1.摘要
近年来,深度网络在红外和可见图像融合(IVIF)中取得了重大突破,引起了广泛关注。然而,大多数现有方法无法处理源图像的轻微不对齐,并且存在高计算和空间开销的问题。本文通过开发一种用于鲁棒且高效融合的循环校正网络ReCoNet,解决了这两个在学术界很少涉及的关键问题。具体而言,我们设计了一个变形模块来显式补偿几何失真,并使用注意力机制来减轻幽灵状伪影等伪影现象。同时,网络由一个并行的扩张卷积层组成,并以循环的方式运行,显著降低了空间和计算复杂度。ReCoNet可以有效且高效地减轻轻微不对齐引起的结构失真和纹理伪影。在两个公共数据集上进行的大量实验证明了我们的ReCoNet相对于最先进的IVIF方法具有优越的准确性和效能。因此,我们在具有不对齐的数据集上相对改善了16%的相关系数(CC),并提高了86%的效率。
实际工作环境中,非同步多源传感器成像通常含有轻微错位、成像畸变等误差,且目标跟踪等部分高级视觉任务对融合运算速度具有较高要求。该项研究针对此类问题,构建了一种图像矫正与融合的高效联合框架。该框架“去伪存真”利用逐次迭代消除多源图像间成像差异、削弱成像畸变,充分利用现代图形计算单元进行并行计算,高效地利用实际场景中含有误差的多模态图像对进行融合,为人机交互与智能自主作业提供了精准的连续感知。该研究方法所生成的融合结果不但在人眼观感上领先,且在多种计算机视觉感知任务结果中,定量测试指标较现有最先进的方法有显著提升
2.引言
红外和可见图像融合(IVIF)生成了一幅融合图像,呈现出互补的特征并且比单一模态图像包含更丰富的信息。生成的图像在视觉上具有吸引力,并且在视频监控、遥感和自动驾驶等实际应用中具有重要意义。
传统的IVIF方法致力于找到跨模态的最佳特征表示,并设计适当的权重进行融合。最近,由于深度学习在非线性拟合和特征提取方面的强大能力,研究人员开始运用深度网络来学习红外和可见图像的共同特征,或者在IVIF的训练样本上设计融合策略。这些方法在特定场景下,例如固定的捕获设备和/或对齐的输入图像,可以产生良好的融合效果,尤其适用于人眼检查。然而,对于现有的IVIF方法,仍然存在两个关键问题,需要解决才能显著提升后续的计算机视觉(CV)任务,包括目标检测、目标跟踪和语义分割等。
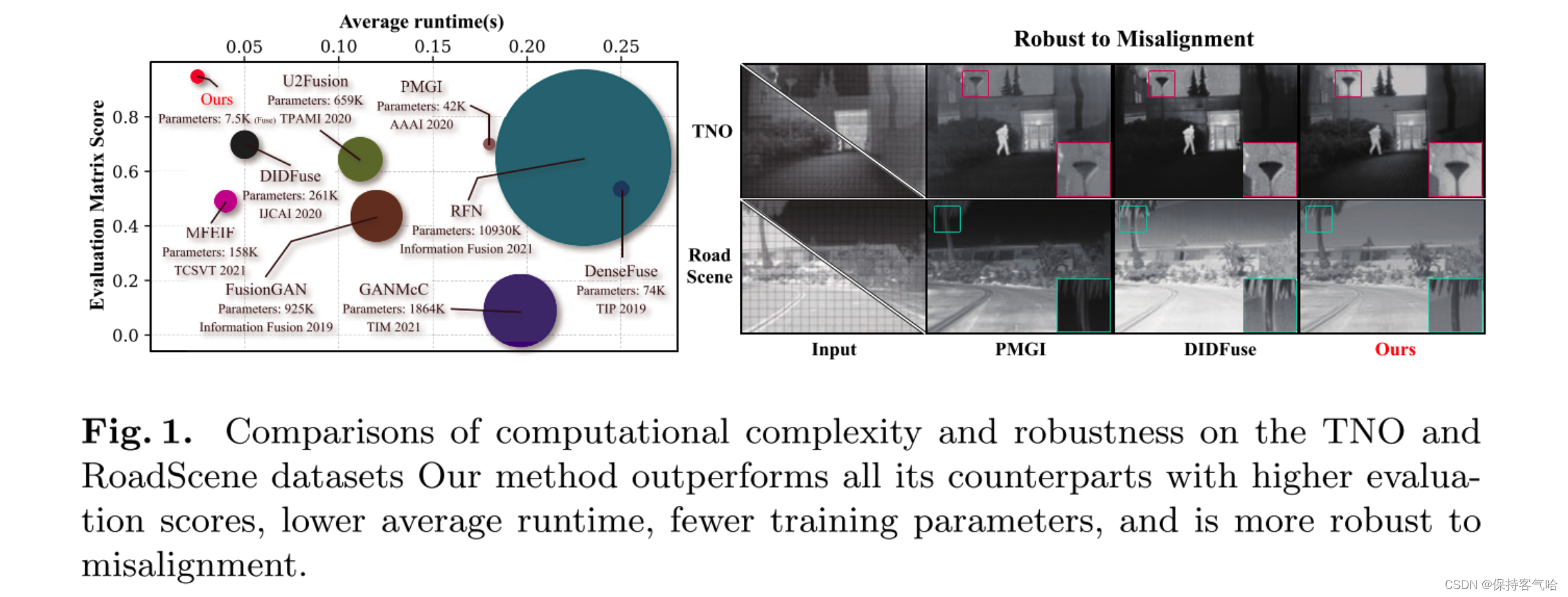
首先,现有的IVIF方法,无论是传统方法还是基于深度学习的方法,通常对输入图像的不对齐非常敏感。一个模态上的轻微平移或变形会在图像结构上产生明显的几何失真,并在纹理细节区域产生幽灵状的伪影,如图1所示,这严重损害了下游CV算法的性能。只有少数几项工作尝试减轻这些不良影响。Ma等人提出了总变差最小化方法,分别加强红外图像的几何结构并保留可见输入图像的纹理。然而,这些方法明显模糊了细节,并未充分利用这两种模态之间的互补信息。此外,其迭代优化过程需要进行密集的梯度计算,导致融合过程耗时。其他基于深度学习的方法采用了注意力/掩膜机制来增强不对齐的鲁棒性,通过减小不匹配补丁的权重来避免伪影。然而,这些注意力/掩膜机制难以描述不同模态之间的相关性,导致融合结果中出现细小的伪影。
其次,现有的方法需要大量的空间来存储众多网络参数,并且在运行时滞后于实时性能 ,如图1中的圆圈和时间值所示,尽管与传统方法相比,深度方法加速了融合过程。主要瓶颈在于这些深度方法需要堆叠多层卷积块来学习红外和可见图像之间共享的共同特征,而这两种模态在外观上存在明显差异。同时,训练这些庞大的网络需要大量的图像对,这在实际中是不可能的
本研究通过开发一种循环轻量级网络来解决由于不对齐而引起的结构失真和纹理伪影问题。具体而言,我们训练了一个微配准模块(R)来预测输入图像之间的变形场。该模块显式地纠正由于像素位移引起的几何结构失真。我们还从两个模态 ( σ i r 和 σ v i s ) (σ_{ir}和σ_{vis}) (σir和σvis)中学习了注意力图,发现各自输入中显著的区域。因此,在融合过程中,可见输入的纹理权重更大,同时区分由于空间偏移引起的高频重复模式,从而隐式地减弱伪影现象。为了提高效率,我们设计了一个并行的扩张卷积层(PDC),它使用多尺度感受野学习上下文信息。我们训练了这个简单的PDC层的一组参数,并在融合流程中以循环的方式运行网络(F),将注意力和轻量级PDC模块级联起来。这个循环过程节省了网络参数的空间,并且迭代地提高了融合质量。图1展示了我们的方法在两个公开可用的数据集上相对于最先进方法的更高的数值分数、更低的计算成本和更少的参数。我们总结我们的主要贡献如下:
- 据我们所知,这是第一个在中波红外和可见图像上联合学习深度网络进行配准和融合的工作,从而实现对源图像不对齐的鲁棒性。
-
我们设计了一个变形模块来显式补偿几何失真,并设计了一个注意力机制来减轻残余的伪影。这种设计有效地解决了给定场景的结构和纹理区域中出现的两种不同类型的不良效应。
-
我们开发了一个并行的扩张卷积层和循环机制,显著降低了空间和计算复杂性。
3.方法
3.1 Motivation

在现实场景中,由于无法克服的内部和外部因素,无法获得像素级别对齐的红外和可见光图像。如图2所示,我们展示了在真实采集中经常出现的三种典型因素。
-
在大多数封装设备中,假设内部系统已经工作了很长时间或处于高温内部环境中,互补金属氧化物半导体(CMOS)会产生图像噪声。
-
对于服务器环境,例如沙漠和热带森林,热气流的折射可能会导致源图像严重失真。
-
颠簸的道路、快速移动的物体或非同步的多视觉摄像机可能会使源图像退化,例如运动模糊和运输问题。一个模态上的轻微偏移或变形会带来明显的几何失真;
很少有现有方法可以克服这些问题,因为它们只在像素级对齐的图像对上执行融合。
基于这一观察,我们提出了一种用于实现IVIF的循环校正网络,该网络具有足够的容量来处理视觉对齐源输入。
除此之外,大多数先前的融合方法都努力通过增加网络的深度和宽度来加强网络,以达到最先进的性能。然而,网络层的这种灾难性增加可能导致对计算和内存的显著需求,因此使它们难以应用于后续的高级计算机视觉任务,例如目标检测、深度估计和目标跟踪。因此,我们的方法精心设计了并行扩张卷积层和循环学习机制,以提高计算效率。
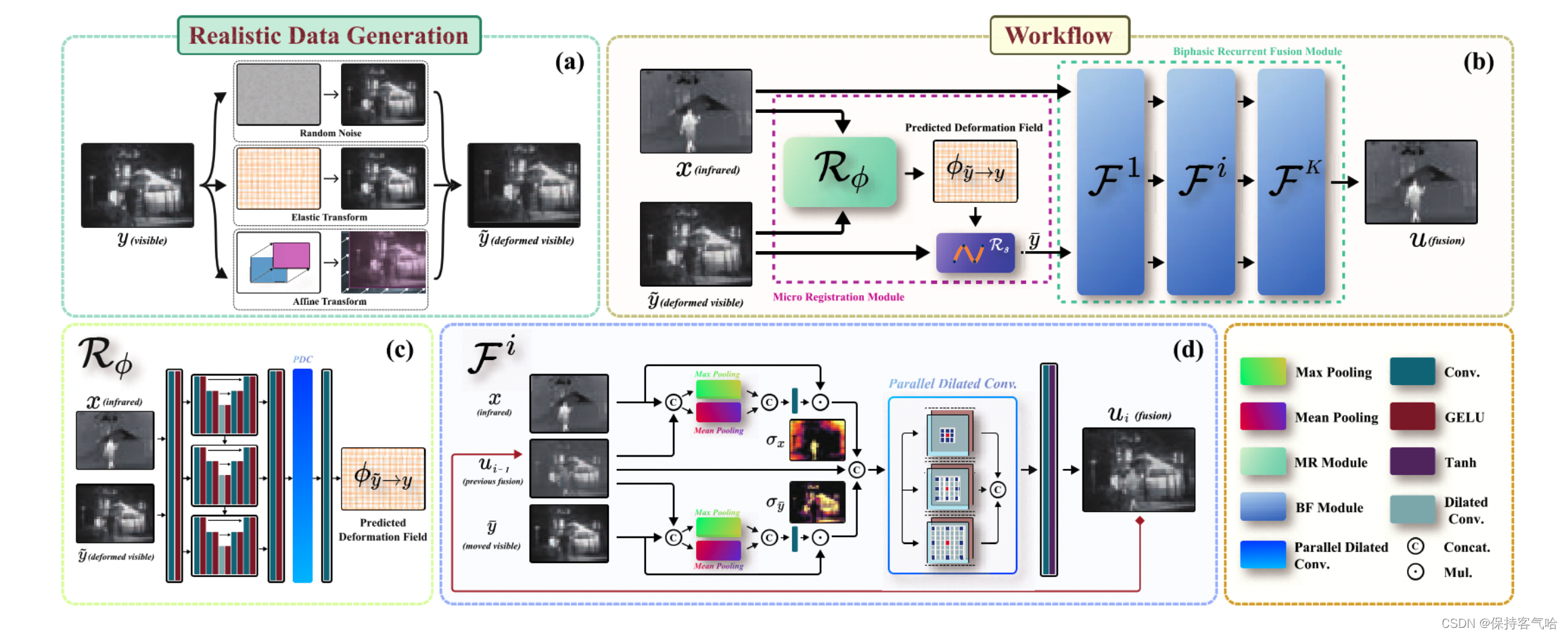
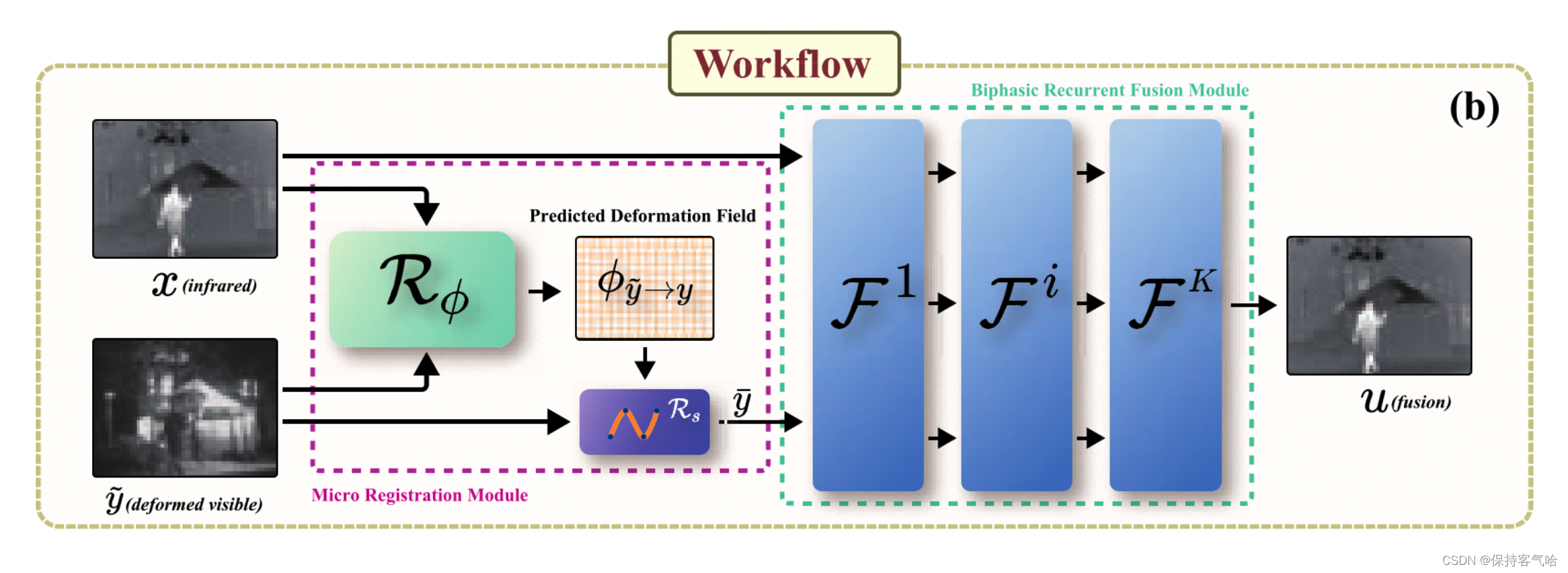
3.2 Micro Registration Module
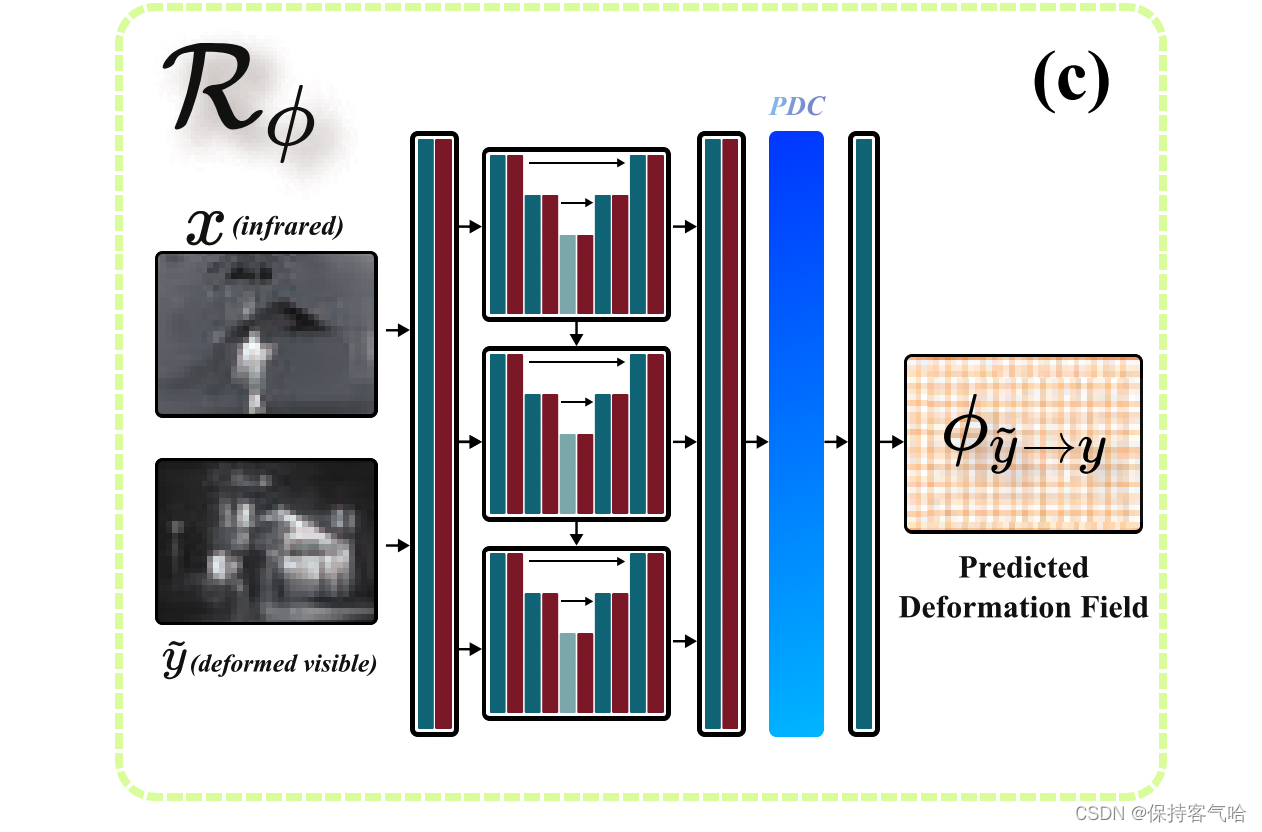
微对齐模块R有助于减轻由几何失真或尺度引起的轻微不对齐误差。它由两个组件组成:变形场预测网络 R ϕ R_ϕ Rϕ和重新采样层 R S R_S RS。变形场 ϕ ϕ ϕ用于表示变换,使我们的方法能够非均匀准确地映射图像。
注:变形场(Deformation field)是一种用于描述图像或物体变形的技术。它是一个向量场,包含了在给定区域内每个点的位移向量。这些位移向量表示了每个点在变形过程中相对于初始位置的移动量。传统的均匀变换,图像中的每个像素都会按照相同的方式进行位移、旋转、缩放或其他几何变换操作。例如,平移变换是一种常见的均匀变换,其中图像中的每个像素都按照相同的位移向量进行移动。非均匀变换可以实现更精确的映射。这意味着不同区域的像素可以被映射到不同的位置,以更好地适应图像的变化。例如,在面部识别中,非均匀变换可以根据每个人的面部特征,将图像中的关键点对齐到相应的位置,从而实现更准确的人脸识别。
假设给定红外图像 x x x和失真的可见光图像 y ~ \tilde{y} y~, R ϕ R_ϕ Rϕ的目标是预测一个变形场 ϕ y ~ → y = R ϕ ( x , y ~ ) ϕ_{ {\tilde{y}}→y}= R_ϕ(x, \tilde{y}) ϕy~→y=Rϕ(x,y~),描述如何将 y ~ \tilde{y} y~非刚性地对齐到y。变形场 ϕ ∈ R h × w × 2 ϕ ∈ R^{h×w×2} ϕ∈Rh×w×2,其中每对 ϕ h , w = ( ∆ x h , ∆ x w ) ∈ R 2 ϕ_{h,w} = (∆x_h, ∆x_w) ∈ R^2 ϕh,w=(∆xh,∆xw)∈R2表示 y ~ \tilde{y} y~中像素 v h , w v_{h,w} vh,w的变形偏移。我们的R主要关注配准后的融合效果,因此设计了一个类似U-Net的微模块。详细的架构在图3的左下角给出。
为了对图像应用几何变换,我们使用重新采样层 R S R_S RS,该层接收 R ϕ R_ϕ Rϕ生成的变形场 ϕ y ~ → y ϕ_{
{\tilde{y}}→y} ϕy~→y并将其应用于失真的可见光图像 y ~ \tilde{y} y~。通过以下方程计算变换后可见光图像 y ˉ \bar{y} yˉ在像素 v h , w v_{h,w} vh,w处的值: y ˉ [ v h , w ] = y ~ [ v h , w + ϕ h , w y ~ → y ] ] ( 1 ) \bar{y}\left[v_{h,w}\right] = \tilde{y}\left[v_{h,w} + \phi^{\tilde{y}\rightarrow y}_{h,w}\right] ](1) yˉ[vh,w]=y~[vh,w+ϕh,wy~→y]](1)
3.3 Biphasic Recurrent Fusion Module
上下文特征(如边缘、目标和轮廓)在融合过程中起着关键作用。然而,随着网络深度的增加,上下文特征逐渐退化,导致融合结果中的目标模糊和细节不清。为了解决这个问题,先前的工作尝试设计各种注意机制或增加网络的宽度(例如添加密集或残差块)。实际上,这些前述的注意机制难以从源图像中表征上下文特征。越来越复杂的模型架构可能导致对计算和内存的重要需求。因此,我们提出了一个双阶段循环融合模块,以获得高计算效率,以在多个尺度上表示足够的上下文特征。
双阶段注意力层:为了获得显著特征并保持与源图像的上下文一致性,提出了双阶段注意力层。它由最大池化操作、平均池化操作和一个无偏置的卷积层组成。对于两个图像的每个像素点,取其最大值和平均值,并将其作为卷积层的输入进行组合。设A表示双阶段注意力层, I a 和 I b I_a和I_b Ia和Ib分别表示两个输入图像,则该过程可以表示为以下方程: A ( I a , I b ) = θ A ∗ [ m a x ( I a , I b ) , a v g ( I a , I b ) ] A(I_a,I_b)=\theta_A *[max(I_a,I_b),avg(I_a,I_b)] A(Ia,Ib)=θA∗[max(Ia,Ib),avg(Ia,Ib)]
注:最大值和平均值的组合可以提供更丰富的特征表达能力。最大值可以捕捉到图像中的局部最强特征,而平均值则提供了图像的整体特征。通过将这两个值结合起来,可以综合考虑图像的局部和全局信息,从而提高特征的表达能力。
在上述公式中,*表示卷积操作, θ A θ_A θA表示我们注意力层中卷积层的参数,我们将 m a x ( I a , I b ) 和 a v g ( I a , I b ) max(I_a, I_b)和avg(I_a, I_b) max(Ia,Ib)和avg(Ia,Ib)拼接作为注意力层的输入。如图3所示,网络根据以下方程从输入图像组 { x , u , y ˉ } {\lbrace x,u,\bar{y} \rbrace} {
x,u,yˉ}计算出注意力图 σ x 和 σ y σ_x和σ_y σx和σy:
σ i r = A x ( x , u i ) σ_{ir} = A_x(x, u_i) σir=Ax(x,ui)
σ y ˉ = A y ˉ ( y ˉ , u i ) σ_{\bar{y}} = A_{\bar{y}}(\bar{y}, u_i) σyˉ=Ayˉ(yˉ,ui)
其中, A x 和 A y A_x和A_y Ax和Ay分别表示红外和可见光的注意力层, u i u_i ui表示上一次迭代的融合结果。

另外,由于双阶段注意力图的存在,我们可以更好地强调上下文特征,并且通过减小对略微失真区域(如非平滑边缘和幽灵效应)的权重,使我们的方法隐式地适应轻微对齐错误。
并行膨胀卷积层:我们开发了一组并行膨胀卷积层,以高效地从源图像中提取特征。一组具有锯齿状波形膨胀因子的膨胀卷积层可以增加感受野而不丢失相邻信息。在三条膨胀路径上,具有相同卷积核大小为3×3的卷积操作具有不同的膨胀因子。如图3所示,膨胀率分别设置为1、2、3。因此,这三条并行卷积路径的感受野分别为3×3、5×5和7×7。
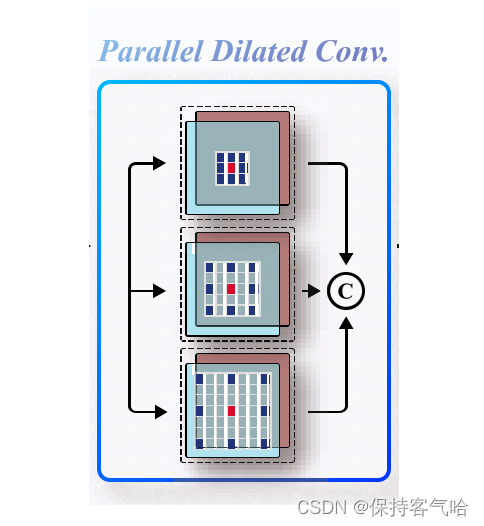
为了提供正式的描述,设 f i n i f^i_{in} fini表示第i次迭代中膨胀卷积层的输入特征图。并行膨胀卷积层的输出特征图 f o u t i f^i_{out} fouti逐步更新如下:
f o u t i = C k ( f i n i ) . k ∈ 1 , 2 , 3 , C ( f i n i ) = θ C k ∗ f i n i + b C k , f^i_{out} = {C^k(f^i_{in})}. k∈{1,2,3},C(f^i_{in}) = θ^k_C ∗ f^i_{in} + b^k_C, fouti=Ck(fini).k∈1,2,3,C(fini)=θCk∗fini+bCk,
其中 θ C k 和 b C k θ^k_C和b^k_C θCk和bCk表示膨胀率为k的卷积层的参数和偏置。
循环学习:我们提出了一种循环架构,以代替耗时的多层卷积来以逐步细化的方式从上下文信息中提取特征。通过部分重用计算图,我们可以减少构建图形的计算复杂性开销,特别适用于动态图网络框架,如PyTorch。如图4所示,与序列网络结构相比,我们在第一个用于构建图形的循环中会花费更多的时间,但在每个后续循环中,我们将节省约27%的时间。总体而言,我们的循环架构减少了约15%的时间、33%的参数和42%的GPU内存。这种循环学习使得ReCoNet能够从上下文信息中提取图像特征并满足实时标准(≥ 25fps)。由于参数和内存的减少,我们的ReCoNet可以部署在移动设备上。

3.4 Loss Functions
我们的网络的总损失函数 L t o t a l L_{total} Ltotal由两个损失项组成,即融合损失 L f u s e L_{fuse} Lfuse和配准损失 L r e g L_{reg} Lreg。融合损失确保网络生成具有更好效果和丰富信息的融合结果,而配准损失有助于限制和改进由于对齐错误引起的图像畸变。我们通过最小化以下损失函数来训练我们的网络:
L t o t a l = λ L f u s e + ( 1 − λ ) L r e g , ( 2 ) L_{total} = λL_{fuse} + (1-λ)L_{reg}, (2) Ltotal=λLfuse+(1−λ)Lreg, (2)
其中λ是一个权衡参数。
融合损失 L f u s e L_{fuse} Lfuse由两个损失项组成。结构相似性 L S S I M L_{SSIM} LSSIM用于从光线、对比度和结构信息方面保持结构的一致性,而像素损失 L p i x e l L_{pixel} Lpixel用于平衡两个源图像的像素强度。因此, L f u s e L_{fuse} Lfuse可以表示为:
L f u s e = γ L S S I M + ( 1 − γ ) L p i x e l , ( 3 ) L_{fuse} = γL_{SSIM} + (1-γ)L_{pixel}, (3) Lfuse=γLSSIM+(1−γ)Lpixel, (3)
其中γ是两个损失项的权重。具体而言,我们约束我们的融合结果与源图像具有相同的基本结构,因此LSSIM损失定义为:
L S S I M = ( 1 − S S I M ( u , x ) ) + ( 1 − S S I M ( u , y ) ) , ( 4 ) L_{SSIM} = (1 - SSIM(u, x)) + (1 - SSIM(u, y)), (4) LSSIM=(1−SSIM(u,x))+(1−SSIM(u,y)), (4)
类似地,融合结果应该平衡来自红外和可见光图像的像素强度分布,像素损失可以表示为:
L p i x e l = ∣ ∣ u − x ∣ ∣ 1 + ∣ ∣ u − y ∣ ∣ 1 , ( 5 ) L_{pixel} = ||u - x||_1 + ||u - y||_1, (5) Lpixel=∣∣u−x∣∣1+∣∣u−y∣∣1, (5)
其中∥·∥1表示 l 1 l_1 l1范数。
除此之外,配准损失 L r e g L_{reg} Lreg在纠正畸变方面也起着关键作用,可以表示为:
L r e g = η L s i m + ( 1 − η ) L s m o o t h , ( 6 ) L_{reg} = ηL_{sim} + (1-η)L_{smooth}, (6) Lreg=ηLsim+(1−η)Lsmooth, (6)
其中 L s i m L_{sim} Lsim表示相似性损失, L s m o o t h L_{smooth} Lsmooth是一个平滑损失,旨在确保生成平滑的变形。η是平衡两个项的权衡参数。
更具体地,Lsim的计算方式为:
L s i m = ∣ ∣ ϕ y ~ → y − ( − ϕ y → y ~ ) ∣ ∣ 2 2 , ( 7 ) L_{sim} = ||\phi_{\tilde{y}→y} - (-ϕ_{y→\tilde{y}})||^2_2, (7) Lsim=∣∣ϕy~→y−(−ϕy→y~)∣∣22, (7)
其中$\phi_{\tilde{y}→y} 表示变形场, 表示变形场, 表示变形场,ϕ_{y→\tilde{y}} 表示生成的随机变形场。由于我们的框架主要关注对齐后的融合效果,所以 表示生成的随机变形场。由于我们的框架主要关注对齐后的融合效果,所以 表示生成的随机变形场。由于我们的框架主要关注对齐后的融合效果,所以-ϕ_{y→\tilde{y}}$在一定程度上被用作变形场的拟合目标。在我们的循环融合机制中,引入的这些细微误差将被消除。
对于二维空间域中的每个像素p, L s m o o t h L_{smooth} Lsmooth可以具体定义为:
L s m o o t h = ∑ p ∈ Ω ∣ ∣ ∇ ϕ ( p ) ∣ ∣ 1 1 , ( 8 ) L_{smooth} = ∑_{p∈Ω}||∇ϕ(p)||^1_1, (8) Lsmooth=∑p∈Ω∣∣∇ϕ(p)∣∣11, (8)
其中∇表示使用相邻像素之间的差分近似得到的空间梯度。
4 Experiments and Results
首先,我们介绍数据集、评估指标和训练细节。然后,我们将提出的方法与八种最先进的方法(即DenseFuse 、FusionGAN 、RFN 、GANMcC、MFEIF 、PMGI 、DIDFuse 和U2Fusion )在对齐/未对齐数据集上进行比较。此外,我们还提供复杂度评估、平均意见分数分析和大量的消融实验。所有实验都在一台配备Nvidia V100 GPU的计算机上使用PyTorch进行。
4.1 Dataset and Preprocessing
数据集:我们的对齐和未对齐融合实验均在TNO和RoadScene 数据集上进行。我们通过随机使用变形场生成具有不同程度扭曲的红外图像。在每个对齐/未对齐的IVIF实验中,我们随机选择了20/180对图像及其对应的TNO/RoadScene数据集作为训练样本。
评估指标:我们采用三个现有的统计指标,包括标准差(SD)、熵(EN)和相关系数(CC),以全面评估从不同方面评估融合图像的质量。
训练细节:λ、γ和η分别设置为0.6、0.28和0.78。Adam优化器使用学习率0.001更新参数,总共进行300个epoch的训练。微注册模块 R ϕ R_ϕ Rϕ和双相循环融合模块F进行联合训练。
4.2 Results on Aligned Dataset

Qualitative Comparisons:图5展示了由不同模型生成的八个代表性融合图像。通过视觉检查,可以看出我们的方法明显优于其他比较模型。尽管其他方法实现了有意义的融合结果,但仍存在一些问题,例如热目标不清晰(参见DenseFuse、RFN和U2Fusion的图5中的绿色框),细节模糊(参见GANMcC和DIDFuse的图5中的红色框)。相反,我们的方法可以生成具有清晰目标、明显对比和丰富细节的视觉友好的融合结果。
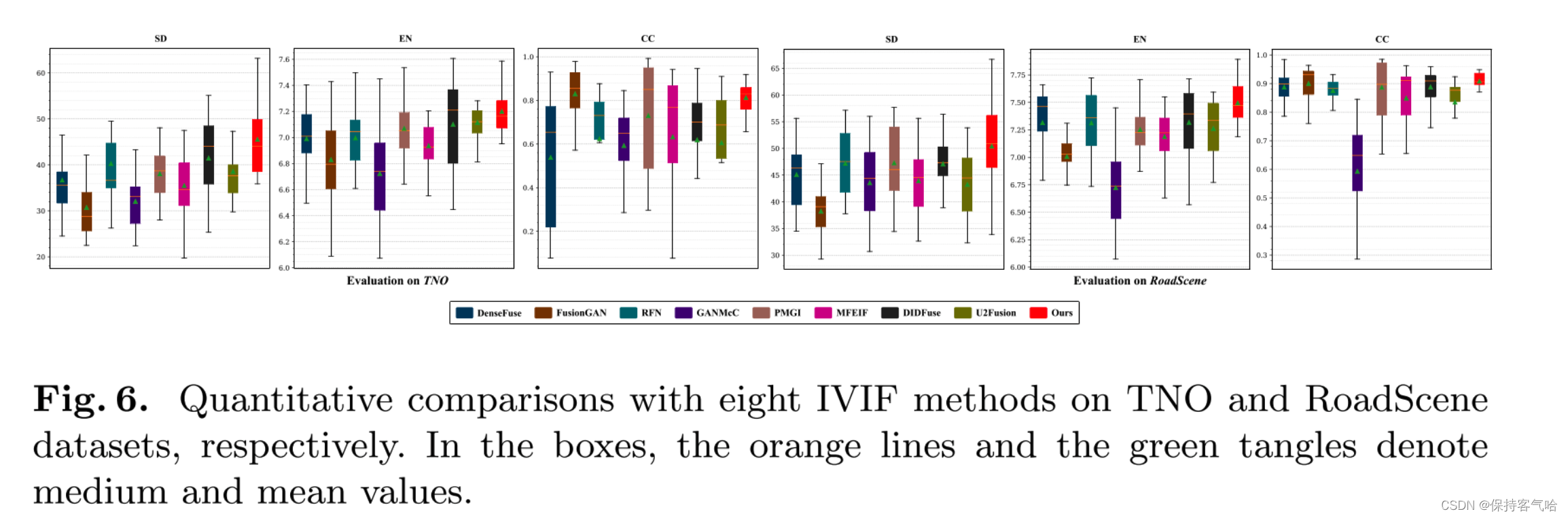
**Quantitative Comparisons: **随后,在TNO/RoadScene数据集的15/40个图像对上展示了定量结果,如图6所示。显然,我们的方法在两个指标(SD和EN)上达到最高值,其次是DIDFuse和U2Fusion。在CC指标上,我们的方法仅在TNO数据集上略微落后于FGAN。
4.3 Results on Slightly Misaligned Dataset
Qualitative Comparisons: 由于我们的方法具有处理轻微错位的图像对的能力,我们进一步在TNO和RoadScene数据集上针对其他最先进的方法进行了融合性能测试,如图7所示。显然,其他方法在融合结果中存在结构扭曲或不良的光环现象。相比之下,我们的方法在一定程度上克服了由图像对错位引起的不良伪影的局限性。这主要得益于训练过程中的结构细化和循环注意力模块。

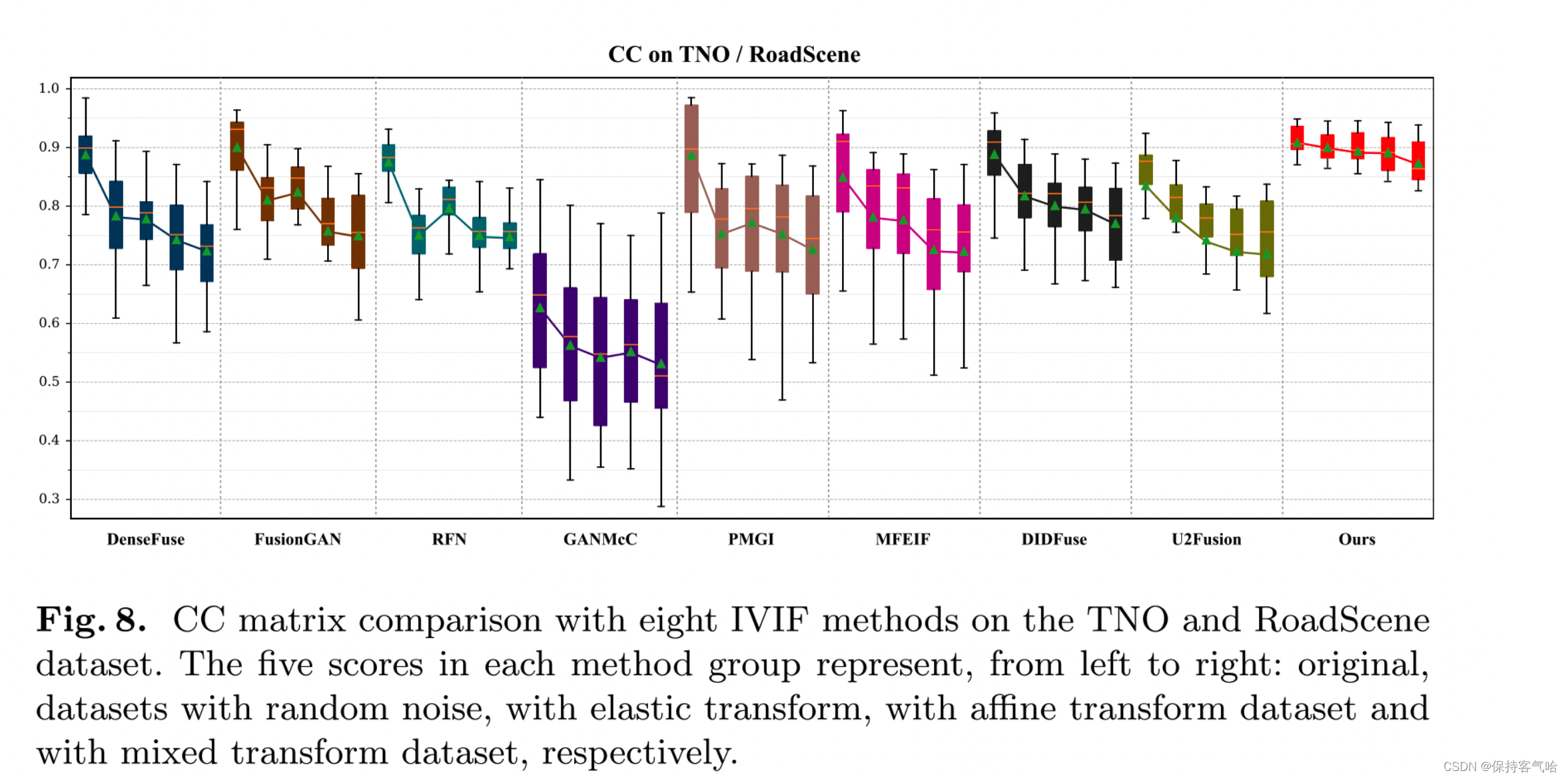
**Quantitative Comparisons: **如图8所示,我们在TNO/RoadScene数据集上评估了这些方法在选定的20张图像上的CC指标,其中包括四种不同的变换:随机噪声、弹性变换、仿射变换和混合变换。很容易注意到,随着对输入图像应用的变换,DenseFuse、PMGI、DIDFuse和U2Fusion的分数显著下降。由于MFEIF使用了注意力机制,它对随机噪声表现出一定的抵抗力。由于FusionGAN是一种基于梯度转换的方法,弹性变换对其影响不大。相反,我们的方法对所有四种变换都具有较强的处理能力。
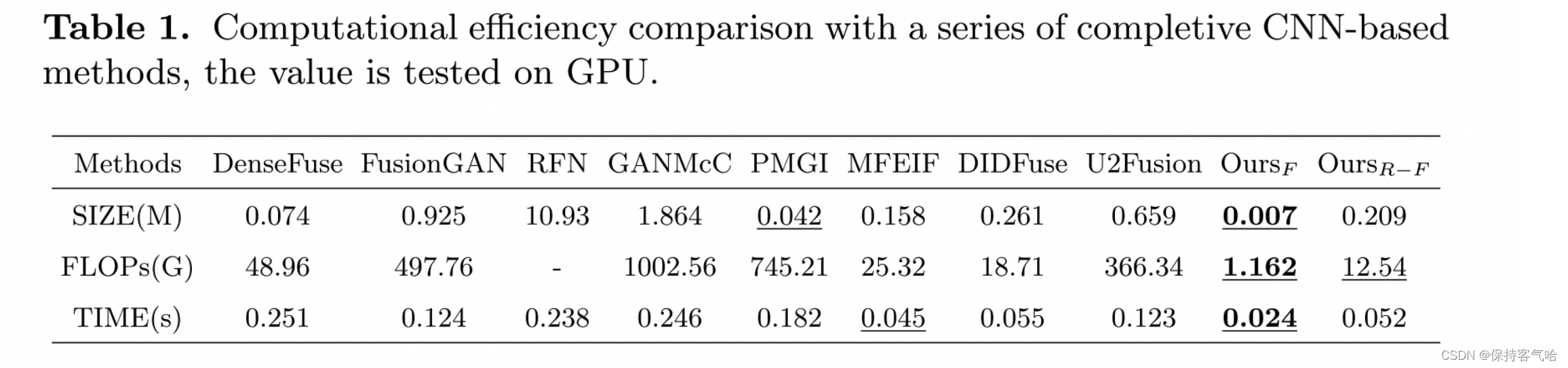
4.4 Computational Complexity Analysis
4.5 Mean Opinion Score Analysis
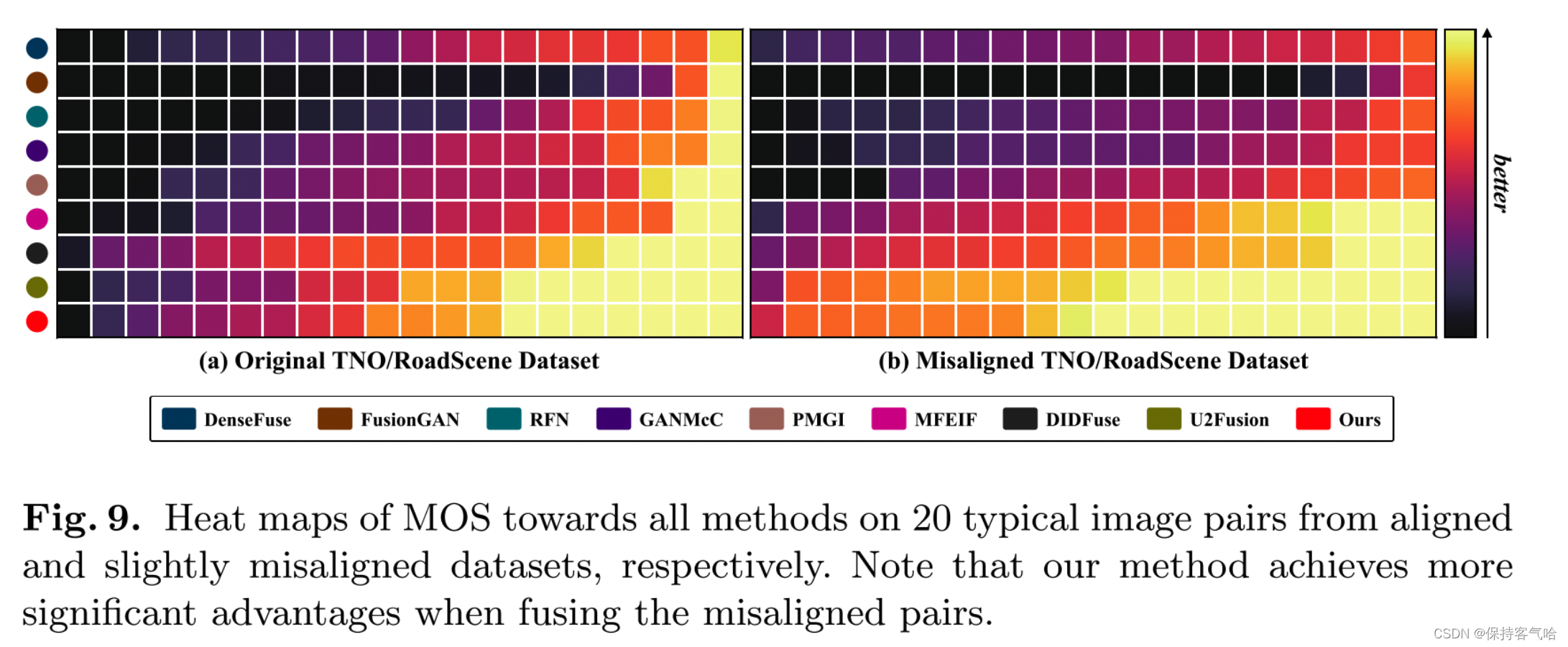
我们从每个数据集(即对齐/未对齐的TNO/RoadScene)中选择了20对典型图像进行主观实验。十位计算机视觉研究人员对融合图像的整体视觉感知、目标清晰度和细节丰富程度进行评分。图9显示了经过归一化后的所有方法的平均意见分数。值得注意的是,我们的方法在两个组别中获得了最高分,表明具有出色的视觉感知效果。
我们在对齐/未对齐的TNO/Roadscene数据集上对这八种IVIF方法进行了额外的主观实验,其中我们从每个数据集中选择了20对典型图像。通过使用三种变换方法(即仿射、弹性和二者结合)对红外图像进行变换,生成了未对齐的数据集。我们请了十位计算机视觉研究人员对融合图像从整体视觉感知、目标清晰度和细节丰富程度三个方面进行评分。图9显示了经过归一化后所有方法的排序平均意见分数(MOS),其中颜色的深浅表示得分的水平(黄色:最好,紫色:最差)。值得注意的是,我们的方法在所有测试图像对中获得了最高的得分,这表明我们的方法更符合人类视觉系统的感知。
4.6 Ablation Studies
**讨论注意力模块中的迭代:**图10展示了循环注意力学习中迭代次数对融合结果的影响。根据融合结果,我们发现随着我们的注意力模块中迭代次数的增加,融合结果往往能够达到更好的视觉效果。纹理细节和目标变得更加清晰。这主要得益于渐进式的循环注意力模块,使得每个迭代对融合结果都有积极的影响。

**去除注意力机制的消融实验:**为了验证我们的注意力模块的好处,我们选择了注意力以及相应的消融实验结果,如图11所示。我们可以发现,我们的注意力模块能够感知源图像中最具有区分性的区域(即红外图像中的目标和可见光图像中的细节),因此融合结果保留了更多有意义的信息。

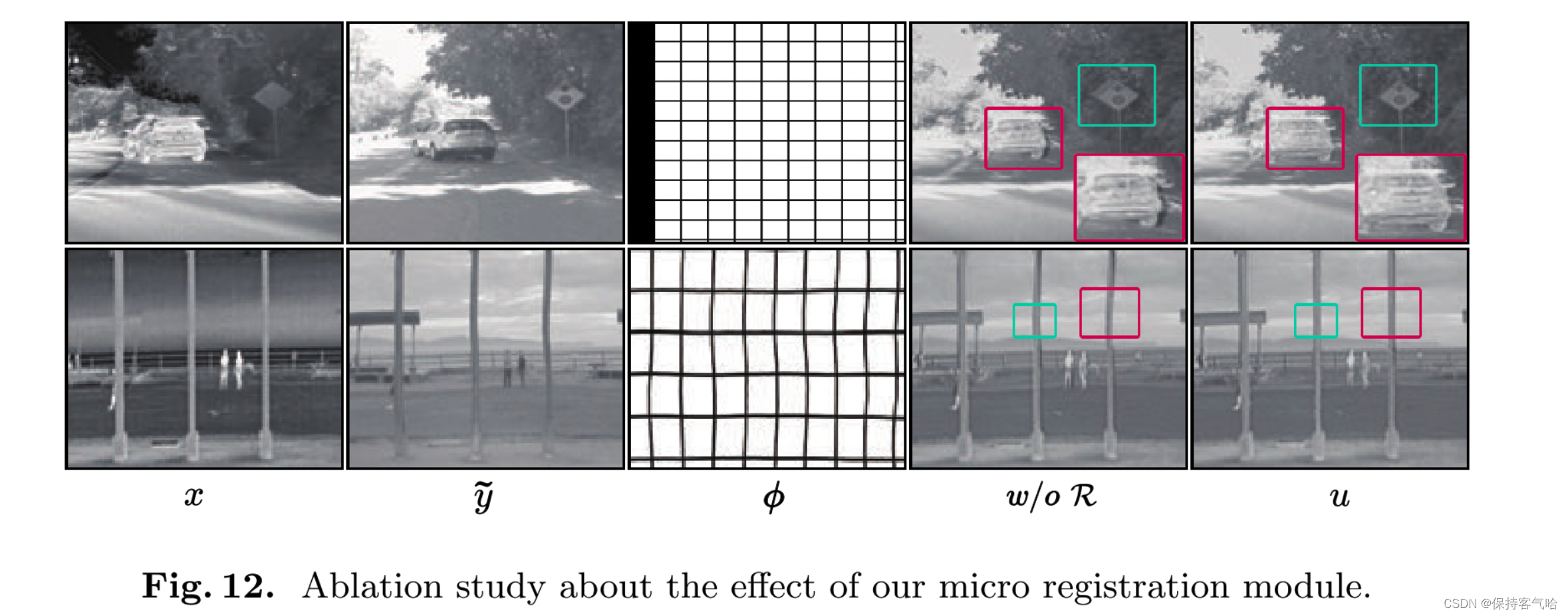
**去除可变形对齐模块的消融实验:**为了研究可变形对齐模块的效果,我们在图12中展示了带有/不带有可变形对齐模块的视觉结果。可以明显看到,在没有注意力模块的情况下,融合结果出现了不良的伪影和结构畸变(例如第二行的路标和底部行的旗杆)。相比之下,我们的方法在一定程度上可以克服伪影和结构畸变的问题。
5 Conclusion
本文提出了一种基于双相循环注意力学习的创新网络,以端到端的方式稳健高效地实现了红外和可见光图像融合。我们首先设计了一个微型注册模块来粗略估计由于图像错位引起的畸变。然后,通过双相循环学习网络成功地融合源图像并消除其他残余的伪影或伪迹。此外,我们还在循环网络中采用了并行扩张卷积和共享计算图,以实现高计算效率。主客观实验结果都表明,我们的ReCoNet在效率上具有显著优势,并且在一定程度上能够处理错位的图像对。与现有的最先进方法相比,我们的ReCoNet具有明显的优越性。