MMSegmentation
开源代码仓:https://github.com/open-mmlab/mmsegmentation
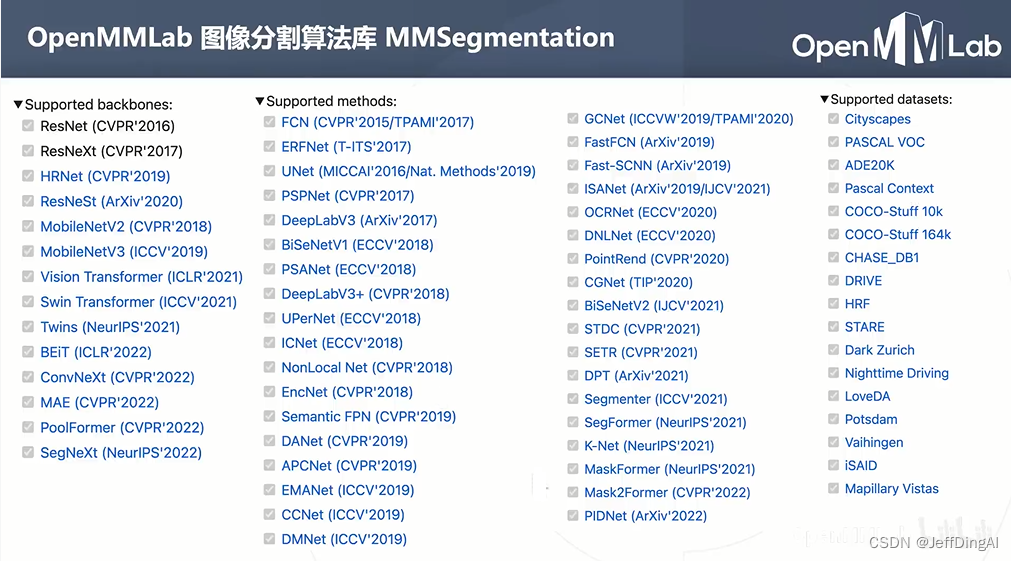
算法丰富:600+预训练模型、40+篇算法复现
模块化设计:配置简便、容易拓展
统一超参:大量消融实验、支持公平对比
使用方便:训练工具、调试工具、推理API
语义分割
基本思路
按颜色分割
物体内部颜色相近,物体交接颜色变化
基于图像处理方法,按照颜色分割
逐像素分割
优势:可以充分利用已有的图像分类模型
问题:效率低下,重叠区域重复计算卷积
预测图的升采样
问题:
图像分类模型使用降采样层(步长卷积或池化)获得高层次特征,导致全卷及网络输出尺寸小于原图,而分割要求同尺寸输出
解决方法:
对预测的分割图升采样,恢复原图分辨率,升采样方案:
-
双线性插值
-
转置卷积:可学习的升采样层
基于多层特征的上采样
问题:基于顶层特征预测,再升采样32倍得到的预测图较为粗糙
分析:高层特征经过多次降采样,细节丢失严重
解决思路:结合低层次和高层次特征图
解决方案FCN:
基于低层次和高层次特征图分别产生类别预测,升采样到原图大小,再平均得到最终结果
上下文信息
原图-主干网络-特征图-预测图
PSPNET
原图-特征图-多尺度池化-特征拼接-类别预测
对特征图进行不同尺度的赤化,得到不同尺度的上下文特征
上下文特征经过通道压缩和空间上采样之后拼接回原特征图->同时包含局部和上下文特征
基于融合的特征产生预测图
DeepLab系列
DeepLab是语义分割的又一系列工作
主要贡献:
-
使用空洞卷积解决网络中的下采样问题
-
使用条件随机场CRF作为后处理手段,精细化分割图
-
使用多尺度的空洞卷积(ASPP模块)捕捉上下文信息
DeepLab V1 发表于2014年,2016、2017、2018提出了V2、V3、V3+版本
空洞卷积解决下采样问题
图像分类模型的下采样层使输出尺寸变小
如果将池化层和卷积层中的步上去掉:
-
可以减少下采样的次数
-
特征图就会变大,需要对应增大卷积核,以维持相同的感受野,但会增加大量的参数
-
使用空洞卷积(Dilated Convolution/Atrous Convolution),在不增加参数的情况下增大感受野
标准卷积:
特征图-下采样-卷积运算-卷积核-结果
空洞卷积:
特征图不变膨胀卷积核再进行卷积运算-膨胀卷积核不产生额外参数-相同计算结果下采样加标准卷积等价于空洞卷积
空洞卷积和下采样
使用升采样方案得到的特征图只有原图的1/4位置的响应,需要配合插值
使用空洞卷积可以得到相同分辨率的特征图且无需额外插值操作
DeepLab模型
DeepLab在图像分类网络基础上做了修改:
-
去除分类模型中的后半部分的下采样层
-
后续的卷积层改为膨胀卷积,并且逐步增加rate来维持源网络的感受野
条件随机场 CRF
模型直接输出的分割图较为粗糙,尤其在物体边界处不能产生很好的分割结果
DeepLab V1&V2使用条件随机场(CRF)作为后处理手段,结合原图颜色和神经网络的预测的类别得到精细化分割结果
CRF是一种概率模型,DeepLab使用CRF对分割结果进行建模,用能量函数用来表示分割结果优劣,通过最小化能量函数获得更好的分割结果
空间金字塔池化
PSPNet使用不同尺度的池化来获取不同尺度的上下文信息
DeepLab V2&V3使用不同尺度的空间卷积达到类似效果
更大膨胀率的空洞卷积-更大感受野-更多的上下文特征
DeepLab V3+
-
DeepLab V2/V3 模型使用ASPP捕捉上下文特征
-
Encoder/Decoder结果(如UNet)在上采样过程中融入低层次特征图,以获得更精细的分割图
-
DeepLab V3+将两种思路融合,在原有模型结构上增加了一个简单的decoder结构
Encoder通过ASPP产生多尺度的高层语义信息
Decoder主要融合低层特征产生惊喜的分割结果