[模型浅析] Swin Transformer源码阅读
写在最前面
本文主要是本人在研究Siwn Transformer过程中的记录,所以可读性并不是很好,推荐对照完整的源码进行理解。由于这是本人第一次细致研究Transformer,所以除了对Swin中Shift window循环位移的实现方法做了比较详细的分析,还着重分析了一下对相对位置编码的实现,希望能对读者有所帮助。此外,文中若有错误还请各位不吝赐教。
完整源码github
源代码函数与论文中模块的对应
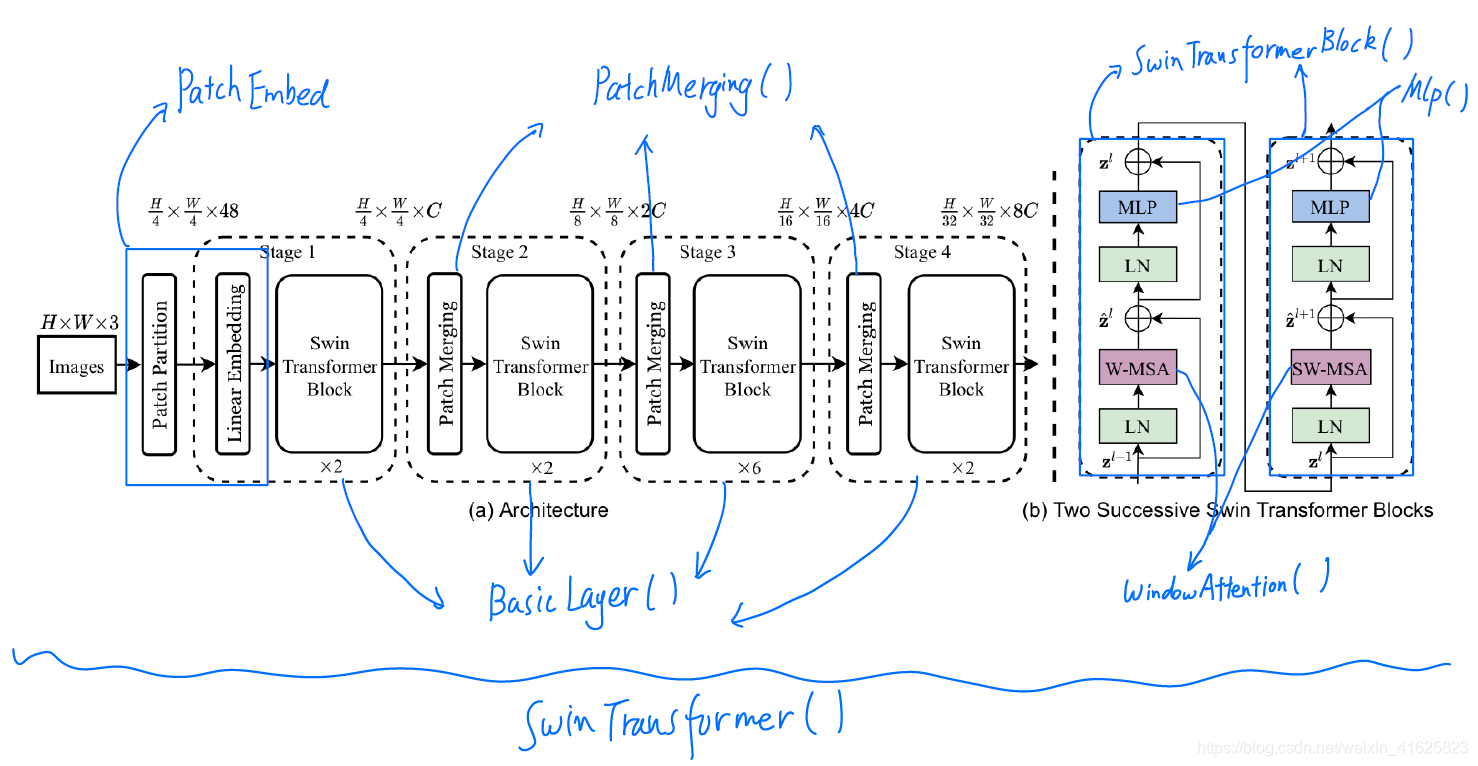
网络的实例化
分析以论文中最轻量的模型(Swin-T)为例。其模型的默认参数的设置基本就对应了该轻量模型,除了设置的drop out比例,在实例化的时候取了0.3(代码片会在最开始标出在代码中所属的类,以便对照源码)。
"""SwinTransformer"""
class SwinTransformer(nn.Module):
def __init__(self,
pretrain_img_size=224,
patch_size=4,
in_chans=3,
embed_dim=96,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.2,
norm_layer=nn.LayerNorm,
ape=False,
patch_norm=True,
out_indices=(0, 1, 2, 3),
frozen_stages=-1,
use_checkpoint=False):
网络的实例化从论文中将图像进行不重叠分块的Patch Partition开始,在代码中这部分通过PatchEmbed类实现,设置norm_layer为LayerNorm:
"""SwinTransformer"""
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
从下面的源码可以看到这部分其实将文中的Patch Partition和Linear embedding合二为一了,最终实现就是直接对图像做一个步长与核尺寸相同(都是4)的卷积,并且加上了LayerNorm。
"""SwinTransformer/PatchEmbed"""
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
Args:
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
由于Swin的标准版中没有使用绝对位置编码,所以实例化的下一个部分就是构建每个阶段的Swin Transformer模块了。在构造之前,先为每个阶段中的模块随机生成了一个Drop Out的比例,用于随机去掉模块在自注意力机制和MLP处理之后的部分特征通路。为了方便后面对照,将网络第一阶段的参数写在注释中。
"""SwinTransformer"""
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
dim=int(embed_dim * 2 ** i_layer), # 96
depth=depths[i_layer], # 2
num_heads=num_heads[i_layer], # 3
window_size=window_size, # 7
mlp_ratio=mlp_ratio, # 4
qkv_bias=qkv_bias, # True
qk_scale=qk_scale, # None
drop=drop_rate, # 0
attn_drop=attn_drop_rate, # 0
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], # [0.0, 0.027272729203104973]
norm_layer=norm_layer, # nn.LayerNorm
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None, # PatchMerging
use_checkpoint=use_checkpoint) # False
每个Basic Layer的组成就是一个 Patch Merging模块加上一系列Swin Transformer Block。按照代码的顺序,先对Swin Transformer Block进行分析。同样,以第一阶段的设置为例(写在注释中)。
"""SwinTransformer/BasicLayer"""
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim, # 96
num_heads=num_heads, # 3
window_size=window_size, # 7
shift_size=0 if (i % 2 == 0) else window_size // 2, # 0 / 3
mlp_ratio=mlp_ratio, # 4
qkv_bias=qkv_bias, # True
qk_scale=qk_scale, # None
drop=drop, # 0
attn_drop=attn_drop, # 0
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path, # 0
norm_layer=norm_layer) # nn.LayerNorm
for i in range(depth)])
在实例化Swin Transformer模块的过程中,归一化层,MLP的设置都不用过多解释,直接关注网络的核心——WindowAttention。WindowAttention在实例化的过程中主要任务是构建一个相对位置偏移量,并实例化Attention用到的MLP和Drop out等。
Window Attention中的相对位置编码
相对位置编码在论文中并没有给出详细的解释,通过源代码,发现其实使用一个正态分布的随机数来为每一种相对位置关系(并且区分不同注意力头,所以是一个三维的张量)编码。relative_position_bias_table就是随机生成的编码,可以看到在最后一行使用了截断的正态分布对其进行填充。由于这个编码在网络的整个训练和推理过程中都是不变的,所以需要用register_buffer将其存储为一个不需要训练的模型参数。

"""SwinTransformer/BasicLayer/WindowAttention"""
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
代码中容易让人产生迷惑的部分是索引生成的过程。这一过程如下图所示,其实并不复杂,只是在实现过程中用了一些技巧。最终生成的索引是一个在 [ 0 , ( W ∗ 2 − 1 ) 2 ] [0,(W*2-1)^2] [0,(W∗2−1)2]之内的整数。这是由于对于一个W*W的窗口,其能产生的所有相对位置关系在每个方向上都是在 [ − ( W − 1 ) , W − 1 ] [-(W-1),W-1] [−(W−1),W−1]之间。

至此网络的实例化基本结束。在实例化的最后为每个输出特征设置了额外的LayerNorm层,并按需设置冻结参数。
# add a norm layer for each output
for i_layer in out_indices:
layer = norm_layer(num_features[i_layer])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
self._freeze_stages()
数据的前向传播
以输入一副[1, 3, 512, 512]大小的图像为例,来分析整个前向传播流程。首先,图像为经过Patch Partition和Linear embedding。
"""SwinTransformer"""
x = self.patch_embed(x)
由于512可以被4整除,所以不需要对图像进行边缘填充。图像经过核大小为4,步长为4的不重叠卷积之后,产生的特征尺寸变为原本的1/4,通道为96通道。
"""SwinTransformer/PatchEmbed"""
# padding
_, _, H, W = x.size()
if W % self.patch_size[1] != 0:
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1]))
if H % self.patch_size[0] != 0:
x = F.pad(x, (0, 0, 0, self.patch_size[0] - H % self.patch_size[0]))
x = self.proj(x) # B C Wh Ww
之后对特征进行Layer Normalization操作,可以看到代码的实现是将特征在空间维度上拉直(即融合第2,3维度),尺寸变为[1, 96, 16384]。之后在特征的通道维度上进行Layer Normalization,即将每个空间位置上的特征归一化为标准正态分布,再加一个仿射变换。最后,将特征还原回原尺寸。这个过程也是之后所有Layer Normalization的操作流程,将不再复述。
"""SwinTransformer/PatchEmbed"""
if self.norm is not None:
Wh, Ww = x.size(2), x.size(3)
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
x = x.transpose(1, 2).view(-1, self.embed_dim, Wh, Ww)
return x
之后,将特征再次在空间维度上拉直,并将特征交换到最后一维,进行输入Drop Out(目前设置为0,即不进行Drop Out)。
"""SwinTransformer"""
if self.ape:
# interpolate the position embedding to the corresponding size
absolute_pos_embed = F.interpolate(self.absolute_pos_embed, size=(Wh, Ww), mode='bicubic')
x = (x + absolute_pos_embed).flatten(2).transpose(1, 2) # B Wh*Ww C
else:
x = x.flatten(2).transpose(1, 2)
x = self.pos_drop(x)
下面,将拉直的特征(尺寸为[1, 16384, 96])输入第一个Transformer阶段,同时还要输入目前特征的空间尺寸。
"""SwinTransformer"""
for i in range(self.num_layers):
layer = self.layers[i]
x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)
循环位移窗口的实现
在每一个Basic Layer中,需要为固定偏移窗口(shift window)计算自注意力的掩膜。生成的图像掩膜其实就是将后续需要从左上位移到右下的部分按长方形进行分块。将掩膜的右下角10x10的区域进行打印可以看到掩膜一共被分为了8个区域(不考虑0,即不计算掩膜的区域)。
"""SwinTransformer/BasicLayer"""
# calculate attention mask for SW-MSA
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # 1 Hp Wp 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
>>>img_mask[0, -10:, -10:, 0]
tensor([[0., 0., 0., 1., 1., 1., 1., 2., 2., 2.],
[0., 0., 0., 1., 1., 1., 1., 2., 2., 2.],
[0., 0., 0., 1., 1., 1., 1., 2., 2., 2.],
[3., 3., 3., 4., 4., 4., 4., 5., 5., 5.],
[3., 3., 3., 4., 4., 4., 4., 5., 5., 5.],
[3., 3., 3., 4., 4., 4., 4., 5., 5., 5.],
[3., 3., 3., 4., 4., 4., 4., 5., 5., 5.],
[6., 6., 6., 7., 7., 7., 7., 8., 8., 8.],
[6., 6., 6., 7., 7., 7., 7., 8., 8., 8.],
[6., 6., 6., 7., 7., 7., 7., 8., 8., 8.]])
为了更直观的表现,通过下图展示一个简化的版本。图中红色线框代表原图像,蓝色虚线代表没有位移的窗口划分情况。而粗蓝线代表位移之后的划分情况。文中为了提高计算效率,将边缘处的不完整窗口,进行了循环平移合并,即将带有下划线的区块平移到没有下划线的位置。用掩膜记录区块是否原本属于统一窗口的信息,就形成了上面的掩膜形式。

之后,将该掩膜按计算注意力的窗口进行划分并拉直([1, 133, 133, 1]->[361, 7, 7, 1]->[361, 49])。之后又用到了与计算相对位置时相同的的技巧,通过相减来确定每个窗口中的所有组合之间是否原本就属于一个窗口,如果不是,则将掩膜中对应项标记为-100。
"""SwinTransformer/BasicLayer"""
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
将整特征(尺寸为[1, 16384, 96])和掩膜(尺寸为[361, 49, 49])送入窗口注意力模块,计算自注意力机制。
"""SwinTransformer/BasicLayer"""
for blk in self.blocks:
blk.H, blk.W = H, W
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x, attn_mask)
else:
x = blk(x, attn_mask)
在自注意力机制模块中,在经过一次Layer Normalization后,首先对特征进行整形,并在特征的右下侧进行填充,使其尺寸为窗口尺寸的倍数(填充后尺寸为[1, 133, 133, 96])。
"""SwinTransformer/BasicLayer/SwinTransformerBlock"""
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# pad feature maps to multiples of window size
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
之后,如果是Shifted Window,需要对其进行循环平移,直接使用pytorch的roll方法进行实现。随后将特征也进行与掩膜相同的整形([1, 133, 133, 96]->[361, 49, 96]),输入自注意力模块:
"""SwinTransformer/BasicLayer/SwinTransformerBlock"""
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
attn_mask = mask_matrix
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
自注意力模块的计算与一般的Transformer其实基本相同,只不过将Batch Size设置为原本数据的Batch Size与每个特征中窗口数量的乘积,以此实现在窗口中进行自注意力的目的。注意力计算涉及到很多张量的整形操作,为了方便理解,还是以上述输入为例,直接将尺寸的变化写在注释中。
"""SwinTransformer/BasicLayer/SwinTransformerBlock/WindowAttention"""
B_, N, C = x.shape
# [BxNwin, N, C]-> [BxNwin, N, 3xC]->[BxNwin, N, 3, Nhead, C']->[3, BxNwin, Nhead, N, C']
# 0 1 2 3 4
# [361, 49, 96]-> [361, 49, 3x96]->[361, 49, 3, 3, 32]->[3, 361, 3, 49, 32]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [BxNwin, Nhead, N, C']
# [361, 3, 49, 32]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
# [BxNwin, Nhead, N, C'] x [BxNwin, Nhead, C', N] -> [BxNwin, Nhead, N, N]
# [361, 3, 49, 32] x [361, 3, 32, 49] -> [361, 3, 49, 49]
attn = (q @ k.transpose(-2, -1))
之后需要在自注意力中加一个相对位置编码,这时之前生成的编码以及索引就派上了用场,通过索引来获取窗口中每种位置关系固定的编码,并作为偏置项加到注意力map中,实现了对位置信息的输入。
"""SwinTransformer/BasicLayer/SwinTransformerBlockWindowAttention"""
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
最后按照一般自注意力的机制将注意力map经过softmax,并与value项相乘,得到更新的特征,其尺寸[361, 49, 96]与输入尺寸相同。
"""WindowAttention"""
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
随后将特征依次通过另一个Layer Normalization和一个MLP,并加上跳跃连接,即完成数据在一个Swin Block中的传播。
"""SwinTransformerBlock"""
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
后续的传播过程与上述过程基本相同,不再重复。