参考:https://python.langchain.com/en/latest/use_cases/question_answering.html
LangChain旨在帮助开发人员使用语言模型构建端到端的应用程序。
它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
LangChain model 是一种抽象,表示框架中使用的不同类型的模型。LangChain 中的模型主要分为三类:
- LLM(大型语言模型)
- 聊天模型( Chat Model)
- 文本嵌入模型(Text Embedding Models)
文档问答步骤:
1.加载文档
2.创建索引
3.查询索引
文档文档包含获取大量文档,然后问问题。 LLM 模型会基于文档内容回答问题
import os
os.environ["OPENAI_API_KEY"] = ""
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
loader = TextLoader('../source_documents/xxx.txt',encoding='gbk')
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator().from_loaders([loader])
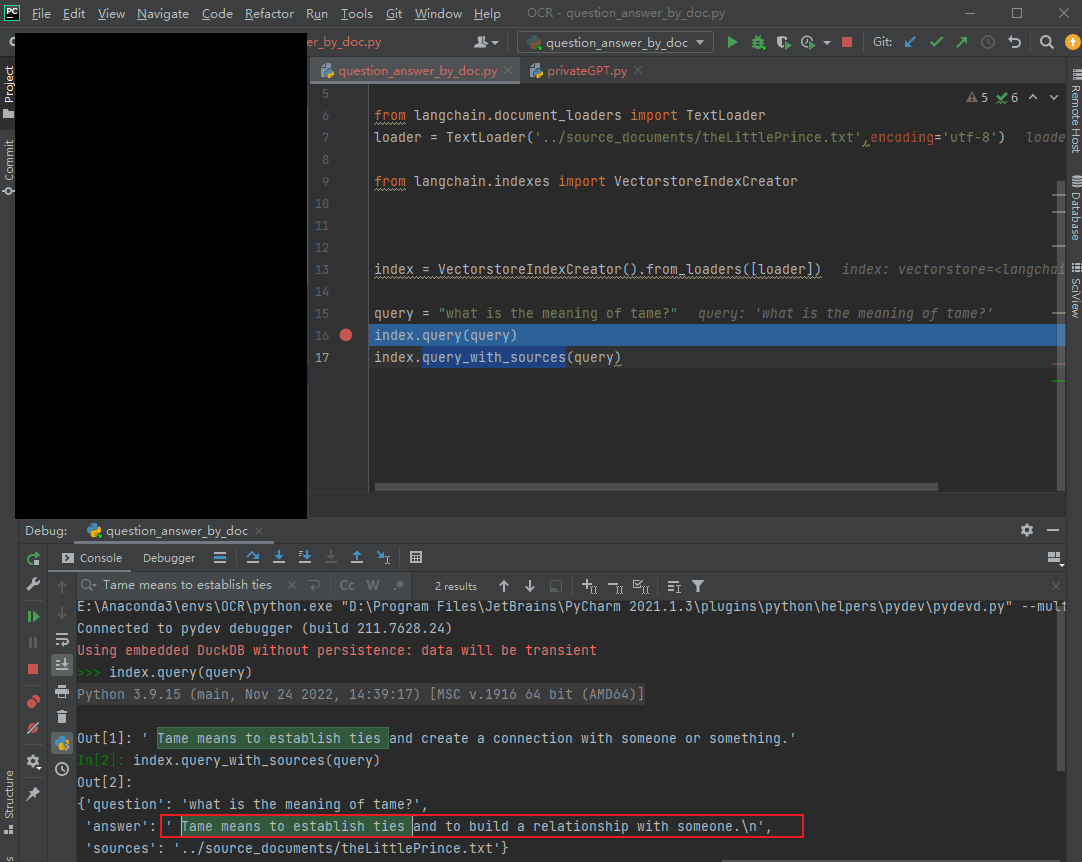
query = "xxx"
index.query(query)
index.query_with_sources(query)
# 内在逻辑
documents = loader.load()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0), chain_type="stuff", retriever=retriever, return_source_documents=True)
# qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True)
query = "What did the president say about Ketanji Brown Jackson"
# qa.run(query)
res = qa(query)
answer, docs = res['result'], res['source_documents']
报错 openai.error.InvalidRequestError: This model’s maximum context length is 4097 tokens. 更改CharacterTextSplitter的chunk_size参数,适当减小
测试效果:英文似乎更好,中文也还行