介绍
MMTracking 是PyTorch的开源视频感知工具箱。它是OpenMMLab项目的一部分。
它支持 4 个视频任务:
视频对象检测 (VID)
单目标跟踪 (SOT)
多目标跟踪 (MOT)
视频实例分割 (VIS)
主要特点
第一个统一视频感知平台
我们是第一个统一多功能视频感知任务的开源工具箱,包括视频对象检测、多对象跟踪、单对象跟踪和视频实例分割。
模块化设计
我们将视频感知框架分解为不同的组件,并且可以通过组合不同的模块轻松构建定制的方法。
简单、快速、强大
简单:MMTracking 与其他 OpenMMLab 项目交互。它基于MMDetection构建,我们只需通过修改配置即可利用任何检测器。
快速:所有操作都在 GPU 上运行。训练和推理速度比其他实现更快或相当。
Strong:我们重现了最先进的模型,其中一些模型甚至优于官方实现。
入门
MMTracking的基本使用方法请参考get_started.md 。
提供了 Colab 教程。您可以在此处预览笔记本或直接在Colab上运行它。
号外号外~ MMTracking 要开始持续更新啦
同时释放了高效、强大的基准模型,部分实现超出官方版本(比如视频目标检测中的 SELSA、多目标跟踪中的 Tracktor、单目标跟踪中的 SiameseRPN++),在部分学术数据集(比如 ImageNet VID)达到 SOTA 水平。
1)、在 MMTracking V0.5.0 刚刚发布的时候,我们支持了以下算法:
视频目标检测(VID)算法:
视频目标检测只需要对视频内的每一帧进行检测,不要求对不同帧中的同一目标进行关联。
DFF (CVPR 2017)
FGFA (ICCV 2017)
SELSA (ICCV 2019)
Temporal RoI Align (AAAI 2021)
多目标跟踪(MOT)算法:
多目标检测在完成视频目标检测的基础上,更加侧重于对视频内的同一目标进行关联。
SORT (ICIP 2016)
DeepSORT (ICIP 2017)
Tracktor (ICCV 2019)
单目标跟踪(SOT)算法:
单目标跟踪更加侧重人机交互,算法需要在给定一个任意类别,任意形状目标的情况下,能够对其进行持续跟踪。
SiameseRPN++ (CVPR 2019)
MMTracking V0.7.0 发布啦!该版本主要新增了以下特性:
Codebase
重构、完善了英文用户文档、中文用户文档,用鲜明的例子告诉大家如何推理、测试、训练 VID、MOT、SOT 的模型
支持所有算法的 FP16 训练与测试
VID
支持新的视频目标检测算法 Temporal RoI Align (AAAI 2021), 同时为所有视频目标检测算法提供了使用 ResNeXt-101 为 backbone 的预训练模型,该方法以 84.1 mAP@50 的性能在 ImageNet VID 数据集上达到了 SOTA 水平
MOT
提供 Tracktor 在 MOT15、MOT16、MOT20 上的结果,在更加复杂的 MOT20 数据集的主要评估指标 MOTA 上,比官方版本高出 5.3 个点
支持在 MOT 数据集训练 ReID model
支持在 MOT 数据集进行错误(FP、FN、IDS)可视化分析
SOT
支持更多的 SOT 数据集:LaSOT、UAV123、TrackingNet,其它主流数据集也即将支持
OpenMMLab 内部项目间的充分交互
MMTracking: OpenMMLab 一体化视频目标感知平台
视频内的目标感知在大部分情况下可以认为是 2D 目标检测的下游任务,十分依赖各种 2D 目标检测算法。在此之前,如何使用或切换不同的 2D 目标检测器其实是一个很烦琐耗时的任务。
在 MMTracking 中,我们充分利用了 OpenMMLab 其他平台的成果与优势,极大的简化了代码框架。比如,我们 import 或继承了 MMDetection 中的大部分模块,极大的简化了代码框架。在这种模式下,我们可以通过 configs 直接使用 MMDetection 中的所有模型。以多目标跟踪举例,每一个多目标跟踪模型多由以下几个模块组成:
import torch.nn as nn
from mmdet.models import build_detector
class BaseMultiObjectTracker(nn.Module):
def __init__(self,
detector=None,
reid=None,
tracker=None,
motion=None,
pretrains=None):
self.detector = build_detector(detector)
...
Configs 示例:
model = dict(
type='BaseMultiObjectTracker',
detector=dict(type='FasterRCNN', **kwargs),
reid=dict(type='BaseReID', **kwargs),
motion=dict(type='KalmanFilter', **kwargs),
tracker=dict(type='BaseTracker', **kwargs))
快速上手!MMTracking 食用指南 之 VID 篇(视频目标检测)(附 AAAI2021 论文解读 !)
1、运行 VID demo
该脚本可以使用视频对象检测模型来推断输入视频。
python demo/demo_vid.py \
${CONFIG_FILE}\
--input ${INPUT} \
--checkpoint ${CHECKPOINT_FILE} \
[--output ${OUTPUT}] \
[--device ${DEVICE}] \
[--show]
并且INPUT和OUTPUT支持mp4视频格式和文件夹格式。
可选参数:
OUTPUT:可视化演示的输出。如果未指定,则–show有义务即时播放视频。
DEVICE:用于推理的设备。选项有cpu或cuda:0等。
–show:是否动态显示视频。
例子:
假设您已经将检查点下载到该目录checkpoints/,您的视频文件名为demo.mp4,输出路径为./outputs/
python ./demo/demo_vid.py \
configs/vid/selsa/selsa_faster-rcnn_r50-dc5_8xb1-7e_imagenetvid.py \
--input ./demo.mp4 \
--checkpoint checkpoints/selsa_faster_rcnn_r101_dc5_1x_imagenetvid_20201218_172724-aa961bcc.pth \
--output ./outputs/ \
--show
在 MMTracking 根目录下只需执行以下命令,即可使用 SELSA + Temporal RoI Align 算法运行 VID demo
python demo/demo_vid.py configs/vid/temporal_roi_align/selsa-troialign_faster-rcnn_r101-dc5_8xb1-7e_imagenetvid.py --input demo/demo.mp4 --checkpoint checkpoints/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid_20210822_111621-22cb96b9.pth --output vid.mp4 --show
python demo/demo_vid.py configs/vid/temporal_roi_align/selsa-troialign_faster-rcnn_x101-dc5_8xb1-7e_imagenetvid.py --input demo/demo.mp4 --checkpoint checkpoints/selsa_troialign_faster_rcnn_x101_dc5_7e_imagenetvid_20210822_164036-4471ac42.pth --output vid.mp4 --show
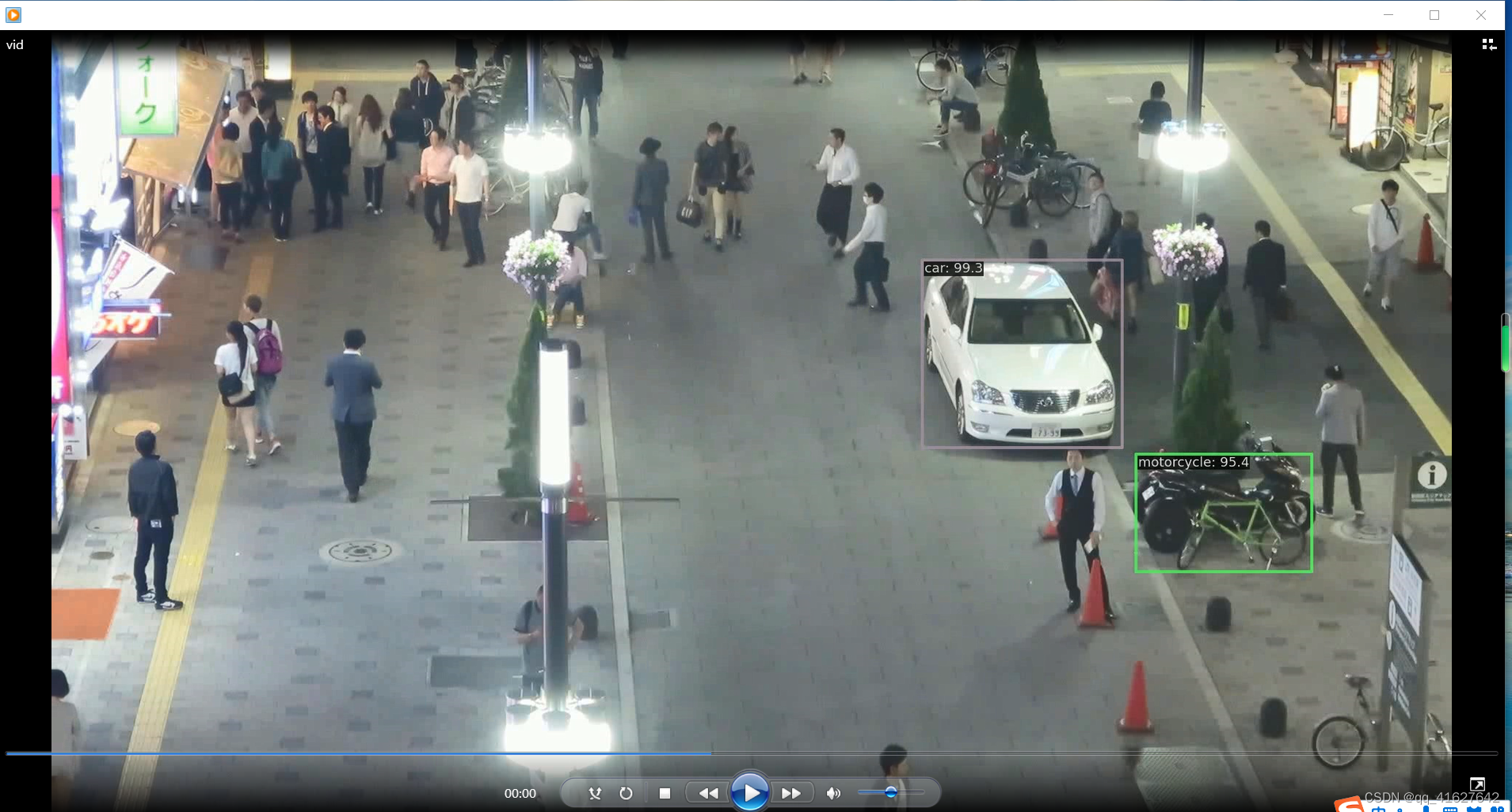
2、测试 VID 模型
在 MMTracking 根目录下使用以下命令即可测试 VID 模型,并且评估模型的 bbox mAP
./tools/dist_test.sh configs/vid/temporal_roi_align/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid.py 8 \
--checkpoint checkpoints/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid_20210822_111621-22cb96b9.pth \
--out results.pkl \
--eval bbox
3、训练 VID 模型
在 MMTracking 根目录下使用以下命令即可训练 VID 模型,并且在最后一个 epoch 评估模型的 bbox mAP
./tools/dist_train.sh ./configs/temporal_roi_align/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid.py 8 \
--work-dir ./work_dirs/
最新上线!MMTracking 视频实例分割篇食用指南
上新!MMTracking 单目标跟踪任务食用指南
MMTracking 多目标跟踪(MOT)任务的食用指南