LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe
文章目录
一、Chat models
1.1 Chat models简介
LCEL提供了声明式的方式来组合Runnables成为链,它是一个标准接口,可以轻松定义自定义链条并以标准方式调用它们,还可以批处理、流处理等。该标准接口包括以下几个方法(前缀'a'表示为对应的异步处理方法):
- invoke/ainvoke:处理单个输入
- batch/abatch:批处理多个输入列表
- stream/astream:流式处理单个输入并产生输出
astream_log:流式返回中间步骤的数据,以及最终响应数据
所有 ChatModel 都实现Runnable接口,该接口附带以上所有方法的默认实现 ,这为所有 ChatModel 提供了对异步、流式传输和批处理的基本支持。另外,Stream方法还需要 ChatModel厂商本身也支持,最终各种 ChatModel的集成情况,详见《Chat models》。
- 有关LCEL及Runnables的更多信息,详见《LangChain(0.0.339)官方文档二:LCEL》
- 有关LangChain内置集成的各种Chat models文档,可查看Integrations部分。
Chat models底层实现是LLMs,但它不使用“文本输入、文本输出”API,而是使用“聊天消息”作为输入和输出的界面,即chat model基于消息(List[BaseMessage] )而不是原始文本。在langchain中,消息接口由 BaseMessage 定义,它有两个必需属性:
content:消息的内容,通常为字符串。role:消息来源(BaseMessage)的实体类别,比如:HumanMessage:来自人类/用户的BaseMessage。AIMessage:来自AI/助手的BaseMessage。SystemMessage:来自系统的BaseMessage。FunctionMessage/ ToolMessage:包含函数或工具调用输出的BaseMessage。ChatMessage:如果上述角色都不合适,可以自定义角色,详见《Types of MessagePromptTemplate》。- 消息也可以是 str (将自动转换为 HumanMessage )和 PromptValue(PromptTemplate的值) 。
对应的,LangChain提供了不同类型的 MessagePromptTemplate 。最常用的是 AIMessagePromptTemplate 、 SystemMessagePromptTemplate 和 HumanMessagePromptTemplate ,它们分别创建 AI 消息、系统消息和用户消息。
1.2 Chat models的调用方式
在简单的应用中,单独使用LLM是可以的,但在更复杂的应用中,可能需要将多个大型语言模型进行链式组合,或与其他组件进行链式调用,以对多个输入同时进行处理。组合成Chain的方式有两种:
- 使用内置的 Chain,比如LLMChain(基本的链类型)、SequentialChain(处理单个输入且单个输出的情况)、Router Chain(同一输入router到不同的输出)。
- 使用最新的LCEL(LangChain Expression Language)框架来实现chaining,调用Runnables的各种实现方法。
1.2.1 配置Baidu Qianfan
本章以百度文心一言为例进行演示。要调用文心一言 API,需要先获取文心一言调用秘钥。首先我们需要进入文心千帆服务平台,注册登录之后选择“应用接入”——“创建应用”。然后简单输入基本信息,选择默认配置,创建应用即可。
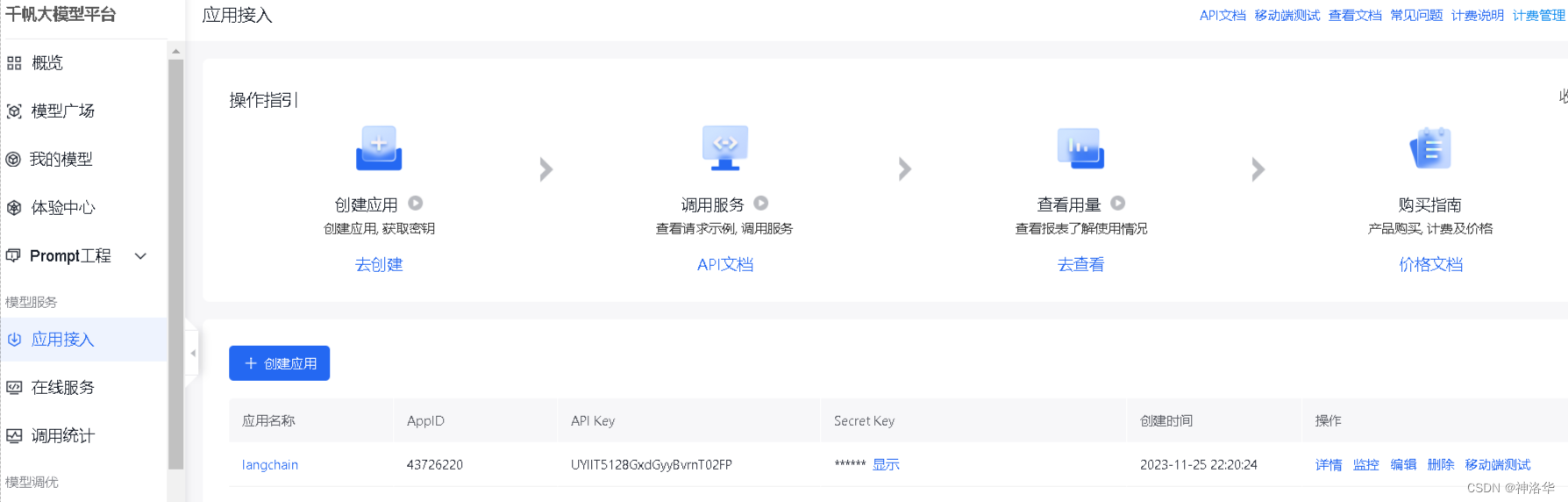
创建完成后,点击应用的“详情”即可看到此应用的 AppID,API Key,Secret Key。然后在百度智能云在线调试平台-示例代码中心快速调试接口,获取AccessToken(不解之处,详见API文档)。最后在项目文件夹下使用vim .env(Linux)或type nul > .env(Windows cmd)创建.env文件,并在其中写入:
QIANFAN_AK="xxx"
QIANFAN_SK="xxx"
access_token="xxx"
下面将这些变量配置到环境中,后续就可以自动使用了。
# 使用openai、智谱ChatGLM、百度文心需要分别安装openai,zhipuai,qianfan
import os
import openai,zhipuai,qianfan
from langchain.llms import ChatGLM
from langchain.chat_models import ChatOpenAI,QianfanChatEndpoint
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key =os.environ['OPENAI_API_KEY']
zhipuai.api_key =os.environ['ZHIPUAI_API_KEY']
qianfan.qianfan_ak=os.environ['QIANFAN_AK']
qianfan.qianfan_sk=os.environ['QIANFAN_SK']
from langchain.schema.messages import HumanMessage,SystemMessage
messages = [
SystemMessage(content="You're a helpful assistant"),
HumanMessage(content="What is the purpose of model regularization?"),
]
chat = QianfanChatEndpoint()
更多内容请参考《Baidu Qianfan》
1.2.2 使用LCEL方式调用Chat models
- 常规调用
chat.invoke(messages) # 处理单个输入
chat.batch([messages]) # 批处理输入
# 流式处理输入
for chunk in chat.stream(messages):
print(chunk.content, end="", flush=True)
AIMessage(content='模型正则化的目的是为了防止模型过拟合,提高模型的泛化能力。模型正则化通过引入额外的项,使得模型在训练过程中需要最小化这些项的损失,从而约束模型的复杂度,避免模型对训练数据中的噪声和异常值过度拟合。这样可以提高模型的泛化能力,使得模型在未见过的数据上也能表现良好。常见的模型正则化方法包括L1正则化、L2正则化、dropout等。', additional_kwargs={'id': 'as-2y2heq69su', 'object': 'chat.completion', 'created': 1701506605, 'result': '模型正则化的目的是为了防止模型过拟合,提高模型的泛化能力。模型正则化通过引入额外的项,使得模型在训练过程中需要最小化这些项的损失,从而约束模型的复杂度,避免模型对训练数据中的噪声和异常值过度拟合。这样可以提高模型的泛化能力,使得模型在未见过的数据上也能表现良好。常见的模型正则化方法包括L1正则化、L2正则化、dropout等。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 9, 'completion_tokens': 101, 'total_tokens': 110}})
再举一个简单的例子:
answer=chat.invoke("使用‘白小林’写一首三行诗")
answer
AIMessage(content='白小林游历天涯,\n心灵轻舞映朝霞。\n笑看人生四季花。', additional_kwargs={'id': 'as-q59v21q44t', 'object': 'chat.completion', 'created': 1701510940, 'result': '白小林游历天涯,\n心灵轻舞映朝霞。\n笑看人生四季花。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 11, 'completion_tokens': 22, 'total_tokens': 33}})
返回的结果是一个AIMessage,可以使用dict将其转为字典格式进行后续处理:
print(answer.dict()['content'])
白小林游历天涯,
心灵轻舞映朝霞。
笑看人生四季花。
print(answer.dict()['additional_kwargs']['usage'])
{'prompt_tokens': 11, 'completion_tokens': 22, 'total_tokens': 33}
- 异步调用:
# 异步处理输入
await chat.ainvoke(messages)
async for chunk in chat.astream(messages):
print(chunk.content, end="", flush=True)
async for chunk in chat.astream_log(messages):
print(chunk)
1.2.3 使用内置Chain调用Chat models
在旧版的LangChain中,可以将一条或多条消息传递给chat model.来完成聊天,输出是一条消息。
chat(messages) # 输出和chat.invoke(messages)一样
也可以使用 generate来进行多条消息的批处理:
batch_messages = [
[
SystemMessage(
content="You are a helpful assistant that translates English to French."
),
HumanMessage(content="I love programming."),
],
[
SystemMessage(
content="You are a helpful assistant that translates English to French."
),
HumanMessage(content="I love artificial intelligence."),
],
]
result = chat.generate(batch_messages)
result
LLMResult(generations=[[ChatGeneration(text='非常好!编程是一项非常有趣和有挑战性的工作。你更喜欢哪种类型的编程?', generation_info={'finish_reason': 'stop', 'id': 'as-eczv9t6wdu', 'object': 'chat.completion', 'created': 1701507897, 'result': '非常好!编程是一项非常有趣和有挑战性的工作。你更喜欢哪种类型的编程?', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 4, 'completion_tokens': 19, 'total_tokens': 23}}, message=AIMessage(content='非常好!编程是一项非常有趣和有挑战性的工作。你更喜欢哪种类型的编程?', additional_kwargs={'id': 'as-eczv9t6wdu', 'object': 'chat.completion', 'created': 1701507897, 'result': '非常好!编程是一项非常有趣和有挑战性的工作。你更喜欢哪种类型的编程?', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 4, 'completion_tokens': 19, 'total_tokens': 23}}))], [ChatGeneration(text='很好,你对人工智能的热爱很令人赞赏。人工智能技术已经变得越来越重要,它正在改变我们的生活和工作方式。', generation_info={'finish_reason': 'stop', 'id': 'as-7gc409h5d1', 'object': 'chat.completion', 'created': 1701507898, 'result': '很好,你对人工智能的热爱很令人赞赏。人工智能技术已经变得越来越重要,它正在改变我们的生活和工作方式。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 5, 'completion_tokens': 24, 'total_tokens': 29}}, message=AIMessage(content='很好,你对人工智能的热爱很令人赞赏。人工智能技术已经变得越来越重要,它正在改变我们的生活和工作方式。', additional_kwargs={'id': 'as-7gc409h5d1', 'object': 'chat.completion', 'created': 1701507898, 'result': '很好,你对人工智能的热爱很令人赞赏。人工智能技术已经变得越来越重要,它正在改变我们的生活和工作方式。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 5, 'completion_tokens': 24, 'total_tokens': 29}}))]], llm_output={}, run=[RunInfo(run_id=UUID('a81202f3-8210-44f9-959c-0e6af4686ae7')), RunInfo(run_id=UUID('564b8ec4-3531-4b6e-b50c-1baafd16e8ff'))])
1.3 缓存
LangChain为chat models提供了可选的缓存层(caching layer),如果您经常多次进行相同的请求,那么它可以减少API调用次数,从而在一定程度上降低费用,也加速了应用的响应速度。
from langchain.globals import set_llm_cache
from langchain.chat_models import ChatOpenAI
llm = QianfanChatEndpoint()
1.3.1 内存缓存
from langchain.cache import InMemoryCache
set_llm_cache(InMemoryCache())
# 第一次生成时间较长
llm.predict("Tell me a joke")
CPU times: user 35.9 ms, sys: 28.6 ms, total: 64.6 ms
Wall time: 4.83 s
"\n\nWhy couldn't the bicycle stand up by itself? It was...two tired!"
# 第二次从内存加载,时间更短
llm.predict("Tell me a joke")
CPU times: user 238 µs, sys: 143 µs, total: 381 µs
Wall time: 1.76 ms
'\n\nWhy did the chicken cross the road?\n\nTo get to the other side.'
1.3.2 SQLite 缓存
SQLite 是一种嵌入式关系型数据库引擎,它是一个零配置的、无服务器的、自包含的数据库系统。与传统的数据库管理系统(DBMS)不同,SQLite 不需要单独的服务器进程来运行,而是直接嵌入到应用程序中。这使得 SQLite 成为一种轻量级、无服务器的、自包含的数据库系统,适用于小型应用和嵌入式设备。
rm .langchain.db
下面设置LangChain 的 LLM 缓存设置为 SQLiteCache,并指定 SQLite 数据库的文件路径为 ".langchain.db"。
from langchain.cache import SQLiteCache
set_llm_cache(SQLiteCache(database_path=".langchain.db"))
llm.predict("Tell me a joke")
CPU times: user 17 ms, sys: 9.76 ms, total: 26.7 ms
Wall time: 825 ms
'\n\nWhy did the chicken cross the road?\n\nTo get to the other side.'
# The second time it is, so it goes faster
llm.predict("Tell me a joke")
CPU times: user 2.46 ms, sys: 1.23 ms, total: 3.7 ms
Wall time: 2.67 ms
'\n\nWhy did the chicken cross the road?\n\nTo get to the other side.'
1.4 Prompts
1.4.1 使用(role, content)创建
ChatPromptTemplate是 chat models 的聊天消息列表。 每个聊天消息都与内容相关联,并具有一个称为role(角色)的额外参数。例如,在 OpenAI 聊天补全 API 中,聊天消息可以与 AI 助手、人类或系统角色相关联。创建一个聊天提示模板就像这样:
from langchain.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
messages
[SystemMessage(content='You are a helpful AI bot. Your name is Bob.'),
HumanMessage(content='Hello, how are you doing?'),
AIMessage(content="I'm doing well, thanks!"),
HumanMessage(content='What is your name?')]
1.4.2 使用MessagePromptTemplate创建
ChatPromptTemplate.from_messages接受多种消息表示方式。比如除了使用上面提到的(type, content)的2元组表示法之外,你还可以传入MessagePromptTemplate或BaseMessage的实例,这为你在构建聊天提示时提供了很大的灵活性,下面用百度千帆进行演示。
import os
import openai,qianfan
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key =os.environ['OPENAI_API_KEY']
qianfan.qianfan_ak=os.environ['QIANFAN_AK']
qianfan.qianfan_sk=os.environ['QIANFAN_SK']
- 使用MessagePromptTemplate
from langchain.chat_models import QianfanChatEndpoint
from langchain.prompts import HumanMessagePromptTemplate,SystemMessagePromptTemplate
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chat = QianfanChatEndpoint()
chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
AIMessage(content='编程是一项非常有趣和有挑战性的工作,我很羡慕你能够享受其中的乐趣。', additional_kwargs={'id': 'as-cxezsmtfga', 'object': 'chat.completion', 'created': 1701520678, 'result': '编程是一项非常有趣和有挑战性的工作,我很羡慕你能够享受其中的乐趣。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 4, 'completion_tokens': 18, 'total_tokens': 22}})
- 使用BaseMessage的实例
from langchain.schema.messages import SystemMessage
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant that re-writes the user's text to "
"sound more upbeat."
)
),
HumanMessagePromptTemplate.from_template("{text}"),
]
)
chat(chat_template.format_messages(text="i dont like eating tasty things."))
AIMessage(content='很抱歉听到您不喜欢吃美味的食物。您有其他喜欢的食物类型吗?或许我们可以找到一些其他您喜欢吃的食物,您试试看是否能够喜欢呢?', additional_kwargs={
'id': 'as-sdcbpxad11', 'object': 'chat.completion', 'created': 1701520841, 'result': '很抱歉听到您不喜欢吃美味的食物。您有其他喜欢的食物类型吗?或许我们可以找到一些其他您喜欢吃的食物,您试试看是否能够喜欢呢?', 'is_truncated': False, 'need_clear_history': False, 'usage': {
'prompt_tokens': 8, 'completion_tokens': 34, 'total_tokens': 42}})
1.5 跟踪令牌使用情况
本节介绍如何跟踪调用的令牌使用情况,目前仅针对 OpenAI API 实现。
1.5.1 跟踪单个 Chat model
from langchain.callbacks import get_openai_callback
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4")
with get_openai_callback() as cb:
result = llm.invoke("Tell me a joke")
print(cb)
Tokens Used: 24
Prompt Tokens: 11
Completion Tokens: 13
Successful Requests: 1
Total Cost (USD): $0.0011099999999999999
按顺序跟踪多个请求:
with get_openai_callback() as cb:
result = llm.invoke("Tell me a joke")
result2 = llm.invoke("Tell me a joke")
print(cb.total_tokens)
48
1.5.2 跟踪chain或agent
from langchain.agents import AgentType, initialize_agent, load_tools
from langchain.llms import OpenAI
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.OPENAI_FUNCTIONS, verbose=True)
with get_openai_callback() as cb:
response = agent.run(
"Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?"
)
print(f"Total Tokens: {
cb.total_tokens}")
print(f"Prompt Tokens: {
cb.prompt_tokens}")
print(f"Completion Tokens: {
cb.completion_tokens}")
print(f"Total Cost (USD): ${
cb.total_cost}")
> Entering new AgentExecutor chain...
Invoking: `Search` with `Olivia Wilde's current boyfriend`
['Things are looking golden for Olivia Wilde, as the actress has jumped back into the dating pool following her split from Harry Styles — read ...', "“I did not want service to take place at the home of Olivia's current partner because Otis and Daisy might be present,” Sudeikis wrote in his ...", "February 2021: Olivia Wilde praises Harry Styles' modesty. One month after the duo made headlines with their budding romance, Wilde gave her new beau major ...", 'An insider revealed to People that the new couple had been dating for some time. "They were in Montecito, California this weekend for a wedding, ...', 'A source told People last year that Wilde and Styles were still friends despite deciding to take a break. "He\'s still touring and is now going ...', "... love life. “He's your typical average Joe.” The source adds, “She's not giving too much away right now and wants to keep the relationship ...", "Multiple sources said the two were “taking a break” from dating because of distance and different priorities. “He's still touring and is now ...", 'Comments. Filed under. celebrity couples · celebrity dating · harry styles · jason sudeikis · olivia wilde ... Now Holds A Darker MeaningNYPost.', '... dating during filming. The 39-year-old did however look very cosy with the comedian, although his relationship status is unknown. Olivia ...']
Invoking: `Search` with `Harry Styles current age`
responded: Olivia Wilde's current boyfriend is Harry Styles. Let me find out his age for you.
29 years
Invoking: `Calculator` with `29 ^ 0.23`
Answer: 2.169459462491557Harry Styles' current age (29 years) raised to the 0.23 power is approximately 2.17.
> Finished chain.
Total Tokens: 1929
Prompt Tokens: 1799
Completion Tokens: 130
Total Cost (USD): $0.06176999999999999
二、LLMs
参考《》
2.1 LLMs的调用
同Chat models一样,LLM也实现了 Runnable 接口,所以你同样可以使用LCEL语法进行调用,比如invoke方法:
from langchain.llms import QianfanLLMEndpoint
llm = QianfanLLMEndpoint()
print(llm.invoke("使用‘白小林’写一首三行诗"))
白小林在林间漫步,
阳光洒落笑语连连。
林中鸟鸣声声醉,
白小林心中乐无边。
其它iainvoke、batch/abatch、stream/astream、astream_log方法和Chat models一样,就不一一演示了。另外,也可以使用内置的chain方法进行调用:
llm("Tell me a joke")
'\n\nQ: What did the fish say when it hit the wall?\nA: Dam!'
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"] * 3)
len(llm_result.generations)
6
另外有关各LLMs是否支持异步调用、流式调用,详见LLMs中的Model表格。
2.2 异步API
LLM通过实现Runnable接口提供了异步调用的基本支持,如果LLM提供商有原生的异步实现,会优先使用这些实现,否则默认使用LLM的异步支持方式,将调用移到后台线程以便让应用中的其他异步函数继续执行。
import asyncio
import time
from langchain.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-instruct", temperature=0.9)
def invoke_serially():
for _ in range(10):
resp = llm.invoke("Hello, how are you?")
async def async_invoke(llm):
resp = await llm.ainvoke("Hello, how are you?")
async def invoke_concurrently():
tasks = [async_invoke(llm) for _ in range(10)]
await asyncio.gather(*tasks)
s = time.perf_counter()
# If running this outside of Jupyter, use asyncio.run(generate_concurrently())
await invoke_concurrently()
elapsed = time.perf_counter() - s
print("\033[1m" + f"Concurrent executed in {
elapsed:0.2f} seconds." + "\033[0m")
s = time.perf_counter()
invoke_serially()
elapsed = time.perf_counter() - s
print("\033[1m" + f"Serial executed in {
elapsed:0.2f} seconds." + "\033[0m")
Concurrent executed in 1.03 seconds.
Serial executed in 6.80 seconds.
为了简化代码,我们也可以使用 abatch 进行异步批处理:
s = time.perf_counter()
# If running this outside of Jupyter, use asyncio.run(generate_concurrently())
await llm.abatch(["Hello, how are you?"] * 10)
elapsed = time.perf_counter() - s
print("\033[1m" + f"Batch executed in {
elapsed:0.2f} seconds." + "\033[0m")
Batch executed in 1.31 seconds.
| 方法 | 说明 | 执行时间 |
|---|---|---|
invoke_serially() |
使用循环方式执行LLM的操作10次 | 约6.8秒 |
invoke_concurrently() |
使用ainvoke在循环中以异步方式执行操作10次 |
约1.03秒,展示了并行执行的优势 |
abatch |
批处理请求(异步) | 约1.31秒,展示了批处理的高效性 |
| 原生异步实现 | 如果LLM提供商支持原生异步操作,可能比提供的默认异步功能更有效率 |
2.3 自定义 LLM
2.3.1 自定义 LLM的简单实现
对于你自己的LLM或者LangChain尚没有封装支持的LLM,可以创建自定义的LLM封装器,只需要实现:
_call方法:此方法接收一个字符串和一些可选的停用词,然后返回一个字符串_identifying_params属性(可选):用于帮助打印这个类时的显示信息(字典类型)
下面实现一个非常简单的自定义LLM,其功能是返回输入文本的前n个字符。
from typing import Any, List, Mapping, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.llms.base import LLM
class CustomLLM(LLM):
n: int
@property
def _llm_type(self) -> str:
return "custom"
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
return prompt[: self.n]
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {
"n": self.n}
这段代码定义了一个名为CustomLLM的类,它继承自LLM基类,并实现了自定义的LLM功能。
-
n: int:这是一个类属性,用于存储一个整数值。它表示后面在_call方法中会用到的字符数量。 -
_llm_type方法:这是一个私有方法,返回一个描述此LLM类型的字符串。在这里,返回的是"custom",用于标识这是一个自定义的LLM类型。 -
_call方法:这个方法是必须实现的,它接收一个字符串prompt作为输入,还可以接收一个可选的stop参数(一个字符串列表),以及其他任意的关键字参数。这个方法的功能是根据给定的prompt字符串返回其前面n个字符。如果传入了stop参数,会引发一个ValueError异常,因为这里不允许使用stop参数。 -
_identifying_params方法:这是一个属性方法,返回一个包含LLM标识参数的字典。在这个例子中,它返回一个字典,包含了一个键为"n"的参数,其值为self.n,即当前的字符数量。
然后我们就可以像别的LLM一样来调用了:
llm = CustomLLM(n=10)
llm("This is a foobar thing")
'This is a '
打印此LLM以查看信息:
print(llm)
CustomLLM
Params: {'n': 10}
2.3.2 自定义zhipuai&百度文心 LLM
llm-universe项目中有自定义zhipuai LLM的实现zhipuai_llm.py,和自定义百度文心LLM实现wenxin_llm.py,可供参考(之前版本的LangChain有很多模型每月集成)。
2.4 缓存
同Chat model一样,LLM也可以使用缓存来获取重复的请求结果。
#### 2.4.1 内存缓存
from langchain.globals import set_llm_cache
from langchain.llms import OpenAI
# To make the caching really obvious, lets use a slower model.
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
2.4.1 内存缓存
from langchain.cache import InMemoryCache
set_llm_cache(InMemoryCache())
# The first time, it is not yet in cache, so it should take longer
llm.predict("Tell me a joke")
# The second time it is, so it goes faster
llm.predict("Tell me a joke")
2.4.2 SQLite 缓存
rm .langchain.db
# We can do the same thing with a SQLite cache
from langchain.cache import SQLiteCache
set_llm_cache(SQLiteCache(database_path=".langchain.db"))
# The first time, it is not yet in cache, so it should take longer
llm.predict("Tell me a joke")
# The second time it is, so it goes faster
llm.predict("Tell me a joke")
2.4.3 关闭特定LLM的 缓存
您还可以选择在启用了全局缓存后,关闭特定的 LLM的 缓存。
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2, cache=False)
llm("Tell me a joke")
CPU times: user 5.8 ms, sys: 2.71 ms, total: 8.51 ms
Wall time: 745 ms
'\n\nWhy did the chicken cross the road?\n\nTo get to the other side!'
llm("Tell me a joke") # 两次时间差不多,表示没有启用缓存的结果
CPU times: user 4.91 ms, sys: 2.64 ms, total: 7.55 ms
Wall time: 623 ms
'\n\nTwo guys stole a calendar. They got six months each.'
2.4.4 可选链式缓存
您还可以在链中只缓存部分节点。下面示例中,我们将加载一个总结器的Map-Reduce链。我们会对Map步骤的结果进行缓存,但对Combine步骤的结果不缓存(中间结果缓存加载,最终结果直接生成)。
首先创建两个OpenAI的LLM实例,其中一个将缓存关闭。然后,使用CharacterTextSplitter读取state_of_the_union.txt的文本内容,并将其分成多个文档,创建对应的Document对象。
llm = OpenAI(model_name="text-davinci-002")
no_cache_llm = OpenAI(model_name="text-davinci-002", cache=False)
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.mapreduce import MapReduceChain
from langchain.docstore.document import Document
text_splitter = CharacterTextSplitter()
with open('../../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
texts = text_splitter.split_text(state_of_the_union)
docs = [Document(page_content=t) for t in texts[:3]]
接下来,使用load_summarize_chain方法加载总结器的Map-Reduce链,并指定了对应的LLM和链类型。在这里,为了Map步骤使用了允许缓存的LLM,而对Reduce步骤使用了禁用缓存的LLM。
from langchain.chains.summarize import load_summarize_chain
chain = load_summarize_chain(llm, chain_type="map_reduce", reduce_llm=no_cache_llm)
chain.run(docs)
CPU times: user 452 ms, sys: 60.3 ms, total: 512 ms
Wall time: 5.09 s
'\n\nPresident Biden is discussing the American Rescue Plan and the Bipartisan Infrastructure Law, which will create jobs and help Americans. He also talks about his vision for America, which includes investing in education and infrastructure. In response to Russian aggression in Ukraine, the United States is joining with European allies to impose sanctions and isolate Russia. American forces are being mobilized to protect NATO countries in the event that Putin decides to keep moving west. The Ukrainians are bravely fighting back, but the next few weeks will be hard for them. Putin will pay a high price for his actions in the long run. Americans should not be alarmed, as the United States is taking action to protect its interests and allies.'
再次当运行该链后,执行速度明显提高,但最终的结果与之前运行的结果不同。这是因为在Map步骤进行了缓存,但在Reduce步骤没有进行缓存,而是直接生成的。
chain.run(docs)
CPU times: user 11.5 ms, sys: 4.33 ms, total: 15.8 ms
Wall time: 1.04 s
'\n\nPresident Biden is discussing the American Rescue Plan and the Bipartisan Infrastructure Law, which will create jobs and help Americans. He also talks about his vision for America, which includes investing in education and infrastructure.'
此外还有Redis Cache、GPTCache、Momento Cache等,详见《LLM Caching integrations》。
2.5 序列化
序列化是指将对象的状态转换为字节流或JSON和XML等格式,使其能够在不同系统、编程语言或存储介质之间进行传输或持久化存储。反序列化则是将序列化后的数据重新转换为对象的过程。
LangChain的Python和LangChain的JavaScript共享一个序列化方案,即无论是使用Python还是JavaScript编写的代码,在处理LangChain对象的序列化和反序列化时,可以采用相同的机制和格式,提供了跨语言交互和数据共享的能力。
通过运行类方法is_lc_serializable,你可以检查一个LangChain类是否可序列化。
from langchain.llms import OpenAI
from langchain.llms.loading import load_llm
OpenAI.is_lc_serializable()
True
2.5.1 存储
任何可序列化的对象都可以序列化为 dict 或 json 字符串,下面演示dumpd和dumps两种方法。
from langchain.load import dumpd, dumps
llm = OpenAI(model="gpt-3.5-turbo-instruct")
dumpd(llm)
{'lc': 1,
'type': 'constructor',
'id': ['langchain', 'llms', 'openai', 'OpenAI'],
'kwargs': {'model': 'gpt-3.5-turbo-instruct',
'openai_api_key': {'lc': 1, 'type': 'secret', 'id': ['OPENAI_API_KEY']}}}
dumps(llm)
'{"lc": 1, "type": "constructor", "id": ["langchain", "llms", "openai", "OpenAI"], "kwargs": {"model": "gpt-3.5-turbo-instruct", "openai_api_key": {"lc": 1, "type": "secret", "id": ["OPENAI_API_KEY"]}}}'
2.5.2 加载
from langchain.load import loads
from langchain.load.load import load
loaded_1 = load(dumpd(llm))
loaded_2 = loads(dumps(llm))
print(loaded_1.invoke("How are you doing?"))
I am an AI and do not have the capability to experience emotions. But thank you for asking. Is there anything I can assist you with?
2.6 跟踪令牌使用情况(略)
跟踪LLM令牌使用情况同Chat models差不多,目前仅也针对 OpenAI API 实现,直接查看文档《Tracking token usage》就行,这里就不写了。