人体关键点检测与MMPose
介绍
人体姿态估计(Human Pose Estimation)是计算机视觉领域中的一个重要研究方向,也是计算机理解人类动作、行为必不可少的一步,人体姿态估计是指通过计算机算法在图像或视频中定位人体关键点,目前被广泛应用于动作检测、虚拟现实、人机交互、视频监控等诸多领域。本次课程涵盖人体姿态估计的介绍与应用、2D 姿态估计、3D 姿态估计、DensePose、Body Mesh 以及 MMPose 等内容。
什么是人体姿态估计
从给定的图像中识别人脸、手部、身体等关键点
3D姿态估计:预测人体关键点在三维空间中的坐标,可以在三维空间中还原人体的姿态
人体参数化模型:从图像或者视频中会付出运动的3D人体模型
PoseC3D:基于人体姿态识别动作
2D姿态估计
2D人体姿态估计:在图像上定位人体关键点的坐标
基本思路:基于回归
将关键点检测问题建模成一个回归问题,让模型直接回归关键点的坐标
深度模型直接回归坐标有些困难,精度不是最优
基本思路:基于热力图
并不直接回归关键点的坐标,而是预测关键点位于每个位置的概率
热力图可以基于原始关键点坐标生成,作为训练网络的监督信息
网络预测的热力图也可以通过求极大值等方法得到关键点坐标
模型预测热力图比直接回归坐标相对容易,模型精度相对更高,因此主流算法更多基于热力图但预测热力图的计算消耗大于直接回归
多人姿态估计:自顶向下方法
整体精度受限于检测器的精度
速度和计算量会正比于人数
一些新工作考虑将两个阶段聚合成一个阶段
多人姿态估计:自底向上方法
优点:推理速度与人数无关
多人姿态估计:单阶段方法
一步实现人体的检测与姿态估计
基于回归的自顶向下方法
DeepPose
以分类网络为基础,将最后一层分类改为回归,一次性预测所有关键点的坐标
通过最小化平方误差训练网络
通过级联提升精度
优势:
回归模型理论上可以达到无限精度,热力图方法的精度受限于特征图的空间分辨率
回归模型不需要维持高分辨率特征图,计算层面更高效,相比之下,热力图方法需要计算和存储高分辨率的热力图和特征图,计算成本更高
劣势:
图像到关键点坐标的映射高度非线性,导致回归坐标比回归热力图更难,回归方法的精度也弱于热力图方法,因此DeepPose提出之后的很长一段时间内,2D关键点预测算法主要基于热力图
RLE(ResidualLog-likelihood Estimation)
核心思路:对于关键点的位置进行更准确的概率建模,从而提高位置预测的精度
经典回归范式
模型预测关键点坐标与真值计算误差作为损失,背后隐含了高斯分布的假设,但不一定符合数据的实际分布
RLE的范式
显示建模关键点的概率分布,通过最大似然拟合最优的位置分布
RLE的整体设计
RLE的目标是建模关键点位置的概率分布,即给定图像,给出每个关键点的位置分布
可以基于标准化流构建该分布,但RLE算法还引入了两个技巧以降低模型你和真实分布的难度
- 重参数化
- 残差似然函数
基于热力图的自顶向下方法
Hourglass模块
Hourglass模型在FLIC和MPII数据集上的性能在当时处于领先,在MPII上每一项在当时都达到SOTA.
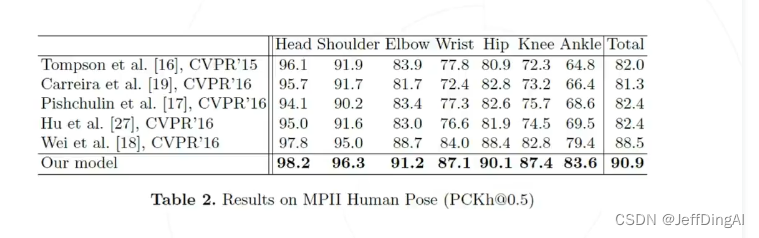
Simple Baseline(2018)
力求结构简单,使用ResNet配合反卷积形成编码器-解码器结构
HRNet
核心思路:在下采样时通过保留分辨率分支来保持网络全过程特征图的高分辨率与空间位置信息,并设计了独特的网络结构实现不同分辨率的多尺度特征融合
自底向上方法
Part Affinity Filelds & OpenPose
基本思路:基于图像同事预测关节位置和四肢走向,利用肢体走向辅助关键点的聚类:即,如果某两个关键点由某段肢体相连,则这两个关键点同属于同一个人
单阶段方法
SPM
SPM首次提出了人体姿态估计的单阶段解决方案,在取得速度优势的同时,也取得了不逊色于二阶段方法的检测率。并且该方法可以直接从2D图像扩展到3D图像的人体姿态估计
Structured Pose Representation(SPR)
为了统一人体实例和身体关节的位置信息,为多人姿势估计提供单阶段解决方案,SPR引入了一个辅助关节,即关节以表示人员实例位置,它是唯一标识关节
但是SPR存在明显弊端,例如由于可能存在交大的姿势变化,可能涉及身体关节和根关节之间的远距离位移,这给从图像表示映射到矢量域的位移估计带来困难。
因此在SPR的基础上提出了Hierarchical SPR,根据自由度和变形程度将根关节和身体关节划分为四个层次
第一级:根关节
第二级:包含颈肩臂
第三级:包含头肘膝
第四级:包含手腕脚踝
基于Transformer的方法
PRTR
人体姿态估计和物体检测有一定相似性,都涉及对图像内容的定位
在DETR中query通过注意力机智逐渐聚焦到特定物体上
姿态估计可模仿DETR:让query逐渐聚焦到特定人体关键点上
两阶段算法
人体检测阶段:使用DETR检测得出图中的不同的人
关键点检测阶段:同样使用DETR结构,不同的是query学习关键点信息,最终回归关键点位置
TokenPose
将视觉token和关键点tokern一起送入encoder可以同时从图像中学习外观视觉表现和关键点间的约束关系
分类模型ViT也是用类似方法,将一个分类token和visual token一起做自注意力
3D人体姿态估计
通过给定的图像预测人体关键点在三维空间中的坐标,可以在三维空间中还原人体的姿态
总结
