Part1 Vision Transformer
1 网络结构
ViT模型不仅适用于NLP领域,在CV领域也能取得不错的效果。
在原论文中,作者对比了三种模型,一种是ViT,即“纯”Transformer模型;一种是ResNet网络;另一种是Hybrid模型,它是将传统CNN和Transformer混合起来的模型。最终发现,当迭代次数多时,ViT模型的精度会超过混合模型。
ViT(Vision Transformer)模型架构如下:

该模型先把图片分为多个patch,每个patch大小为16*16;再将每个patch输入到Embedding层,每个patch可以得到一个向量,称为token;再在这些token的前面加一个用于分类的token;再对每个token添加用于标记位置的Position Embedding;再将这些添加了位置信息的token输入到Transformer Encoder中,通过MLPHead得到最终的分类结果。
1.1 Linear Projection of Flattened Patches(Embedding层)
直接通过一个卷积层来实现即可,输入token序列,即二维矩阵[num_token,token_dim],再对tokens进行拼接[class]token和叠加Position Embedding,其中拼接用cat操作即可,叠加直接相加即可。
经过实验,如果不使用Position Embedding,准确率会明显下降,但使用什么样的Position Embedding对准确率影响不大,位置编码的差异不重要,因此源码中默认使用的是参数更少的一维的位置编码。
最终学习到的位置编码间的相似度如下,每行与每列都各自有较高的相似度:

1.2 Transformer Encoder
该层结构和MLP结构如下:
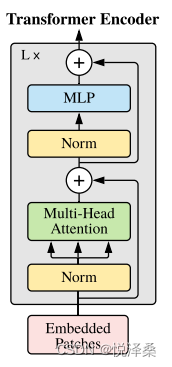
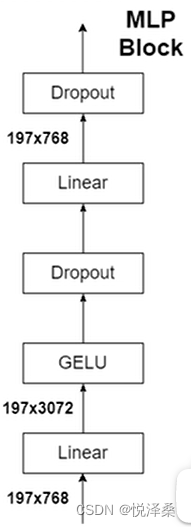
这里将Embedded Patches进行Layer Norm,再传入多头注意力,再进行Dropout和Layer Norm,最后进行MLP得到Encoder Block,然后将Encoder Block堆叠了L次。
1.3 MLPHead(最终用于分类的层结构)
当训练ImageNet21K或者更大的数据集时,它是由Linear+tanh激活函数+Linear组成的,当迁移到ImageNet1K或者自己的数据集上时,只有一个Linear。
1.4 ViT的多种类型
有三种,分别为Base,Large和Huge,规格如下:
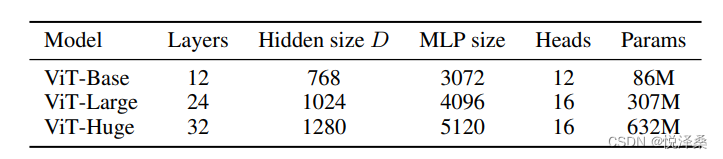
- Layers:Transform Encoder中重复堆叠Encoder Block的次数
- Hidden Size:通过Embedding层后每个token的向量长度dim
- MLP Size:MLP模块第一个全连接的节点的个数,是Hidden Size的4倍
- Heads:多头注意力中的head数量
2 基于Pytorch搭建网络
代码来自于官方实现
学习链接:ViT
代码链接:(colab)ViT
# Vision Transformer
"""
original code from rwightman:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
from functools import partial
from collections import OrderedDict
import torch
import torch.nn as nn
# 随机深度方法
def drop_path(x,drop_prob:float=0.,training:bool=False):
if drop_prob==0. or not training:
return x
keep_prob = 1-drop_prob
shape = (x.shape[0],)+(1,)*(x.ndim-1) # work with diff dim tensors
random_tensor = keep_prob+torch.rand(shape,dtype=x.dtype,device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob)*random_tensor
return output
class DropPath(nn.Module):
def __init__(self,drop_prob=None):
super(DropPath,self).__init__()
self.drop_prob = drop_prob
def forward(self,x):
return drop_path(x,self.drop_prob,self.training)
# Patch Embedding
class PatchEmbed(nn.Module):
def __init__(self,img_size=224,patch_size=16,in_c=3,embed_dim=768,norm_layer=None):
super().__init__()
img_size = (img_size,img_size)
patch_size = (patch_size,patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0]//patch_size[0],img_size[1]//patch_size[1])
self.num_patches = self.grid_size[0]*self.grid_size[1]
self.proj = nn.Conv2d(in_c,embed_dim,kernel_size=patch_size,stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B,C,H,W = x.shape
assert H==self.img_size[0] and W==self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten:[B,C,H,W]->[B,C,HW]
# transpose:[B,C,HW]->[B,HW,C]
x = self.proj(x).flatten(2).transpose(1,2)
x = self.norm(x)
return x
class Attention(nn.Module):
def __init__(self,dim,num_heads=8,qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):
super(Attention,self).__init__()
self.num_heads = num_heads
head_dim = dim//num_heads
self.scale = qk_scale or head_dim**-0.5
self.qkv = nn.Linear(dim,dim*3,bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim,dim)
self.proj_drop = nn.Dropout(proj_drop_ratio)
def forward(self, x):
B,N,C = x.shape
# 调整维度的位置,方便运算
qkv = self.qkv(x).reshape(B,N,3,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
q,k,v = qkv[0],qkv[1],qkv[2]
# 矩阵乘法
attn = ([email protected](-2,-1))*self.scale # norm
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn@v).transpose(1,2).reshape(B,N,C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Mlp(nn.Module):
def __init__(self,in_features,hidden_features=None,out_features=None,act_layer=nn.GELU,drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features,hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features,out_features)
self.drop = nn.Dropout(drop)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop_ratio=0.,
attn_drop_ratio=0.,
drop_path_ratio=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
super(Block,self).__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim,num_heads=num_heads,qkv_bias=qkv_bias,qk_scale=qk_scale,
attn_drop_ratio=attn_drop_ratio,proj_drop_ratio=drop_ratio)
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio>0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim*mlp_ratio)
self.mlp = Mlp(in_features=dim,hidden_features=mlp_hidden_dim,act_layer=act_layer,drop=drop_ratio)
def forward(self,x):
x = x+self.drop_path(self.attn(self.norm1(x)))
x = x+self.drop_path(self.mlp(self.norm2(x)))
return x
class VisionTransformer(nn.Module):
def __init__(self,img_size=224,patch_size=16,in_c=3,num_classes=1000,
embed_dim=768,depth=12,num_heads=12,mlp_ratio=4.0,qkv_bias=True,
qk_scale=None,representation_size=None,distilled=False,drop_ratio=0.,
attn_drop_ratio=0.,drop_path_ratio=0.,embed_layer=PatchEmbed,
norm_layer=None,act_layer=None):
super(VisionTransformer,self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim=embed_dim
self.num_tokens = 2 if distilled else 1
norm_layer = norm_layer or partial(nn.LayerNorm,eps=1e-6)
act_layer = act_layer or nn.GELU
self.patch_embed = embed_layer(img_size=img_size,patch_size=patch_size,in_c=in_c,embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1,1,embed_dim))
self.dist_token = nn.Parameter(torch.zeros(1,1,embed_dim)) if distilled else None
self.pos_embed = nn.Parameter(torch.zeros(1,num_patches+self.num_tokens,embed_dim))
self.pos_drop = nn.Dropout(p=drop_ratio)
dpr = [x.item() for x in torch.linspace(0,drop_path_ratio,depth)]
self.blocks = nn.Sequential(*[
Block(dim=embed_dim,num_heads=num_heads,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias,
qk_scale=qk_scale,drop_ratio=drop_ratio,attn_drop_ratio=attn_drop_ratio,
drop_path_ratio=dpr[i],norm_layer=norm_layer,act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
# Representation layer
if representation_size and not distilled:
self.has_logits = True
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
("fc",nn.Linear(embed_dim,representation_size)),
("act",nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = nn.Identity()
self.head = nn.Linear(self.num_features,num_classes) if num_classes>0 else nn.Identity()
self.head_dist = None
if distilled:
self.head_dist = nn.Linear(self.embed_dim,self.num_classes) if num_classes>0 else nn.Identity()
nn.init.trunc_normal_(self.pos_embed,std=0.02)
if self.dist_token is not None:
nn.init.trunc_normal_(self.dist_token,std=0.02)
nn.init.trunc_normal_(self.cls_token,std=0.02)
self.apply(_init_vit_weights)
def forward_features(self, x):
# [B,C,H,W]->[B,num_patches,embed_dim]
x = self.patch_embed(x) # [B,196,768]
# [1,1,768]->[B,1,768]
cls_token = self.cls_token.expand(x.shape[0],-1,-1)
if self.dist_token is None:
x = torch.cat((cls_token,x),dim=1) # [B,197,768]
else:
x = torch.cat((cls_token,self.dist_token.expand(x.shape[0],-1,-1),x),dim=1)
x = self.pos_drop(x+self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:
return self.pre_logits(x[:,0])
else:
return x[:,0], x[:,1]
def forward(self, x):
x = self.forward_features(x)
if self.head_dist is not None:
x, x_dist = self.head(x[0]),self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
return x,x_dist
else:
return (x+x_dist)/2
else:
x = self.head(x)
return x
def _init_vit_weights(m):
if isinstance(m,nn.Linear):
nn.init.trunc_normal_(m.weight,std=.01)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m,nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def vit_base_patch16_224(num_classes:int=1000):
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=None,
num_classes=num_classes)
return model
def vit_base_patch16_224_in21k(num_classes:int=21843,has_logits:bool=True):
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=768 if has_logits else None,
num_classes=num_classes)
return model
def vit_base_patch32_224(num_classes:int=1000):
model = VisionTransformer(img_size=224,
patch_size=32,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=None,
num_classes=num_classes)
return model
def vit_base_patch32_224_in21k(num_classes:int=21843,has_logits:bool=True):
model = VisionTransformer(img_size=224,
patch_size=32,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=768 if has_logits else None,
num_classes=num_classes)
return model
def vit_large_patch16_224(num_classes:int=1000):
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=1024,
depth=24,
num_heads=16,
representation_size=None,
num_classes=num_classes)
return model
def vit_large_patch16_224_in21k(num_classes:int=21843,has_logits:bool=True):
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=1024,
depth=24,
num_heads=16,
representation_size=1024 if has_logits else None,
num_classes=num_classes)
return model
def vit_large_patch32_224_in21k(num_classes:int=21843,has_logits:bool=True):
model = VisionTransformer(img_size=224,
patch_size=32,
embed_dim=1024,
depth=24,
num_heads=16,
representation_size=1024 if has_logits else None,
num_classes=num_classes)
return model
def vit_huge_patch14_224_in21k(num_classes:int=21843,has_logits:bool=True):
model = VisionTransformer(img_size=224,
patch_size=14,
embed_dim=1280,
depth=32,
num_heads=16,
representation_size=1280 if has_logits else None,
num_classes=num_classes)
return modelPart2 Swin Transformer
1 网络结构
1.1 整体框架
和ViT相比,Swin Transformer更具有层次性,随着层数加深,下采样力度不断加大,并且它使用没有重叠的窗口将feature map分离开了,对每个窗口各自进行MLP多头自注意力计算,从而大大降低计算量。
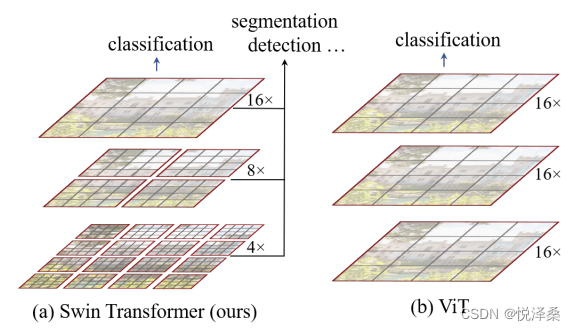
Swin Transformer的网络整体框架如下:
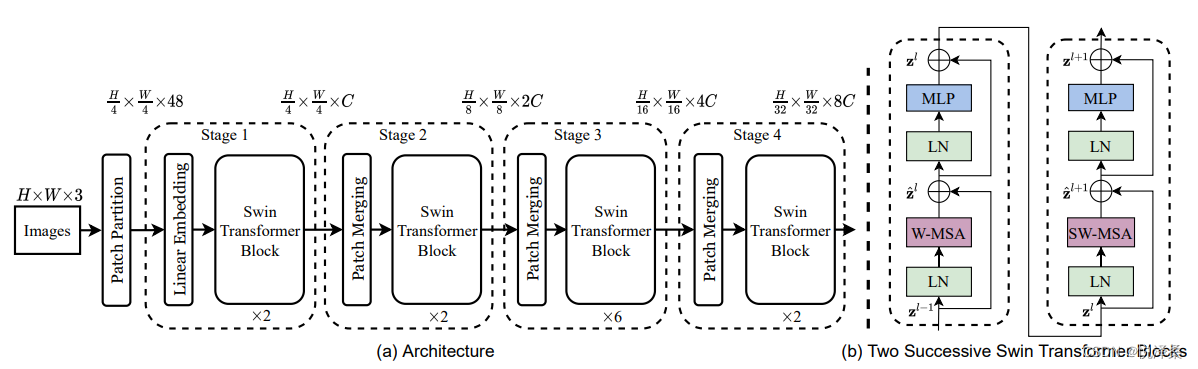
对一张三通道图片,先进行Patch Partition操作,再经过4个不同的Stage进行下采样,下采样每个Stage会增加两倍,每增加2倍,channel数也会对应扩大两倍,除了Stage1的头部是Linear Embedding之外,其他的Stage的头部都是Patch Merging。这里的Patch Partition操作是先用4*4的窗口对图像进行分割,再进行展平;Linear Embedding层起到了调整维度的作用,并且对每个channel进行了Layer Norm处理;这两种结构都可以通过搭建卷积层来实现。
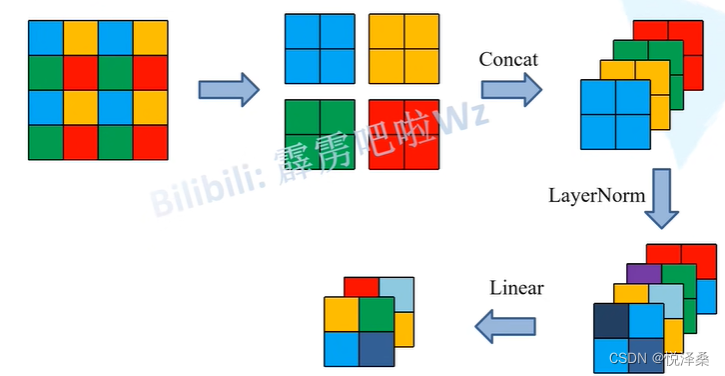
1.2 Patch Merging
Patch Merging的原理示意如下,它进行的是下采样操作,使得特征图的长宽减半,channel翻倍:
1.3 W-MSA
W-MSA即Windows Multi-head Self-Attention,相比之前的多头自注意力模块,它使用没有重叠的窗口将feature map分离开了,每个窗口各自进行多头注意力计算,达到了减少计算量的效果,但同时也会造成窗口之前无法进行信息交互,使得感受野变小。
二者的计算量如下,h,w分别代表feature map的高度和宽度,c代表feature map的深度,m代表每个窗口的大小。
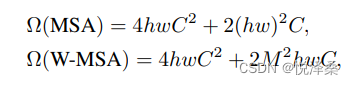
1.4 SW-MSA
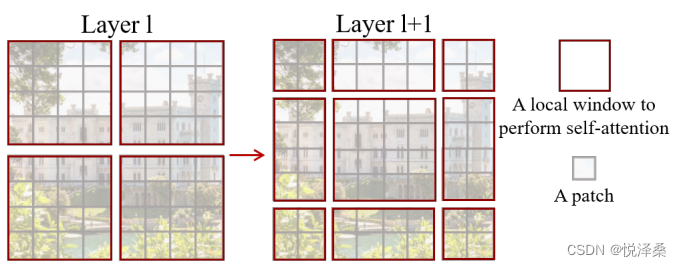
SW-MSA即Shifted Window Multi-head Self-Attention,示意图如下,在W-MSA的基础上,它进行了一定的偏移,从而实现了不同窗口之间的信息交互:
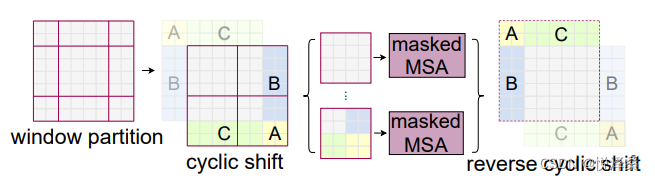
1.5 Relative Position Bias(相对位置偏移)
涉及的公式如下,这里的B就是相对位置偏移:

相对位置偏移的示意图如下:
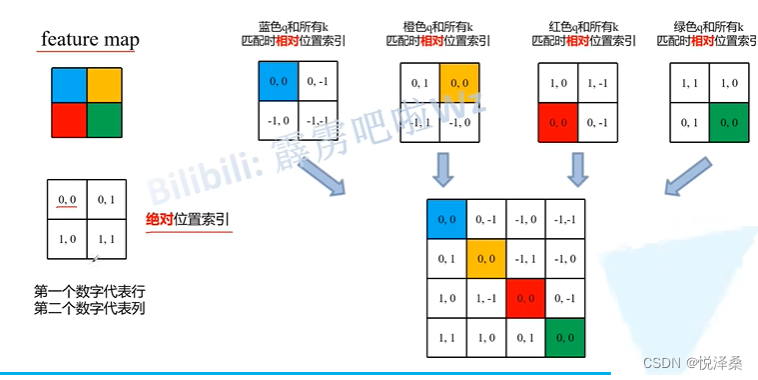




1.6 具体配置参数
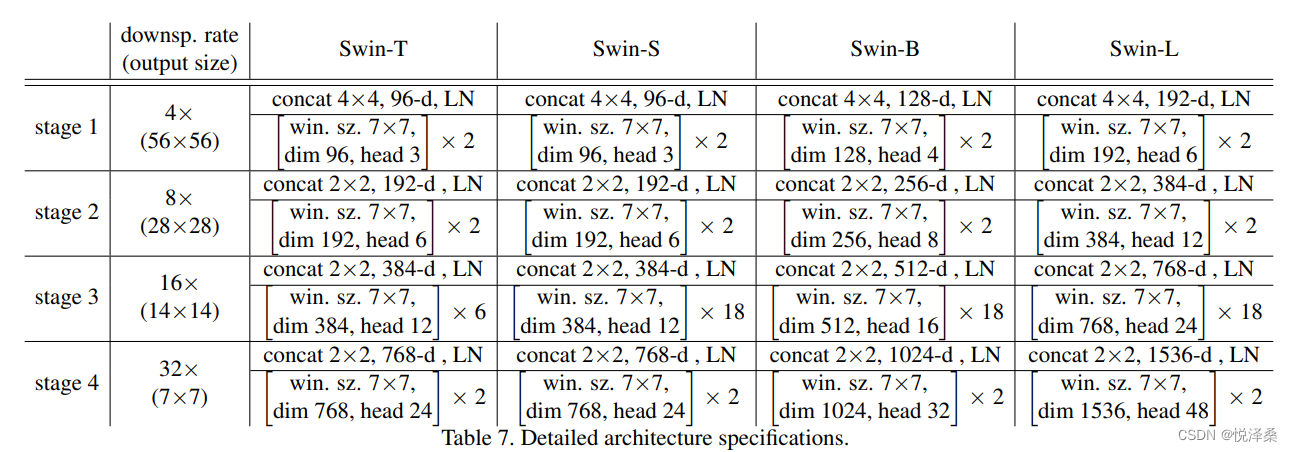
2 基于Pytorch搭建网络
# Swin Transformer
""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows`
- https://arxiv.org/pdf/2103.14030
Code/weights from https://github.com/microsoft/Swin-Transformer
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from typing import Optional
def drop_path_f(x,drop_prob:float=0.,training:bool=False):
if drop_prob==0. or not training:
return x
keep_prob = 1-drop_prob
shape = (x.shape[0],)+(1,)*(x.ndim-1) # work with diff dim
random_tensor = keep_prob+torch.rand(shape,dtype=x.dtype,device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob)*random_tensor
return output
class DropPath(nn.Module):
def __init__(self,drop_prob=None):
super(DropPath,self).__init__()
self.drop_prob = drop_prob
def forward(self,x):
return drop_path_f(x,self.drop_prob,self.training)
def window_partition(x,window_size:int):
# 将feature map按照window_size划分成一个个没有重叠的window
B,H,W,C = x.shape
x = x.view(B,H//window_size,window_size,W//window_size,window_size,C)
windows = x.permute(0,1,3,2,4,5).contiguous().view(-1,window_size,window_size,C)
return windows
def window_reverse(windows,window_size:int,H:int,W:int):
# 将一个个window还原成一个feature map
B = int(windows.shape[0]/(H*W/window_size/window_size))
x = windows.view(B,H//window_size,W//window_size,window_size,window_size,-1)
x = x.permute(0,1,3,2,4,5).contiguous().view(B,H,W,-1)
return x
class PatchEmbed(nn.Module):
def __init__(self,patch_size=4,in_c=3,embed_dim=96,norm_layer=None):
super().__init__()
patch_size = (patch_size,patch_size)
self.patch_size = patch_size
self.in_chans = in_c
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_c,embed_dim,kernel_size=patch_size,stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
_,_,H,W = x.shape
# padding
pad_input = (H%self.patch_size[0]!=0) or (W%self.patch_size[1]!=0)
if pad_input:
x = F.pad(x,(0,self.patch_size[1]-W%self.patch_size[1],
0,self.patch_size[0]-H%self.patch_size[0],0,0))
# 下采样patch_size倍
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1,2)
x = self.norm(x)
return x,H,W
class PatchMerging(nn.Module):
def __init__(self,dim,norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4*dim,2*dim,bias=False)
self.norm = norm_layer(4*dim)
def forward(self,x,H,W):
B,L,C = x.shape
assert L==H*W,"input feature has wrong size"
x = x.view(B,H,W,C)
# padding
pad_input = (H%2==1) or (W%2==1)
if pad_input:
x = F.pad(x,(0,0,0,W%2,0,H%2))
x0 = x[:,0::2,0::2,:] # [B,H/2,W/2,C]
x1 = x[:,1::2,0::2,:] # [B,H/2,W/2,C]
x2 = x[:,0::2,1::2,:] # [B,H/2,W/2,C]
x3 = x[:,1::2,1::2,:] # [B,H/2,W/2,C]
x = torch.cat([x0,x1,x2,x3],-1) # [B,H/2,W/2,4*C]
x = x.view(B,-1,4*C) # [B,H/2*W/2,4*C]
x = self.norm(x)
x = self.reduction(x) # [B,H/2*W/2,2*C]
return x
class Mlp(nn.Module):
def __init__(self,in_features,hidden_features=None,out_features=None,act_layer=nn.GELU,drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features,hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features,out_features)
self.drop2 = nn.Dropout(drop)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class WindowAttention(nn.Module):
def __init__(self,dim,window_size,num_heads,qkv_bias=True,attn_drop=0.,proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim//num_heads
self.scale = head_dim**-0.5
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2*window_size[0]-1)*(2*window_size[1]-1),num_heads))
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h,coords_w],indexing="ij"))
coords_flatten = torch.flatten(coords,1)
relative_coords = coords_flatten[:,:,None]-coords_flatten[:,None,:]
relative_coords = relative_coords.permute(1,2,0).contiguous()
relative_coords[:,:,0] += self.window_size[0]-1
relative_coords[:,:,1] += self.window_size[1]-1
relative_coords[:,:,0] *= 2*self.window_size[1]-1
relative_position_index = relative_coords.sum(-1)
self.register_buffer("relative_position_index",relative_position_index)
self.qkv = nn.Linear(dim,dim*3,bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim,dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_position_bias_table,std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self,x,mask:Optional[torch.Tensor]=None):
B_,N,C = x.shape
qkv = self.qkv(x).reshape(B_,N,3,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
q,k,v = qkv.unbind(0)
q = q*self.scale
attn = ([email protected](-2,-1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0]*self.window_size[1],self.window_size[0]*self.window_size[1],-1)
relative_position_bias = relative_position_bias.permute(2,0,1).contiguous()
attn = attn+relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_//nW,nW,self.num_heads,N,N)+mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1,self.num_heads,N,N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn@v).transpose(1,2).reshape(B_,N,C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformerBlock(nn.Module):
def __init__(self,dim,num_heads,window_size=7,shift_size=0,
mlp_ratio=4.,qkv_bias=True,drop=0.,attn_drop=0.,drop_path=0.,
act_layer=nn.GELU,norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0<=self.shift_size<self.window_size,"shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim,window_size=(self.window_size,self.window_size),num_heads=num_heads,
qkv_bias=qkv_bias,attn_drop=attn_drop,proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path>0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim*mlp_ratio)
self.mlp = Mlp(in_features=dim,hidden_features=mlp_hidden_dim,act_layer=act_layer,drop=drop)
def forward(self,x,attn_mask):
H,W = self.H, self.W
B,L,C = x.shape
assert L==H*W,"input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B,H,W,C)
# 把feature map给pad到window size的整数倍
pad_l = pad_t = 0
pad_r = (self.window_size-W%self.window_size)%self.window_size
pad_b = (self.window_size-H%self.window_size)%self.window_size
x = F.pad(x,(0,0,pad_l,pad_r,pad_t,pad_b))
_,Hp,Wp,_ = x.shape
if self.shift_size>0:
shifted_x = torch.roll(x,shifts=(-self.shift_size,-self.shift_size),dims=(1,2))
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x,self.window_size)
x_windows = x_windows.view(-1,self.window_size*self.window_size,C)
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows,mask=attn_mask)
attn_windows = attn_windows.view(-1,self.window_size,self.window_size,C)
shifted_x = window_reverse(attn_windows,self.window_size,Hp,Wp)
if self.shift_size>0:
x = torch.roll(shifted_x,shifts=(self.shift_size,self.shift_size),dims=(1,2))
else:
x = shifted_x
if pad_r>0 or pad_b>0:
# 把前面pad的数据移除掉
x = x[:,:H,:W,:].contiguous()
x = x.view(B,H*W,C)
# FFN
x = shortcut+self.drop_path(x)
x = x+self.drop_path(self.mlp(self.norm2(x)))
return x
class BasicLayer(nn.Module):
def __init__(self,dim,depth,num_heads,window_size,mlp_ratio=4.,
qkv_bias=True,drop=0.,attn_drop=0.,drop_path=0.,
norm_layer=nn.LayerNorm,downsample=None,use_checkpoint=False):
super().__init__()
self.dim = dim
self.depth = depth
self.window_size = window_size
self.use_checkpoint = use_checkpoint
self.shift_size = window_size//2
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i%2==0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path,list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
if downsample is not None:
self.downsample = downsample(dim=dim,norm_layer=norm_layer)
else:
self.downsample = None
def create_mask(self,x,H,W):
# 保证Hp和Wp是window_size的整数倍
Hp = int(np.ceil(H/self.window_size))*self.window_size
Wp = int(np.ceil(W/self.window_size))*self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1,Hp,Wp,1),device=x.device)
h_slices = (slice(0,-self.window_size),
slice(-self.window_size,-self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0,-self.window_size),
slice(-self.window_size,-self.shift_size),
slice(-self.shift_size,None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:,h,w,:] = cnt
cnt += 1
mask_windows = window_partition(img_mask,self.window_size)
mask_windows = mask_windows.view(-1,self.window_size*self.window_size)
attn_mask = mask_windows.unsqueeze(1)-mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask!=0,float(-100.0)).masked_fill(attn_mask==0,float(0.0))
return attn_mask
def forward(self,x,H,W):
attn_mask = self.create_mask(x,H,W)
for blk in self.blocks:
blk.H,blk.W = H,W
if not torch.jit.is_scripting() and self.use_checkpoint:
x = checkpoint.checkpoint(blk,x,attn_mask)
else:
x = blk(x,attn_mask)
if self.downsample is not None:
x = self.downsample(x,H,W)
H,W = (H+1)//2,(W+1)//2
return x,H,W
class SwinTransformer(nn.Module):
def __init__(self,patch_size=4,in_chans=3,num_classes=1000,
embed_dim=96,depths=(2,2,6,2),num_heads=(3,6,12,24),
window_size=7,mlp_ratio=4.,qkv_bias=True,
drop_rate=0.,attn_drop_rate=0.,drop_path_rate=0.1,
norm_layer=nn.LayerNorm,patch_norm=True,
use_checkpoint=False,**kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
# stage4输出特征矩阵的channels
self.num_features = int(embed_dim*2**(self.num_layers-1))
self.mlp_ratio = mlp_ratio
# 分割成不重叠的patches
self.patch_embed = PatchEmbed(
patch_size=patch_size,in_c=in_chans,embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0,drop_path_rate,sum(depths))]
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layers = BasicLayer(dim=int(embed_dim*2**i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer+1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer<self.num_layers-1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layers)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features,num_classes) if num_classes>0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self,m):
if isinstance(m,nn.Linear):
nn.init.trunc_normal_(m.weight,std=.02)
if isinstance(m,nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.LayerNorm):
nn.init.constant_(m.bias,0)
nn.init.constant_(m.weight,1.0)
def forward(self,x):
x,H,W = self.patch_embed(x)
x = self.pos_drop(x)
for layer in self.layers:
x,H,W = layer(x,H,W)
x = self.norm(x)
x = self.avgpool(x.transpose(1,2))
x = torch.flatten(x,1)
x = self.head(x)
return x
def swin_tiny_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,patch_size=4,window_size=7,embed_dim=96,depths=(2,2,6,2),
num_heads=(3,6,12,24),num_classes=num_classes,**kwargs)
return model
def swin_small_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,patch_size=4,window_size=7,embed_dim=96,depths=(2,2,18,2),
num_heads=(3,6,12,24),num_classes=num_classes,**kwargs)
return model
def swin_base_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,patch_size=4,window_size=7,embed_dim=128,depths=(2,2,18,2),
num_heads=(4,8,16,32),num_classes=num_classes,**kwargs)
return model
def swin_base_patch4_window12_384(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384.pth
model = SwinTransformer(in_chans=3,patch_size=4,window_size=12,embed_dim=128,depths=(2,2,18,2),
num_heads=(4,8,16,32),num_classes=num_classes,**kwargs)
return model
def swin_base_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
model = SwinTransformer(in_chans=3,patch_size=4,window_size=7,embed_dim=128,depths=(2,2,18,2),
num_heads=(4,8,16,32),num_classes=num_classes,**kwargs)
return model
def swin_base_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth
model = SwinTransformer(in_chans=3,patch_size=4,window_size=12,embed_dim=128,depths=(2,2,18,2),
num_heads=(4,8,16,32),num_classes=num_classes,**kwargs)
return model
def swin_large_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22k.pth
model = SwinTransformer(in_chans=3,patch_size=4,window_size=7,embed_dim=192,depths=(2,2,18,2),
num_heads=(6,12,24,48),num_classes=num_classes,**kwargs)
return model
def swin_large_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth
model = SwinTransformer(in_chans=3,patch_size=4,window_size=12,embed_dim=192,depths=(2,2,18,2),
num_heads=(6,12,24,48),num_classes=num_classes,**kwargs)
return modelPart3 ConvNeXt
1 网络结构
1.1 使用的结构

Marco design
①stage ratio
将ResNet50的堆叠次数由(3,4,6,3)调整成(3,3,9,3),与Swin-T保持一致,效果有了明显提升
②“patchify” stem
将stem(最初的下采样模块)换成卷积核大小为4,步距为4的卷积层,准确率有了微小的提升,FLOPs也有略微降低
ResNeXt
相比ResNet,ResNeXt在FLOPs和准确率之间做了更好的平衡,这里作者还采用了DW卷积,增大输入特征的宽度时,准确率有了较大的提升,FLOPs也有增加
Inverted bottleneck
作者认为Transformer block中的MLP模块非常像两头粗中间细的倒残差模块,因此把Bottleneck block换成了倒残差模块,准确率有了微小的提升,FLOPs也有明显的下降
Large kerner size
将DW卷积上移,之前是1*1卷积->DW卷积->1*1卷积,现在是DW卷积->1*1卷积->1*1卷积,并将DW卷积的卷积核大小由3*3改为了7*7
Various layer-wise Micro designs
将ReLU替换为GELU,并且减少了激活函数的使用数量,减少了BN的使用次数,将BN替换为LN,加快了收敛并减小了过拟合,最后使用了一个单独的下采样层
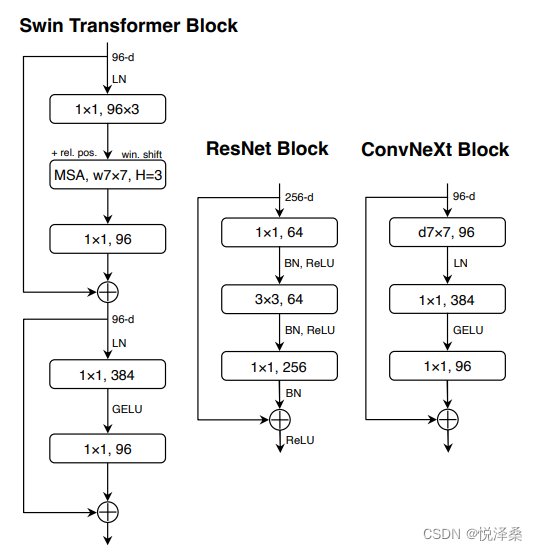
1.2 网络效果
与相同规模的Swin Transformer相比,ConvNeXt的准确率更高,并且每秒推理的图片数量增加了约40%。
1.3 多种版本

其中C代表每个输入特征层的channel,B代表每个stage的block的重复次数
2 基于Pytorch搭建网络
# ConvNeXt
"""
original code from facebook research:
https://github.com/facebookresearch/ConvNeXt
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
def drop_path(x,drop_prob:float=0.,training:bool=False):
if drop_prob==0. or not training:
return x
keep_prob = 1-drop_prob
shape = (x.shape[0],)+(1,)*(x.ndim-1) # work with diff dim
random_tensor = keep_prob+torch.rand(shape,dtype=x.dtype,device=x.device)
random_tensor.floor_()
output = x.div(keep_prob)*random_tensor
return output
class DropPath(nn.Module):
def __init__(self,drop_prob=None):
super(DropPath,self).__init__()
self.drop_prob = drop_prob
def forward(self,x):
return drop_path(x,self.drop_prob,self.training)
class LayerNorm(nn.Module):
def __init__(self,normalized_shape,eps=1e-6,data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape),requires_grad=True)
self.bias = nn.Parameter(torch.zeros(normalized_shape),requires_grad=True)
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last","channels_first"]:
raise ValueError(f"not support data format '{self.data_format}'")
self.normalized_shape = (normalized_shape,)
def forward(self,x:torch.Tensor)->torch.Tensor:
if self.data_format=="channels_last":
return F.layer_norm(x,self.normalized_shape,self.weight,self.bias,self.eps)
elif self.data_format=="channels_first":
# [batch_size,channels,height,width]
mean = x.mean(1,keepdim=True)
var = (x-mean).pow(2).mean(1,keepdim=True)
x = (x-mean)/torch.sqrt(var+self.eps)
x = self.weight[:,None,None]*x+self.bias[:,None,None]
return x
class Block(nn.Module):
def __init__(self,dim,drop_rate=0.,layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim,dim,kernel_size=7,padding=3,groups=dim) # DW卷积
self.norm = LayerNorm(dim,eps=1e-6,data_format="channels_last")
self.pwconv1 = nn.Linear(dim,4*dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4*dim,dim)
self.gamma = nn.Parameter(layer_scale_init_value*torch.ones((dim,)),
requires_grad=True) if layer_scale_init_value>0 else None
self.drop_path = DropPath(drop_rate) if drop_rate>0. else nn.Identity()
def forward(self,x:torch.Tensor)->torch.Tensor:
shortcut = x
x = self.dwconv(x)
x = x.permute(0,2,3,1) # [N,C,H,W]->[N,H,W,C]
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma*x
x = x.permute(0,3,1,2) # [N,H,W,C]->[N,C,H,W]
x = shortcut+self.drop_path(x)
return x
class ConvNeXt(nn.Module):
def __init__(self,in_chans:int=3,num_classes:int=1000,depths:list=None,
dims:list=None,drop_path_rate:float=0.,
layer_scale_init_value:float=1e-6,head_init_scale:float=1.):
super().__init__()
self.downsample_layers = nn.ModuleList()
stem = nn.Sequential(nn.Conv2d(in_chans,dims[0],kernel_size=4,stride=4),
LayerNorm(dims[0],eps=1e-6,data_format="channels_first"))
self.downsample_layers.append(stem)
# 对应stage2-stage4前的3个downsample
for i in range(3):
downsample_layer = nn.Sequential(LayerNorm(dims[i],eps=1e-6,data_format="channels_first"),
nn.Conv2d(dims[i],dims[i+1],kernel_size=2,stride=2))
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList()
dp_rates = [x.item() for x in torch.linspace(0,drop_path_rate,sum(depths))]
cur = 0
# 构建每个stage中堆叠的block
for i in range(4):
stage = nn.Sequential(*[Block(dim=dims[i],drop_rate=dp_rates[cur+j],layer_scale_init_value=layer_scale_init_value)
for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1],eps=1e-6)
self.head = nn.Linear(dims[-1],num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self,m):
if isinstance(m,(nn.Conv2d,nn.Linear)):
nn.init.trunc_normal_(m.weight,std=0.2)
nn.init.constant_(m.bias,0)
def forward_features(self,x:torch.Tensor)->torch.Tensor:
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2,-1]))
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.forward_features(x)
x = self.head(x)
return x
def convnext_tiny(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth
model = ConvNeXt(depths=[3,3,9,3],dims=[96,192,384,768],num_classes=num_classes)
return model
def convnext_small(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pth
model = ConvNeXt(depths=[3,3,27,3],dims=[96,192,384,768],num_classes=num_classes)
return model
def convnext_base(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth
# https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth
model = ConvNeXt(depths=[3,3,27,3],dims=[128,256,512,1024],num_classes=num_classes)
return model
def convnext_large(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth
# https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pth
model = ConvNeXt(depths=[3,3,27,3],dims=[192,384,768,1536],=num_classes)
return model
def convnext_xlarge(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pth
model = ConvNeXt(depths=[3,3,27,3],dims=[256,512,1024,2048],=num_classes)
return modelPart4 个人体会
自然语言处理和计算机视觉有一些相通之处,所以Transformer目前是一个较热门的研究方向,有很多地方可以优化和改造,但相比之下,CNN的发展更为成熟,具有更多成熟的搭配结构,必要时可以将多种结构组合起来,从而达到更优。