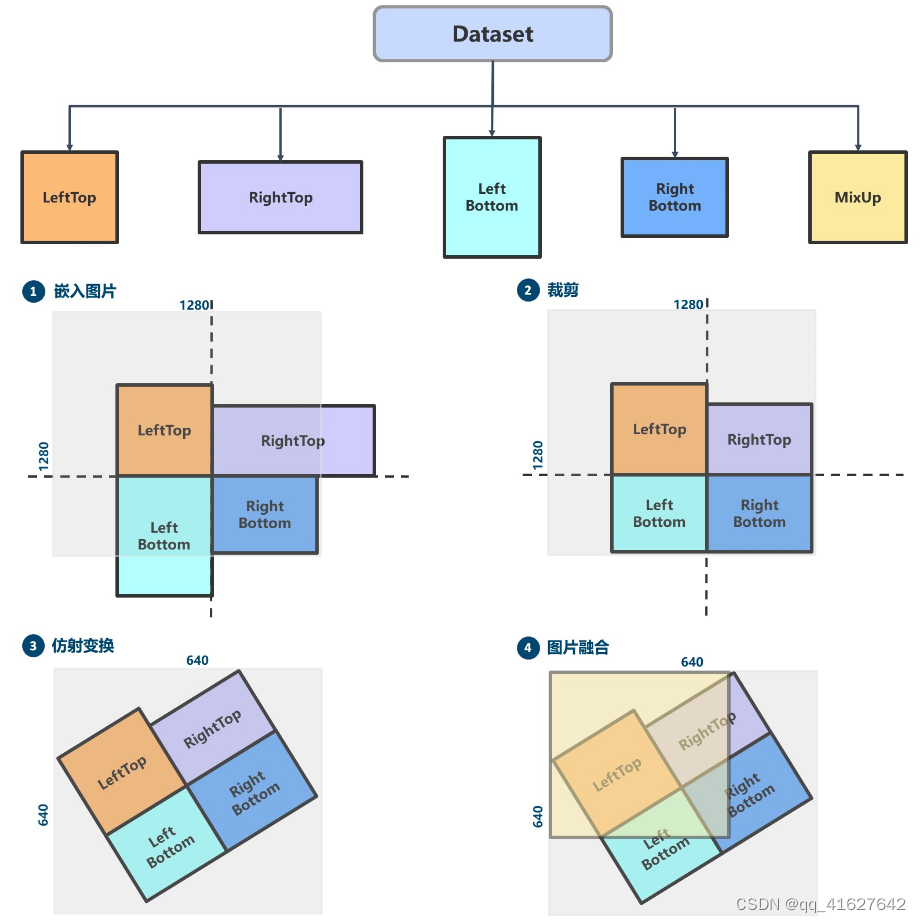
1.1.1 Mosaic马赛克

Mosaic马赛克是一种混合数据增强方法,需要将四张图像拼接在一起,这相当于增加训练批量大小。
我们可以将这个过程总结为:
随机生成四张拼接图像的交点坐标。
随机选择其他三张图像的索引并读取相应的注释。
通过保持纵横比将每个图像的大小调整为指定大小。
根据上、下、左、右规则计算每幅图像在输出图像中的位置。您还需要计算裁剪坐标,因为图像可能超出范围。
使用裁剪坐标裁剪缩放后的图像并将其粘贴到计算的位置。其余的地方将用114 pixels 来填充。
相应地处理每个图像的标签。
注意:由于四张图像拼接在一起,因此输出图像区域将放大四倍(从 640x640 到 1280x1280)。因此,要恢复为 640x640,您必须添加RandomAffine转换。否则,图像区域将始终增大四倍。
1.1.2 RandomAffine

RandomAffine 有两个目的:
对图像执行随机几何仿射变换。
将 Mosaic 生成的图像尺寸缩小至 640x640。
RandomAffine 包括平移、旋转、缩放、错位等几何增强。由于 Mosaic 和 RandomAffine 是强增强,因此它们会引入相当大的噪声。因此,需要对增强标注进行处理。规则是
增强型gt bbox的宽高要大于wh_thr;
增强前后gt bbox的面积比要大于ar_thr,防止变化太大。
最大纵横比应小于area_thr,以防止其变化太大。
物体检测算法很少会使用这种增强方法,因为旋转后注释框会变大,导致不准确。
1.1.3 mix混合
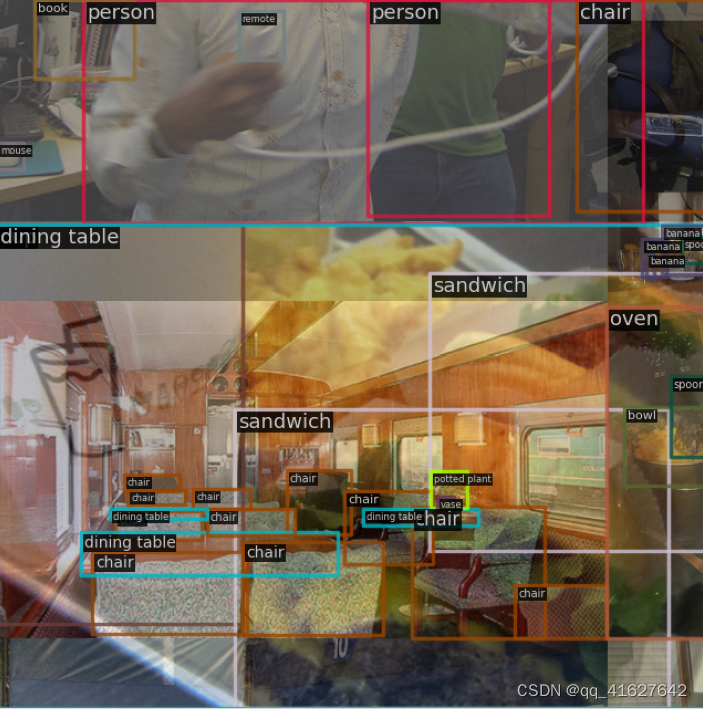
MixUp,与Mosaic类似,也是一种混合图像增强。它随机选择另一个图像并将两个图像混合在一起。有多种方法可以做到这一点,典型的方法是直接将标签缝合在一起或使用混合标签的alpha方法。原作者的做法很简单:直接拼接标签,通过分布式采样混合图像。
注意:在YOLOv5的MixUP实现中,在混合过程之前必须先对另一张随机图像进行Mosaic+RandomAffine处理。这可能与其他开源库中的实现不同。
1.1.4 图像模糊和其他增强

其余的增强是:
使用 Albu 进行图像模糊和其他变换
HSV 色彩空间增强
随机水平翻转
Albu库已经封装在MMDetection中,用户可以通过简单的配置直接使用Albu的所有方法。HSV作为一种非常普通且常见的处理方法,现在不再进一步介绍。
1.1.5 MMYOLO 中的实现
虽然随机翻转等传统的单图像增强相对容易实现,但马赛克等混合数据增强则更为复杂。因此,在MMDetection对YOLOX的重新实现中,引入了一个名为MultiImageMixDataset的数据集包装器。流程如下:
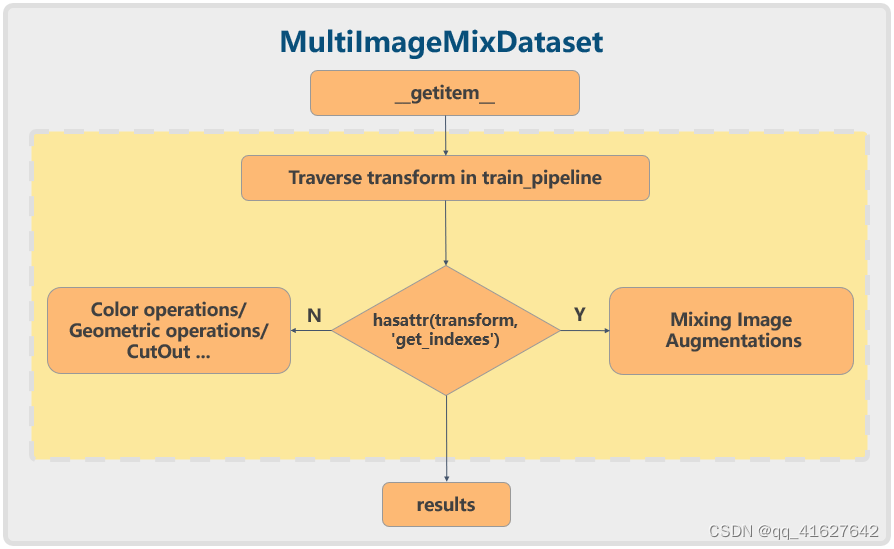
对于Mosaic等混合数据增强,您需要实现一个额外的get_indexes方法来检索其他图像的索引信息,然后执行增强。以MMDetection中YOLOX的实现为例。配置文件是这样的:
train_pipeline = [
dict(type='Mosaic', img_scale=img_scale, pad_val=114.0),
dict(
type='RandomAffine',
scaling_ratio_range=(0.1, 2),
border=(-img_scale[0] // 2, -img_scale[1] // 2)),
dict(
type='MixUp',
img_scale=img_scale,
ratio_range=(0.8, 1.6),
pad_val=114.0),
...
]
train_dataset = dict(
# use MultiImageMixDataset wrapper to support mosaic and mixup
type='MultiImageMixDataset',
dataset=dict(
type='CocoDataset',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
]),
pipeline=train_pipeline)
MultiImageMixDataset传入了数据增强方法,包括Mosaic和RandomAffine。CocoDataset 还添加了一个管道来加载图像和注释。这样,可以快速实现混合数据增强方法。
然而,上述实现有一个缺点:对于不熟悉 MMDetection 的用户来说,他们经常忘记 Mosaic 必须与 MultiImageMixDataset 一起使用。否则,它将返回错误。另外,这种方法增加了理解的复杂性和难度。
为了解决这个问题,我们在MMYOLO中进一步简化了它。通过使数据集对象可以直接访问管道,混合数据增强的实现和使用可以与随机翻转相同。
MMYOLO中YOLOX的配置写法如下
pre_transform = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
]
train_pipeline = [
*pre_transform,
dict(
type='Mosaic',
img_scale=img_scale,
pad_val=114.0,
pre_transform=pre_transform),
dict(
type='mmdet.RandomAffine',
scaling_ratio_range=(0.1, 2),
border=(-img_scale[0] // 2, -img_scale[1] // 2)),
dict(
type='YOLOXMixUp',
img_scale=img_scale,
ratio_range=(0.8, 1.6),
pad_val=114.0,
pre_transform=pre_transform),
...
]
这消除了对 MultiImageMixDataset 的需要,并使其更易于使用和理解。
回到YOLOv5配置,由于MixUp中另一张随机选取的图像也需要经过Mosaic+RandomAffine增强后才能使用,因此YOLOv5-m数据增强配置如下。
pre_transform = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
]
mosaic_transform= [
dict(
type='Mosaic',
img_scale=img_scale,
pad_val=114.0,
pre_transform=pre_transform),
dict(
type='YOLOv5RandomAffine',
max_rotate_degree=0.0,
max_shear_degree=0.0,
scaling_ratio_range=(0.1, 1.9), # scale = 0.9
border=(-img_scale[0] // 2, -img_scale[1] // 2),
border_val=(114, 114, 114))
]
train_pipeline = [
*pre_transform,
*mosaic_transform,
dict(
type='YOLOv5MixUp',
prob=0.1,
pre_transform=[
*pre_transform,
*mosaic_transform
]),
...
]
1.2 网络结构
YOLOv5网络结构是标准的CSPDarknet + PAFPN + non-decoupled Head
YOLOv5网络结构的大小由deepen_factor和widen_factor参数决定。deepen_factor控制网络结构的深度,即 in CSPLayer DarknetBottleneck modules 堆栈数量。widen_factor控制网络结构的宽度,即模块输出特征图的通道数。以YOLOv5-l为例。它的。整体结构如上图所示。 Its deepen_factor = widen_factor = 1.0
图的上半部分是模型的概览;下半部分是具体的网络结构,其中各个模块都用数字连续标注,方便用户对应YOLOv5官方仓库的配置文件。中间部分是各个子模块的详细组成。
如果您想使用netron可视化网络结构的详细信息,请在netron中打开MMDeploy导出的ONNX文件格式。
1.2.1 主干网
CSPDarknet在 MMYOLO 继承自BaseBackbone。整体结构类似ResNet共有5层设计,including one Stem Layer and four Stage Layer。
Stem Layer is a ConvModule whose kernel size is 6x6. It is more efficient than the Focus module used before v6.1.
Stem Layer是一个ConvModule,内核大小为 6x6 。它比v6.1 之前使用的Focus模块效率更高。
除了最后一层之外,每个Stage Layer都由ConvModule and one CSPLayer组成,如上图中的详细信息部分所示。ConvModule是一个 3x3 Conv2d + BatchNorm + SiLU activation function module。CSPLayer是YOLOv5官方存储库中的C3模块,由带有残差连接的three ConvModule + n DarknetBottleneck 组成。
最后一个 Stage Laye在末尾添加一个SPPF module模块。该模块是通过多个5x5MaxPool2d layers对输入进行序列化,与该SPP module 模块效果相同但速度更快。
P5模型将第二个到第四个的相应结果传递给Neck 结构体并提取三个输出特征图。以 640x640 输入图像为例。输出特征为(B,256,80,80)、(B,512,40,40)和(B,1024,20,20)。对应的步幅是8/16/32。
P6模型将第二个到第五个Stage Laye的相应结果传递给Neck结构体并提取三个输出特征图。以 1280x1280 输入图像为例。输出特征为(B,256,160,160)、(B,512,80,80)、(B,768,40,40)和(B,1024,20,20)。对应的步幅为8/16/32/64。
1.2.2 颈部
官方YOLOv5中没有Neck部分。然而,为了方便用户更容易地对应其他目标检测网络,我们将官方存储库的Head分为PAFPN和Head。
基于该BaseYOLONeck结构,YOLOv5Neck也遵循相同的构建过程。然而,对于不存在的模块,我们使用nn.Identity。
Neck模块输出的特征图与Backbone相同。P5型号为(B,256,80,80)、(B,512,40,40)和(B,1024,20,20);P6 型号为 (B,256,160,160)、(B,512,80,80)、(B,768,40,40) 和 (B,1024,20,20)。
The Head structure of YOLOv5 is the same as YOLOv3, which is a non-decoupled Head. The Head module includes three convolution modules that do not share weights. They are used only for input feature map transformation.
The PAFPN outputs three feature maps of different scales, whose shapes are (B,256,80,80), (B,512,40,40), and (B,1024,20,20) accordingly.
Since YOLOv5 has a non-decoupled output, that is, classification and bbox detection results are all in different channels of the same convolution module. Taking the COCO dataset as an example:
When the input of P5 model is 640x640 resolution, the output shapes of the Head module are (B, 3x(4+1+80),80,80), (B, 3x(4+1+80),40,40) and (B, 3x(4+1+80),20,20).
When the input of P6 model is 1280x1280 resolution, the output shapes of the Head module are (B, 3x(4+1+80),160,160), (B, 3x(4+1+80),80,80), (B, 3x(4+1+80),40,40) and (B, 3x(4+1+80),20,20).
3 represents three anchors, 4 represents the bbox prediction branch, 1 represents the obj prediction branch, and 80 represents the class prediction branch of the COCO dataset.
1.2.3 头部
YOLOv5的Head结构与YOLOv3相同,都是一个non-decoupled Head。Head 模块包括三个不共享权重的卷积模块。它们仅用于输入特征图转换。
PAFPN输出三个不同尺度的特征图,其形状分别为(B,256,80,80)、(B,512,40,40)和(B,1024,20,20)。
由于YOLOv5具有非解耦的输出,即分类和bbox检测结果都在同一卷积模块的不同通道中。以COCO数据集为例:
当P5模型的输入为640x640分辨率时,Head模块的输出形状为、和。(B, 3x(4+1+80),80,80)(B, 3x(4+1+80),40,40)(B, 3x(4+1+80),20,20)
当P6模型的输入为1280x1280分辨率时,Head模块的输出形状为 (B, 3x(4+1+80),160,160), (B, 3x(4+1+80),80,80), (B, 3x(4+1+80),40,40) and (B, 3x(4+1+80),20,20).
3 represents three anchors, 4 represents the bbox prediction branch, 1 represents the obj prediction branch, and 80 represents the class prediction branch of the COCO dataset.
1.3 正负样本分配策略
正负样本分配策略的核心是确定预测特征图的所有位置中哪些位置应该为正或负,甚至哪些样本将被忽略。
这是目标检测算法最重要的组成部分之一,因为好的策略可以提高算法的性能。
YOLOv5的分配策略可以简单概括为计算anchor和gt_bbox之间的形状匹配率。另外,还引入了跨邻域网格以获得更多的正样本。
它由以下两个主要步骤组成:
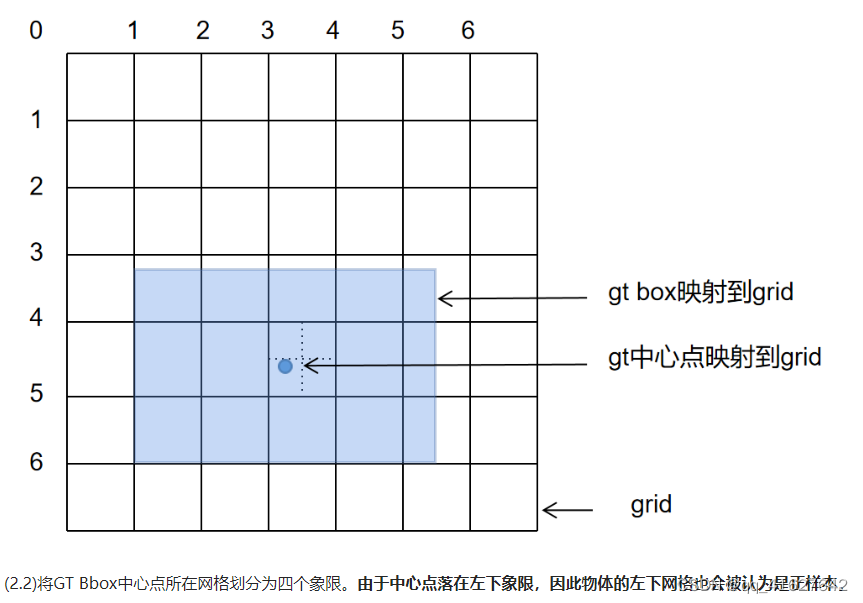
对于任意输出层,YOLOv5不再采用常用的基于最大IoU匹配的策略,而是转而比较形状匹配率shape matching ratio。首先,使用GT Bbox和当前层的anchor来计算宽高比。如果比值大于阈值,则认为GT Bbox和Anchor不匹配。然后暂时丢弃当前的GT Bbox,并将该GT Bbox在当前层的网格中的预测位置视为负样本。
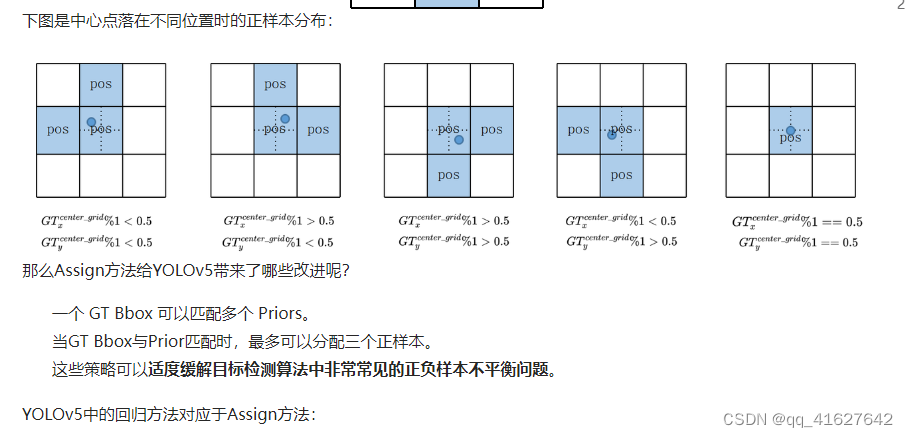
对于剩余的GT Bbox(匹配的GT Bbox),YOLOv5计算它们属于哪个网格。使用舍入规则找到最近的两个网格,并将所有三个网格视为一组,负责预测GT Bbox。与之前的YOLO系列算法相比,正样本数量增加了至少三倍。
现在我们将详细解释分配策略的每个部分。一些描述和插图直接或间接引用自官方仓库。
1.3.1 锚点设置
YOLOv5是一种基于anchor的目标检测算法。与YOLOv3类似,anchor的大小仍然是通过聚类得到的。然而,与YOLOv3的不同之处在于,YOLOv5不再基于IoU进行聚类,而是改用宽度和高度上的长宽比(基于形状匹配的方法)。
在对定制数据进行训练时,用户可以使用 MMYOLO 中的工具来分析并获得数据集合适的锚点大小。
python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm v5-k-means
--input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR}
然后修改配置文件中的默认锚点大小设置:
anchors = [[(10, 13), (16, 30), (33, 23)], [(30, 61), (62, 45), (59, 119)],
[(116, 90), (156, 198), (373, 326)]]
1.3.2 Bbox编解码流程
预测的边界框将根据基于锚点的算法中预设的锚点进行变换。然后,transformation amount is predicted,称为GT Bbox编码过程。最后,在预测之后需要进行Pred Bbox解码,将bbox恢复到原始尺度,称为Pred Bbox解码过程。
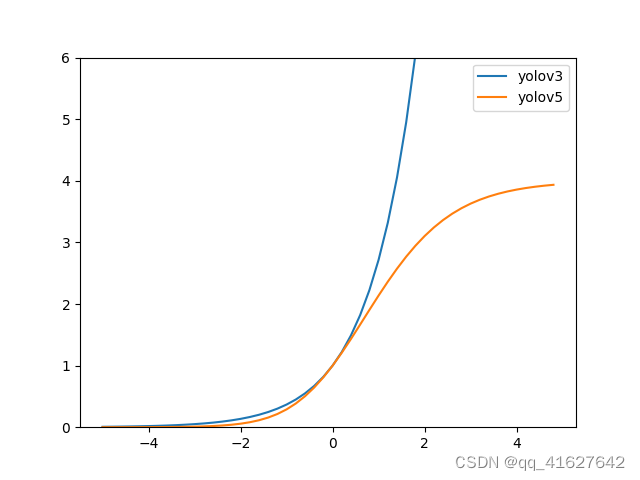
在YOLOv3中,bbox回归公式为:

通过改变中心点范围可以更好地预测0和1,这使得bbox坐标回归更加准确。
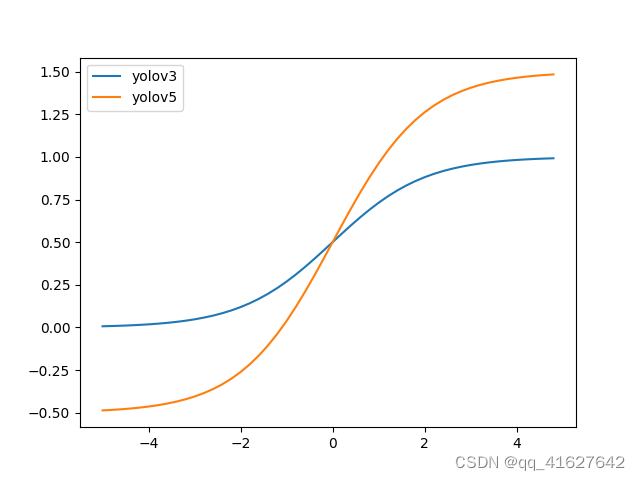
exp(x)在宽高回归公式中是无界的,可能会导致梯度失控,导致训练阶段不稳定。YOLOv5 中修改后的宽高回归优化了这个问题。
1.3.3 分配策略
注意:在 MMYOLO 中,对于基于锚的网络和无锚的网络,我们将锚称为先验。
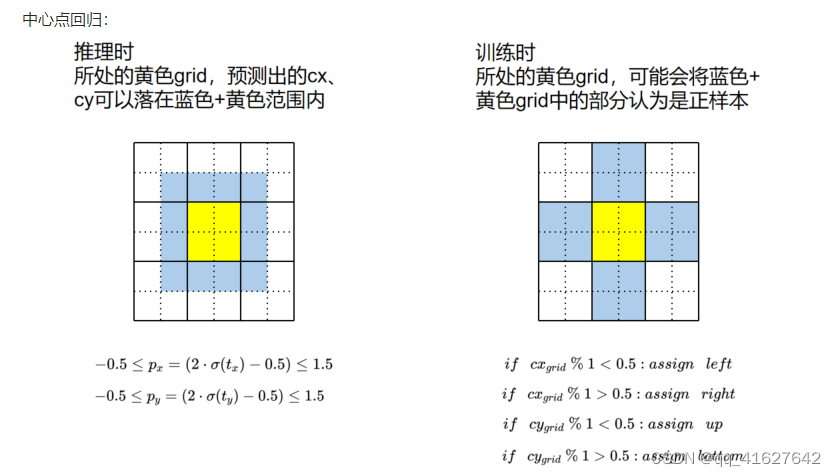
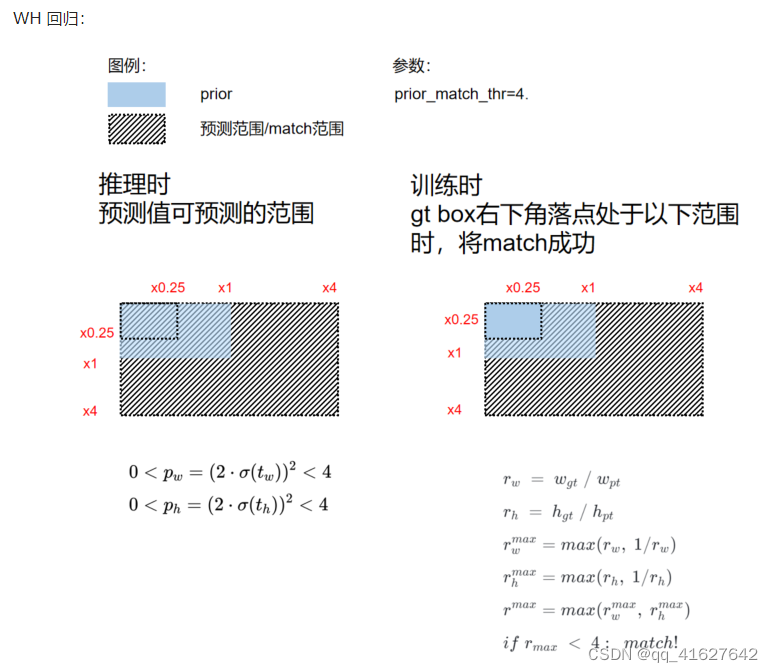
正样本分配包括以下两个步骤:
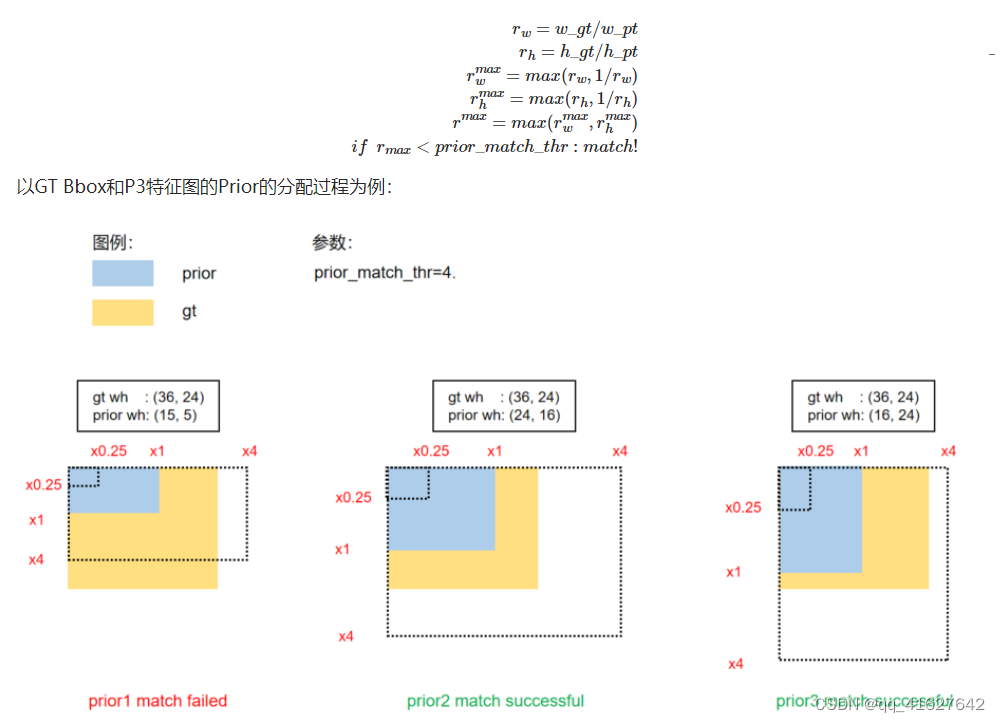
(1) Scale comparison
比较 GT BBox 中的 WH 和 Prior 中的 WH 的scale:

1.4 损耗设计
YOLOv5总共包含三个Loss,分别是:
Classes loss类别损失:BCE损失
Objectness loss客观性损失:BCE 损失
Location loss位置丢失:CIoU 丢失
这三种损失按一定比例合计:
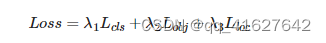
根据不同的权重添加P3、P4、P5层对应的Objectness损失。默认设置是
obj_level_weights=[4., 1., 0.4]

在重新实现中,我们发现YOLOv5中使用的CIoU与官方最新的CIoU存在一定的差距,这体现在alpha参数的计算上。
在正式版本中:
参考:https://github.com/Zzh-tju/CIoU/blob/master/layers/modules/multibox_loss.py#L53-L55
alpha = (ious > 0.5).float() * v / (1 - ious + v)
在YOLOv5的版本中:
alpha = v / (v - ious + (1 + eps))
这是一个有趣的细节,我们需要在后续开发中测试不同的alpha计算方法所带来的精度差距。
1.5 优化和训练策略
YOLOv5对每个优化器的参数组都有非常细粒度的控制,简要包括以下部分。
1.5.1 优化器分组(Optimizer grouping)
优化参数分为三组:Conv/Bias/BN。在 WarmUp 阶段,不同的组使用不同的 lr 和动量更新曲线。同时,在WarmUp阶段采用基于iter的更新策略,在非WarmUp阶段就变成了基于epoch的更新策略,相当棘手。
在MMYOLO中,YOLOv5OptimizerConstructor优化器构造函数用于实现优化器参数分组。优化器构造函数的作用是精细地控制一些特殊参数组的初始化过程,使其能够很好地满足需要。
不同的参数组通过YOLOv5ParamSchedulerHook使用不同的scheduling curve functions。
1.5.2权重衰减参数自适应(weight decay parameter auto-adaptation)
作者针对不同的batch size采用不同的权重衰减策略,具体为:
**当训练batch size不超过64时,权重衰减保持不变。
当训练批次大小超过 64 时,权重衰减将根据总批次大小线性缩放。**
MMYOLO 也是通过 YOLOv5OptimizerConstructor 来实现的。
1.5.3 梯度累积( Gradient accumulation)
为了最大化在不同batch size下的性能,作者在总batch size小于64时自动设置梯度累积函数。
训练过程与大多数YOLO类似,包括以下策略:
不使用预先训练的权重。
没有多尺度的训练策略,可以开启cudnn.benchmark来进一步加速训练。
EMA 策略用于平滑模型。
默认情况下使用 AMP 自动进行混合精度训练。
需要提醒的是,YOLOv5官方存储库对bs为128的小模型使用单卡v100训练。但是m/l/x模型是用不同数量的多卡训练的。这种训练策略不是比较标准,为此MMYOLO中使用了8张卡,每张卡将bs设置为16。同时,为了避免性能差异,训练时开启了SyncBN。
1.6 推理与后处理
YOLOv5 后处理与 YOLOv3 非常相似。事实上,YOLO系列的所有后处理阶段都是相似的。
1.6.1 核心参数(Core parameters)
多标签multi_label
对于多类别预测,需要考虑是否是多标签情况。多标签案例可以预测一个位置上多个类别的概率。由于 YOLOv5 使用 sigmoid,因此一个对象可能有两个不同的预测。评估mAP好,但不好用。因此,在评估时将 multi_label 设置为True,并更改为False以便进行推理和实际使用。
Score_thr 和 nms_thr
Score_thr阈值用于每个类别的得分,得分低于阈值的检测框被视为背景。nms_thr 用于 nms 进程。在评估过程中,score_thr可以设置得很低,这样可以提高召回率和mAP。然而,它对于实际使用没有意义,并且导致推理性能非常慢。因此,在测试和推理阶段设置了不同的阈值。
nms_pre 和 max_per_img
nms_pre是NMS之前要保留的最大帧数,用于防止NMS过程中输入帧过多而导致速度变慢。max_per_img是最终要保留的最大帧数,通常设置为300。
以 COCO 数据集为例。它有 80 个类,输入大小为 640x640。
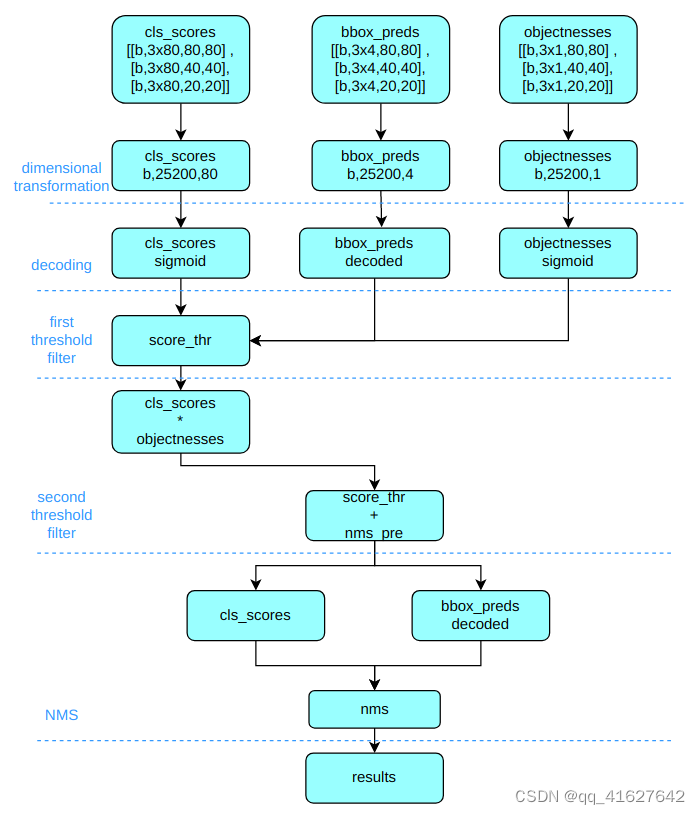
推理和后处理包括:
(1) 维度变换
YOLOv5 输出三个特征图。每个特征图的缩放比例为 80x80、40x40 和 20x20。由于每个位置有 3 个锚点,因此输出特征图通道为 3x(5+80)=255。YOLOv5使用非解耦Head,而大多数其他算法使用解耦Head。因此,为了统一后处理逻辑,我们将YOLOv5的Head解耦为类别预测分支、bbox预测分支和obj预测分支。
将类别预测、bbox预测、obj预测这三个尺度拼接在一起,进行维度变换。后续处理时,最后替换原来的通道维度,类别预测分支、bbox预测分支、obj预测分支的形状为(b, 3x80x80+3x40x40+3x20x20, 80)=(b,25200,80 )、(b,25200,4) 和 (b,25200,1)。
(2) 解码至原始图尺度
分类分支和obj分支需要使用sigmoid函数计算,而bbox预测分支需要解码并reduced to the original image in xyxy format。
(3) 第一次过滤
迭代batch中的每个图,然后使用score_thr对类别预测分数进行阈值过滤,去除score_thr以下的预测结果。
(4)二次过滤
将obj预测分数与过滤后的类别预测分数相乘,然后仍然使用score_thr进行阈值过滤。这个过程中还需要考虑multi_label 和 nms_pre ,以保证过滤后检测到的框数量不超过 nms_pre。
(5) 重新缩放至原始大小并进行NMS
基于预处理过程,将剩余的检测框恢复到网络输出之前的原始图尺度并进行NMS。最终输出的检测帧不能超过max_per_img。
1.6.2 批量形状策略(batch shape strategy)
为了加快验证集上的推理过程,作者提出了 batch shape strategy,其原则是保证同一batch内的图像在batch推理过程中具有最少数量的pad像素,并且不需要所有图像在整个验证过程中批次具有相同的规模。
它首先根据整个测试或验证集的长宽比对图像进行排序,然后根据设置形成一批排序后的图像。同时计算当前batch的batch shape,防止pad像素过多。我们专注于使用原始纵横比进行填充,而不是将图像填充到完美的正方形。
image_shapes = []
for data_info in data_list:
image_shapes.append((data_info['width'], data_info['height']))
image_shapes = np.array(image_shapes, dtype=np.float64)
n = len(image_shapes) # number of images
batch_index = np.floor(np.arange(n) / self.batch_size).astype(
np.int64) # batch index
number_of_batches = batch_index[-1] + 1 # number of batches
aspect_ratio = image_shapes[:, 1] / image_shapes[:, 0] # aspect ratio
irect = aspect_ratio.argsort()
data_list = [data_list[i] for i in irect]
aspect_ratio = aspect_ratio[irect]
# Set training image shapes
shapes = [[1, 1]] * number_of_batches
for i in range(number_of_batches):
aspect_ratio_index = aspect_ratio[batch_index == i]
min_index, max_index = aspect_ratio_index.min(
), aspect_ratio_index.max()
if max_index < 1:
shapes[i] = [max_index, 1]
elif min_index > 1:
shapes[i] = [1, 1 / min_index]
batch_shapes = np.ceil(
np.array(shapes) * self.img_size / self.size_divisor +
self.pad).astype(np.int64) * self.size_divisor
for i, data_info in enumerate(data_list):
data_info['batch_shape'] = batch_shapes[batch_index[i]]
2 Sum up
本文重点详细介绍YOLOv5的原理以及我们在MMYOLO中的实现,希望能够帮助用户理解算法和实现过程。同时再次请注意,由于YOLOv5本身在不断更新,这个开源库也会不断迭代。因此,请始终检查最新版本。
算法原理及YOLOV8实现
YOLOv8是YOLOv5的下一个重大更新,由Ultralytics于2023年1月10日开源,现在支持图像分类、对象检测和实例分割任务。
据官方介绍,Ultralytics YOLOv8是Ultralytics开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8 是一种尖端、最先进 (SOTA) 模型,它建立在先前 YOLO 版本成功的基础上,并引入了新功能和改进,以进一步提高性能和灵活性。其中包括新的骨干网络、新的无锚检测头和新的损失函数。YOLOv8 还非常高效,可以在从 CPU 到 GPU 的各种硬件平台上运行。
不过,ultralytics 并没有将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,因为 ultralytics 将库定位为一个算法框架而不是具体的算法,主要关注可扩展性。预计该库不仅可以用于 YOLO 模型族,还可以用于非 YOLO 模型以及分类分割姿态估计等各种任务。
总的来说,YOLOv8 是一个强大而灵活的目标检测和图像分割工具,它提供了两全其美的功能:SOTA 技术使用以及和比较所有先前 YOLO 版本的能力
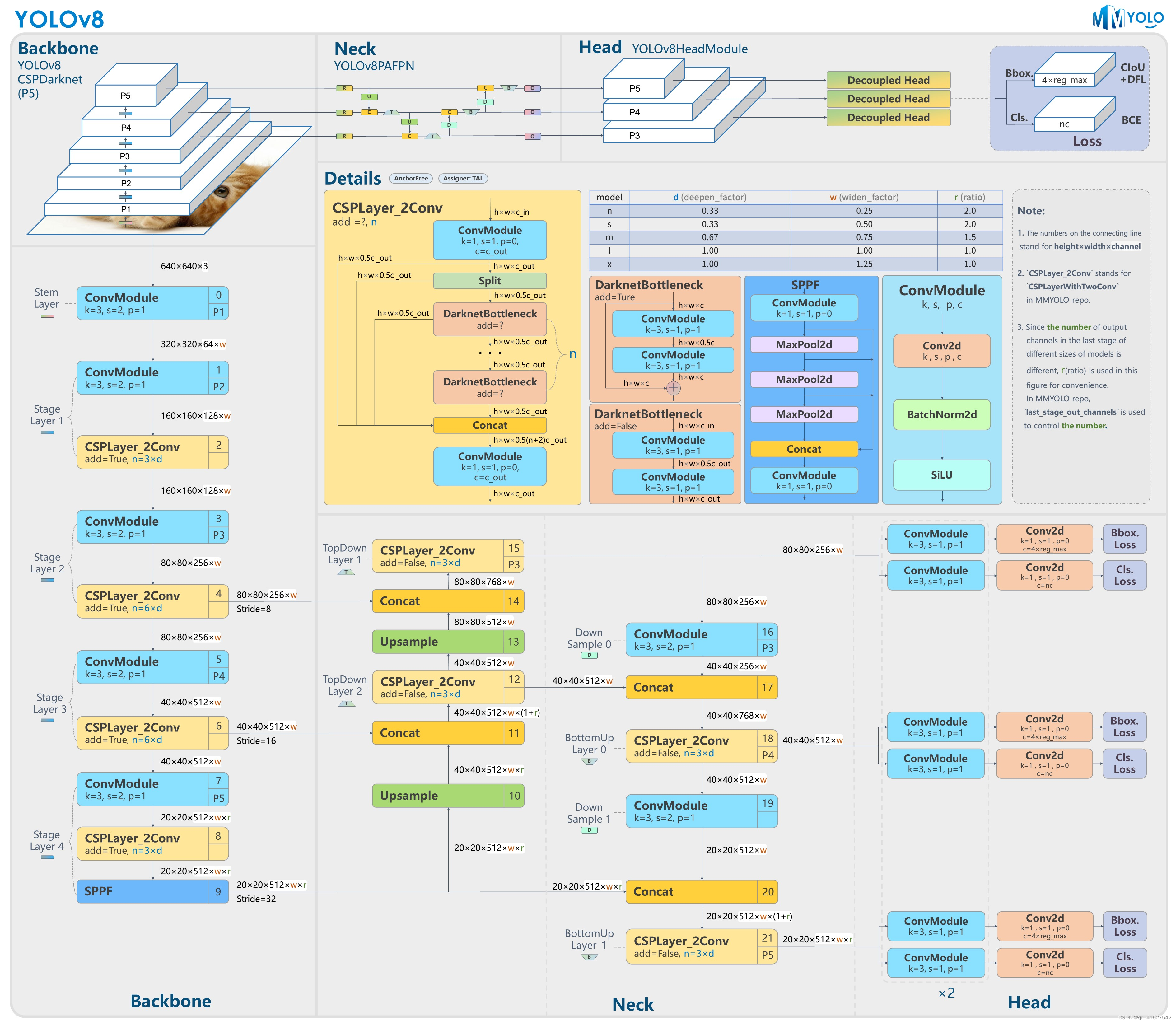
图1:YOLOv8-P5
。
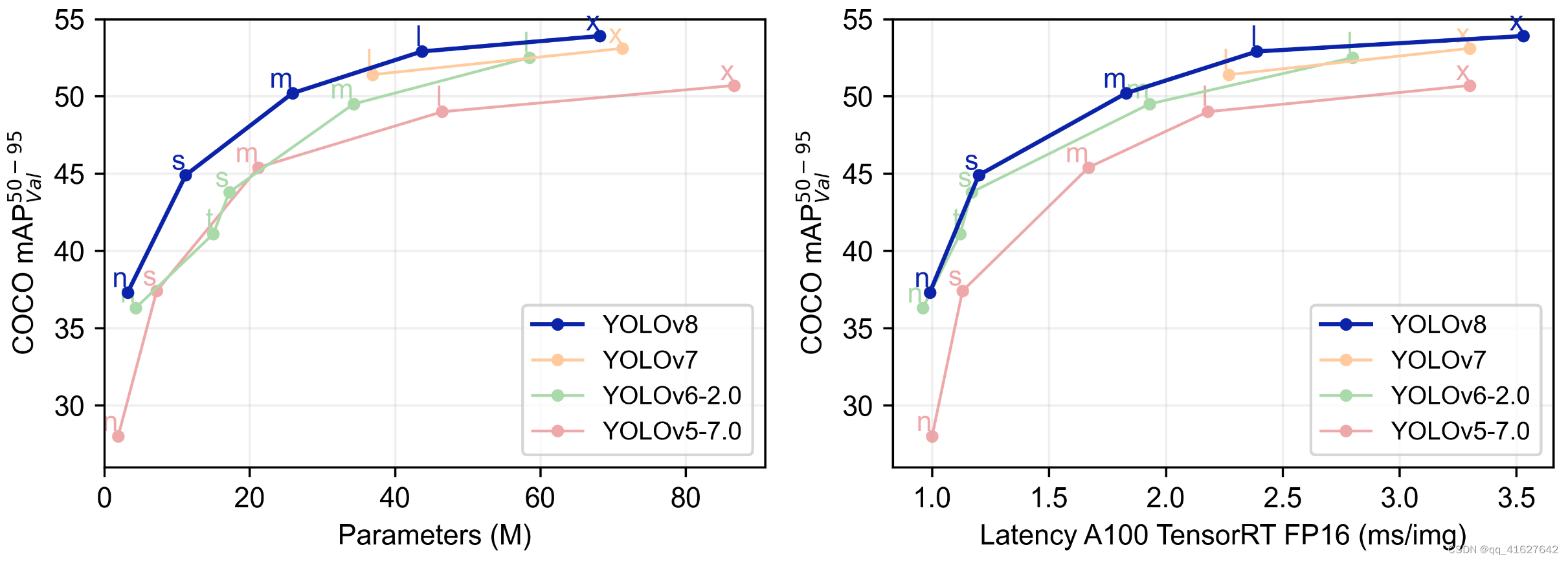
下表显示了在COCO Val 2017数据集上测试的官方mAP、参数数量和FLOPs的结果。很明显,YOLOv8 相比 YOLOv5 精度有了显着提升。然而,N/S/M模型的参数数量和FLOPs显着增加。此外,可以看出,与大多数 YOLOv5 模型相比,YOLOv8 的推理速度较慢。
The following table shows the official results of mAP, number of parameters and FLOPs tested on the COCO Val 2017 dataset. It is evident that YOLOv8 has significantly improved precision compared to YOLOv5. However, the number of parameters and FLOPs of the N/S/M models have significantly increased. Additionally, it can be observed that the inference speed of YOLOv8 is slower in comparison to most of the YOLOv5 models.
值得一提的是,最近的 YOLO 系列在 COCO 数据集上表现出了显着的性能提升。然而,它们在自定义数据集上的通用性尚未得到广泛测试,因此这将是 MMYOLO 未来开发的重点。
1 YOLOv8概述
YOLOv8的核心特性和修改可以总结如下:
提出了一种新的最先进(SOTA)模型,具有 P5 640 和 P6 1280 分辨率的对象检测模型,以及基于 YOLACT 的实例分割模型。该模型还包括与 YOLOv5 类似的 N/S/M/L/X 尺度的不同尺寸选项,以适应各种场景。
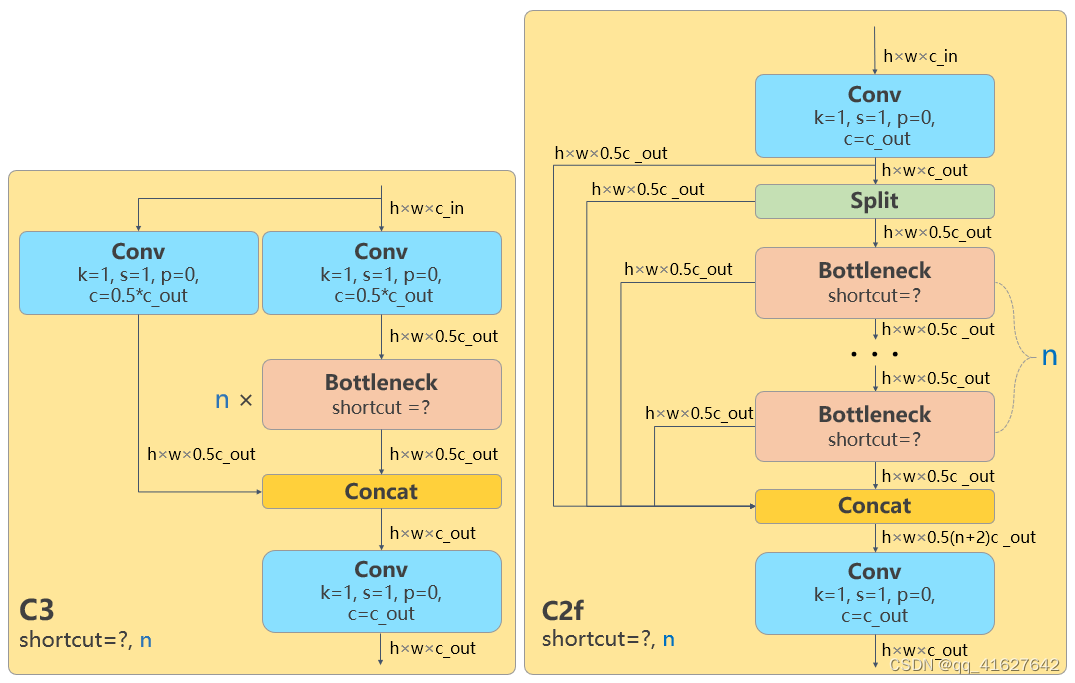
主干网络和neck模块是基于YOLOv7 ELAN设计理念,用C2f模块替代YOLOv5的C3模块。然而,这个C2f模块中有很多诸如Split和Concat之类的操作不像以前那样部署友好。
Head模块更新为目前主流的解耦结构,将分类头和检测头分离,并从Anchor-Based切换为Anchor-Free。
损失计算采用TOOD中的TaskAlignedAssigner,并在回归损失中引入Distribution Focal Loss。
在数据增强部分,Mosaic在最后10个训练epoch中关闭,这与YOLOX训练部分相同。 从上面的总结可以看出,YOLOv8主要参考了YOLOX、YOLOv6、YOLOv7和PPYOLOE等最近提出的算法的设计。
接下来我们将通过模型结构设计、损失计算、训练策略、模型推理过程和数据增强5个部分来详细介绍YOLOv8模型的各种改进。
2 模型结构设计
图1是基于YOLOv8官方代码的模型结构图。如果你喜欢这种风格的模型结构图,欢迎查看MMYOLO的算法README中的模型结构图,目前涵盖YOLOv5、YOLOv6、YOLOX、RTMDet和YOLOv8。
在不考虑 head 模块的情况下比较 YOLOv5 和 YOLOv8 yaml 配置文件,可以看到变化很小。
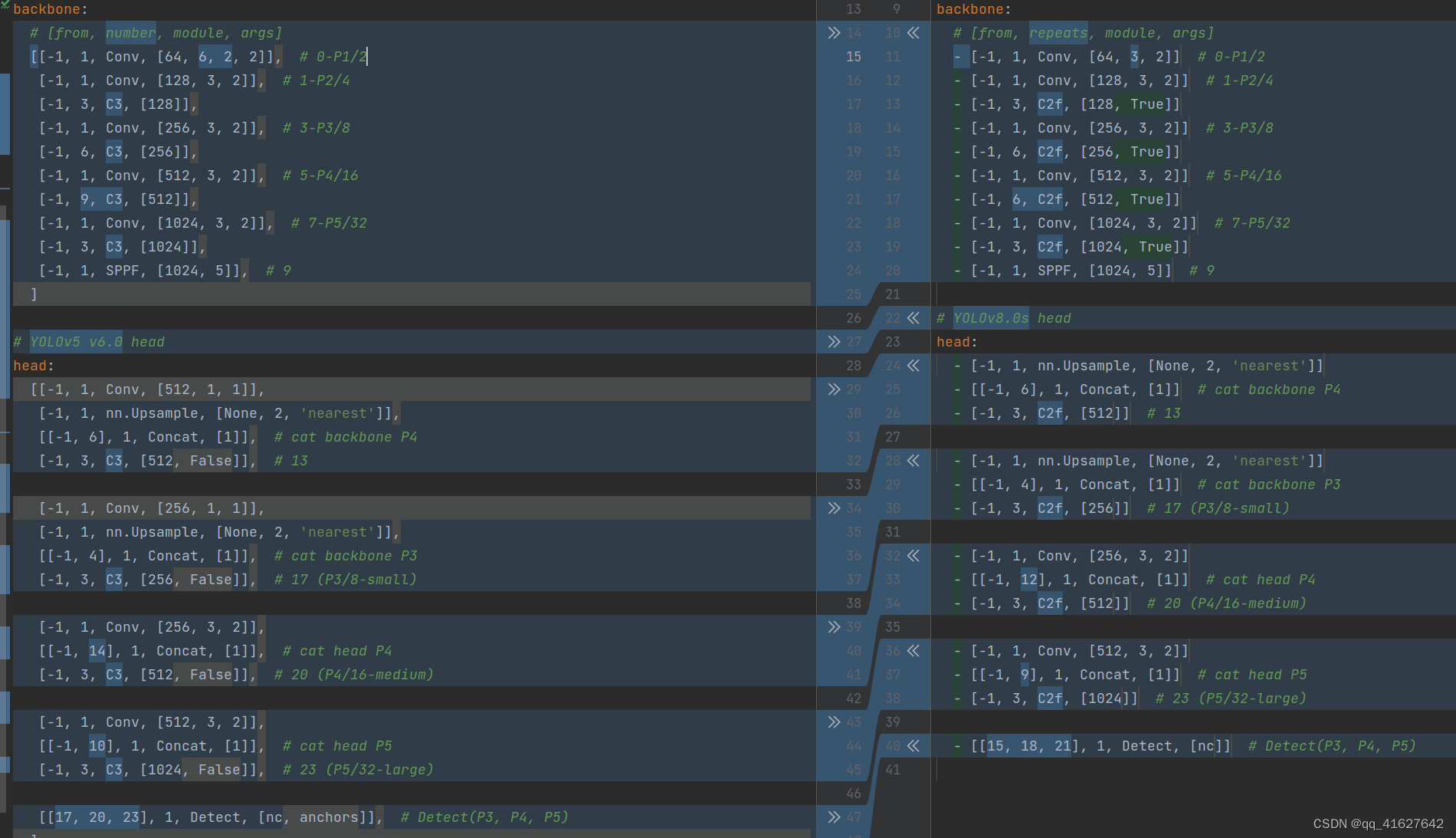
左边的结构是YOLOv5-s,另一边是YOLOv8-s。主干网络和neck模块的具体变化是:
第一个卷积层的内核已从 6x6 更改为 3x3
所有C3模块均替换为C2f,结构如下,增加了更多的跳过连接和额外的分割操作。
从颈部模块中删除了 2 个卷积连接层
block number已从 3-6-9-3 更改为 3-6-6-3。
如果我们看一下N/S/M/L/X模型,我们可以看到N/S和L/X模型只改变了缩放因子,但S/ML骨干网络中的通道数没有相同且不遵循相同比例因子原则。这种设计的主要原因是同一组缩放因子下的通道设置不是最优的,并且YOLOv7网络设计也没有对所有模型遵循一组缩放因子。
该模型最显着的变化在于头部模块。head模块由原来的 coupling structure结构改为解耦结构,风格也由YOLOv5的Anchor-Based改为Anchor-Free。结构如下图所示。
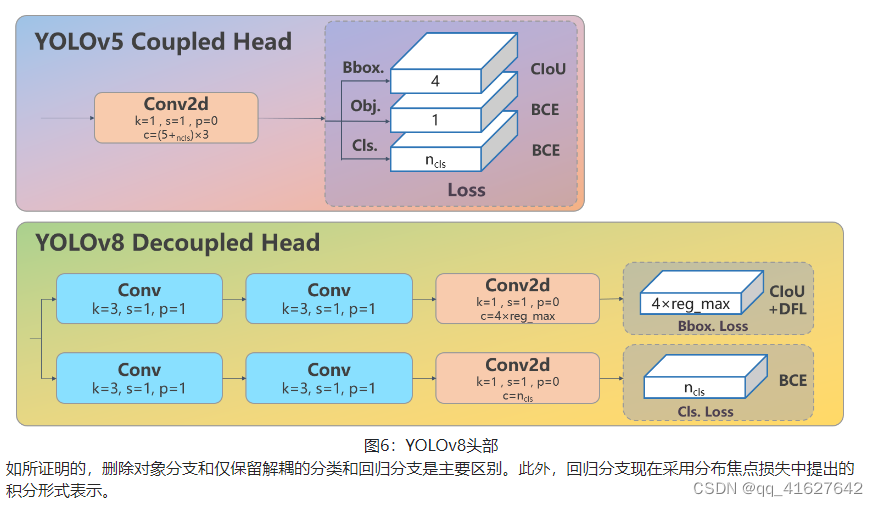
As demonstrated, the removal of the objectness branch and the retention of only the decoupled classification and regression branches stand as the major differences. Additionally, the regression branch now employs integral form representation as proposed in the Distribution Focal Loss.
3 损耗计算
损失计算过程由2部分组成:样本分配策略和损失计算。
当代检测器大多数采用动态样本分配策略,例如YOLOX的simOTA、TOOD的TaskAlignedAssigner和RTMDet的DynamicSoftLabelAssigner。鉴于动态分配策略的优越性,YOLOv8算法直接结合了TOOD的TaskAlignedAssigner中采用的算法。
TaskAlignedAssigner的匹配策略可以概括为:根据分类和回归的加权分数选择正样本。
The loss calculation process consists of 2 parts: the sample assignment strategy and loss calculation.
The majority of contemporary detectors employ dynamic sample assignment strategies, such as YOLOX’s simOTA, TOOD’s TaskAlignedAssigner, and RTMDet’s DynamicSoftLabelAssigner. Given the superiority of dynamic assignment strategies, the YOLOv8 algorithm directly incorporates the one employed in TOOD’s TaskAlignedAssigner.
The matching strategy of TaskAlignedAssigner can be summarized as follows: positive samples are selected based on the weighted scores of classification and regression.

4 数据增强
YOLOv8 的数据增强与 YOLOv5 类似,但它按照 YOLOX 中的建议,在最后 10 个 epoch 中停止了 Mosaic 增强。数据处理管道如下图所示。
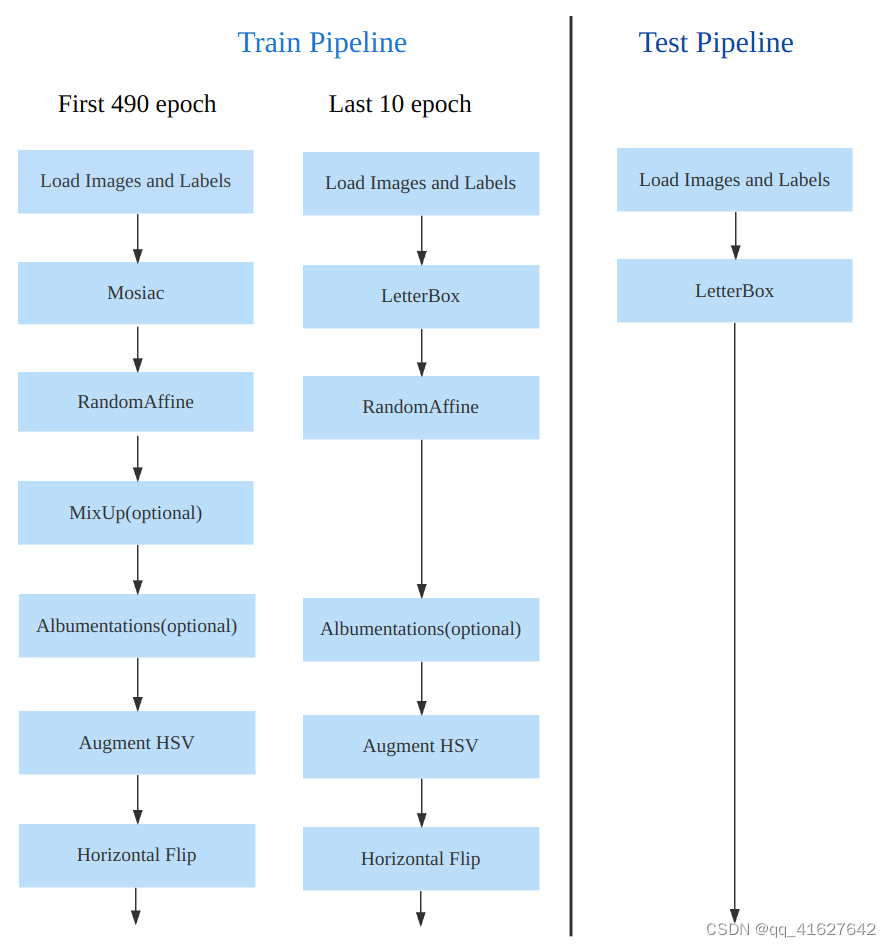
不同尺度模型所需的数据增强强度不同,因此需要根据情况调整尺度模型的超参数。对于较大的模型,通常采用 MixUp 和 CopyPaste 等技术。数据增强的结果可以在下面的示例中看到:

运行browse_dataset脚本即可得到上述可视化结果。
由于 YOLOv8 中使用的数据增强过程与 YOLOv5 类似,因此我们不会在本文中深入探讨细节。为了更深入地了解每个数据转换,我们建议查看MMYOLO中的YOLOv5算法分析文档。
5 培训策略
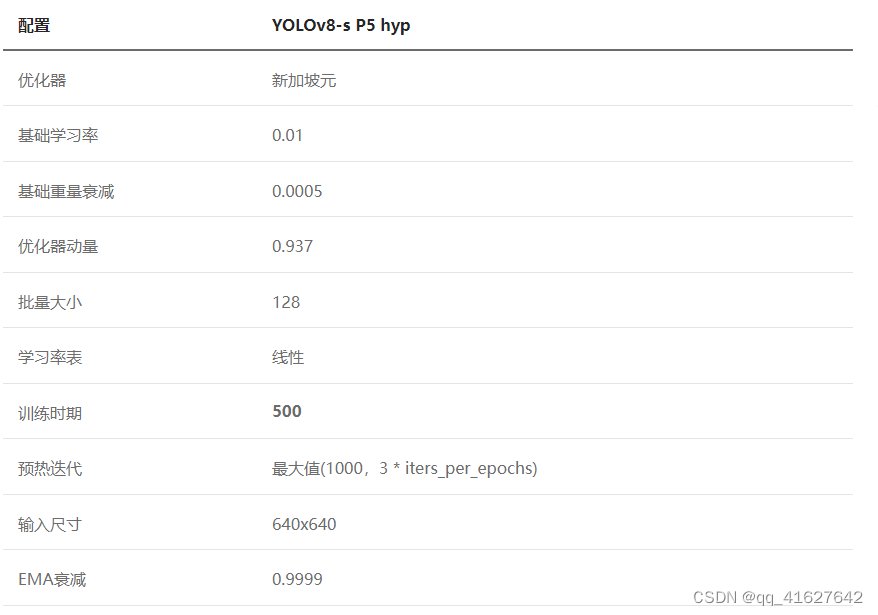
OLOv8 和 YOLOv5 的训练策略之间的区别很小。最显着的变化是 YOLOv8 的训练 epoch 总数从 300 增加到 500,导致训练持续时间显着延长。作为说明,YOLOv8-S的训练策略可以简洁地概述如下:
6 推理过程
YOLOv8的推理过程与YOLOv5几乎相同。唯一的区别是Distribution Focal Loss中的积分表示bbox需要解码为规则的4维bbox,后续计算过程与YOLOv5相同。
以COCO 80类为例,假设输入图像尺寸为640x640,MMYOLO中实现的推理过程如下所示
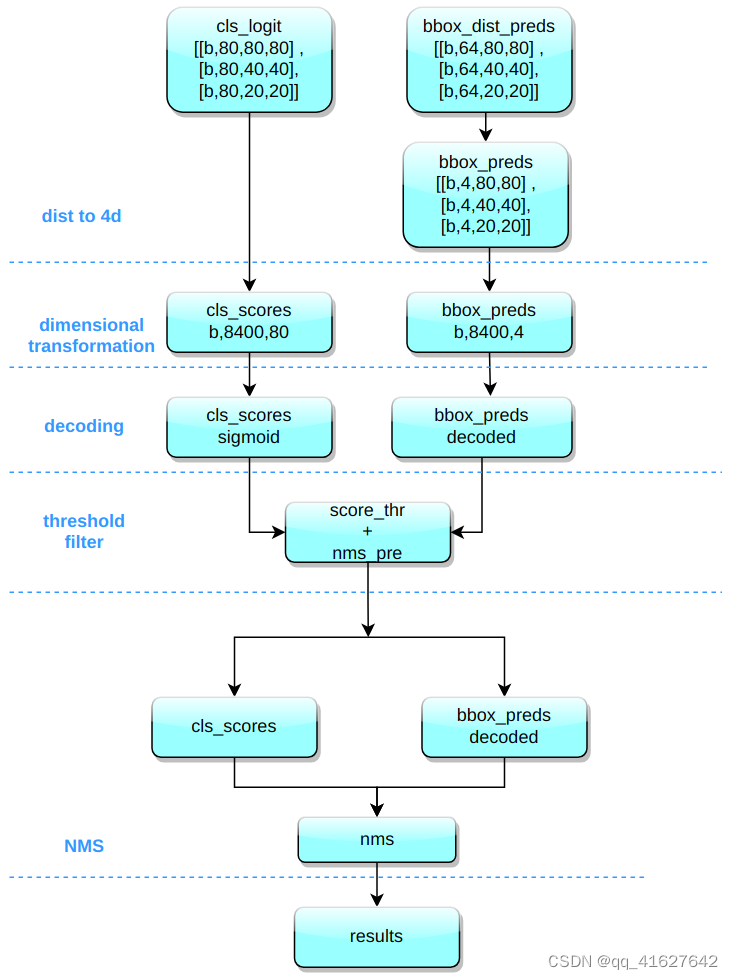
推理和后处理过程为:
(1) 解码边界框 将框中心与边界之间的距离的概率整合为距离的数学期望。
(2) 维度变换80x80YOLOv8 输出三个具有、40x40和尺度 的特征图20x20。head模块总共输出6个分类和回归不同尺度的特征图。将类别预测分支和bbox预测分支的3个不同尺度进行组合并进行维度变换。为了后续处理方便,将原始通道维度转置到最后,类别预测分支和bbox预测分支形状为(b, 80x80+40x40+20x20, 80)=(b,8400,80),(b ,8400,4) 分别。
(3)尺度恢复 分类预测分支利用sigmoid计算,而bbox预测分支需要解码为xyxy格式并转换为输入图像的原始尺度。
(4) 阈值化 迭代批次中的每个图并用于score_thr执行阈值化。在这个过程中,我们还需要考虑multi_label和nms_pre,保证过滤后检测到的bbox数量不超过nms_pre。
(5)缩小到原始图像比例并进行NMS 重新使用预处理参数,首先将剩余的bbox调整大小到原始图像比例,然后进行NMS。最终bbox的数量不能超过max_per_img。
特别注意:YOLOv5 中存在的批量形状推理策略目前在 YOLOv8 中尚未激活。通过在 MMYOLO 中进行快速测试,可以观察到激活 Batch shape 策略可以导致 AP 大约增加 0.1% 到 0.2% 左右。
7 特征图可视化
MMYOLO 提供了一套全面的特征图可视化工具来帮助用户可视化特征图。
以YOLOv8-s模型为例。第一步是下载官方权重,然后使用yolov8_to_mmyolo脚本将其转换为 MMYOLO。注意,脚本必须放在官方仓库下才能正确运行。
假设您想要可视化主干输出的 3 个特征图的效果,并且权重名为“mmyolov8s.pth”。运行以下命令:
cd mmyolo
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean
特别是,为了确保特征图和图像显示对齐,test_pipeline需要将原始配置替换为以下内容:
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # change
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]

从上图我们可以看出,不同的输出特征图主要负责预测不同尺度的物体。我们还可以可视化颈部层的 3 个输出特征图。
cd mmyolo
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean --target-layers neck

从上图中我们可以发现,物体处的特征更加集中。
概括
本文深入探讨了 YOLOv8 算法的复杂性,对其总体设计、模型结构、损失函数、训练数据增强技术和推理过程进行了全面的检查。为了帮助理解,提供了大量图表。
综上所述,YOLOv8是一种结合了图像分类、Anchor-Free目标检测和实例分割的高效算法。其检测组件结合了众多最先进的 YOLO 算法,以实现新的性能水平。
算法原理及RTMDET实现
高性能、低延迟的单阶段物体检测
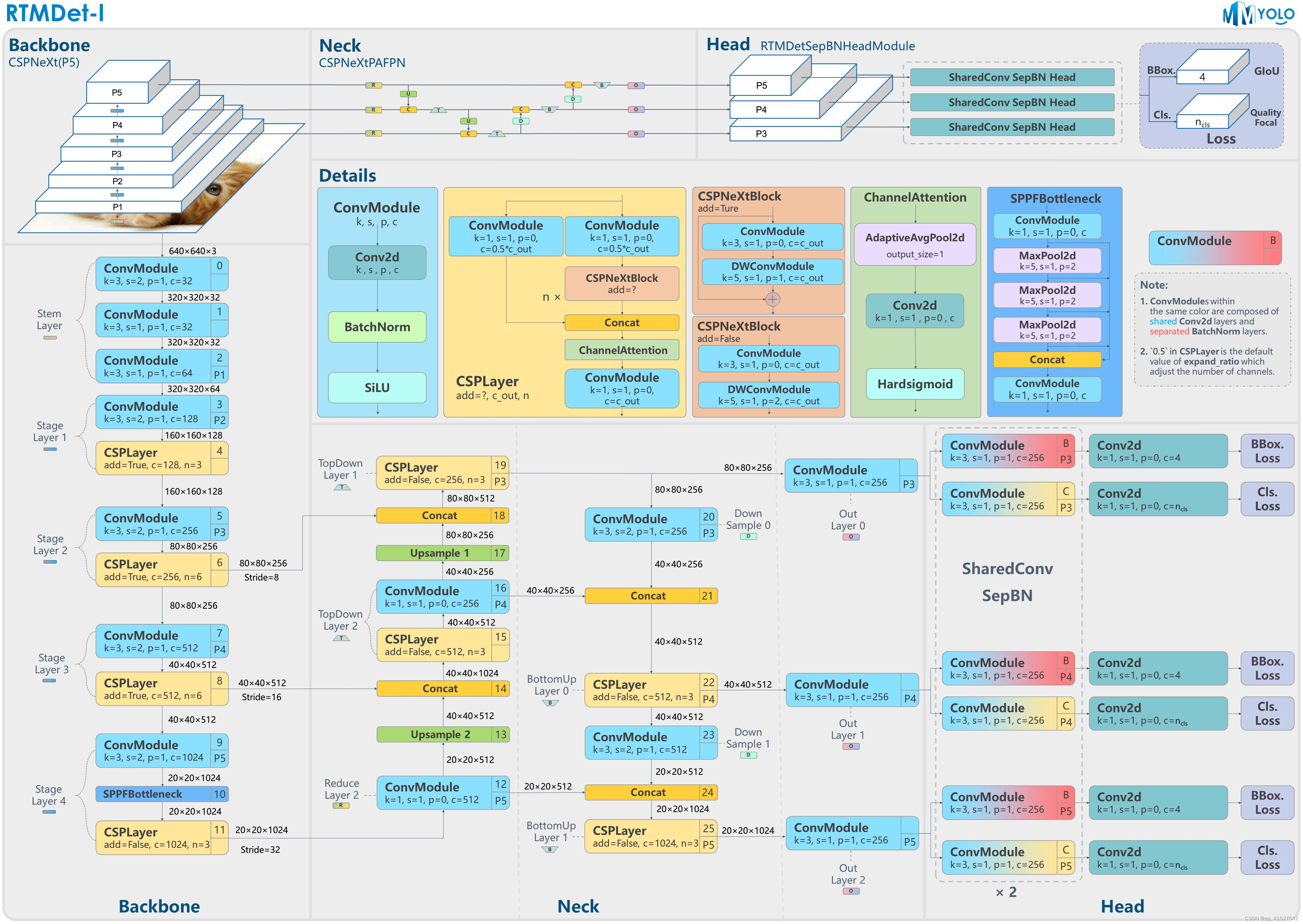
近年来,开源社区涌现出一大批高精度目标检测项目,其中最突出的项目之一就是YOLO系列。OpenMMLab 还与社区合作推出了 MMYOLO。在研究了当前 YOLO 系列中的许多改进模型后,MMDetection 核心开发人员凭经验总结了这些设计和训练方法,并对其进行了优化,推出了高精度、低延迟的单阶段目标检测器 RTMDet、Real - time Models for Object Det部分(发布到制造)_
RTMDet由一系列不同尺寸的tiny/s/m/l/x型号组成,为不同的应用场景提供了不同的选择。具体来说,RTMDet-x 实现了 300+ FPS 的推理速度和 52.6 mAP 的精度。
注:推理速度和准确性测试(不包括 NMS)是在1 个 NVIDIA 3090 GPU 上进行的。TensorRT 8.4.3, cuDNN 8.2.0, FP16, batch size=1
最轻的模型 RTMDet-tiny 只需 4M 个参数即可实现 40.9 mAP,推理速度 < 1 ms。
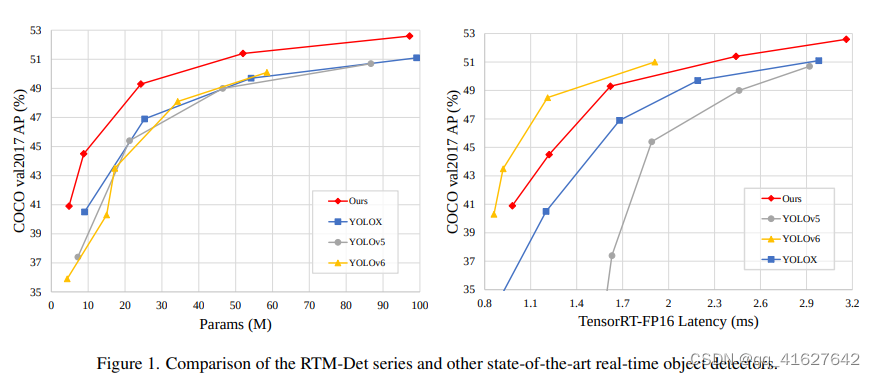
该图中的准确性是与 300 个训练 epoch 的公平比较,没有进行蒸馏。