文章目录
LangChain 提供了几个类和函数来帮助构建和使用提示:
- Prompt templates:提示模板,可参数化的模型输入
- Example selectors:如果你有大量示例,示例选择器可以动态选择要包含在提示中的示例
下面一一进行介绍。
一、Prompt Engineering
1.1 Prompt Engineering简介
在迁移学习之前,传统的机器学习中我们依赖不同的模型来执行不同的任务,比如,我们需要单独的模型进行分类、命名实体识别 (NER)、问答 (QA) 和许多其他任务:

随着transformers和迁移学习的引入,语言模型只需要在网络末端(头部)进行一些微调,就可以使语言模型适应不同的任务:

时至今日,即使是这种方法也已经过时了。大型语言模型 (LLM)作为基座模型以支持多元应用的能力,使得我们只需要为不同的任务构建不同的提示,通过 Prompt 链路组合来实现业务逻辑,连更改最后几个模型层进行微调都不需要了,这就是Prompt Engineering。

在传统的 AI 开发中,我们首先需要将非常复杂的业务逻辑依次拆解,对于每一个子业务构造训练数据与验证数据,对于每一个子业务训练优化模型,最后形成完整的模型链路来解决整个业务逻辑。然而,在大模型开发中,用一个通用大模型 + 若干业务 Prompt 就可以解决任务,从而将传统的模型训练调优转变成了更简单、轻松、低成本的 Prompt 设计调优。
同时,在评估思路上,大模型开发与传统 AI 开发也有了质的差异。传统 AI 开发需要首先构造训练集、测试集、验证集,通过在训练集上训练模型、在测试集上调优模型、在验证集上最终验证模型效果来实现性能的评估。然而,大模型开发更敏捷、灵活,我们一般不会在初期显式地确定训练集、验证集,由于不再需要训练子模型,我们不再构造训练集,而是直接从实际业务需求出发构造小批量验证集,设计合理 Prompt 来满足验证集效果。然后,我们将不断从业务逻辑中收集当下 Prompt 的 Bad Case,并将 Bad Case 加入到验证集中,针对性优化 Prompt,最后实现较好的泛化效果。
1.2 prompt组成部分
在深入研究 Langchain 的 PromptTemplate 之前,我们需要更好地了解一下提示。提示通常由多个部分组成:

并非所有提示都包含这些组件,但一个好的提示通常是由多个部分组成,让我们更详细的了解它们:
Instructions:指令,告诉模型要做什么,如何使用外部信息(如果提供),如何处理查询,以及如何构造输出等。External information or context(s):外部信息或上下文,一般充当模型的额外知识来源。此部分可以手动插入到提示中,比如通过向量数据库检索(RAG,retrieval augmentation generating),或通过其他方式(API、计算等)。User input:用户输入Output indicator:输出指示器标记要生成的文本的开头
每个组件通常按此顺序放置在提示中,比如:
prompt = """Answer the question based on the context below. If the
question cannot be answered using the information provided answer
with "I don't know".
Context: Large Language Models (LLMs) are the latest models used in NLP.
Their superior performance over smaller models has made them incredibly
useful for developers building NLP enabled applications. These models
can be accessed via Hugging Face's `transformers` library, via OpenAI
using the `openai` library, and via Cohere using the `cohere` library.
Question: Which libraries and model providers offer LLMs?
Answer: """
下面主要讲解如何使用langchain库中的提示模板构建prompt,至于提示工程中prompt的编写原则等问题,以及复杂一点的示例,可以参考《LangChain:LLM应用程序开发(上)——Models、Prompt、Parsers、Memory、Chains》、 《ChatGLM 大模型应用构建 & Prompt 工程》、《吴恩达&OpenAI最新课程:prompt-engineering-for-developers读书笔记》。
二、 Prompt templates
为了增强提示的复用性,我们一般不太会对context和User input进行硬编码,而是通过一个模板来输入它们。LangChain提供了用于生成语言模型提示的预定义模板。这些模板包括指令、少量示例以及适用于特定任务的具体背景和问题。
本质上有两种不同的提示模板可用 -——字符串提示模板PromptTemplate和聊天提示模板ChatPromptTemplate。前者提供字符串格式的简单提示,而后者生成更结构化的提示以与聊天 API 一起使用。
2.1 langchain_core.prompts
在 langchain_core.prompts文档中有介绍,其Class hierarchy为:
BasePromptTemplate --> PipelinePromptTemplate
StringPromptTemplate --> PromptTemplate
FewShotPromptTemplate
FewShotPromptWithTemplates
BaseChatPromptTemplate --> AutoGPTPrompt
ChatPromptTemplate --> AgentScratchPadChatPromptTemplate
BaseMessagePromptTemplate --> MessagesPlaceholder
BaseStringMessagePromptTemplate --> ChatMessagePromptTemplate
HumanMessagePromptTemplate
AIMessagePromptTemplate
SystemMessagePromptTemplate
先看一下BasePromptTemplate,它是所有prompt templates的基类,用于生成特定格式的提示。该类继承自RunnableSerializable类(泛型类,泛型参数是Dict和PromptValue)和ABC类(Abstract Base Class,抽象基类),包含以下参数:
| 参数 | 类型 | 必填 | 描述 |
|---|---|---|---|
input_types |
Dict[str, Any] | 可选 | 期望的提示模板变量类型的字典。如果未提供,则假定所有变量均为字符串。 |
input_variables |
List[str] | 必选 | 期望的提示模板变量的名称列表。 |
output_parser |
Optional[lBaseOutputParser] = None | 可选 | 用于解析调用此格式化提示的LLM输出的方法。 |
partial_variables |
Mapping[str, Union[str, Callable[[], str]]] | 可选 | 字典映射,包含部分变量的名称、类型或生成值的回调函数。 |
该类还包含以下方法:
-
异步方法:
类中定义了多个异步方法,如abatch、ainvoke、astream等,用于异步执行任务。这些方法提供了默认实现,但可以在子类中进行覆盖以实现更高效的批处理或异步执行。 -
配置相关的方法:
config_schema方法返回一个 Pydantic 模型,用于验证配置。configurable_fields方法返回一个可配置字段的序列化对象。
-
输入输出相关的方法:
get_input_schema和get_output_schema方法返回 Pydantic 模型,用于验证输入和输出。invoke方法用于将单个输入转换为输出。
-
流式处理相关方法:
astream_log方法用于流式处理运行输出,包括内部运行的日志等信息。astream方法是astream_log方法的默认实现。
-
其他方法:
- 包括一系列用于处理配置、模型序列化等的方法,如
lc_id、json、dict等。
- 包括一系列用于处理配置、模型序列化等的方法,如
-
属性:
- 包括
InputType、OutputType、config_specs等属性,用于获取输入类型、输出类型和配置规范。
- 包括
-
类方法:
- 包括用于解析对象、生成 JSON 表示、更新引用等类方法。
总体而言,该类是一个通用的 Prompt 模板类,提供了一系列用于处理配置、输入输出、异步执行等功能的方法。如果需要使用该模板,可以通过继承该类并实现必要的方法来定制特定的 Prompt 行为。
BaseMessagePromptTemplate继承自Serializable和ABC(Abstract Base Class),它是消息提示模板的基类,用于创建新模型并验证输入数据。
-
类方法
construct:创建一个新模型,通过解析和验证关键字参数中的输入数据。如果输入数据无法解析为有效模型,则引发ValidationError。参数有_fields_set(可选的字段集合)和**values(其他数值),返回新的模型实例。 -
类方法
copy:复制模型,可选择包含、排除、更改哪些字段,返回新的模型实例。 -
类方法
dict:生成模型的字典表示,可选择包含或排除特定字段。 -
抽象方法
format_messages:从关键字参数中格式化消息,应返回BaseMessage的列表。- 参数:
kwargs,用于格式化的关键字参数。 - 返回:
BaseMessage的列表。
- 参数:
-
其他类方法和属性:略
2.2 PromptTemplate
2.2.1 简介
使用PromptTemplate可以为字符串提示创建模板。默认情况下,PromptTemplate使用Python的str.format语法进行模板化。
Python f-string template:
from langchain.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
'Tell me a funny joke about chickens.'
该模板支持任意数量的变量,包括无变量:
from langchain.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke")
prompt_template.format()
'Tell me a joke'
PromptTemplate 默认使用 Python f-string 作为其模板格式,但目前也支持 jinja2格式。通过 template_format 参数可指定 jinja2 (参考《Template formats》)。
jinja2 template:
from langchain.prompts import PromptTemplate
jinja2_template = "Tell me a {
{ adjective }} joke about {
{ content }}"
prompt = PromptTemplate.from_template(jinja2_template, template_format="jinja2")
prompt.format(adjective="funny", content="chickens")
# Output: Tell me a funny joke about chickens.
2.2.2 ICEL
PromptTemplate 和 ChatPromptTemplate 实现了Runnable接口,这是LangChain表达式语言(LCEL)的基本构建块。这意味着它们支持invoke、ainvoke、stream、astream、batch、abatch、astream_log等调用。
PromptTemplate 接受一个字典(prompt变量)并返回一个StringPromptValue。ChatPromptTemplate 接受一个字典并返回一个 ChatPromptValue,这些value对象可以转换成不同的格式,为后续使用和处理提供了便利。
根据StringPromptValue文档可知:StringPromptValue类继承自基类PromptValue,表示一个字符串prompt的值,有以下方法:
__init__方法:用于根据关键字参数构建一个StringPromptValue实例。需要一个必填的text参数,表示prompt的文本。还有可选的type参数,默认为’StringPromptValue’,表示值的类型。如果输入数据不合法会抛出ValidationError。copy方法:复制模型的方法,可以选择包含、排除或更新某些字段。deep=True时为深拷贝。dict方法:将模型转换为字典的方法,可以选择包含或排除某些字段。to_messages方法:将prompt的值转换为消息列表并返回。to_string方法:将prompt的值转换为字符串并返回。
prompt_val = prompt_template.invoke({
"adjective": "funny", "content": "chickens"})
prompt_val # 输出: StringPromptValue(text='Tell me a joke')
prompt_val.to_string() # 输出:'Tell me a joke'
prompt_val.to_messages() # 输出:[HumanMessage(content='Tell me a joke')]
prompt_val.copy(update={
"text": "Hello! How are you?"}) # 输出:StringPromptValue(text='Hello! How are you?')
prompt.dict() # 输出:{'text': 'Tell me a funny joke about chickens.'}
prompt.json() # 输出:'{"text": "Tell me a funny joke about chickens."}'
prompt.json().to_json()
{
'lc': 1,
'type': 'constructor',
'id': ['langchain', 'prompts', 'base', 'StringPromptValue'],
'kwargs': {
'text': 'Tell me a funny joke about chickens.'}}
2.2.3 禁用输入验证
PromptTemplate会通过检查输入的变量是否与模板中定义的变量相匹配来验证模板字符串。如果存在不匹配的变量,默认情况下会引发ValueError异常。你可以通过设置validate_template=False,禁用这种验证行为,因此不再会引发错误。
template = "I am learning langchain because {reason}."
prompt_template = PromptTemplate(template=template,
input_variables=["reason", "foo"]) # ValueError due to extra variables
prompt_template = PromptTemplate(template=template,
input_variables=["reason", "foo"],
validate_template=False) # No error
2.3 ChatPromptTemplate
下面以百度文心一言为例进行演示。要调用文心一言 API,需要先获取文心一言调用秘钥。首先我们需要进入文心千帆服务平台,注册登录之后选择“应用接入”——“创建应用”。然后简单输入基本信息,选择默认配置,创建应用即可。
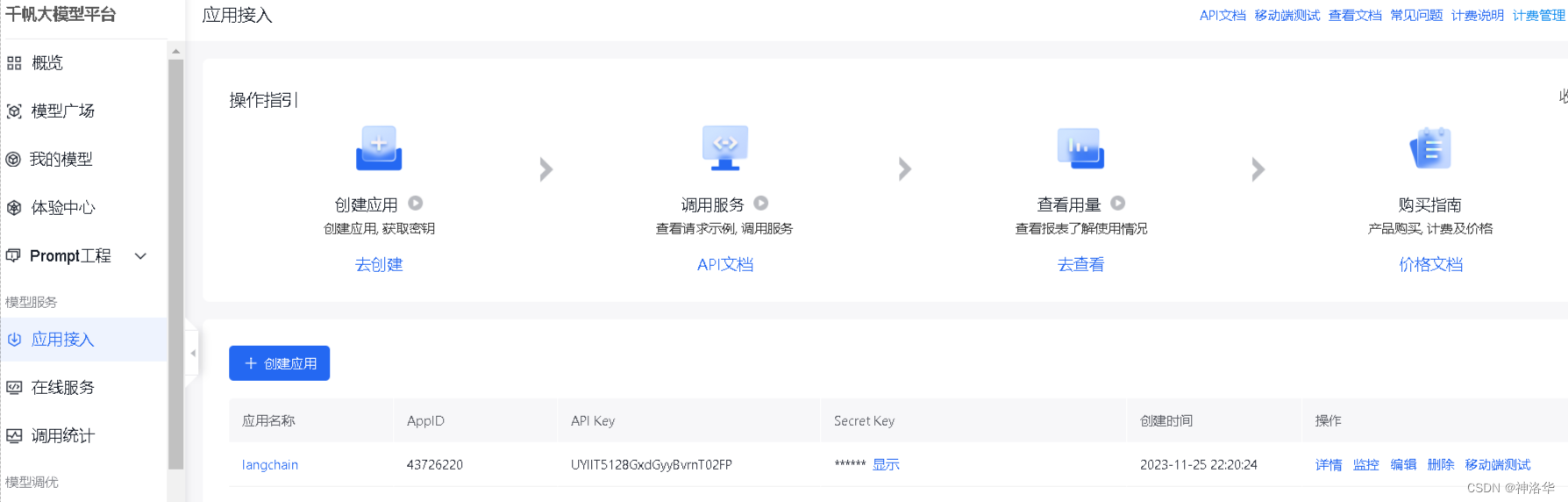
创建完成后,点击应用的“详情”即可看到此应用的 AppID,API Key,Secret Key。然后在百度智能云在线调试平台-示例代码中心快速调试接口,获取AccessToken(不解之处,详见API文档)。最后在项目文件夹下使用vim .env(Linux)或type nul > .env(Windows cmd)创建.env文件,并在其中写入:
QIANFAN_AK="xxx"
QIANFAN_SK="xxx"
access_token="xxx"
下面将这些变量配置到环境中,后续就可以自动使用了。
# 使用openai、智谱ChatGLM、百度文心需要分别安装openai,zhipuai,qianfan
import os
import openai,zhipuai,qianfan
from langchain.llms import ChatGLM
from langchain.chat_models import ChatOpenAI,QianfanChatEndpoint
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key =os.environ['OPENAI_API_KEY']
zhipuai.api_key =os.environ['ZHIPUAI_API_KEY']
qianfan.qianfan_ak=os.environ['QIANFAN_AK']
qianfan.qianfan_sk=os.environ['QIANFAN_SK']
2.3.1 使用(role, content)创建
ChatPromptTemplate是 chat models 的聊天消息列表。 每个聊天消息都与内容相关联,并具有一个称为role(角色)的额外参数。例如,在 OpenAI 聊天补全 API 中,聊天消息可以与 AI 助手、人类或系统角色相关联。创建一个聊天提示模板就像这样:
from langchain.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
messages
[SystemMessage(content='You are a helpful AI bot. Your name is Bob.'),
HumanMessage(content='Hello, how are you doing?'),
AIMessage(content="I'm doing well, thanks!"),
HumanMessage(content='What is your name?')]
2.3.2 使用MessagePromptTemplate创建
ChatPromptTemplate.from_messages接受多种消息表示方式。比如除了使用上面提到的(type, content)的2元组表示法之外,你还可以传入MessagePromptTemplate或BaseMessage的实例,这为你在构建聊天提示时提供了很大的灵活性,下面用百度千帆进行演示。
import os
import openai,qianfan
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key =os.environ['OPENAI_API_KEY']
qianfan.qianfan_ak=os.environ['QIANFAN_AK']
qianfan.qianfan_sk=os.environ['QIANFAN_SK']
- 使用MessagePromptTemplate
from langchain.chat_models import QianfanChatEndpoint
from langchain.prompts import HumanMessagePromptTemplate,SystemMessagePromptTemplate
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chat = QianfanChatEndpoint()
chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
AIMessage(content='编程是一项非常有趣和有挑战性的工作,我很羡慕你能够享受其中的乐趣。', additional_kwargs={'id': 'as-cxezsmtfga', 'object': 'chat.completion', 'created': 1701520678, 'result': '编程是一项非常有趣和有挑战性的工作,我很羡慕你能够享受其中的乐趣。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 4, 'completion_tokens': 18, 'total_tokens': 22}})
- 使用BaseMessage的实例
from langchain.schema.messages import SystemMessage
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant that re-writes the user's text to "
"sound more upbeat."
)
),
HumanMessagePromptTemplate.from_template("{text}"),
]
)
chat(chat_template.format_messages(text="i dont like eating tasty things."))
AIMessage(content='很抱歉听到您不喜欢吃美味的食物。您有其他喜欢的食物类型吗?或许我们可以找到一些其他您喜欢吃的食物,您试试看是否能够喜欢呢?', additional_kwargs={
'id': 'as-sdcbpxad11', 'object': 'chat.completion', 'created': 1701520841, 'result': '很抱歉听到您不喜欢吃美味的食物。您有其他喜欢的食物类型吗?或许我们可以找到一些其他您喜欢吃的食物,您试试看是否能够喜欢呢?', 'is_truncated': False, 'need_clear_history': False, 'usage': {
'prompt_tokens': 8, 'completion_tokens': 34, 'total_tokens': 42}})
2.3.3 自定义MessagePromptTemplate
Chat models底层实现是LLMs,但它不使用“文本输入、文本输出”API,而是使用“聊天消息”作为输入和输出的界面,即chat model基于消息(List[BaseMessage] )而不是原始文本。在langchain中,消息接口由 BaseMessage 定义,它有两个必需属性:
content:消息的内容,通常为字符串。role:消息来源(BaseMessage)的实体类别,比如:HumanMessage:来自人类/用户的BaseMessage。AIMessage:来自AI/助手的BaseMessage。SystemMessage:来自系统的BaseMessage。FunctionMessage/ ToolMessage:包含函数或工具调用输出的BaseMessage。ChatMessage:如果上述角色都不合适,可以自定义角色。- 消息也可以是 str (将自动转换为 HumanMessage )和 PromptValue(PromptTemplate的值) 。
对应的,LangChain提供了不同类型的 MessagePromptTemplate 。最常用的是 AIMessagePromptTemplate 、 SystemMessagePromptTemplate 和 HumanMessagePromptTemplate ,它们分别创建 AI 消息、系统消息和用户消息。
2.3.3.1 自定义消息角色名
如果要创建任意角色获取聊天消息,可以使用 ChatMessagePromptTemplate,它允许用户指定角色名称。
from langchain.prompts import ChatMessagePromptTemplate
prompt = "May the {subject} be with you"
chat_message_prompt = ChatMessagePromptTemplate.from_template(role="Jedi", template=prompt)
chat_message_prompt.format(subject="force")
ChatMessage(content='May the force be with you', additional_kwargs={}, role='Jedi')
2.3.3.2 自定义消息
LangChain 还提供了 MessagesPlaceholder ,它使您可以完全控制格式化期间要呈现的消息。当您不确定消息提示模板应使用什么角色或希望在格式化期间插入消息列表时,这会很有用。
from langchain.prompts import MessagesPlaceholder
human_prompt = "Summarize our conversation so far in {word_count} words."
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
chat_prompt = ChatPromptTemplate.from_messages([MessagesPlaceholder(variable_name="conversation"), human_message_template])
human_message = HumanMessage(content="What is the best way to learn programming?")
ai_message = AIMessage(content="""\
1. Choose a programming language: Decide on a programming language that you want to learn.
2. Start with the basics: Familiarize yourself with the basic programming concepts such as variables, data types and control structures.
3. Practice, practice, practice: The best way to learn programming is through hands-on experience\
""")
chat_prompt.format_prompt(conversation=[human_message, ai_message], word_count="10").to_messages()
[HumanMessage(content='What is the best way to learn programming?', additional_kwargs={}),
AIMessage(content='1. Choose a programming language: Decide on a programming language that you want to learn. \n\n2. Start with the basics: Familiarize yourself with the basic programming concepts such as variables, data types and control structures.\n\n3. Practice, practice, practice: The best way to learn programming is through hands-on experience', additional_kwargs={}),
HumanMessage(content='Summarize our conversation so far in 10 words.', additional_kwargs={})]
2.3.4 LCEL
ChatPromptTemplate 也支持LCEL, ChatPromptValue和StringPromptValue的方法也基本一致:
chat_val = chat_template.invoke({
"text": "i dont like eating tasty things."})
chat_val.to_messages()
[SystemMessage(content="You are a helpful assistant that re-writes the user's text to sound more upbeat."),
HumanMessage(content='i dont like eating tasty things.')]
chat_val.to_string()
"System: You are a helpful assistant that re-writes the user's text to sound more upbeat.\nHuman: i dont like eating tasty things."
2.3.5 chat_prompt输出的三种format方法
chat_prompt.format 方法的输出可以以三种形式获取:
- 字符串形式:调用
chat_prompt.format()或者chat_prompt.format_prompt().to_string()可以直接获取格式化后的字符串作为输出。
output = chat_prompt.format(input_language="English", output_language="French", text="I love programming.")
output
'System: You are a helpful assistant that translates English to French.\nHuman: I love programming.'
# or alternatively
output_2 = chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_string()
assert output == output_2
- 消息(Message)列表形式:调用
chat_prompt.format_prompt().to_messages()可以获取格式化输出对应的一系列消息对象列表。
chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages()
[SystemMessage(content='You are a helpful assistant that translates English to French.', additional_kwargs={}),
HumanMessage(content='I love programming.', additional_kwargs={})]
- ChatPromptValue 对象形式:直接调用 chat_prompt.format_prompt() 可以获取封装了格式化输出信息的 ChatPromptValue 对象。
chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.")
ChatPromptValue(messages=[SystemMessage(content='You are a helpful assistant that translates English to French.', additional_kwargs={}), HumanMessage(content='I love programming.', additional_kwargs={})])
三、 自定义PromptTemplate
LangChain提供了一组默认的提示模板,用于生成各种任务的提示。然而,有时默认模板可能无法满足特定需求,例如希望为语言模型创建具有特定动态指令的自定义模板。本节介绍使用PromptTemplate创建自定义提示。
为了创建自定义字符串提示模板,需要满足两个要求:
- 必须具有
input_variables属性,指明模板需要什么输入变量; - 必须定义一个
format方法,该方法接受与预期input_variables相对应的关键字参数,并返回格式化后的提示。
示例:创建一个将函数名称作为输入的自定义提示模板,该模板将格式化提示,以提供函数的源代码。首先,需要创建一个函数,该函数将根据函数名称返回函数的源代码。
import inspect
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)
inspect是python内置的模块,用于获取源代码等信息
接下来,我们将创建一个自定义提示模板,该模板接受函数名称作为输入,并格式化提示以提供函数的源代码。另外,我们从 pydantic 模块中导入 BaseModel 类和 validator 装饰器,用于创建数据模型和验证输入。
from langchain.prompts import StringPromptTemplate
from pydantic import BaseModel,validator
# 根据给定的函数名称和源代码,生成一个关于函数的英语解释
PROMPT = """\
Given the function name and source code, generate an English language explanation of the function.
Function Name: {function_name}
Source Code:
{source_code}
Explanation:
"""
class FunctionExplainerPromptTemplate(StringPromptTemplate, BaseModel):
"""一个自定义的提示模板,接受函数名称作为输入,并格式化提示模板以提供函数的源代码。"""
@validator("input_variables") # 使用 validator 装饰器定义了一个用于验证输入变量的方法。
def validate_input_variables(cls, v):
"""定义了验证输入变量的方法,确保只有一个名为 function_name 的输入变量。"""
if len(v) != 1 or "function_name" not in v:
raise ValueError("function_name 必须是唯一的输入变量。")
return v
def format(self, **kwargs) -> str:
# 获取函数的源代码
source_code = get_source_code(kwargs["function_name"])
# 生成要发送到语言模型的提示
prompt = PROMPT.format(
function_name=kwargs["function_name"].__name__, source_code=source_code
)
return prompt
def _prompt_type(self):
return "function-explainer"
-
自定义提示模板FunctionExplainerPromptTemplate,它接受函数名称作为输入变量,并通过inspect模块获取函数源代码,将源代码嵌入到提示文本中
-
提示模板继承了
StringPromptTemplate和pydantic的BaseModel,后者提供了输入验证功能 -
@validator("input_variables"):这是一个 pydantic 的 validator 装饰器。作用是对 input_variables 这个属性的值进行验证。一旦有代码给 input_variables 赋值,就会自动触发验证。 -
validate_input_variables方法:定义了对input_variables 验证逻辑,- cls 参数代表的是当前提示模板类自身,用于在类级别方法中访问类本身。这个方法被定义为类方法(使用了 @classmethod 装饰器),因此它的第一个参数是类自身而不是实例自身(self)。
- v 参数则代表的是要验证的 input_variables 属性的值。
-
format方法生成最终的提示文本,包含函数名称和源代码(对于一个函数func,func.__name__可以获取到这个函数的名称,作为一个字符串,即func.__name__=“func”) -
_prompt_type方法返回提示类型的字符串标识
现在我们可以使用这个提示模板了:
fn_explainer = FunctionExplainerPromptTemplate(input_variables=["function_name"])
# 根据"get_source_code"函数生成提示
prompt = fn_explainer.format(function_name=get_source_code)
prompt
Given the function name and source code, generate an English language explanation of the function.
Function Name: get_source_code
Source Code:
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)
Explanation:
- 创建实例 fn_explainer 时,通过构造函数参数传入了 input_variables 的值:[“function_name”],对应FunctionExplainerPromptTemplate 类方法validate_input_variables 的 v 参数。
- format 方法签名为
def format(self, **kwargs) -> str:,这里的**kwargs表示它可以接受任意多个关键字参数。这么做的好处是:- 灵活:调用者可以根据需要传入任意多个参数,没有数量和名称的限制。
- 解耦:format 内部的代码不依赖任何具体的外部参数。即使外部参数改变也不影响内部实现,因为内部只需要通过 kwargs 访问需要的参数即可。
例如,我们可能后面需要加入一个新参数 description,用于生成prompt的函数描述。使用 **kwargs 的话Caller端只要:
prompt = fn_explainer.format(
function_name=get_source_code,
description="utility function"
)
而无需改动 format 内部的代码。如果是严格的参数签名,那么任何新增参数都需要修改 format,这是很大的耦合。
四、使用特征存储库(Feature Store)的实时特征创建模板
4.1 What Is a Feature Store?
4.1.1 Feature Store简介
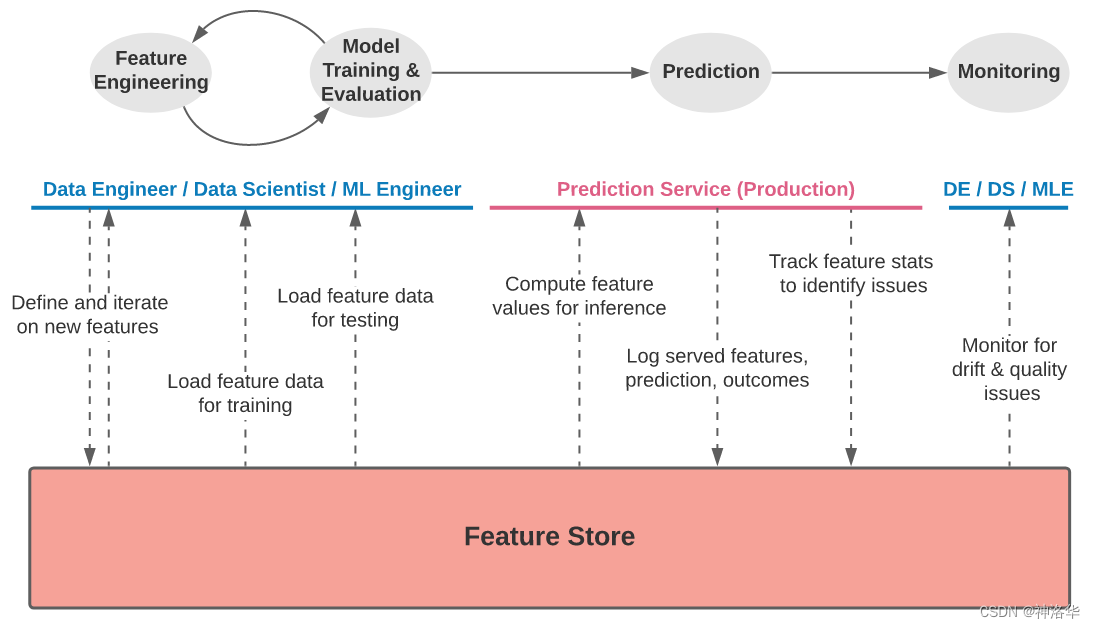
在实际将机器学习系统投入生产中,团队面临着多个数据方面的挑战,涉及到获取正确的原始数据、构建特征、将特征组合成训练数据、在生产环境中计算和提供特征,以及监控生产环境中的特征。特征存储(Feature Store)通过减少数据工程工作的重复性、加速机器学习生命周期,并促进跨团队合作,为组织带来了多方面的益处。
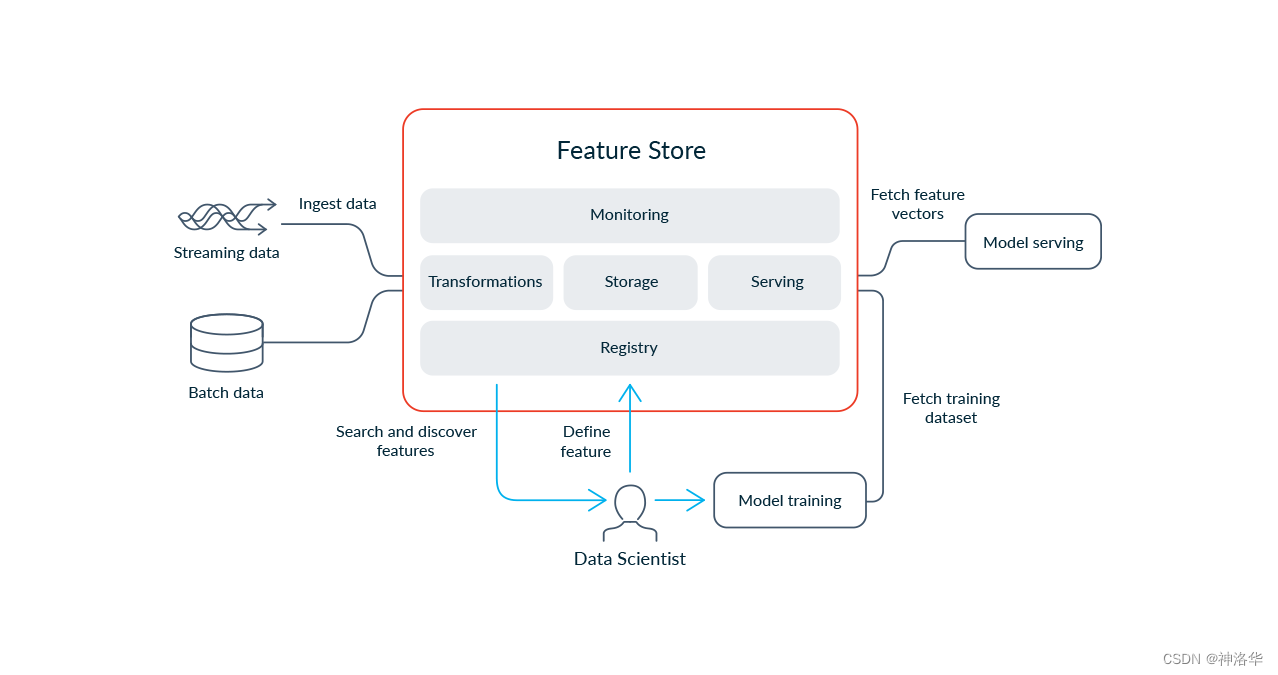
特征存储的核心作用是提供了一个高效、可靠且集中管理特征数据的平台,集中式的存储和管理特征数据。Feature stores具有以下特点:
-
集中管理特征数据:当特征注册到特征存储中后,不同团队和模型都可以共享和重用这些特征,减少了数据工程工作的重复,还可以确保数据一致性和可靠性。
-
数据版本控制和跟踪: 它允许对特征数据进行版本控制,记录数据的变化和更新历史。这对于追踪数据演变过程、复现实验以及监控模型性能变化都非常有用。
-
实现训练数据和服务数据的一致性: 用于训练模型的特征定义必须与在线服务中提供的特征完全匹配,否则将引入训练-服务偏差,这可能会导致灾难性且难以调试的模型性能问题。
-
特征实时性:在生产环境中,确保模型所使用的特征数据是最新且相关的是至关重要的。Feature Store 提供了机制来保证数据的实时性和一致性,以确保模型在推理时使用的是准确的数据。
-
特征工程: Feature Store 通常集成了数据预处理和特征工程功能,自动化特征计算、回填和日志记录。使新的机器学习项目能够使用经过筛选、准备好用于生产的特征库。
4.1.2 Feature Store的组成
现代特征存储有五个主要组成部分:转换(Transformation)、存储(Storage)、提供(Serving)、监控(Monitoring)和特征注册(Feature Registry)。

-
转换(Transformation):负责对数据进行处理,生成特征值。支持批处理、流式处理和按需处理三种方式。重用代码,避免训练服务数据偏差。
-
存储(Storage):提供离线存储用于历史数据,方便模型训练;提供在线存储用于低延迟特征服务。通常与数据湖或数据库集成。使用实体为中心的数据模型。
-
服务(Serving):通过高性能API实时提供特征数据。确保训练和服务使用一致的特征视图,避免偏差。支持通过SDK访问用于模型训练。
-
监控(Monitoring):检测数据质量、一致性等问题,确保系统运行正常。可以聚合和关联多个指标,方便定位根源。
-
注册表(Registry):中心化管理特征定义和元数据。配置和调度特征转换、存储、服务等工作。提供接口与其他系统集成。可追踪来源和依赖,支持审计。
4.2 Feast
在生产LLM应用时,个性化用户体验非常关键。特征存储的核心概念是保持数据的新鲜度和相关性,特别适用于将大型语言模型(LLM)应用于实际生产环境中。LangChain提供了一种简单的方法来将这些数据与LLM结合使用。
Feast是一个流行的开源特征存储框架。使用说明详见Feast文档。假设你已经按照Feast的README中的说明进行了设置和准备。接下来演示如何使用自定义了提示模板类,将Feast提供的特征数据注入到提示文本生成逻辑中,最终输出整合了实时特征的提示内容。
from feast import FeatureStore
# You may need to update the path depending on where you stored it
feast_repo_path = "../../../../../my_feature_repo/feature_repo/"
# 初始化连接到 Feast 特征存储(Feature Store)。
store = FeatureStore(repo_path=feast_repo_path)
FeatureStore是 Feast 提供的用于访问特征存储的客户端类,初始化时需要指定 repo_path 参数,指向预先在本地搭建的 Feast 特征库存储路径,然后就可以通过 store实例访问远程存储中的特征数据。
下面我们将建立一个自定义的FeastPromptTemplate。这个提示模板将接收一个driver id,查找他们的统计数据,并将这些统计数据格式化为一个提示信息。
请注意,这个提示模板的输入仅是driver id,因为这是用户定义的唯一部分(所有其他变量都在提示模板内部查找)。
from langchain.prompts import PromptTemplate, StringPromptTemplate
template = """Given the driver's up to date stats, write them note relaying those stats to them.
If they have a conversation rate above .5, give them a compliment. Otherwise, make a silly joke about chickens at the end to make them feel better
Here are the drivers stats:
Conversation rate: {conv_rate}
Acceptance rate: {acc_rate}
Average Daily Trips: {avg_daily_trips}
Your response:"""
prompt = PromptTemplate.from_template(template)
这段prompt意思是生成最新的驾驶员统计数据(会话率、接收率和日均行程数)并提供给他们。如果转化率(conversation rate)大于0.5,就给予赞美,否则就在信息末尾讲一个关于鸡的傻笑笑话来逗他们开心(make them feel better)。
class FeastPromptTemplate(StringPromptTemplate):
# **kwargs表示它可以接收任意多个关键字参数。
def format(self, **kwargs) -> str:
driver_id = kwargs.pop("driver_id")
feature_vector = store.get_online_features(
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_hourly_stats:avg_daily_trips",
],
entity_rows=[{
"driver_id": driver_id}],
).to_dict()
kwargs["conv_rate"] = feature_vector["conv_rate"][0]
kwargs["acc_rate"] = feature_vector["acc_rate"][0]
kwargs["avg_daily_trips"] = feature_vector["avg_daily_trips"][0]
return prompt.format(**kwargs)
driver_id = kwargs.pop("driver_id"):从kwargs字典中取出"driver_id"对应的值,赋值到driver_id变量,且pop方法会从字典中移除这个键值对,此时kwargs是一个空字典。移除driver_id是因为此参数需要单独使用,而其他conv_rate等参数会传递给后续的prompt.format(**kwargs)方法。feature_vector = store.get_online_features(...):get_online_features方法获取实时特征。其中:- feature:是需要获取的特征列表(“项目:特征名”)
- entity_rows::查询的实体行列表。
- 这一段的意思是查询驾驶员ID(
driver_id)的特征列表features 中所对应的特征数据
prompt_template = FeastPromptTemplate(input_variables=["driver_id"])
print(prompt_template.format(driver_id=1001))
Given the driver's up to date stats, write them note relaying those stats to them.
If they have a conversation rate above .5, give them a compliment. Otherwise, make a silly joke about chickens at the end to make them feel better
Here are the drivers stats:
Conversation rate: 0.4745151400566101
Acceptance rate: 0.055561766028404236
Average Daily Trips: 936
Your response:
我们现在可以创建一个利用特征存储实现个性化的链条。
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
chain = LLMChain(llm=ChatOpenAI(), prompt=prompt_template)
chain.run(1001)
"Hi there! I wanted to update you on your current stats. Your acceptance rate is 0.055561766028404236 and your average daily trips are 936. While your conversation rate is currently 0.4745151400566101, I have no doubt that with a little extra effort, you'll be able to exceed that .5 mark! Keep up the great work! And remember, even chickens can't always cross the road, but they still give it their best shot."
五、使用少量示例创建 prompt templates
本章我们将学习如何创建使用少量示例的提示模板。少量示例的提示模板可以从一组示例或者一个示例选择器对象构建而成。后者只是多了一步从示例集中创建示例选择器example selector并进行相似性搜索来过滤示例的步骤。
5.1 使用示例集(example set)
5.1.1 创建示例集
首先创建一个示例集,每个示例都是一个字典,包含输入变量的键和对应的值。
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
"""
},
{
"question": "When was the founder of craigslist born?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
"""
},
{
"question": "Who was the maternal grandfather of George Washington?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
"""
},
{
"question": "Are both the directors of Jaws and Casino Royale from the same country?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
"""
}
]
5.1.2 创建示例格式化器
定义一个格式化器(PromptTemplate 对象),将示例格式化成字符串。
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question: {question}\n{answer}")
print(example_prompt.format(**examples[0]))
Question: Who lived longer, Muhammad Ali or Alan Turing?
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
5.1.3 创建FewShotPromptTemplate
创建 FewShotPromptTemplate 对象,该对象接收示例集和示例格式化器。
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"]
)
print(prompt.format(input="Who was the father of Mary Ball Washington?"))
-
suffix参数:指定了输入问题的格式。具体来说,suffix=“Question: {input}” 表示在几份学习的示例后面,会接上一个 "Question: " 的前缀和输入变量{input}。Question: Who lived longer, Muhammad Ali or Alan Turing? Are follow up questions needed here: Yes. Follow up: How old was Muhammad Ali when he died? Intermediate answer: Muhammad Ali was 74 years old when he died. Follow up: How old was Alan Turing when he died? Intermediate answer: Alan Turing was 41 years old when he died. So the final answer is: Muhammad Ali Question: When was the founder of craigslist born? Are follow up questions needed here: Yes. Follow up: Who was the founder of craigslist? Intermediate answer: Craigslist was founded by Craig Newmark. Follow up: When was Craig Newmark born? Intermediate answer: Craig Newmark was born on December 6, 1952. So the final answer is: December 6, 1952 Question: Who was the maternal grandfather of George Washington? Are follow up questions needed here: Yes. Follow up: Who was the mother of George Washington? Intermediate answer: The mother of George Washington was Mary Ball Washington. Follow up: Who was the father of Mary Ball Washington? Intermediate answer: The father of Mary Ball Washington was Joseph Ball. So the final answer is: Joseph Ball Question: Are both the directors of Jaws and Casino Royale from the same country? Are follow up questions needed here: Yes. Follow up: Who is the director of Jaws? Intermediate Answer: The director of Jaws is Steven Spielberg. Follow up: Where is Steven Spielberg from? Intermediate Answer: The United States. Follow up: Who is the director of Casino Royale? Intermediate Answer: The director of Casino Royale is Martin Campbell. Follow up: Where is Martin Campbell from? Intermediate Answer: New Zealand. So the final answer is: No Question: Who was the father of Mary Ball Washington?
5.2 使用示例选择器(example selector)
示例选择器的功能之一是能够根据查询长度改变要包含的示例数量,示例的动态选择很重要,因为我们输入的最大长度是有限的,我们可以选择合适的样本数量以进行小样本学习,这包括平衡示例数量和提示大小、tokens数量等。示例选择器允许我们根据这些变量改变包含的示例数量。
c o n t e x t w i n d o w = i n p u t t o k e n s + o u t p u t t o k e n s context window=input tokens+output tokens contextwindow=inputtokens+outputtokens
示例选择器有很多种, 常用的有:
- SemanticSimilarityExampleSelector :根据输入和示例之间的相似性来选择k个示例。具体来说,使用一个嵌入模型来计算输入和少数示例之间的相似性,并使用向量存储(vectorstore)来执行最近邻搜索。
- LengthBasedExampleSelector:根据输入长度选择要使用的示例。对于较长的输入,它将选择较少的示例,而对于较短的输入,它将选择更多示例。
5.2.1 SemanticSimilarityExampleSelector
SemanticSimilarityExampleSelector 类继承自BaseExampleSelector和BaseModel,详情如下:
| 参数 | 类型 | 描述 |
|---|---|---|
| example_keys | Optional[List[str]] | 可选参数,用于过滤示例的键列表。 |
| input_keys | Optional[List[str]] | 可选参数,用于过滤输入的键列表。如果提供,搜索将基于输入变量而不是所有变量。 |
| k | int | 选择的示例数量,默认为4。 |
| vectorstore | langchain_core.vectorstores.VectorStore [Required] | 包含有关示例信息的VectorStore,必需。 |
| 方法 | 描述 |
|---|---|
| init(example_keys, input_keys, k, vectorstore) | 通过解析和验证关键字参数的输入数据创建新模型。如果输入数据无法解析为有效模型,则引发ValidationError。 |
| add_example(example) | 将新示例添加到vectorstore中。 |
| from_examples(examples, embeddings, vectorstore_cls, k, input_keys, **vectorstore_cls_kwargs) | 使用示例列表和嵌入创建k-shot示例选择器。根据查询相似性动态重新排列示例。 |
| select_examples(input_variables) | 基于语义相似性选择要使用的示例。返回一个包含所选示例的列表。 |
- 根据示例集创建ExampleSelector
首先我们将重用上一节中的示例集和格式化程序,但是,这次我们不会直接将这些示例馈送到 FewShotPromptTemplate 对象,而是先馈送到 ExampleSelector 对象进行选择。
Example selectors需要定义的唯一方法是 select_examples,它根据输入示例,返回选择的示例列表。你可以Select by length、Select by MMR、Select by n-gram overlap、Select by similarity。
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# 创建语义相似性示例选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 可供选择的示例列表。
examples,
# 用于生成嵌入的嵌入类,用于测量语义相似性。
OpenAIEmbeddings(),
# 用于存储嵌入并进行相似性搜索的VectorStore类。
Chroma,
# 要生成的示例数量。
k=1
)
# 选择与输入最相似的示例。
question = "Who was the father of Mary Ball Washington?"
selected_examples = example_selector.select_examples({
"question": question})
print(f"与输入最相似的示例:{
question}")
for example in selected_examples:
print("\n")
for k, v in example.items():
print(f"{
k}: {
v}") # 打印example键值对,即question,answer及其对应的值
Running Chroma using direct local API.
Using DuckDB in-memory for database. Data will be transient.
Examples most similar to the input: Who was the father of Mary Ball Washington?
question: Who was the maternal grandfather of George Washington?
answer:
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
Chroma是一个向量存储库,详细信息见Vector stores。
- 将示例选择器输入 FewShotPromptTemplate
最后,同4.1.3一样,创建一个 FewShotPromptTemplate 对象,该对象接受示例选择器和少数示例的格式化程序。
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"]
)
print(prompt.format(input="Who was the father of Mary Ball Washington?"))
Question: Who was the maternal grandfather of George Washington?
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
Question: Who was the father of Mary Ball Washington?
5.2.2 LengthBasedExampleSelector
examples = [
{
"query": "How are you?",
"answer": "I can't complain but sometimes I still do."
}, {
"query": "What time is it?",
"answer": "It's time to get a watch."
}, {
"query": "What is the meaning of life?",
"answer": "42"
}, {
"query": "What is the weather like today?",
"answer": "Cloudy with a chance of memes."
}, {
"query": "What is your favorite movie?",
"answer": "Terminator"
}, {
"query": "Who is your best friend?",
"answer": "Siri. We have spirited debates about the meaning of life."
}, {
"query": "What should I do today?",
"answer": "Stop talking to chatbots on the internet and go outside."
}
]
启用LengthBasedExampleSelector:
from langchain.prompts.example_selector import LengthBasedExampleSelector
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=50 # this sets the max length that examples should be
)
我们将max_length测量为通过将字符串拆分为空格和换行符来确定的单词数。确切的逻辑如下所示:
import re
some_text = "There are a total of 8 words here.\nPlus 6 here, totaling 14 words."
words = re.split('[\n ]', some_text)
print(words, len(words))
['There', 'are', 'a', 'total', 'of', '8', 'words', 'here.', 'Plus', '6', 'here,', 'totaling', '14', 'words.'] 14
将example_selector传递给 FewShotPromptTemplate,以创建一个新的动态提示模板:
# now create the few shot prompt template
dynamic_prompt_template = FewShotPromptTemplate(
example_selector=example_selector, # use example_selector instead of examples
example_prompt=example_prompt,
prefix=prefix,
suffix=suffix,
input_variables=["query"],
example_separator="\n"
)
现在,如果我们传递一个更短或更长的查询,我们应该看到包含的示例的数量会有所不同。
print(dynamic_prompt_template.format(query="How do birds fly?"))
The following are exerpts from conversations with an AI
assistant. The assistant is typically sarcastic and witty, producing
creative and funny responses to the users questions. Here are some
examples:
User: How are you?
AI: I can't complain but sometimes I still do.
User: What time is it?
AI: It's time to get a watch.
User: What is the meaning of life?
AI: 42
User: What is the weather like today?
AI: Cloudy with a chance of memes.
User: How do birds fly?
AI:
query = """If I am in America, and I want to call someone in another country, I'm
thinking maybe Europe, possibly western Europe like France, Germany, or the UK,
what is the best way to do that?"""
print(dynamic_prompt_template.format(query=query))
The following are exerpts from conversations with an AI
assistant. The assistant is typically sarcastic and witty, producing
creative and funny responses to the users questions. Here are some
examples:
User: How are you?
AI: I can't complain but sometimes I still do.
User: If I am in America, and I want to call someone in another country, I'm
thinking maybe Europe, possibly western Europe like France, Germany, or the UK,
what is the best way to do that?
AI:
这允许我们限制tokens的过度使用,以及超过LLM的最大上下文长度。
六、使用少量示例创建ChatPromptTemplate
few-shot prompting(少样本提示)的目的是根据输入动态选择相关的样本,并将这些样本格式化成提示给模型,使用 FewShotChatMessagePromptTemplate可以实现这一点。
6.1 使用示例集
最基本的少样本提示是使用固定的提示示例,这种方法最简单,在生产环境中也较为可靠。其基本组成部分是:
examples:包含在最终提示中的示例(字典类型)列表example_prompt:通过examples的 format_messages 方法将每个示例转换为 1 条或多条消息,比如one human message and one AI message response,或者是a human message followed by a function call message(紧跟着一个函数调用消息)。
下面进行演示。首先导入样本:
from langchain.prompts import ChatPromptTemplate,FewShotChatMessagePromptTemplate
examples = [
{
"input": "2+2", "output": "4"},
{
"input": "2+3", "output": "5"},
]
创建FewShotChatMessagePromptTemplate:
# This is a prompt template used to format each individual example.
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
print(few_shot_prompt.format())
Human: 2+2
AI: 4
Human: 2+3
AI: 5
调用创建好的FewShotChatMessagePromptTemplate:
from langchain.chat_models import ChatAnthropic
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a wondrous wizard of math."),
few_shot_prompt,
("human", "{input}"),
]
)
chain = final_prompt | ChatAnthropic(temperature=0.0)
chain.invoke({
"input": "What's the square of a triangle?"})
AIMessage(content=' Triangles do not have a "square". A square refers to a shape with 4 equal sides and 4 right angles. Triangles have 3 sides and 3 angles.\n\nThe area of a triangle can be calculated using the formula:\n\nA = 1/2 * b * h\n\nWhere:\n\nA is the area \nb is the base (the length of one of the sides)\nh is the height (the length from the base to the opposite vertex)\n\nSo the area depends on the specific dimensions of the triangle. There is no single "square of a triangle". The area can vary greatly depending on the base and height measurements.', additional_kwargs={}, example=False)
在构建最终推理prompt时,首先设置系统角色,然后提供少样本示例,最后传入用户的输入,让模型进行推理。final_prompt同时为模型提供上下文、示例和输入的作用,使其能够有针对性地生成响应。
6.2 使用示例选择器
有时您可能希望根据输入来限制显示哪些示例,以达到Dynamic few-shot prompting的效果。为此,您可以将 examples 替换为 example_selector ,其他组件与上面相同(即包含example_selector和example_prompt)。
首先构建向量存储(vectorstore),存储输入和输出的embeddings,然后基于向量相似性实现动态示例选择。
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
examples = [
{
"input": "2+2", "output": "4"},
{
"input": "2+3", "output": "5"},
{
"input": "2+4", "output": "6"},
{
"input": "What did the cow say to the moon?", "output": "nothing at all"},
{
"input": "Write me a poem about the moon",
"output": "One for the moon, and one for me, who are we to talk about the moon?",
},
]
to_vectorize = [" ".join(example.values()) for example in examples]
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_texts(to_vectorize, embeddings, metadatas=examples)
之后,创建example_selector。此处,我们选择前 2 个示例最相似的示例。
example_selector = SemanticSimilarityExampleSelector(
vectorstore=vectorstore,
k=2,
)
# The prompt template will load examples by passing the input do the `select_examples` method
example_selector.select_examples({
"input": "horse"})
[{'input': 'What did the cow say to the moon?', 'output': 'nothing at all'},
{'input': '2+4', 'output': '6'}]
创建FewShotChatMessagePromptTemplate:
from langchain.prompts import ChatPromptTemplate,FewShotChatMessagePromptTemplate,
# 定义few-shot prompt.
few_shot_prompt = FewShotChatMessagePromptTemplate(
# input variables选择要传递给示例选择器的值
input_variables=["input"],
example_selector=example_selector,
# 定义每个示例的格式。在这种情况下,每个示例将变成 2 条消息:
# 1 条来自人类,1 条来自 AI
example_prompt=ChatPromptTemplate.from_messages(
[("human", "{input}"), ("ai", "{output}")]
),
)
print(few_shot_prompt.format(input="What's 3+3?"))
Human: 2+3
AI: 5
Human: 2+2
AI: 4
创建最终的提示模板:
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a wondrous wizard of math."),
few_shot_prompt,
("human", "{input}"),
]
)
print(few_shot_prompt.format(input="What's 3+3?"))
Human: 2+3
AI: 5
Human: 2+2
AI: 4
from langchain.chat_models import ChatAnthropic
chain = final_prompt | ChatAnthropic(temperature=0.0)
chain.invoke({
"input": "What's 3+3?"})
AIMessage(content=' 3 + 3 = 6', additional_kwargs={}, example=False)