LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe
一、Text embedding models
1.1 Embeddings类

embedding models会创建文本的向量表示,这对于在LLM中检索相关上下文至关重要。langchain_core.embeddings.Embeddings类是Langchain提供的用于嵌入模型的接口类。它是一个抽象基类,定义了嵌入模型的通用接口。该类提供了以下方法:
embed_documents(texts: List[str]) -> List[List[float]]:将文本列表嵌入为向量表示。返回一个包含每个文本向量的列表。embed_query(text: str) -> List[float]:将单个文本嵌入为向量表示。返回一个表示文本向量的列表。
这两个方法分别接受文档嵌入(多个文本)和查询嵌入(单个文本)作为输入。之所以这么做,是因为一些嵌入提供商针对文档(待搜索的内容)和查询(搜索查询本身)提供不同的嵌入方法。另外Embeddings类还有对应的异步方法aembed_documents和aembed_query。
1.2 OpenAI
# 使用openai、智谱ChatGLM、百度文心需要分别安装openai,zhipuai,qianfan
import os
import openai,zhipuai,qianfan
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key =os.environ['OPENAI_API_KEY']
zhipuai.api_key =os.environ['ZHIPUAI_API_KEY']
qianfan.qianfan_ak=os.environ['QIANFAN_AK']
qianfan.qianfan_sk=os.environ['QIANFAN_SK']
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
- embed_documents
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
(5, 1536)
- embed_query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
embedded_query[:5]
[0.0053587136790156364,
-0.0004999046213924885,
0.038883671164512634,
-0.003001077566295862,
-0.00900818221271038]
1.3 Sentence Transformers on Hugging Face
Hugging Face sentence-transformers是一个常用进行sentence、text和image嵌入的模型。LangChain在HuggingFaceEmbeddings 类中集成了此模型,另外还为更熟悉直接使用该包的用户添加了 SentenceTransformerEmbeddings 的别名。
!pip install langchain sentence_transformers
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# Equivalent to SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text, "This is not a test document."])
1.4 CacheBackedEmbeddings
1.4.1 简介
CacheBackedEmbeddings是Langchain中的一个嵌入模型包装器,通过在键值存储(文本被哈希处理,并将哈希用作缓存中的键)中缓存嵌入结果以避免重复计算。它支持使用不同的字节存储(ByteStore)来进行缓存,例如本地文件系统或内存存储。CacheBackedEmbeddings的主要方法为:
-
from_bytes_store:初始化 CacheBackedEmbeddings,包含以下参数:- underlying_embedder:嵌入模型(Embeddings类)
- document_embedding_cache:字节存储( BaseStore类),用于缓存文档嵌入。可以根据具体需求选择不同的字节存储来进行缓存,以满足不同的应用场景。
- namespace:用于文档缓存的命名空间,可选。最好是设置 namespace 参数,以避免使用不同嵌入模型嵌入的相同文本发生冲突,比如将其设置为所使用的嵌入模型的名称。
-
embed_documents:将文本列表嵌入为向量表示。如果缓存中不存在对应的嵌入结果,会使用底层的嵌入模型进行计算,并将结果存储在缓存中。 -
embed_query:将单个文本嵌入为向量表示。目前该方法不支持缓存。
CacheBackedEmbeddings同样支持异步嵌入方法aembed_documents和aembed_query。
1.4.2 与Vector Store一起使用
让我们看一个使用本地文件系统存储嵌入并使用 FAISS 矢量存储进行检索的示例。
#!pip install openai faiss-cpu
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.storage import LocalFileStore
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
underlying_embeddings = OpenAIEmbeddings()
store = LocalFileStore("./cache/")
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, store, namespace=underlying_embeddings.model
)
之前的嵌入缓存为空:
list(store.yield_keys())
[]
加载文档,将其分割成块,嵌入每个块并将其加载到向量存储中:
raw_documents = TextLoader("../../state_of_the_union.txt").load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
%%time
db = FAISS.from_documents(documents, cached_embedder) # 创建向量存储
CPU times: user 218 ms, sys: 29.7 ms, total: 248 ms
Wall time: 1.02 s
如果我们尝试再次创建向量存储,它会快得多,因为它不需要重新计算任何嵌入。
%%time
db2 = FAISS.from_documents(documents, cached_embedder)
CPU times: user 15.7 ms, sys: 2.22 ms, total: 18 ms
Wall time: 17.2 ms
以下是创建的一些嵌入:
list(store.yield_keys())[:5]
['text-embedding-ada-00217a6727d-8916-54eb-b196-ec9c9d6ca472',
'text-embedding-ada-0025fc0d904-bd80-52da-95c9-441015bfb438',
'text-embedding-ada-002e4ad20ef-dfaa-5916-9459-f90c6d8e8159',
'text-embedding-ada-002ed199159-c1cd-5597-9757-f80498e8f17b',
'text-embedding-ada-0021297d37a-2bc1-5e19-bf13-6c950f075062']
1.4.3 内存缓存
下面演示使用InMemoryByteStore 作为ByteStore,即将嵌入临时缓存到内存中,而非持久化存储在磁盘中,这只需要在初始化时切换store就行。
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import InMemoryByteStore
store = InMemoryByteStore()
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, store, namespace=underlying_embeddings.model
)
二、Vector stores
2.1 langchain_core.vectorstores
处理和搜索非结构化数据最常见的方式是将其进行嵌入,然后将生成的嵌入向量存储在向量存储库中(Vector stores),后续就可以对此数据库执行向量搜索,以检索到与query最相似的结果。
langchain_core.vectorstores提供了超过50种Vector stores(详见Vector stores集成) 。其主要方法为:
| 函数名 | 描述 |
|---|---|
as_retriever(**kwargs) |
创建一个检索器对象,并使用其提供的方法进行文档检索。 |
from_documents(documents, embedding, **kwargs) |
从指定的文档和向量模型初始化一个向量存储库 |
from_texts(texts, embedding[, metadatas]) |
从指定的文本和向量模型初始化一个向量存储库 |
add_documents(documents, **kwargs) |
添加文档嵌入到向量存储中。 |
add_texts(texts[, metadatas]) |
添加文本嵌入添加到向量存储中。 |
search(query, search_type, **kwargs) |
使用指定的搜索类型检索相似文档 |
similarity_search(query[, k]) |
检索与query最相似的k个文档(余弦相似性)。 |
similarity_search_with_score(*args, **kwargs) |
检索相似文档,同时返回相似度分数(未归一化的余弦距离,越小越相似) |
similarity_search_with_relevance_scores(query) |
检索相似文档,同时返回相似度分数(归一化的余弦相似性,越接近1越相似) |
similarity_search_by_vector(embedding[, k]) |
检索与嵌入向量最相似的k个文档(余弦相似性)。 |
max_marginal_relevance_search(query[, k, ...]) |
使用MMR(最大边际相关性搜索 )检索相似文档 |
max_marginal_relevance_search_by_vector(...) |
使用MMR(最大边际相关性搜索 )检索相似文档 |
delete([ids]) |
根据向量ID或其他条件进行删除操作。 |
- MMR:相似性搜索(Similarity Search)只考虑文档与查询的相似度,而MMR除此之外还考虑所选文档之间的差异性,这样可以确保搜索结果不仅与查询相关,还具有一定的多样性。
- 异步支持:除了as_retriever之外,其它所有方法都有对应的异步实现,主需要在方法名前面加一个
a,表示async。
对于langchain_core.vectorstores,你可以直接对其进行检索,也可以使用as_retriever方法将其转换为检索器(VectorStoreRetriever)后再进行检索,二者的区别是:
- 直接检索:
- 需要手动编写代码来执行检索操作。
- 需要了解vectorstores的API和方法,以正确地执行检索操作。
- 需要处理返回的结果并进行后续的处理和分析。
- 检索器检索:
- 检索器通常提供了更简化和高级的接口,使得执行检索操作更加方便和易于使用。
- 检索器可能提供了额外的功能,如结果排序、过滤、分页等,以便更好地处理和展示检索结果。
2.2 chroma
参考《Chroma》
chroma是一个免费开源,可以在本地机器上运行的向量存储库,下面进行演示。
2.2.1 基本示例
# pip install chromadb
- 加载文档, 分割成chunks, 嵌入每个chunks并将结果存储到vector store.
from langchain.document_loaders import TextLoader
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
db = Chroma.from_documents(documents, embedding_function)
- 相似性搜索(文本)
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
- 相似性搜索(向量)
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
可见结果是一样的。
- 相似性搜索(余弦距离)
docs = db.similarity_search_with_score(query)
docs[0]
(Document(page_content='Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', metadata={'source': '../../../state_of_the_union.txt'}),
1.1972057819366455)
- 检索器搜索
检索器提供了更多的灵活性和定制化选项,可以根据具体需求进行调整。
retriever = db.as_retriever(search_type="mmr")
retriever.get_relevant_documents(query)[0]
Document(page_content='Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', metadata={'source': '../../../state_of_the_union.txt'})
2.2.2 保存到磁盘
如果您想保存到磁盘,只需在初始化 Chroma 客户端时传递您想要保存数据的目录即可。要注意的是,多个客户端可能会干扰彼此的工作,所以在任何时间,每个路径应该仅运行一个客户端。
# save to disk
db2 = Chroma.from_documents(docs, embedding_function, persist_directory="./chroma_db")
docs = db2.similarity_search(query)
# load from disk
db3 = Chroma(persist_directory="./chroma_db", embedding_function=embedding_function)
docs = db3.similarity_search(query)
print(docs[0].page_content)
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
2.2.3 将 Chroma 客户端传递到 Langchain
您还可以创建一个Chroma Client并将其传递给LangChain,这样做有很多优点:
-
更方便的访问底层数据库:Chroma客户端提供了一个简单的接口,您可以很方便的进行添加、获取、更新、删除文档,以及执行相似度搜索等操作,而无需直接与数据库进行交互。
-
更高的开发效率:Chroma客户端封装了与底层数据库的交互细节,您可以使用Chroma客户端提供的方法来处理文档嵌入、相似度搜索等任务,而无需编写复杂的数据库查询语句,使您能够更专注于应用程序的开发。
-
简化的集成:您可以将Chroma客户端作为Langchain的输入,将底层数据库与Langchain或其他应用程序集成得更加紧密,从而实现更高级的文本处理和分析功能。
-
数据持久化和共享:Chroma客户端支持数据的持久化存储,使您可以将文档和嵌入结果保存在数据库中,并在不同的应用程序间进行共享和重用。
import chromadb
persistent_client = chromadb.PersistentClient()
collection = persistent_client.get_or_create_collection("collection_name")
collection.add(ids=["1", "2", "3"], documents=["a", "b", "c"])
langchain_chroma = Chroma(
client=persistent_client,
collection_name="collection_name",
embedding_function=embedding_function,
)
print("There are", langchain_chroma._collection.count(), "in the collection")
- 使用
chromadb.PersistentClient()创建一个PersistentClient对象,这是Chroma的持久化客户端。 - 使用
get_or_create_collection方法获取或创建一个名为"collection_name"的集合。接下来,我们使用add方法向集合中添加了一些文档和对应的ID。 - 创建Chroma对象,参数为持久化客户端、集合名称以及嵌入函数(embedding_function),后者用于将文档嵌入为向量表示。
- 最后,我们打印了集合中的文档数量,以验证集合中的文档是否正确添加。
最终输出显示为:
Add of existing embedding ID: 1
Add of existing embedding ID: 2
Add of existing embedding ID: 3
Add of existing embedding ID: 1
Add of existing embedding ID: 2
Add of existing embedding ID: 3
Add of existing embedding ID: 1
Insert of existing embedding ID: 1
Add of existing embedding ID: 2
Insert of existing embedding ID: 2
Add of existing embedding ID: 3
Insert of existing embedding ID: 3
There are 3 in the collection
你也可以使用OpenAI Embeddings来替代上面的embedding_function(SentenceTransformerEmbeddings)。
from getpass import getpass
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
new_client = chromadb.EphemeralClient()
openai_lc_client = Chroma.from_documents(
docs, embeddings, client=new_client, collection_name="openai_collection"
)
query = "What did the president say about Ketanji Brown Jackson"
docs = openai_lc_client.similarity_search(query)
print(docs[0].page_content)
2.2.4 更新和删除、过滤文档
在构建实际应用程序时,您不仅需要添加数据,还需要更新和删除数据。在Chroma中,用户可以使用 ids来简化这个过程。ids 可以是文件名,也可以是 filename_paragraphNumber 等组合。下面是一个基础示例:
# 创建了一个简单的ID列表,用于标识每个文档。
ids = [str(i) for i in range(1, len(docs) + 1)]
# 创建Chroma对象example_db
example_db = Chroma.from_documents(docs, embedding_function, ids=ids)
docs = example_db.similarity_search(query)
# 打印第一个文档的元数据,然后更新了第一个文档的元数据
print(docs[0].metadata)
docs[0].metadata = {
"source": "../../modules/state_of_the_union.txt",
"new_value": "hello world",
}
example_db.update_document(ids[0], docs[0])
print(example_db._collection.get(ids=[ids[0]]))
# 删除最后一个文档
print("count before", example_db._collection.count())
example_db._collection.delete(ids=[ids[-1]])
print("count after", example_db._collection.count())
{'source': '../../../state_of_the_union.txt'}
{'ids': ['1'], 'embeddings': None, 'metadatas': [{'new_value': 'hello world', 'source': '../../../state_of_the_union.txt'}], 'documents': ['Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.']}
count before 46
count after 45
我们还可以在Chroma集合中根据指定条件进行过滤操作。下面示例中,我们使用 get 方法执行过滤操作,使用where参数指定过滤条件。
# filter collection for updated source
example_db.get(where={
"source": "some_other_source"})
{'ids': [], 'embeddings': None, 'metadatas': [], 'documents': []}
2.2.5 使用 Docker 容器(略)
2.3 Qdrant(Async)
矢量存储通常作为需要一些 IO 操作的单独服务运行,因此它们可能会被异步调用。这会带来性能优势,因为您不必浪费时间等待外部服务的响应。另外如果您使用异步框架(例如 FastAPI),这一点也可能很重要。Qdrant向量存储库支持所有异步操作,本章节将用它来演示。
pip install qdrant-client
from langchain.vectorstores import Qdrant
- 异步创建向量存储
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
- await关键字用于等待异步操作的完成。
- "http://localhost:6333"是Qdrant服务的URL地址,指定了Qdrant向量存储的位置。
- 相似性搜索(文本)
query = "What did the president say about Ketanji Brown Jackson"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
- 相似性搜索(向量)
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
- 最大边际相关性搜索(MMR):MMR也支持异步操作。
query = "What did the president say about Ketanji Brown Jackson"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{
i + 1}.", doc.page_content, "\n")
1. Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
2. We can’t change how divided we’ve been. But we can change how we move forward—on COVID-19 and other issues we must face together.
I recently visited the New York City Police Department days after the funerals of Officer Wilbert Mora and his partner, Officer Jason Rivera.
They were responding to a 9-1-1 call when a man shot and killed them with a stolen gun.
Officer Mora was 27 years old.
Officer Rivera was 22.
Both Dominican Americans who’d grown up on the same streets they later chose to patrol as police officers.
I spoke with their families and told them that we are forever in debt for their sacrifice, and we will carry on their mission to restore the trust and safety every community deserves.
I’ve worked on these issues a long time.
I know what works: Investing in crime prevention and community police officers who’ll walk the beat, who’ll know the neighborhood, and who can restore trust and safety.
2.3 Faiss (有空再补)
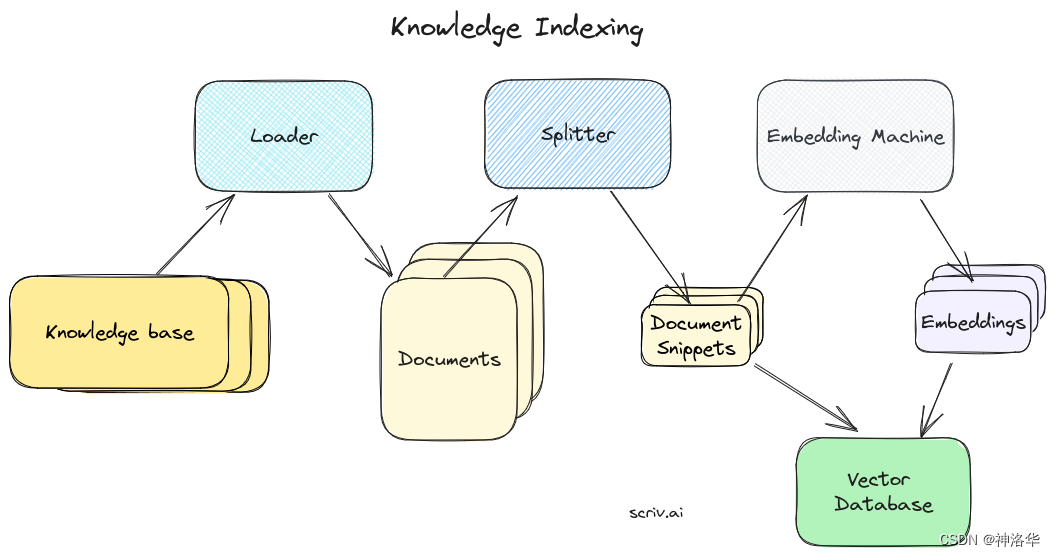
三、Indexing
本章讲解使用 LangChain 索引 API( indexing API.) 的基本索引工作流程。
LangChain indexing API是一种用于加载和同步任何文档到向量存储的API,甚至可以对相较于原始源文档经历了多个转换步骤(例如,通过文本分块)的文档进行索引,它有助于:
- 避免重新计算未更改文档的嵌入
- 避免将重复的内容写入Vector stores
- 当源文档更新或删除时自动删除旧版本(可选)
LangChain indexing API使用记录管理器(RecordManager)来跟踪文档写入向量存储的情况。索引文档时,会计算并存储每个文档的哈希值、写入时间和source id 等信息。
3.1 快速入门
3.1.1 环境配置
本章节示例中选用了百度千帆的embedding模型,关于千帆的注册和API key的配置,详见《LangChain(0.0.340)官方文档一:快速入门》2.1章节。(选千帆主要是OpenAI没额度,sentence_transformers等模型需要下载,反正只是测试用)。
# pip install qianfan==0.2.2
# pip install chroma==0.4.19
import os
import qianfan
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
qianfan.qianfan_ak=os.environ['QIANFAN_AK']
qianfan.qianfan_sk=os.environ['QIANFAN_SK']
3.1.2 初始化vector store和record_manager
from langchain.embeddings import QianfanEmbeddingsEndpoint
from langchain.indexes import SQLRecordManager, index
from langchain.schema import Document
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
embedding =QianfanEmbeddingsEndpoint()
vectorstore = Chroma(collection_name="test_index", embedding_function=embedding)
collection_name = "test_index"
namespace = f"chroma/{
collection_name}"
record_manager = SQLRecordManager(namespace, db_url="sqlite:///record_manager_cache.sql")
record_manager.create_schema()
初始化记录管理器时:
- 指定集合名称和命名空间。建议命名空间同时考虑所选的vector store和集合空间名,比如“redis/my_docs”、“chromadb/my_docs”或“postgres/my_docs”。
- 初始化
SQLRecordManager对象作为记录管理器。SQLRecordManager使用SQL数据库来存储文档的索引信息,包括文档的ID、哈希值、索引时间和元数据等``` db_url的值是"sqlite:///record_manager_cache.sql"。这表示我们将使用SQLite数据库,并将记录存储在名为record_manager_cache.sql的SQLite数据库文件中。- 使用SQLRecordManager时,需要在数据库中创建一个表来存储文档的索引、元数据等信息。
create_schema()方法会根据记录管理器的配置,自动创建此数据库表结构。
3.1.3 创建文档
- 创建两个Document对象,表示要索引的文档
- 定义一个辅助函数
_clear(),用于清除之前的索引内容。
def _clear():
"""Hacky helper method to clear content. See the `full` mode section to to understand why it works."""
index([], record_manager, vectorstore, cleanup="full", source_id_key="source")
doc1 = Document(
page_content="kitty kitty kitty kitty kitty", metadata={
"source": "kitty.txt"}
)
doc2 = Document(page_content="doggy doggy the doggy", metadata={
"source": "doggy.txt"})
# 创建一个分割器,指定分割字符为“t”,并在文本中保留分割符。每个chunks大小为12个字符,重叠部分为两个字符。
new_docs = CharacterTextSplitter(
separator="t", keep_separator=True, chunk_size=12, chunk_overlap=2
).split_documents([doc1, doc2])
new_docs
[Document(page_content='kitty kit', metadata={'source': 'kitty.txt'}),
Document(page_content='tty kitty ki', metadata={'source': 'kitty.txt'}),
Document(page_content='tty kitty', metadata={'source': 'kitty.txt'}),
Document(page_content='doggy doggy', metadata={'source': 'doggy.txt'}),
Document(page_content='the doggy', metadata={'source': 'doggy.txt'})]
最后,我们将调用index函数将文档添加到向量存储中,由于涉及到不同的删除模式,这一步将在下一章讲解。
3.2 删除模式
当你更新向量存储库时,您可能希望删除与正在编制索引的新文档相同来源的现有文档。LangChain indexing API可实现此功能,并提供了三种删除模式——None,Incremental,Full,其区别为:
None:不执行任何自动清理操作,需要用户手动清理Incremental: 自动执行增量清理操作,即在每次写入新文档前执行清理操作。具体来说:- 如果源文档或派生文档的内容发生了更改,则删除旧前版本的内容
- 如果源文件被删除,则也会删除与此源文件相关的内容。
Full:自动执行完全清理操作。机制和Incremental模式一样,只不过清理操作是在写入新文档之后执行的。 Full模式的目的,是在所有批次索引之后,进行一次全面的清理操作。
当索引新文档时,API会检查新文档的源ID是否存在于记录管理器中。如果源ID不存在于记录管理器中,表示该源文档已被删除.。即使源文档已被删除,langchain也能正确地从vector store中删除相应的内容,确保向量存储中的索引始终反映最新的文档状态,避免了无效或过时的索引存在。
另外,metadata 属性包含一个名为 source 的字段,其指向与给定文档相关的最终出处。例如,假设一些文档是某个父文档分割之后的chunks ,那么这些文档的source应该引用同一个父文档。
通常情况下,应该始终指定 source 的字段,除非你从不打算使用incremental 模式或full模式的自动删除功能,或者由于某种原因无法正确指定 source 字段。
3.2.1 None模式
使用index函数时,需指定要索引的文档列表、记录管理器、vector store、删除模式和源ID的键。本节使用None模式,而之前定义的_clear()函数是full模式,用于执行手动清除。
_clear()
index(
[doc1, doc1, doc1, doc1, doc1],
record_manager,
vectorstore,
cleanup=None,
source_id_key="source",
)
{'num_added': 1, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
_clear()
index([doc1, doc2], record_manager, vectorstore, cleanup=None, source_id_key="source")
{'num_added': 2, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
第二次执行将自动跳过所有内容(相同文件不会重复被索引):
index([doc1, doc2], record_manager, vectorstore, cleanup=None, source_id_key="source")
{'num_added': 0, 'num_updated': 0, 'num_skipped': 2, 'num_deleted': 0}
3.2.2 incremental模式
_clear()
index(
new_docs,
record_manager,
vectorstore,
cleanup="incremental",
source_id_key="source",
)
{'num_added': 5, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
如果我们改变源文档doggy.txt的内容,那么旧的文档将被删除
changed_doggy_docs = [
Document(page_content="woof woof", metadata={
"source": "doggy.txt"}),
Document(page_content="woof woof woof", metadata={
"source": "doggy.txt"}),
]
index(
changed_doggy_docs,
record_manager,
vectorstore,
cleanup="incremental",
source_id_key="source",
)
{'num_added': 0, 'num_updated': 0, 'num_skipped': 2, 'num_deleted': 2}
vectorstore.similarity_search("dog", k=30)
[Document(page_content='woof woof woof', metadata={'source': 'doggy.txt'}),
Document(page_content='woof woof', metadata={'source': 'doggy.txt'}),
Document(page_content='kitty kit', metadata={'source': 'kitty.txt'}),
Document(page_content='tty kitty', metadata={'source': 'kitty.txt'}),
Document(page_content='tty kitty ki', metadata={'source': 'kitty.txt'})]
3.2.3 full模式
在Full模式下,用户应该将希望被索引的所有文档传递给索引函数。如果在vector store中存在未传递给索引函数的文档,它们都将被删除!这是为了确保vector store中的索引与用户提供的完整内容一致。
_clear()
all_docs = [doc1, doc2]
index(all_docs, record_manager, vectorstore, cleanup="full", source_id_key="source")
{'num_added': 2, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
假设有人删除了第一个文档(源文档):
del all_docs[0]
all_docs
[Document(page_content='doggy', metadata={'source': 'doggy.txt'})]
再次执行index函数,会清理已删除的内容。
index(all_docs, record_manager, vectorstore, cleanup="full", source_id_key="source")
{'num_added': 0, 'num_updated': 0, 'num_skipped': 1, 'num_deleted': 1}
3.3 使用loaders进行文档索引
索引可以接受文档的可迭代对象,也可以接受任何文档加载器,但是加载过程必须正确设置source keys。
from langchain.document_loaders.base import BaseLoader
class MyCustomLoader(BaseLoader):
def lazy_load(self):
text_splitter = CharacterTextSplitter(
separator="t", keep_separator=True, chunk_size=12, chunk_overlap=2
)
docs = [
Document(page_content="woof woof", metadata={
"source": "doggy.txt"}),
Document(page_content="woof woof woof", metadata={
"source": "doggy.txt"}),
]
yield from text_splitter.split_documents(docs)
def load(self):
return list(self.lazy_load())
_clear()
loader = MyCustomLoader()
loader.load()
[Document(page_content='woof woof', metadata={'source': 'doggy.txt'}),
Document(page_content='woof woof woof', metadata={'source': 'doggy.txt'})]
使用此加载器进行文档索引:
index(loader, record_manager, vectorstore, cleanup="full", source_id_key="source")
{'num_added': 2, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
vectorstore.similarity_search("dog", k=30)
[Document(page_content='woof woof', metadata={'source': 'doggy.txt'}),
Document(page_content='woof woof woof', metadata={'source': 'doggy.txt'})]