关于论文的学习笔记:Co-DETR:DETRs与协同混合分配训练论文学习笔记-CSDN博客
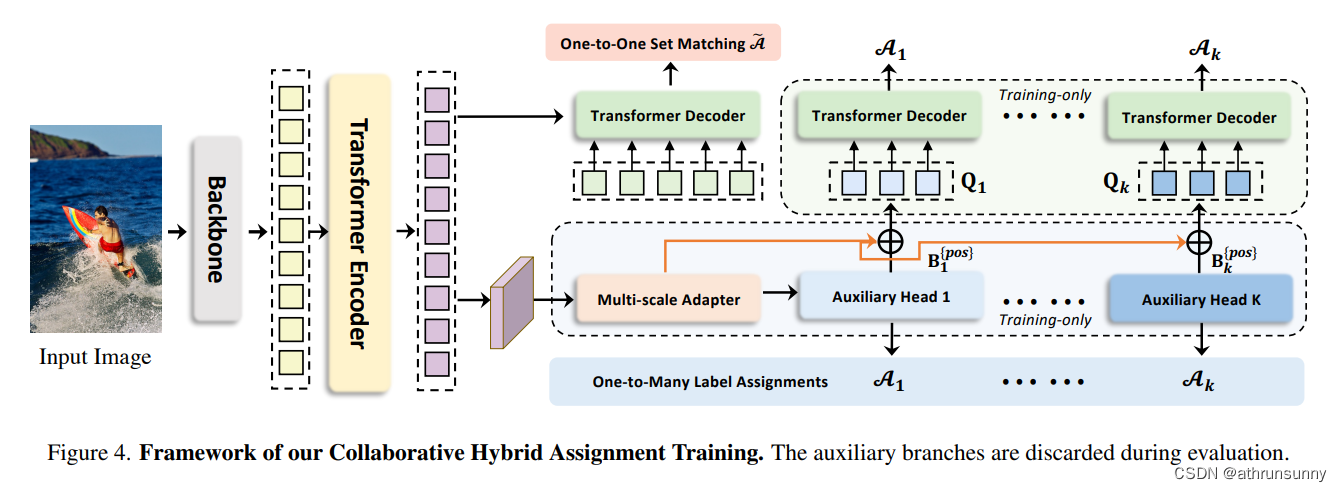
作者提出了一种新的协同混合任务训练方案,即Co-DETR,以从多种标签分配方式中学习更高效的基于detr的检测器。这种新的训练方案通过训练ATSS和Faster RCNN等一对多标签分配监督下的多个并行辅助头部,可以很容易地提高编码器在端到端检测器中的学习能力。此外,作者通过从这些辅助头部提取正坐标来进行额外的定制正查询,以提高解码器中正样本的训练效率。在推理中,这些辅助头被丢弃,因此,作者的方法不给原始检测器引入额外的参数和计算成本,同时不需要手工制作的非最大抑制(NMS)。
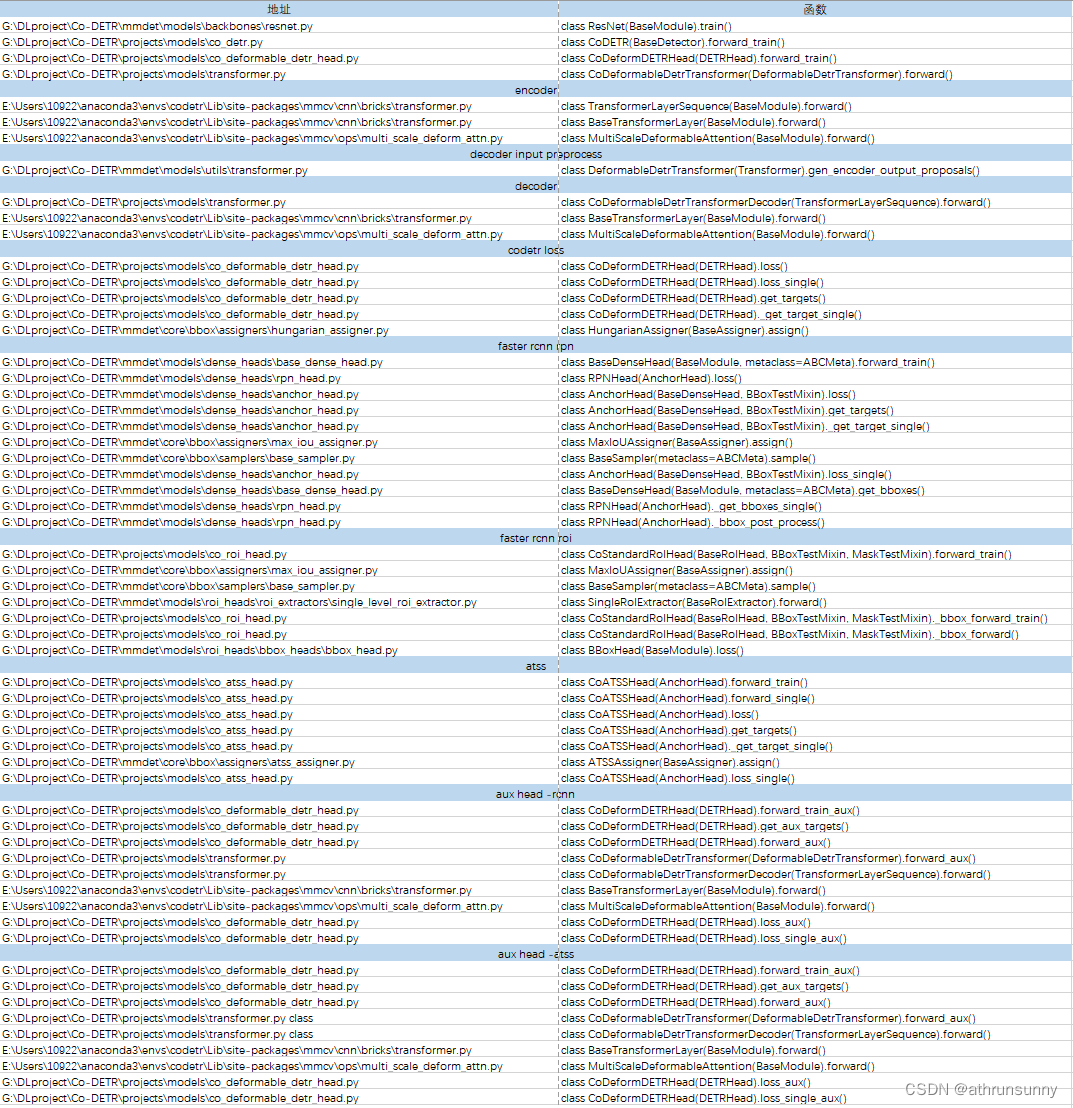
代码基于mmdetection实现,以下列了一些主要函数以及对应的路径,方便调试时对照,代码真是量大管饱,稍不留神就容易迷失在代码的海洋里。
配置文件
代码的配置文件\Co-DETR\projects\configs\co_deformable_detr\co_deformable_detr_r50_1x_coco.py
_base_ = [
'../_base_/datasets/coco_detection.py',
'../_base_/default_runtime.py'
]
# model settings
num_dec_layer = 6
lambda_2 = 2.0
model = dict(
type='CoDETR',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='ChannelMapper',
in_channels=[512, 1024, 2048],
kernel_size=1,
out_channels=256,
act_cfg=None,
norm_cfg=dict(type='GN', num_groups=32),
num_outs=4),
# faster-rcnn的辅助rpn头
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
octave_base_scale=4,
scales_per_octave=3,
ratios=[0.5, 1.0, 2.0],
strides=[8, 16, 32, 64, 128]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0*num_dec_layer*lambda_2),
loss_bbox=dict(type='L1Loss', loss_weight=1.0*num_dec_layer*lambda_2)),
query_head=dict(
type='CoDeformDETRHead',
num_query=300,
num_classes=80,
in_channels=2048,
sync_cls_avg_factor=True,
with_box_refine=True,
as_two_stage=True,
mixed_selection=True,
transformer=dict(
type='CoDeformableDetrTransformer',
num_co_heads=2, # 辅助头的设置,默认2个
encoder=dict(
type='DetrTransformerEncoder',
num_layers=6,
transformerlayers=dict(
type='BaseTransformerLayer',
attn_cfgs=dict(
type='MultiScaleDeformableAttention', embed_dims=256, dropout=0.0),
feedforward_channels=2048,
ffn_dropout=0.0,
operation_order=('self_attn', 'norm', 'ffn', 'norm'))),
decoder=dict(
type='CoDeformableDetrTransformerDecoder',
num_layers=num_dec_layer,
return_intermediate=True,
look_forward_twice=True,
transformerlayers=dict(
type='DetrTransformerDecoderLayer',
attn_cfgs=[
dict(
type='MultiheadAttention',
embed_dims=256,
num_heads=8,
dropout=0.0),
dict(
type='MultiScaleDeformableAttention',
embed_dims=256,
dropout=0.0)
],
feedforward_channels=2048,
ffn_dropout=0.0,
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm')))),
positional_encoding=dict(
type='SinePositionalEncoding',
num_feats=128,
normalize=True,
offset=-0.5),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=2.0),
loss_bbox=dict(type='L1Loss', loss_weight=5.0),
loss_iou=dict(type='GIoULoss', loss_weight=2.0)),
# faster-rcnn的辅助roi头
roi_head=[dict(
type='CoStandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[8, 16, 32, 64],
finest_scale=112),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
reg_decoded_bbox=True,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0*num_dec_layer*lambda_2),
loss_bbox=dict(type='GIoULoss', loss_weight=10.0*num_dec_layer*lambda_2)))],
# ATSS辅助头
bbox_head=[dict(
type='CoATSSHead',
num_classes=80,
in_channels=256,
stacked_convs=1,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
ratios=[1.0],
octave_base_scale=8,
scales_per_octave=1,
strides=[8, 16, 32, 64, 128]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0*num_dec_layer*lambda_2),
loss_bbox=dict(type='GIoULoss', loss_weight=2.0*num_dec_layer*lambda_2),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0*num_dec_layer*lambda_2)),],
# model training and testing settings
train_cfg=[
dict(
assigner=dict(
type='HungarianAssigner',
cls_cost=dict(type='FocalLossCost', weight=2.0),
reg_cost=dict(type='BBoxL1Cost', weight=5.0, box_format='xywh'),
iou_cost=dict(type='IoUCost', iou_mode='giou', weight=2.0))),
dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=4000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)),
dict(
assigner=dict(type='ATSSAssigner', topk=9),
allowed_border=-1,
pos_weight=-1,
debug=False),],
test_cfg=[
dict(max_per_img=100),
dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.0,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)),
dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.0,
nms=dict(type='nms', iou_threshold=0.6),
max_per_img=100),
# soft-nms is also supported for rcnn testing
# e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
])
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
# train_pipeline, NOTE the img_scale and the Pad's size_divisor is different
# from the default setting in mmdet.
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='AutoAugment',
policies=[
[
dict(
type='Resize',
img_scale=[(480, 1333), (512, 1333), (544, 1333),
(576, 1333), (608, 1333), (640, 1333),
(672, 1333), (704, 1333), (736, 1333),
(768, 1333), (800, 1333)],
multiscale_mode='value',
keep_ratio=True)
],
[
dict(
type='Resize',
# The radio of all image in train dataset < 7
# follow the original impl
img_scale=[(400, 4200), (500, 4200), (600, 4200)],
multiscale_mode='value',
keep_ratio=True),
dict(
type='RandomCrop',
crop_type='absolute_range',
crop_size=(384, 600),
allow_negative_crop=True),
dict(
type='Resize',
img_scale=[(480, 1333), (512, 1333), (544, 1333),
(576, 1333), (608, 1333), (640, 1333),
(672, 1333), (704, 1333), (736, 1333),
(768, 1333), (800, 1333)],
multiscale_mode='value',
override=True,
keep_ratio=True)
]
]),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=1),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
# test_pipeline, NOTE the Pad's size_divisor is different from the default
# setting (size_divisor=32). While there is little effect on the performance
# whether we use the default setting or use size_divisor=1.
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=1),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(filter_empty_gt=False, pipeline=train_pipeline),
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline))
# optimizer
optimizer = dict(
type='AdamW',
lr=2e-4,
weight_decay=1e-4,
paramwise_cfg=dict(
custom_keys={
'backbone': dict(lr_mult=0.1),
'sampling_offsets': dict(lr_mult=0.1),
'reference_points': dict(lr_mult=0.1)
}))
optimizer_config = dict(grad_clip=dict(max_norm=0.1, norm_type=2))
# learning policy
lr_config = dict(policy='step', step=[11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
这里使用默认的配置 co_deformable_detr_r50_1x_coco.py,默认使用2个辅助头。
Backbone
输入图像首先经过resnet得到三层的特征图,并将最后一层特征图进行下采样,得到四层特征图作为deformerable-transformer的输入。
def forward(self, x):
"""Forward function."""
if self.deep_stem:
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x)
outs = []
for i, layer_name in enumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x)
if i in self.out_indices:
outs.append(x)
return tuple(outs)
def train(self, mode=True):
"""Convert the model into training mode while keep normalization layer
freezed."""
super(ResNet, self).train(mode)
self._freeze_stages()
if mode and self.norm_eval:
for m in self.modules():
# trick: eval have effect on BatchNorm only
if isinstance(m, _BatchNorm):
m.eval()Transformer
codetr的主函数在projects\models\co_detr.py的forward_train中
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_masks=None,
proposals=None,
**kwargs):
"""
Args:
img (Tensor): of shape (N, C, H, W) encoding input images.
Typically these should be mean centered and std scaled.
img_metas (list[dict]): list of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmdet/datasets/pipelines/formatting.py:Collect`.
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
gt_masks (None | Tensor) : true segmentation masks for each box
used if the architecture supports a segmentation task.
proposals : override rpn proposals with custom proposals. Use when
`with_rpn` is False.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
batch_input_shape = tuple(img[0].size()[-2:])
for img_meta in img_metas:
img_meta['batch_input_shape'] = batch_input_shape
if not self.with_attn_mask: # remove attn mask for LSJ
for i in range(len(img_metas)):
input_img_h, input_img_w = img_metas[i]['batch_input_shape']
img_metas[i]['img_shape'] = [input_img_h, input_img_w, 3]
# 取了四层feature map,每一层的feature map最后会经过1*1的卷积进行降维[N,512/1024/2048/2048,H,W] -> [N,256,H,W],此处的H和W为对应层的feature map的尺寸 stride分别为[8,16,32,64]
x = self.extract_feat(img, img_metas) #
losses = dict()
def upd_loss(losses, idx, weight=1):
new_losses = dict()
for k,v in losses.items():
new_k = '{}{}'.format(k,idx)
if isinstance(v,list) or isinstance(v,tuple):
new_losses[new_k] = [i*weight for i in v]
else:new_losses[new_k] = v*weight
return new_losses
# DETR encoder and decoder forward
if self.with_query_head:
bbox_losses, x = self.query_head.forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
losses.update(bbox_losses)
# x: 是encoder的输出(memory)根据特征图大小的展开并对最小的特征图进行下采样 [[N 256 H W]*5]
# RPN forward and loss
if self.with_rpn:
proposal_cfg = self.train_cfg[self.head_idx].get('rpn_proposal',
self.test_cfg[self.head_idx].rpn)
rpn_losses, proposal_list = self.rpn_head.forward_train(
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=gt_bboxes_ignore,
proposal_cfg=proposal_cfg,
**kwargs)
losses.update(rpn_losses) # rpn_losses: cls loss和bbox loss proposal_list:rpn输出的经过nms后的proposal [xyxy,score] proposal shape->tuple([1000,5],[1000,5])
else:
proposal_list = proposals
positive_coords = []
for i in range(len(self.roi_head)):
roi_losses = self.roi_head[i].forward_train(x, img_metas, proposal_list,
gt_bboxes, gt_labels,
gt_bboxes_ignore, gt_masks,
**kwargs)
if self.with_pos_coord: # positive_coords =(coords, labels, targets)
positive_coords.append(roi_losses.pop('pos_coords'))
else:
if 'pos_coords' in roi_losses.keys():
tmp = roi_losses.pop('pos_coords')
roi_losses = upd_loss(roi_losses, idx=i)
losses.update(roi_losses)
# ATSS head
for i in range(len(self.bbox_head)):
bbox_losses = self.bbox_head[i].forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
if self.with_pos_coord: # pos_coords = (ori_anchors, ori_labels, ori_bbox_targets, 'atss')
pos_coords = bbox_losses.pop('pos_coords')
positive_coords.append(pos_coords)
else:
if 'pos_coords' in bbox_losses.keys():
tmp = bbox_losses.pop('pos_coords')
bbox_losses = upd_loss(bbox_losses, idx=i+len(self.roi_head))
losses.update(bbox_losses)
if self.with_pos_coord and len(positive_coords)>0:
for i in range(len(positive_coords)):
bbox_losses = self.query_head.forward_train_aux(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore, positive_coords[i], i)
bbox_losses = upd_loss(bbox_losses, idx=i)
losses.update(bbox_losses)
return lossestransformer的代码主体就是deformer-detr
主要位于projects\models\co_deformable_detr_head.py中的forward
def forward(self, mlvl_feats, img_metas):
"""Forward function.
Args:
mlvl_feats (tuple[Tensor]): Features from the upstream
network, each is a 4D-tensor with shape
(N, C, H, W).
img_metas (list[dict]): List of image information.
Returns:
all_cls_scores (Tensor): Outputs from the classification head, \
shape [nb_dec, bs, num_query, cls_out_channels]. Note \
cls_out_channels should includes background.
all_bbox_preds (Tensor): Sigmoid outputs from the regression \
head with normalized coordinate format (cx, cy, w, h). \
Shape [nb_dec, bs, num_query, 4].
enc_outputs_class (Tensor): The score of each point on encode \
feature map, has shape (N, h*w, num_class). Only when \
as_two_stage is True it would be returned, otherwise \
`None` would be returned.
enc_outputs_coord (Tensor): The proposal generate from the \
encode feature map, has shape (N, h*w, 4). Only when \
as_two_stage is True it would be returned, otherwise \
`None` would be returned.
"""
batch_size = mlvl_feats[0].size(0)
input_img_h, input_img_w = img_metas[0]['batch_input_shape']
img_masks = mlvl_feats[0].new_ones(
(batch_size, input_img_h, input_img_w))
for img_id in range(batch_size):
img_h, img_w, _ = img_metas[img_id]['img_shape']
img_masks[img_id, :img_h, :img_w] = 0
# Deformable-DETR对每一层的feature map生成对应mask,用于记录原始图像在padding图中所占的位置,原图位于padding图中的左上角
mlvl_masks = []
mlvl_positional_encodings = []
for feat in mlvl_feats:
mlvl_masks.append(
F.interpolate(img_masks[None],
size=feat.shape[-2:]).to(torch.bool).squeeze(0)) # mlvl_masks->[[N H/8 W/8],[N H/16 W/16],[N H/32 W/32],[N H/64 W/64]]
mlvl_positional_encodings.append(
self.positional_encoding(mlvl_masks[-1])) # 对每个mask层进行位置编码 mlvl_positional_encodings->[[N 256 H/8 W/8],[N 256 H/16 W/16],[N 256 H/32 W/32],[N 256 H/64 W/64]]
query_embeds = None
if not self.as_two_stage or self.mixed_selection:
query_embeds = self.query_embedding.weight # 维度为[300,256]
hs, init_reference, inter_references, \
enc_outputs_class, enc_outputs_coord, enc_outputs = self.transformer(
mlvl_feats,
mlvl_masks,
query_embeds,
mlvl_positional_encodings,
reg_branches=self.reg_branches if self.with_box_refine else None, # noqa:E501
cls_branches=self.cls_branches if self.as_two_stage else None, # noqa:E501
return_encoder_output=True
) # hs [6 300 N 256], init_reference[N 300 4], inter_references [6 N 300 4], enc_outputs_class [N C 80], enc_outputs_coord [N C 4], enc_outputs [C N 256](memory)
# hs -> inter_states:decoder每一层的输出 [6 300 N 256]
# init_reference -> init_reference_out:最初的refpoint [N 300 4]
# inter_references -> inter_references_out:每一层的输出经过Linear后得到的refpoint [6 N 300 4]
# enc_outputs_class -> enc_outputs_class:gen_encoder_output_proposals得到的output_memory(经过有效性过滤)经过Linear后得到的关于类别的输出 [N C 80]
# enc_outputs_coord -> enc_outputs_coord_unact:gen_encoder_output_proposals得到的output_memory(经过有效性过滤)经过Linear后得到的关于坐标的输出加上output_proposals [N C 4]
# enc_outputs -> memory:encoder的输出 [C N 256]
outs = []
num_level = len(mlvl_feats)
start = 0
for lvl in range(num_level):
bs, c, h, w = mlvl_feats[lvl].shape
end = start + h*w
feat = enc_outputs[start:end].permute(1, 2, 0).contiguous() # [N 256 h*w]
start = end
outs.append(feat.reshape(bs, c, h, w)) # encoder的输出根据每一层特征图长宽的展开,并存放在outs中 [[N 256 H/8 W/8],[N 256 H/16 W/16],[N 256 H/32 W/32],[N 256 H/64 W/64]]
outs.append(self.downsample(outs[-1])) # 加入对outs中最小的特征图进行3*3 stride为2的下采样 [[N 256 H/8 W/8],[N 256 H/16 W/16],[N 256 H/32 W/32],[N 256 H/64 W/64],[N 256 H/128 W/128]]
hs = hs.permute(0, 2, 1, 3)
outputs_classes = []
outputs_coords = []
# 从decoder的每一个中间层输出得到类别和bbox,并分别存放在outputs_classes和outputs_coords中
for lvl in range(hs.shape[0]):
if lvl == 0:
reference = init_reference
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference)
outputs_class = self.cls_branches[lvl](hs[lvl]) # cls_branches为Linear(256,80) [N 300 256]->[N 300 80]
tmp = self.reg_branches[lvl](hs[lvl]) #reg_branches为Linear(256,256) Linear(256,256) Linear(256,4) [N 300 256]->[N 300 4]
if reference.shape[-1] == 4:
tmp += reference
else:
assert reference.shape[-1] == 2
tmp[..., :2] += reference
outputs_coord = tmp.sigmoid()
outputs_classes.append(outputs_class) # 每一个decoder输出的class
outputs_coords.append(outputs_coord) # 每一个decoder输出的coord
outputs_classes = torch.stack(outputs_classes) # 将中间层输出的类别合并 [6 N 300 80]
outputs_coords = torch.stack(outputs_coords) # 将中间层输出的bbox合并 [6 N 300 4]
if self.as_two_stage:
return outputs_classes, outputs_coords, \
enc_outputs_class, \
enc_outputs_coord.sigmoid(), outs # outputs_classes:每一个decoder输出的class,outputs_coords:每一个decoder输出的coord(bbox),enc_outputs_class:gen_encoder_output_proposals得到的output_memory经过Linear后得到的关于类别的输出 [N C 80],enc_outputs_coord:gen_encoder_output_proposals得到的output_memory经过Linear后得到的关于坐标的输出加上output_proposals [N C 4],outs:是encoder的输出(memory)根据特征图大小的展开并对最小的特征图进行下采样
else:
return outputs_classes, outputs_coords, \
None, None, outs其中transformer的具体实现在projects\models\transformer.py的CoDeformableDetrTransformer.forward中
def forward(self,
mlvl_feats,
mlvl_masks,
query_embed,
mlvl_pos_embeds,
reg_branches=None,
cls_branches=None,
return_encoder_output=False,
attn_masks=None,
**kwargs):
"""Forward function for `Transformer`.
Args:
mlvl_feats (list(Tensor)): Input queries from
different level. Each element has shape
[bs, embed_dims, h, w].
mlvl_masks (list(Tensor)): The key_padding_mask from
different level used for encoder and decoder,
each element has shape [bs, h, w].
query_embed (Tensor): The query embedding for decoder,
with shape [num_query, c].
mlvl_pos_embeds (list(Tensor)): The positional encoding
of feats from different level, has the shape
[bs, embed_dims, h, w].
reg_branches (obj:`nn.ModuleList`): Regression heads for
feature maps from each decoder layer. Only would
be passed when
`with_box_refine` is True. Default to None.
cls_branches (obj:`nn.ModuleList`): Classification heads
for feature maps from each decoder layer. Only would
be passed when `as_two_stage`
is True. Default to None.
Returns:
tuple[Tensor]: results of decoder containing the following tensor.
- inter_states: Outputs from decoder. If
return_intermediate_dec is True output has shape \
(num_dec_layers, bs, num_query, embed_dims), else has \
shape (1, bs, num_query, embed_dims).
- init_reference_out: The initial value of reference \
points, has shape (bs, num_queries, 4).
- inter_references_out: The internal value of reference \
points in decoder, has shape \
(num_dec_layers, bs,num_query, embed_dims)
- enc_outputs_class: The classification score of \
proposals generated from \
encoder's feature maps, has shape \
(batch, h*w, num_classes). \
Only would be returned when `as_two_stage` is True, \
otherwise None.
- enc_outputs_coord_unact: The regression results \
generated from encoder's feature maps., has shape \
(batch, h*w, 4). Only would \
be returned when `as_two_stage` is True, \
otherwise None.
"""
assert self.as_two_stage or query_embed is not None
feat_flatten = []
mask_flatten = []
lvl_pos_embed_flatten = []
spatial_shapes = []
for lvl, (feat, mask, pos_embed) in enumerate(
zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)):
bs, c, h, w = feat.shape
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
feat = feat.flatten(2).transpose(1, 2) # 将H和W打平 [N,256,H,W] -> [N,H*W,256]
mask = mask.flatten(1) # [N,H,W] -> [N,H*W]
pos_embed = pos_embed.flatten(2).transpose(1, 2) # 同样将H和W打平 [N,256,H,W] -> [N,H*W,256]
lvl_pos_embed = pos_embed + self.level_embeds[lvl].view(1, 1, -1) # self.level_embed是一个nn.Parameter生成的[4,256]的tensor+每一层特征图mask生成的pos_embed
lvl_pos_embed_flatten.append(lvl_pos_embed)
feat_flatten.append(feat)
mask_flatten.append(mask)
feat_flatten = torch.cat(feat_flatten, 1) # 将打平后的tensor cat在一起 feat_flatten->[N H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64 256]
mask_flatten = torch.cat(mask_flatten, 1) # mask_flatten-> [N H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64]
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1) # lvl_pos_embed_flatten->[N H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64 256]
spatial_shapes = torch.as_tensor(
spatial_shapes, dtype=torch.long, device=feat_flatten.device) # 存放着每一层feature map的[H,W],维度为[4,2] [[H/8 W/8],[H/16 W/16],[H/32 W/32],[H/64 W/64]]
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1, )), spatial_shapes.prod(1).cumsum(0)[:-1])) # cat在一起后feature map的起始索引,如:第一层是0,第二层是H/8*W/8+0,第三层是H/16*W/16+H/8*W/8+0,最后一层H/32*W/32+H/16*W/16+H/8*W/8+0 共4维
valid_ratios = torch.stack(
[self.get_valid_ratio(m) for m in mlvl_masks], 1) # 输出一个[N,4,2]的tensor,表示每一层的feature map中对应的非padding部分的有效长宽与该层feature map长宽的比值
# C = H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64 reference_points->[N C 4 2]
reference_points = \
self.get_reference_points(spatial_shapes,
valid_ratios,
device=feat.device)
feat_flatten = feat_flatten.permute(1, 0, 2) # (H*W, bs, embed_dims)
lvl_pos_embed_flatten = lvl_pos_embed_flatten.permute(
1, 0, 2) # (H*W, bs, embed_dims)
memory = self.encoder(
query=feat_flatten,
key=None,
value=None,
query_pos=lvl_pos_embed_flatten,
query_key_padding_mask=mask_flatten,
spatial_shapes=spatial_shapes,
reference_points=reference_points,
level_start_index=level_start_index,
valid_ratios=valid_ratios,
**kwargs)
memory = memory.permute(1, 0, 2) # [C N 256]->[N C 256]
bs, _, c = memory.shape
if self.as_two_stage:
output_memory, output_proposals = \
self.gen_encoder_output_proposals(
memory, mask_flatten, spatial_shapes) # [N C 256] [N C 4]
enc_outputs_class = cls_branches[self.decoder.num_layers](
output_memory) # cls_branches为Linear(256,80) [N C 256]->[N C 80]
enc_outputs_coord_unact = \
reg_branches[
self.decoder.num_layers](output_memory) + output_proposals #reg_branches为Linear(256,256) Linear(256,256) Linear(256,4) [N C 256]->[N C 4]
topk = self.two_stage_num_proposals
topk = query_embed.shape[0] # 300
topk_proposals = torch.topk(
enc_outputs_class[..., 0], topk, dim=1)[1] # 从enc_outputs_class中取前300的query索引 [N 300]
topk_coords_unact = torch.gather(
enc_outputs_coord_unact, 1,
topk_proposals.unsqueeze(-1).repeat(1, 1, 4)) # 根据topk_proposals对enc_outputs_coord_unact进行采样 [N 300 4]
topk_coords_unact = topk_coords_unact.detach()
reference_points = topk_coords_unact.sigmoid()
init_reference_out = reference_points
pos_trans_out = self.pos_trans_norm(
self.pos_trans(self.get_proposal_pos_embed(topk_coords_unact))) # 对topk_coords_unact进行位置编码,之后Linear(512,512) 再LayerNorm 得到[N 300 512]
if not self.mixed_selection:
query_pos, query = torch.split(pos_trans_out, c, dim=2)
else:
# query_embed here is the content embed for deformable DETR
query = query_embed.unsqueeze(0).expand(bs, -1, -1) # 由nn.Embedding生成 [300,256] -> [N 300 256]
query_pos, _ = torch.split(pos_trans_out, c, dim=2) # [N 300 256]
else:
query_pos, query = torch.split(query_embed, c, dim=1)
query_pos = query_pos.unsqueeze(0).expand(bs, -1, -1)
query = query.unsqueeze(0).expand(bs, -1, -1)
reference_points = self.reference_points(query_pos).sigmoid()
init_reference_out = reference_points
# decoder
query = query.permute(1, 0, 2) # [300 N 256]
memory = memory.permute(1, 0, 2) # [C N 256]
query_pos = query_pos.permute(1, 0, 2) # [300 N 256]
inter_states, inter_references = self.decoder(
query=query,
key=None,
value=memory,
query_pos=query_pos,
key_padding_mask=mask_flatten,
reference_points=reference_points,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
valid_ratios=valid_ratios,
reg_branches=reg_branches,
attn_masks=attn_masks,
**kwargs) # inter_states [6 300 N 256], inter_references [6 N 300 4]
inter_references_out = inter_references
if self.as_two_stage:
if return_encoder_output:
return inter_states, init_reference_out,\
inter_references_out, enc_outputs_class,\
enc_outputs_coord_unact, memory
# inter_states:decoder每一层的输出 [6 300 N 256]
# init_reference_out:最初的refpoint [N 300 4]
# inter_references_out:每一层的输出经过Linear后得到的refpoint [6 N 300 4]
# enc_outputs_class:gen_encoder_output_proposals得到的output_memory(经过有效性过滤)经过Linear后得到的关于类别的输出 [N C 80]
# enc_outputs_coord_unact:gen_encoder_output_proposals得到的output_memory(经过有效性过滤)经过Linear后得到的关于坐标的输出加上output_proposals [N C 4]
# memory:encoder的输出 [C N 256]
return inter_states, init_reference_out,\
inter_references_out, enc_outputs_class,\
enc_outputs_coord_unact
if return_encoder_output:
return inter_states, init_reference_out, \
inter_references_out, None, None, memory
return inter_states, init_reference_out, \
inter_references_out, None, None这里的encoder和decoder的deformable attention在\anaconda3\envs\codetr\Lib\site-packages\mmcv\ops\multi_scale_deform_attn.py中
class MultiScaleDeformableAttention(BaseModule):
"""An attention module used in Deformable-Detr.
`Deformable DETR: Deformable Transformers for End-to-End Object Detection.
<https://arxiv.org/pdf/2010.04159.pdf>`_.
Args:
embed_dims (int): The embedding dimension of Attention.
Default: 256.
num_heads (int): Parallel attention heads. Default: 64.
num_levels (int): The number of feature map used in
Attention. Default: 4.
num_points (int): The number of sampling points for
each query in each head. Default: 4.
im2col_step (int): The step used in image_to_column.
Default: 64.
dropout (float): A Dropout layer on `inp_identity`.
Default: 0.1.
batch_first (bool): Key, Query and Value are shape of
(batch, n, embed_dim)
or (n, batch, embed_dim). Default to False.
norm_cfg (dict): Config dict for normalization layer.
Default: None.
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Default: None.
"""
def __init__(self,
embed_dims=256,
num_heads=8,
num_levels=4,
num_points=4,
im2col_step=64,
dropout=0.1,
batch_first=False,
norm_cfg=None,
init_cfg=None):
super().__init__(init_cfg)
if embed_dims % num_heads != 0:
raise ValueError(f'embed_dims must be divisible by num_heads, '
f'but got {embed_dims} and {num_heads}')
dim_per_head = embed_dims // num_heads
self.norm_cfg = norm_cfg
self.dropout = nn.Dropout(dropout)
self.batch_first = batch_first
# you'd better set dim_per_head to a power of 2
# which is more efficient in the CUDA implementation
def _is_power_of_2(n):
if (not isinstance(n, int)) or (n < 0):
raise ValueError(
'invalid input for _is_power_of_2: {} (type: {})'.format(
n, type(n)))
return (n & (n - 1) == 0) and n != 0
if not _is_power_of_2(dim_per_head):
warnings.warn(
"You'd better set embed_dims in "
'MultiScaleDeformAttention to make '
'the dimension of each attention head a power of 2 '
'which is more efficient in our CUDA implementation.')
self.im2col_step = im2col_step
self.embed_dims = embed_dims
self.num_levels = num_levels
self.num_heads = num_heads
self.num_points = num_points
self.sampling_offsets = nn.Linear(
embed_dims, num_heads * num_levels * num_points * 2)
self.attention_weights = nn.Linear(embed_dims,
num_heads * num_levels * num_points)
self.value_proj = nn.Linear(embed_dims, embed_dims)
self.output_proj = nn.Linear(embed_dims, embed_dims)
self.init_weights()
def init_weights(self):
"""Default initialization for Parameters of Module."""
constant_init(self.sampling_offsets, 0.)
thetas = torch.arange(
self.num_heads,
dtype=torch.float32) * (2.0 * math.pi / self.num_heads)
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
grid_init = (grid_init /
grid_init.abs().max(-1, keepdim=True)[0]).view(
self.num_heads, 1, 1,
2).repeat(1, self.num_levels, self.num_points, 1)
for i in range(self.num_points):
grid_init[:, :, i, :] *= i + 1
self.sampling_offsets.bias.data = grid_init.view(-1)
constant_init(self.attention_weights, val=0., bias=0.)
xavier_init(self.value_proj, distribution='uniform', bias=0.)
xavier_init(self.output_proj, distribution='uniform', bias=0.)
self._is_init = True
@deprecated_api_warning({'residual': 'identity'},
cls_name='MultiScaleDeformableAttention')
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
level_start_index=None,
**kwargs):
"""Forward Function of MultiScaleDeformAttention.
Args:
query (torch.Tensor): Query of Transformer with shape
(num_query, bs, embed_dims).
key (torch.Tensor): The key tensor with shape
`(num_key, bs, embed_dims)`.
value (torch.Tensor): The value tensor with shape
`(num_key, bs, embed_dims)`.
identity (torch.Tensor): The tensor used for addition, with the
same shape as `query`. Default None. If None,
`query` will be used.
query_pos (torch.Tensor): The positional encoding for `query`.
Default: None.
key_pos (torch.Tensor): The positional encoding for `key`. Default
None.
reference_points (torch.Tensor): The normalized reference
points with shape (bs, num_query, num_levels, 2),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
key_padding_mask (torch.Tensor): ByteTensor for `query`, with
shape [bs, num_key].
spatial_shapes (torch.Tensor): Spatial shape of features in
different levels. With shape (num_levels, 2),
last dimension represents (h, w).
level_start_index (torch.Tensor): The start index of each level.
A tensor has shape ``(num_levels, )`` and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
torch.Tensor: forwarded results with shape
[num_query, bs, embed_dims].
"""
# encoder:query shape [C N 256] 其中C=H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64 / decoder:query shape [300 N 256]
if value is None:
value = query
if identity is None:
identity = query
if query_pos is not None:
query = query + query_pos # encoder:query + lvl_pos_embed(由每层的feature map的mask生成) / decoder:query + pos_trans_out得到的query_pos
if not self.batch_first:
# change to (bs, num_query ,embed_dims)
query = query.permute(1, 0, 2) # encoder:[C N 256]->[N C 256] /decoder:[300 N 256]->[N 300 256]
value = value.permute(1, 0, 2) # encoder:[C N 256]->[N C 256] /decoder:[C N 256]->[N C 256]
bs, num_query, _ = query.shape
bs, num_value, _ = value.shape
assert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_value
value = self.value_proj(value) # Linear(256,256) [N C 256]->[N C 256]
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0) # 保留有效区域的值,非有效区域用0代替
value = value.view(bs, num_value, self.num_heads, -1) # num_heads=8 [N C 256]->[N C 8 32]
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2) # sampling_offsets为Linear(256,256) num_levels=num_points=4 # 每个query产生对应不同head不同level的偏置,sampling_offsets的shape由 encoder:[N,C,256] -> [N,C,8,4,4,2] / decoder:[N,300,256] -> [N,300,8,4,4,2]
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_levels * self.num_points) # attention_weights为Linear(256,128) 每个偏置向量的权重,经过Linear(256,128),attention_weights的shape由 encoder:[N,C,256] -> [N,C,8,16] / decoder:[N,300,256] -> [N,300,8,16]
attention_weights = attention_weights.softmax(-1)
# 对属于同一个query的来自与不同level的向量权重在每个head分别归一化,softmax后attention_weights的shape由 encoder:[N,C,8,16] -> [N,C,8,4,4] / decoder:[N,300,8,16] -> [N,300,8,4,4]
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_levels,
self.num_points)
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1) # offset_normalizer 将input_spatial_shapes中[H,W]的形式转化为[W,H]
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets \
/ offset_normalizer[None, None, None, :, None, :] # 采样点的坐标[N,C,8,4,4,2]
elif reference_points.shape[-1] == 4:
sampling_locations = reference_points[:, :, None, :, None, :2] \
+ sampling_offsets / self.num_points \
* reference_points[:, :, None, :, None, 2:] \
* 0.5 # 采样点的坐标[N,300,8,4,4,2]
else:
raise ValueError(
f'Last dim of reference_points must be'
f' 2 or 4, but get {reference_points.shape[-1]} instead.')
if torch.cuda.is_available() and value.is_cuda:
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
output = self.output_proj(output) # 输出经过一个Linear层,维度由 encoder:[N,C,256] -> [N,C,256] / decoder: [N,300,256] -> [N,300,256]
if not self.batch_first:
# (num_query, bs ,embed_dims)
output = output.permute(1, 0, 2)
return self.dropout(output) + identityloss就是匈牙利做一对一的匹配,然后加上bbox loss和cls loss以及iou loss
loss的计算过程中会对每个特征图的batch中的每个元素单独进行的,通过get_targets将batch元素拆分成一个列表
def get_targets(self,
cls_scores_list,
bbox_preds_list,
gt_bboxes_list,
gt_labels_list,
img_metas,
gt_bboxes_ignore_list=None):
""""Compute regression and classification targets for a batch image.
Outputs from a single decoder layer of a single feature level are used.
Args:
cls_scores_list (list[Tensor]): Box score logits from a single
decoder layer for each image with shape [num_query,
cls_out_channels].
bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
decoder layer for each image, with normalized coordinate
(cx, cy, w, h) and shape [num_query, 4].
gt_bboxes_list (list[Tensor]): Ground truth bboxes for each image
with shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (num_gts, ).
img_metas (list[dict]): List of image meta information.
gt_bboxes_ignore_list (list[Tensor], optional): Bounding
boxes which can be ignored for each image. Default None.
Returns:
tuple: a tuple containing the following targets.
- labels_list (list[Tensor]): Labels for all images.
- label_weights_list (list[Tensor]): Label weights for all \
images.
- bbox_targets_list (list[Tensor]): BBox targets for all \
images.
- bbox_weights_list (list[Tensor]): BBox weights for all \
images.
- num_total_pos (int): Number of positive samples in all \
images.
- num_total_neg (int): Number of negative samples in all \
images.
"""
# assert gt_bboxes_ignore_list is None, \
# 'Only supports for gt_bboxes_ignore setting to None.'
num_imgs = len(cls_scores_list) # list([300 80],[300 80])
if gt_bboxes_ignore_list is None:
gt_bboxes_ignore_list = [
gt_bboxes_ignore_list for _ in range(num_imgs)
]
# labels_list:当前batch中,值全为80的tensor在pos_inds处插入了gt_labels,其余索引处值为80 长度为bs的list(默认bs=2)
# label_weights_list:维度为[300] 值全为1 长度为bs的list
# bbox_targets_list:当前batch中,值全为[0 0 0 0]的tensor在pos_inds处插入了pos_gt_bboxes_targets,其余索引处值为[0 0 0 0] 长度为bs的list
# bbox_weights_list:bbox_weights根据pos_inds设置为1,即存在gt bbox的索引处设置为1 长度为bs的list
# pos_inds_list:正样本在匈牙利匹配中row上的索引 长度为bs的list
# neg_inds_list:负样本在匈牙利匹配中row上的索引 长度为bs的list
# 通过multi_apply对batch中每一张图的gt和pred(此处主要用在匈牙利算法中)单独处理,之后再将每个batch上的值存放在一个list中
(labels_list, label_weights_list, bbox_targets_list,
bbox_weights_list, pos_inds_list, neg_inds_list) = multi_apply(
self._get_target_single, cls_scores_list, bbox_preds_list,
gt_bboxes_list, gt_labels_list, img_metas, gt_bboxes_ignore_list)
num_total_pos = sum((inds.numel() for inds in pos_inds_list)) # 该batch中正样本的总数
num_total_neg = sum((inds.numel() for inds in neg_inds_list)) # 该batch中负样本的总数
return (labels_list, label_weights_list, bbox_targets_list,
bbox_weights_list, num_total_pos, num_total_neg)
def _get_target_single(self,
cls_score,
bbox_pred,
gt_bboxes,
gt_labels,
img_meta,
gt_bboxes_ignore=None):
""""Compute regression and classification targets for one image.
Outputs from a single decoder layer of a single feature level are used.
Args:
cls_score (Tensor): Box score logits from a single decoder layer
for one image. Shape [num_query, cls_out_channels].
bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
for one image, with normalized coordinate (cx, cy, w, h) and
shape [num_query, 4].
gt_bboxes (Tensor): Ground truth bboxes for one image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (Tensor): Ground truth class indices for one image
with shape (num_gts, ).
img_meta (dict): Meta information for one image.
gt_bboxes_ignore (Tensor, optional): Bounding boxes
which can be ignored. Default None.
Returns:
tuple[Tensor]: a tuple containing the following for one image.
- labels (Tensor): Labels of each image.
- label_weights (Tensor]): Label weights of each image.
- bbox_targets (Tensor): BBox targets of each image.
- bbox_weights (Tensor): BBox weights of each image.
- pos_inds (Tensor): Sampled positive indices for each image.
- neg_inds (Tensor): Sampled negative indices for each image.
"""
num_bboxes = bbox_pred.size(0)
ori_gt_bboxes_ignore = gt_bboxes_ignore
gt_bboxes_ignore = None
# assigner and sampler # 匈牙利匹配
assign_result = self.assigner.assign(bbox_pred, cls_score, gt_bboxes,
gt_labels, img_meta,
gt_bboxes_ignore)
sampling_result = self.sampler.sample(assign_result, bbox_pred,
gt_bboxes)
pos_inds = sampling_result.pos_inds
neg_inds = sampling_result.neg_inds
# label targets
labels = gt_bboxes.new_full((num_bboxes, ),
self.num_classes,
dtype=torch.long) # [300] 值为80
labels[pos_inds] = gt_labels[sampling_result.pos_assigned_gt_inds] # 将gt_labels按正样本col上索引排序,并按正样本row上索引插入labels
label_weights = gt_bboxes.new_ones(num_bboxes) # [300] 值为1
# bbox targets
bbox_targets = torch.zeros_like(bbox_pred) # [300 4]值为0
bbox_weights = torch.zeros_like(bbox_pred) # [300 4]值为0
bbox_weights[pos_inds] = 1.0 # bbox_weights根据正样本row上索引设置为1
img_h, img_w, _ = img_meta['img_shape']
# DETR regress the relative position of boxes (cxcywh) in the image.
# Thus the learning target should be normalized by the image size, also
# the box format should be converted from defaultly x1y1x2y2 to cxcywh.
factor = bbox_pred.new_tensor([img_w, img_h, img_w,
img_h]).unsqueeze(0)
pos_gt_bboxes_normalized = sampling_result.pos_gt_bboxes / factor # 归一化的gt bbox
pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized) # xyxy->cxcywh
bbox_targets[pos_inds] = pos_gt_bboxes_targets # 将pos_gt_bboxes_targets根据pos_inds插入bbox_targets
return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
neg_inds)
# labels,在pos_inds处插入了gt_labels,其余值为80
# label_weights,维度为[300] 值全为1
# bbox_targets,在pos_inds处插入了pos_gt_bboxes_targets,其余值为0
# bbox_weights,bbox_weights根据pos_inds设置为1
# pos_inds,正样本在匈牙利匹配中row上的索引
# neg_inds,负样本在匈牙利匹配中row上的索引之后计算loss
def loss(self,
all_cls_scores,
all_bbox_preds,
enc_cls_scores,
enc_bbox_preds,
enc_outputs,
gt_bboxes_list,
gt_labels_list,
img_metas,
gt_bboxes_ignore=None):
""""Loss function.
Args:
all_cls_scores (Tensor): Classification score of all
decoder layers, has shape
[nb_dec, bs, num_query, cls_out_channels].
all_bbox_preds (Tensor): Sigmoid regression
outputs of all decode layers. Each is a 4D-tensor with
normalized coordinate format (cx, cy, w, h) and shape
[nb_dec, bs, num_query, 4].
enc_cls_scores (Tensor): Classification scores of
points on encode feature map , has shape
(N, h*w, num_classes). Only be passed when as_two_stage is
True, otherwise is None.
enc_bbox_preds (Tensor): Regression results of each points
on the encode feature map, has shape (N, h*w, 4). Only be
passed when as_two_stage is True, otherwise is None.
gt_bboxes_list (list[Tensor]): Ground truth bboxes for each image
with shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (num_gts, ).
img_metas (list[dict]): List of image meta information.
gt_bboxes_ignore (list[Tensor], optional): Bounding boxes
which can be ignored for each image. Default None.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
# gt_bboxes_ignore = None
# assert gt_bboxes_ignore is None, \
# f'{self.__class__.__name__} only supports ' \
# f'for gt_bboxes_ignore setting to None.'
# all_cls_scores:每一个decoder输出class(6层),
# all_bbox_preds:每一个decoder输出coord(6层),
# enc_cls_scores:gen_encoder_output_proposals得到的output_memory(经过筛选)经过Linear后得到的关于类别的输出 [N C 80],
# enc_bbox_preds:gen_encoder_output_proposals得到的output_memory(经过筛选)经过Linear后得到的关于坐标的输出加上output_proposals [N C 4],
# enc_outputs:是encoder的输出(memory)根据特征图大小的展开并对最小的特征图进行下采样
num_dec_layers = len(all_cls_scores)
all_gt_bboxes_list = [gt_bboxes_list for _ in range(num_dec_layers)] # 对gt_bboxes_list复制6次,用于对应每一层decoder的输出
all_gt_labels_list = [gt_labels_list for _ in range(num_dec_layers)] # 对gt_labels_list复制6次,用于对应每一层decoder的输出
all_gt_bboxes_ignore_list = [
gt_bboxes_ignore for _ in range(num_dec_layers)
] # [None, None, None, None, None, None]
img_metas_list = [img_metas for _ in range(num_dec_layers)] # 对img_metas复制6次,
# 对GT bbox和label以及图像信息复制成长度为6的列表
losses_cls, losses_bbox, losses_iou = multi_apply(
self.loss_single, all_cls_scores, all_bbox_preds,
all_gt_bboxes_list, all_gt_labels_list, img_metas_list,
all_gt_bboxes_ignore_list)
loss_dict = dict()
# loss of proposal generated from encode feature map.
if enc_cls_scores is not None:
binary_labels_list = [
torch.zeros_like(gt_labels_list[i])
for i in range(len(img_metas))
]
enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
self.loss_single(enc_cls_scores, enc_bbox_preds,
gt_bboxes_list, binary_labels_list,
img_metas, gt_bboxes_ignore)
loss_dict['enc_loss_cls'] = enc_loss_cls
loss_dict['enc_loss_bbox'] = enc_losses_bbox
loss_dict['enc_loss_iou'] = enc_losses_iou
# loss from the last decoder layer
loss_dict['loss_cls'] = losses_cls[-1]
loss_dict['loss_bbox'] = losses_bbox[-1]
loss_dict['loss_iou'] = losses_iou[-1]
# loss from other decoder layers
num_dec_layer = 0
for loss_cls_i, loss_bbox_i, loss_iou_i in zip(losses_cls[:-1],
losses_bbox[:-1],
losses_iou[:-1]):
loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
loss_dict[f'd{num_dec_layer}.loss_bbox'] = loss_bbox_i
loss_dict[f'd{num_dec_layer}.loss_iou'] = loss_iou_i
num_dec_layer += 1
return loss_dict
def loss_single(self,
cls_scores,
bbox_preds,
gt_bboxes_list,
gt_labels_list,
img_metas,
gt_bboxes_ignore_list=None):
""""Loss function for outputs from a single decoder layer of a single
feature level.
Args:
cls_scores (Tensor): Box score logits from a single decoder layer
for all images. Shape [bs, num_query, cls_out_channels].
bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
for all images, with normalized coordinate (cx, cy, w, h) and
shape [bs, num_query, 4].
gt_bboxes_list (list[Tensor]): Ground truth bboxes for each image
with shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (num_gts, ).
img_metas (list[dict]): List of image meta information.
gt_bboxes_ignore_list (list[Tensor], optional): Bounding
boxes which can be ignored for each image. Default None.
Returns:
dict[str, Tensor]: A dictionary of loss components for outputs from
a single decoder layer.
"""
num_imgs = cls_scores.size(0)
cls_scores_list = [cls_scores[i] for i in range(num_imgs)] # cls_scores[N 300 80] 根据图像数量在batch维度拆分成每张图像对应的cls预测
bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)] # bbox_preds[N 300 4] 根据图像数量在batch维度拆分成每张图像对应的bbox预测
cls_reg_targets = self.get_targets(cls_scores_list, bbox_preds_list,
gt_bboxes_list, gt_labels_list,
img_metas, gt_bboxes_ignore_list)
(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
num_total_pos, num_total_neg) = cls_reg_targets
labels = torch.cat(labels_list, 0) # 对每张图上经过匈牙利匹配后得到的gt label合并
label_weights = torch.cat(label_weights_list, 0) # 值为1
bbox_targets = torch.cat(bbox_targets_list, 0) # 对每张图上经过匈牙利匹配后得到的gt bbox合并
bbox_weights = torch.cat(bbox_weights_list, 0) # 存在gt bbox的索引位置值为1
# classification loss
cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
# construct weighted avg_factor to match with the official DETR repo
cls_avg_factor = num_total_pos * 1.0 + \
num_total_neg * self.bg_cls_weight
if self.sync_cls_avg_factor:
cls_avg_factor = reduce_mean(
cls_scores.new_tensor([cls_avg_factor]))
cls_avg_factor = max(cls_avg_factor, 1)
loss_cls = self.loss_cls(
cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
# Compute the average number of gt boxes across all gpus, for
# normalization purposes
num_total_pos = loss_cls.new_tensor([num_total_pos])
num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
# construct factors used for rescale bboxes
factors = []
for img_meta, bbox_pred in zip(img_metas, bbox_preds):
img_h, img_w, _ = img_meta['img_shape']
factor = bbox_pred.new_tensor([img_w, img_h, img_w,
img_h]).unsqueeze(0).repeat(
bbox_pred.size(0), 1)
factors.append(factor)
factors = torch.cat(factors, 0) # bbox scale 用于将bbox从归一化坐标恢复到图像坐标
# DETR regress the relative position of boxes (cxcywh) in the image,
# thus the learning target is normalized by the image size. So here
# we need to re-scale them for calculating IoU loss
bbox_preds = bbox_preds.reshape(-1, 4)
bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
# regression IoU loss, defaultly GIoU loss
loss_iou = self.loss_iou(
bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
# regression L1 loss
loss_bbox = self.loss_bbox(
bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
return loss_cls, loss_bbox, loss_iouRPN head
# RPN forward and loss
if self.with_rpn:
proposal_cfg = self.train_cfg[self.head_idx].get('rpn_proposal',
self.test_cfg[self.head_idx].rpn)
rpn_losses, proposal_list = self.rpn_head.forward_train(
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=gt_bboxes_ignore,
proposal_cfg=proposal_cfg,
**kwargs)
losses.update(rpn_losses) # rpn_losses: cls loss和bbox loss proposal_list:rpn输出的经过nms后的proposal [xyxy,score] proposal shape->tuple([1000,5],[1000,5])
else:
proposal_list = proposals
positive_coords = []
for i in range(len(self.roi_head)):
roi_losses = self.roi_head[i].forward_train(x, img_metas, proposal_list,
gt_bboxes, gt_labels,
gt_bboxes_ignore, gt_masks,
**kwargs)
if self.with_pos_coord: # positive_coords =(coords, labels, targets)
positive_coords.append(roi_losses.pop('pos_coords'))
else:
if 'pos_coords' in roi_losses.keys():
tmp = roi_losses.pop('pos_coords')
roi_losses = upd_loss(roi_losses, idx=i)
losses.update(roi_losses)RPNHead(
(loss_cls): CrossEntropyLoss(avg_non_ignore=False)
(loss_bbox): L1Loss()
(rpn_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(rpn_cls): Conv2d(256, 9, kernel_size=(1, 1), stride=(1, 1))
(rpn_reg): Conv2d(256, 36, kernel_size=(1, 1), stride=(1, 1))
)
init_cfg={'type': 'Normal', 'layer': 'Conv2d', 'std': 0.01}
这里就是faster rcnn的主体了,其中输入的x是之前encoder输出的query根据每一层特征图的展开,并对最后一层的特征图进行下采样,得到五层特征图,作为faster rcnn中rpn head的输入
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
"""
Args:
x (list[Tensor]): Features from FPN.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used
Returns:
tuple:
losses: (dict[str, Tensor]): A dictionary of loss components.
proposal_list (list[Tensor]): Proposals of each image.
"""
outs = self(x) # outs是一个tuple类型,存放两个list元素,第一个list存放rpn_cls_score, 第二个list存放rpn_bbox_pred
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas) # outs与gt bbox和图像信息合并
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore) # 计算bbox loss(l1 loss)和cls loss(CE loss)
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(
*outs, img_metas=img_metas, cfg=proposal_cfg)
return losses, proposal_list对rpn的输出求cls loss和bbox loss(L1 loss)
def loss_single(self, cls_score, bbox_pred, anchors, labels, label_weights,
bbox_targets, bbox_weights, num_total_samples):
"""Compute loss of a single scale level.
Args:
cls_score (Tensor): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W).
bbox_pred (Tensor): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W).
anchors (Tensor): Box reference for each scale level with shape
(N, num_total_anchors, 4).
labels (Tensor): Labels of each anchors with shape
(N, num_total_anchors).
label_weights (Tensor): Label weights of each anchor with shape
(N, num_total_anchors)
bbox_targets (Tensor): BBox regression targets of each anchor
weight shape (N, num_total_anchors, 4).
bbox_weights (Tensor): BBox regression loss weights of each anchor
with shape (N, num_total_anchors, 4).
num_total_samples (int): If sampling, num total samples equal to
the number of total anchors; Otherwise, it is the number of
positive anchors.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
# classification loss
labels = labels.reshape(-1)
label_weights = label_weights.reshape(-1)
cls_score = cls_score.permute(0, 2, 3,
1).reshape(-1, self.cls_out_channels)
loss_cls = self.loss_cls(
cls_score, labels, label_weights, avg_factor=num_total_samples)
# regression loss
bbox_targets = bbox_targets.reshape(-1, 4)
bbox_weights = bbox_weights.reshape(-1, 4)
bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
if self.reg_decoded_bbox:
# When the regression loss (e.g. `IouLoss`, `GIouLoss`)
# is applied directly on the decoded bounding boxes, it
# decodes the already encoded coordinates to absolute format.
anchors = anchors.reshape(-1, 4)
bbox_pred = self.bbox_coder.decode(anchors, bbox_pred)
loss_bbox = self.loss_bbox(
bbox_pred,
bbox_targets,
bbox_weights,
avg_factor=num_total_samples)
return loss_cls, loss_bbox
@force_fp32(apply_to=('cls_scores', 'bbox_preds'))
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss. Default: None
Returns:
dict[str, Tensor]: A dictionary of loss components.
""" # RPN 的cls 和bbox loss
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores] # 每一层feature map的尺寸
assert len(featmap_sizes) == self.prior_generator.num_levels
device = cls_scores[0].device
# anchor_list: 每个特征图上生成的anchor valid_flag_list: 有效区域的标识符,用于判断anchor是否在图像的有效区域内
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_metas, device=device)
label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
cls_reg_targets = self.get_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
gt_bboxes_ignore_list=gt_bboxes_ignore,
gt_labels_list=gt_labels,
label_channels=label_channels)
if cls_reg_targets is None:
return None
(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
num_total_pos, num_total_neg) = cls_reg_targets
num_total_samples = (
num_total_pos + num_total_neg if self.sampling else num_total_pos)
# anchor number of multi levels
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
# concat all level anchors and flags to a single tensor
concat_anchor_list = []
for i in range(len(anchor_list)):
concat_anchor_list.append(torch.cat(anchor_list[i]))
all_anchor_list = images_to_levels(concat_anchor_list,
num_level_anchors) # 将已经合并的anchor按特征图层级展开
losses_cls, losses_bbox = multi_apply(
self.loss_single,
cls_scores,
bbox_preds,
all_anchor_list,
labels_list,
label_weights_list,
bbox_targets_list,
bbox_weights_list,
num_total_samples=num_total_samples)
return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)rpn head会得到对应的proposal
def get_bboxes(self,
cls_scores, # rpn预测的类别(前背景)
bbox_preds, # rpn预测的bbox
score_factors=None,
img_metas=None,
cfg=None, # {'nms_pre': 4000, 'max_per_img': 1000, 'nms': {'type': 'nms', 'iou_threshold': 0.7}, 'min_bbox_size': 0}
rescale=False,
with_nms=True,
**kwargs):
"""Transform network outputs of a batch into bbox results.
Note: When score_factors is not None, the cls_scores are
usually multiplied by it then obtain the real score used in NMS,
such as CenterNess in FCOS, IoU branch in ATSS.
Args:
cls_scores (list[Tensor]): Classification scores for all
scale levels, each is a 4D-tensor, has shape
(batch_size, num_priors * num_classes, H, W).
bbox_preds (list[Tensor]): Box energies / deltas for all
scale levels, each is a 4D-tensor, has shape
(batch_size, num_priors * 4, H, W).
score_factors (list[Tensor], Optional): Score factor for
all scale level, each is a 4D-tensor, has shape
(batch_size, num_priors * 1, H, W). Default None.
img_metas (list[dict], Optional): Image meta info. Default None.
cfg (mmcv.Config, Optional): Test / postprocessing configuration,
if None, test_cfg would be used. Default None.
rescale (bool): If True, return boxes in original image space.
Default False.
with_nms (bool): If True, do nms before return boxes.
Default True.
Returns:
list[list[Tensor, Tensor]]: Each item in result_list is 2-tuple.
The first item is an (n, 5) tensor, where the first 4 columns
are bounding box positions (tl_x, tl_y, br_x, br_y) and the
5-th column is a score between 0 and 1. The second item is a
(n,) tensor where each item is the predicted class label of
the corresponding box.
"""
assert len(cls_scores) == len(bbox_preds)
if score_factors is None:
# e.g. Retina, FreeAnchor, Foveabox, etc.
with_score_factors = False
else:
# e.g. FCOS, PAA, ATSS, AutoAssign, etc.
with_score_factors = True
assert len(cls_scores) == len(score_factors)
num_levels = len(cls_scores)
featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
mlvl_priors = self.prior_generator.grid_priors(
featmap_sizes,
dtype=cls_scores[0].dtype,
device=cls_scores[0].device) # 每一层的anchor
result_list = []
for img_id in range(len(img_metas)):
img_meta = img_metas[img_id]
cls_score_list = select_single_mlvl(cls_scores, img_id)
bbox_pred_list = select_single_mlvl(bbox_preds, img_id)
if with_score_factors:
score_factor_list = select_single_mlvl(score_factors, img_id)
else:
score_factor_list = [None for _ in range(num_levels)] # [None, None, None, None, None]
results = self._get_bboxes_single(cls_score_list, bbox_pred_list,
score_factor_list, mlvl_priors,
img_meta, cfg, rescale, with_nms,
**kwargs)
result_list.append(results)
return result_list # tuple([1000,5],[1000,5])ROI head
roi head对rpn中的proposal提取roi,此处roi通过iou进行匹配
ModuleList(
(0): CoStandardRoIHead(
(bbox_roi_extractor): SingleRoIExtractor(
(roi_layers): ModuleList(
(0): RoIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=0, pool_mode=avg, aligned=True, use_torchvision=False)
(1): RoIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=0, pool_mode=avg, aligned=True, use_torchvision=False)
(2): RoIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=0, pool_mode=avg, aligned=True, use_torchvision=False)
(3): RoIAlign(output_size=(7, 7), spatial_scale=0.015625, sampling_ratio=0, pool_mode=avg, aligned=True, use_torchvision=False)
)
)
(bbox_head): Shared2FCBBoxHead(
(loss_cls): CrossEntropyLoss(avg_non_ignore=False)
(loss_bbox): GIoULoss()
(fc_cls): Linear(in_features=1024, out_features=81, bias=True)
(fc_reg): Linear(in_features=1024, out_features=320, bias=True)
(shared_convs): ModuleList()
(shared_fcs): ModuleList(
(0): Linear(in_features=12544, out_features=1024, bias=True)
(1): Linear(in_features=1024, out_features=1024, bias=True)
)
(cls_convs): ModuleList()
(cls_fcs): ModuleList()
(reg_convs): ModuleList()
(reg_fcs): ModuleList()
(relu): ReLU(inplace=True)
)
init_cfg=[{'type': 'Normal', 'std': 0.01, 'override': {'name': 'fc_cls'}}, {'type': 'Normal', 'std': 0.001, 'override': {'name': 'fc_reg'}}, {'type': 'Xavier', 'distribution': 'uniform', 'override': [{'name': 'shared_fcs'}, {'name': 'cls_fcs'}, {'name': 'reg_fcs'}]}]
)
)
class CoStandardRoIHead(BaseRoIHead, BBoxTestMixin, MaskTestMixin):
"""Simplest base roi head including one bbox head and one mask head."""
def forward_train(self,
x,
img_metas,
proposal_list,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_masks=None,
**kwargs):
"""
Args:
x (list[Tensor]): list of multi-level img features.
img_metas (list[dict]): list of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmdet/datasets/pipelines/formatting.py:Collect`.
proposals (list[Tensors]): list of region proposals.
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
gt_masks (None | Tensor) : true segmentation masks for each box
used if the architecture supports a segmentation task.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
# assign gts and sample proposals
if self.with_bbox or self.with_mask:
num_imgs = len(img_metas)
if gt_bboxes_ignore is None:
gt_bboxes_ignore = [None for _ in range(num_imgs)] # [None, None]
sampling_results = []
for i in range(num_imgs):
assign_result = self.bbox_assigner.assign(
proposal_list[i], gt_bboxes[i], gt_bboxes_ignore[i],
gt_labels[i])
sampling_result = self.bbox_sampler.sample(
assign_result,
proposal_list[i],
gt_bboxes[i],
gt_labels[i],
feats=[lvl_feat[i][None] for lvl_feat in x])
sampling_results.append(sampling_result)
losses = dict()
# bbox head forward and loss
if self.with_bbox:
bbox_results = self._bbox_forward_train(x, sampling_results,
gt_bboxes, gt_labels,
img_metas)
losses.update(bbox_results['loss_bbox'])
bbox_targets = bbox_results['bbox_targets']
num_imgs = len(img_metas)
max_proposal = 2000
for res in sampling_results:
max_proposal = min(max_proposal, res.bboxes.shape[0])
ori_coords = bbox2roi([res.bboxes for res in sampling_results])
ori_proposals, ori_labels, ori_bbox_targets, ori_bbox_feats = [], [], [], []
for i in range(num_imgs):
idx = (ori_coords[:,0]==i).nonzero().squeeze(1)
idx = idx[:max_proposal]
ori_proposal = ori_coords[idx][:, 1:].unsqueeze(0)
ori_label = bbox_targets[0][idx].unsqueeze(0)
ori_bbox_target = bbox_targets[2][idx].unsqueeze(0)
ori_bbox_feat = bbox_results['bbox_feats'].mean(-1).mean(-1)
ori_bbox_feat = ori_bbox_feat[idx].unsqueeze(0)
ori_proposals.append(ori_proposal)
ori_labels.append(ori_label)
ori_bbox_targets.append(ori_bbox_target)
ori_bbox_feats.append(ori_bbox_feat)
ori_coords = torch.cat(ori_proposals, dim=0)
ori_labels = torch.cat(ori_labels, dim=0)
ori_bbox_targets = torch.cat(ori_bbox_targets, dim=0)
ori_bbox_feats = torch.cat(ori_bbox_feats, dim=0)
pos_coords = (ori_coords, ori_labels, ori_bbox_targets, ori_bbox_feats, 'rcnn')
losses.update(pos_coords=pos_coords)
# mask head forward and loss
if self.with_mask:
mask_results = self._mask_forward_train(x, sampling_results,
bbox_results['bbox_feats'],
gt_masks, img_metas)
losses.update(mask_results['loss_mask'])
return losses
def _bbox_forward(self, x, rois):
"""Box head forward function used in both training and testing."""
# TODO: a more flexible way to decide which feature maps to use
bbox_feats = self.bbox_roi_extractor(
x[:self.bbox_roi_extractor.num_inputs], rois) # x[:4] bbox_feats [1024 256 7 7]
if self.with_shared_head:
bbox_feats = self.shared_head(bbox_feats)
cls_score, bbox_pred = self.bbox_head(bbox_feats) # cls_score[1024 81] bbox_pred[1024 320]
bbox_results = dict(
cls_score=cls_score, bbox_pred=bbox_pred, bbox_feats=bbox_feats)
return bbox_results
def _bbox_forward_train(self, x, sampling_results, gt_bboxes, gt_labels,
img_metas):
"""Run forward function and calculate loss for box head in training."""
rois = bbox2roi([res.bboxes for res in sampling_results])
bbox_results = self._bbox_forward(x, rois)
bbox_targets = self.bbox_head.get_targets(sampling_results, gt_bboxes,
gt_labels, self.train_cfg)
loss_bbox = self.bbox_head.loss(bbox_results['cls_score'],
bbox_results['bbox_pred'], rois,
*bbox_targets)
bbox_results.update(loss_bbox=loss_bbox)
bbox_results.update(bbox_targets=bbox_targets)
return bbox_results对提取的roi区域进行ROIAlign
class SingleRoIExtractor(BaseRoIExtractor):
"""Extract RoI features from a single level feature map.
If there are multiple input feature levels, each RoI is mapped to a level
according to its scale. The mapping rule is proposed in
`FPN <https://arxiv.org/abs/1612.03144>`_.
Args:
roi_layer (dict): Specify RoI layer type and arguments.
out_channels (int): Output channels of RoI layers.
featmap_strides (List[int]): Strides of input feature maps.
finest_scale (int): Scale threshold of mapping to level 0. Default: 56.
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None
"""
def __init__(self,
roi_layer,
out_channels,
featmap_strides,
finest_scale=56,
init_cfg=None):
super(SingleRoIExtractor, self).__init__(roi_layer, out_channels,
featmap_strides, init_cfg)
self.finest_scale = finest_scale
def map_roi_levels(self, rois, num_levels):
"""Map rois to corresponding feature levels by scales.
- scale < finest_scale * 2: level 0
- finest_scale * 2 <= scale < finest_scale * 4: level 1
- finest_scale * 4 <= scale < finest_scale * 8: level 2
- scale >= finest_scale * 8: level 3
Args:
rois (Tensor): Input RoIs, shape (k, 5).
num_levels (int): Total level number.
Returns:
Tensor: Level index (0-based) of each RoI, shape (k, )
"""
scale = torch.sqrt(
(rois[:, 3] - rois[:, 1]) * (rois[:, 4] - rois[:, 2])) # roi区域面积的0.5次方
target_lvls = torch.floor(torch.log2(scale / self.finest_scale + 1e-6))
target_lvls = target_lvls.clamp(min=0, max=num_levels - 1).long() # 限制在0-3的范围内
return target_lvls
@force_fp32(apply_to=('feats', ), out_fp16=True)
def forward(self, feats, rois, roi_scale_factor=None):
"""Forward function."""
out_size = self.roi_layers[0].output_size
num_levels = len(feats) # feats为memory reshape后前四层的特征图
expand_dims = (-1, self.out_channels * out_size[0] * out_size[1])
if torch.onnx.is_in_onnx_export():
# Work around to export mask-rcnn to onnx
roi_feats = rois[:, :1].clone().detach()
roi_feats = roi_feats.expand(*expand_dims)
roi_feats = roi_feats.reshape(-1, self.out_channels, *out_size)
roi_feats = roi_feats * 0
else:
roi_feats = feats[0].new_zeros(
rois.size(0), self.out_channels, *out_size) # 创建roi feat [1024 256 7 7]
# TODO: remove this when parrots supports
if torch.__version__ == 'parrots':
roi_feats.requires_grad = True
if num_levels == 1:
if len(rois) == 0:
return roi_feats
return self.roi_layers[0](feats[0], rois)
target_lvls = self.map_roi_levels(rois, num_levels)
if roi_scale_factor is not None:
rois = self.roi_rescale(rois, roi_scale_factor)
for i in range(num_levels):
mask = target_lvls == i
if torch.onnx.is_in_onnx_export():
# To keep all roi_align nodes exported to onnx
# and skip nonzero op
mask = mask.float().unsqueeze(-1)
# select target level rois and reset the rest rois to zero.
rois_i = rois.clone().detach()
rois_i = rois_i * mask
mask_exp = mask.expand(*expand_dims).reshape(roi_feats.shape)
roi_feats_t = self.roi_layers[i](feats[i], rois_i)
roi_feats_t = roi_feats_t * mask_exp
roi_feats = roi_feats + roi_feats_t
continue
inds = mask.nonzero(as_tuple=False).squeeze(1)
if inds.numel() > 0:
rois_ = rois[inds]
roi_feats_t = self.roi_layers[i](feats[i], rois_) # roialign
roi_feats[inds] = roi_feats_t
else:
# Sometimes some pyramid levels will not be used for RoI
# feature extraction and this will cause an incomplete
# computation graph in one GPU, which is different from those
# in other GPUs and will cause a hanging error.
# Therefore, we add it to ensure each feature pyramid is
# included in the computation graph to avoid runtime bugs.
roi_feats = roi_feats + sum(
x.view(-1)[0]
for x in self.parameters()) * 0. + feats[i].sum() * 0.
return roi_featsroi head输出ori_coords, ori_labels, ori_bbox_targets, ori_bbox_feats, 'rcnn'
ATSS head
# ATSS head
for i in range(len(self.bbox_head)):
bbox_losses = self.bbox_head[i].forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
if self.with_pos_coord: # pos_coords = (ori_anchors, ori_labels, ori_bbox_targets, 'atss')
pos_coords = bbox_losses.pop('pos_coords')
positive_coords.append(pos_coords)
else:
if 'pos_coords' in bbox_losses.keys():
tmp = bbox_losses.pop('pos_coords')
bbox_losses = upd_loss(bbox_losses, idx=i+len(self.roi_head))
losses.update(bbox_losses)CoATSSHead(
(loss_cls): FocalLoss()
(loss_bbox): GIoULoss()
(relu): ReLU(inplace=True)
(cls_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
)
(reg_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
)
(atss_cls): Conv2d(256, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(atss_reg): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(atss_centerness): Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(scales): ModuleList(
(0): Scale()
(1): Scale()
(2): Scale()
(3): Scale()
(4): Scale()
)
(loss_centerness): CrossEntropyLoss(avg_non_ignore=False)
)
init_cfg={'type': 'Normal', 'layer': 'Conv2d', 'std': 0.01, 'override': {'type': 'Normal', 'name': 'atss_cls', 'std': 0.01, 'bias_prob': 0.01}}
逻辑上来说就是,在每层特征图上,取每个锚框的中心点与GT中心点计算最短L2距离,并且根据距离最短的中心点取锚框与GT的最大iou的topk个锚框作为正样本,然后动态设置io阈值
class CoATSSHead(AnchorHead):
"""Bridging the Gap Between Anchor-based and Anchor-free Detection via
Adaptive Training Sample Selection.
ATSS head structure is similar with FCOS, however ATSS use anchor boxes
and assign label by Adaptive Training Sample Selection instead max-iou.
https://arxiv.org/abs/1912.02424
"""
def __init__(self,
num_classes,
in_channels,
stacked_convs=4,
conv_cfg=None,
norm_cfg=dict(type='GN', num_groups=32, requires_grad=True),
reg_decoded_bbox=True,
loss_centerness=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0),
init_cfg=dict(
type='Normal',
layer='Conv2d',
std=0.01,
override=dict(
type='Normal',
name='atss_cls',
std=0.01,
bias_prob=0.01)),
**kwargs):
self.stacked_convs = stacked_convs
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
super(CoATSSHead, self).__init__(
num_classes,
in_channels,
reg_decoded_bbox=reg_decoded_bbox,
init_cfg=init_cfg,
**kwargs)
self.sampling = False
if self.train_cfg:
self.assigner = build_assigner(self.train_cfg.assigner)
# SSD sampling=False so use PseudoSampler
sampler_cfg = dict(type='PseudoSampler')
self.sampler = build_sampler(sampler_cfg, context=self)
self.loss_centerness = build_loss(loss_centerness)
def _init_layers(self):
"""Initialize layers of the head."""
self.relu = nn.ReLU(inplace=True)
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
self.cls_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg))
self.reg_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg))
self.atss_cls = nn.Conv2d(
self.feat_channels,
self.num_anchors * self.cls_out_channels,
3,
padding=1)
self.atss_reg = nn.Conv2d(
self.feat_channels, self.num_base_priors * 4, 3, padding=1)
self.atss_centerness = nn.Conv2d(
self.feat_channels, self.num_base_priors * 1, 3, padding=1)
self.scales = nn.ModuleList(
[Scale(1.0) for _ in self.prior_generator.strides])
def forward(self, feats):
"""Forward features from the upstream network.
Args:
feats (tuple[Tensor]): Features from the upstream network, each is
a 4D-tensor.
Returns:
tuple: Usually a tuple of classification scores and bbox prediction
cls_scores (list[Tensor]): Classification scores for all scale
levels, each is a 4D-tensor, the channels number is
num_anchors * num_classes.
bbox_preds (list[Tensor]): Box energies / deltas for all scale
levels, each is a 4D-tensor, the channels number is
num_anchors * 4.
"""
return multi_apply(self.forward_single, feats, self.scales)
def forward_single(self, x, scale):
"""Forward feature of a single scale level.
Args:
x (Tensor): Features of a single scale level.
scale (:obj: `mmcv.cnn.Scale`): Learnable scale module to resize
the bbox prediction.
Returns:
tuple:
cls_score (Tensor): Cls scores for a single scale level
the channels number is num_anchors * num_classes.
bbox_pred (Tensor): Box energies / deltas for a single scale
level, the channels number is num_anchors * 4.
centerness (Tensor): Centerness for a single scale level, the
channel number is (N, num_anchors * 1, H, W).
"""
cls_feat = x
reg_feat = x
for cls_conv in self.cls_convs:
cls_feat = cls_conv(cls_feat)
for reg_conv in self.reg_convs:
reg_feat = reg_conv(reg_feat)
cls_score = self.atss_cls(cls_feat) # [N 80 H W]
# we just follow atss, not apply exp in bbox_pred
bbox_pred = scale(self.atss_reg(reg_feat)).float() # [N 4 H W]
centerness = self.atss_centerness(reg_feat) # [N 1 H W]
return cls_score, bbox_pred, centerness
def loss_single(self, anchors, cls_score, bbox_pred, centerness, labels,
label_weights, bbox_targets, img_metas, num_total_samples):
"""Compute loss of a single scale level.
Args:
cls_score (Tensor): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W).
bbox_pred (Tensor): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W).
anchors (Tensor): Box reference for each scale level with shape
(N, num_total_anchors, 4).
labels (Tensor): Labels of each anchors with shape
(N, num_total_anchors).
label_weights (Tensor): Label weights of each anchor with shape
(N, num_total_anchors)
bbox_targets (Tensor): BBox regression targets of each anchor
weight shape (N, num_total_anchors, 4).
num_total_samples (int): Number os positive samples that is
reduced over all GPUs.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
anchors = anchors.reshape(-1, 4)
cls_score = cls_score.permute(0, 2, 3, 1).reshape(
-1, self.cls_out_channels).contiguous()
bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
centerness = centerness.permute(0, 2, 3, 1).reshape(-1)
bbox_targets = bbox_targets.reshape(-1, 4)
labels = labels.reshape(-1)
label_weights = label_weights.reshape(-1)
# classification loss
loss_cls = self.loss_cls(
cls_score, labels, label_weights, avg_factor=num_total_samples)
# FG cat_id: [0, num_classes -1], BG cat_id: num_classes
bg_class_ind = self.num_classes
pos_inds = ((labels >= 0)
& (labels < bg_class_ind)).nonzero().squeeze(1)
if len(pos_inds) > 0:
pos_bbox_targets = bbox_targets[pos_inds]
pos_bbox_pred = bbox_pred[pos_inds]
pos_anchors = anchors[pos_inds]
pos_centerness = centerness[pos_inds]
centerness_targets = self.centerness_target(
pos_anchors, pos_bbox_targets)
pos_decode_bbox_pred = self.bbox_coder.decode(
pos_anchors, pos_bbox_pred)
# regression loss
loss_bbox = self.loss_bbox(
pos_decode_bbox_pred,
pos_bbox_targets,
weight=centerness_targets,
avg_factor=1.0)
# centerness loss
loss_centerness = self.loss_centerness(
pos_centerness,
centerness_targets,
avg_factor=num_total_samples)
else:
loss_bbox = bbox_pred.sum() * 0
loss_centerness = centerness.sum() * 0
centerness_targets = bbox_targets.new_tensor(0.)
return loss_cls, loss_bbox, loss_centerness, centerness_targets.sum()
@force_fp32(apply_to=('cls_scores', 'bbox_preds', 'centernesses'))
def loss(self,
cls_scores,
bbox_preds,
centernesses,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
centernesses (list[Tensor]): Centerness for each scale
level with shape (N, num_anchors * 1, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (list[Tensor] | None): specify which bounding
boxes can be ignored when computing the loss.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores] # 得到每层feature map的尺寸
assert len(featmap_sizes) == self.prior_generator.num_levels
device = cls_scores[0].device
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_metas, device=device)
label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
cls_reg_targets = self.get_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
gt_bboxes_ignore_list=gt_bboxes_ignore,
gt_labels_list=gt_labels,
label_channels=label_channels)
if cls_reg_targets is None:
return None
(anchor_list, labels_list, label_weights_list, bbox_targets_list,
bbox_weights_list, num_total_pos, num_total_neg,
ori_anchors, ori_labels, ori_bbox_targets) = cls_reg_targets
num_total_samples = reduce_mean(
torch.tensor(num_total_pos, dtype=torch.float,
device=device)).item()
num_total_samples = max(num_total_samples, 1.0)
new_img_metas = [img_metas for _ in range(len(anchor_list))]
losses_cls, losses_bbox, loss_centerness,\
bbox_avg_factor = multi_apply(
self.loss_single,
anchor_list,
cls_scores,
bbox_preds,
centernesses,
labels_list,
label_weights_list,
bbox_targets_list,
new_img_metas,
num_total_samples=num_total_samples)
bbox_avg_factor = sum(bbox_avg_factor)
bbox_avg_factor = reduce_mean(bbox_avg_factor).clamp_(min=1).item()
losses_bbox = list(map(lambda x: x / bbox_avg_factor, losses_bbox))
pos_coords = (ori_anchors, ori_labels, ori_bbox_targets, 'atss')
return dict(
loss_cls=losses_cls,
loss_bbox=losses_bbox,
loss_centerness=loss_centerness,
pos_coords=pos_coords)
def centerness_target(self, anchors, gts):
# only calculate pos centerness targets, otherwise there may be nan
anchors_cx = (anchors[:, 2] + anchors[:, 0]) / 2
anchors_cy = (anchors[:, 3] + anchors[:, 1]) / 2
l_ = anchors_cx - gts[:, 0]
t_ = anchors_cy - gts[:, 1]
r_ = gts[:, 2] - anchors_cx
b_ = gts[:, 3] - anchors_cy
left_right = torch.stack([l_, r_], dim=1)
top_bottom = torch.stack([t_, b_], dim=1)
centerness = torch.sqrt(
(left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) *
(top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0]))
assert not torch.isnan(centerness).any()
return centerness
def get_targets(self,
anchor_list,
valid_flag_list,
gt_bboxes_list,
img_metas,
gt_bboxes_ignore_list=None,
gt_labels_list=None,
label_channels=1,
unmap_outputs=True):
"""Get targets for ATSS head.
This method is almost the same as `AnchorHead.get_targets()`. Besides
returning the targets as the parent method does, it also returns the
anchors as the first element of the returned tuple.
"""
num_imgs = len(img_metas)
assert len(anchor_list) == len(valid_flag_list) == num_imgs
# anchor number of multi levels
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
num_level_anchors_list = [num_level_anchors] * num_imgs
# concat all level anchors and flags to a single tensor
for i in range(num_imgs):
assert len(anchor_list[i]) == len(valid_flag_list[i])
anchor_list[i] = torch.cat(anchor_list[i])
valid_flag_list[i] = torch.cat(valid_flag_list[i])
# compute targets for each image
if gt_bboxes_ignore_list is None:
gt_bboxes_ignore_list = [None for _ in range(num_imgs)]
if gt_labels_list is None:
gt_labels_list = [None for _ in range(num_imgs)]
(all_anchors, all_labels, all_label_weights, all_bbox_targets,
all_bbox_weights, pos_inds_list, neg_inds_list) = multi_apply(
self._get_target_single,
anchor_list,
valid_flag_list,
num_level_anchors_list,
gt_bboxes_list,
gt_bboxes_ignore_list,
gt_labels_list,
img_metas,
label_channels=label_channels,
unmap_outputs=unmap_outputs)
# no valid anchors
if any([labels is None for labels in all_labels]):
return None
# sampled anchors of all images
num_total_pos = sum([max(inds.numel(), 1) for inds in pos_inds_list])
num_total_neg = sum([max(inds.numel(), 1) for inds in neg_inds_list])
# split targets to a list w.r.t. multiple levels
ori_anchors = all_anchors
ori_labels = all_labels
ori_bbox_targets = all_bbox_targets
anchors_list = images_to_levels(all_anchors, num_level_anchors)
labels_list = images_to_levels(all_labels, num_level_anchors)
label_weights_list = images_to_levels(all_label_weights,
num_level_anchors)
bbox_targets_list = images_to_levels(all_bbox_targets,
num_level_anchors)
bbox_weights_list = images_to_levels(all_bbox_weights,
num_level_anchors)
return (anchors_list, labels_list, label_weights_list,
bbox_targets_list, bbox_weights_list, num_total_pos,
num_total_neg, ori_anchors, ori_labels, ori_bbox_targets)
def _get_target_single(self,
flat_anchors,
valid_flags,
num_level_anchors,
gt_bboxes,
gt_bboxes_ignore,
gt_labels,
img_meta,
label_channels=1,
unmap_outputs=True):
"""Compute regression, classification targets for anchors in a single
image.
Args:
flat_anchors (Tensor): Multi-level anchors of the image, which are
concatenated into a single tensor of shape (num_anchors ,4)
valid_flags (Tensor): Multi level valid flags of the image,
which are concatenated into a single tensor of
shape (num_anchors,).
num_level_anchors Tensor): Number of anchors of each scale level.
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
img_meta (dict): Meta info of the image.
label_channels (int): Channel of label.
unmap_outputs (bool): Whether to map outputs back to the original
set of anchors.
Returns:
tuple: N is the number of total anchors in the image.
labels (Tensor): Labels of all anchors in the image with shape
(N,).
label_weights (Tensor): Label weights of all anchor in the
image with shape (N,).
bbox_targets (Tensor): BBox targets of all anchors in the
image with shape (N, 4).
bbox_weights (Tensor): BBox weights of all anchors in the
image with shape (N, 4)
pos_inds (Tensor): Indices of positive anchor with shape
(num_pos,).
neg_inds (Tensor): Indices of negative anchor with shape
(num_neg,).
"""
inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
img_meta['img_shape'][:2],
self.train_cfg.allowed_border)
if not inside_flags.any():
return (None, ) * 7
# assign gt and sample anchors
anchors = flat_anchors[inside_flags, :]
num_level_anchors_inside = self.get_num_level_anchors_inside(
num_level_anchors, inside_flags) # 每层特征图上对应的有效anchor的数量
assign_result = self.assigner.assign(anchors, num_level_anchors_inside,
gt_bboxes, gt_bboxes_ignore,
gt_labels)
sampling_result = self.sampler.sample(assign_result, anchors,
gt_bboxes)
num_valid_anchors = anchors.shape[0]
bbox_targets = torch.zeros_like(anchors)
bbox_weights = torch.zeros_like(anchors)
labels = anchors.new_full((num_valid_anchors, ),
self.num_classes,
dtype=torch.long)
label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
pos_inds = sampling_result.pos_inds
neg_inds = sampling_result.neg_inds
if len(pos_inds) > 0:
if self.reg_decoded_bbox:
pos_bbox_targets = sampling_result.pos_gt_bboxes
else:
pos_bbox_targets = self.bbox_coder.encode(
sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
bbox_targets[pos_inds, :] = pos_bbox_targets
bbox_weights[pos_inds, :] = 1.0
if gt_labels is None:
# Only rpn gives gt_labels as None
# Foreground is the first class since v2.5.0
labels[pos_inds] = 0
else:
labels[pos_inds] = gt_labels[
sampling_result.pos_assigned_gt_inds]
if self.train_cfg.pos_weight <= 0:
label_weights[pos_inds] = 1.0
else:
label_weights[pos_inds] = self.train_cfg.pos_weight
if len(neg_inds) > 0:
label_weights[neg_inds] = 1.0
# map up to original set of anchors
if unmap_outputs:
num_total_anchors = flat_anchors.size(0)
anchors = unmap(anchors, num_total_anchors, inside_flags)
labels = unmap(
labels, num_total_anchors, inside_flags, fill=self.num_classes)
label_weights = unmap(label_weights, num_total_anchors,
inside_flags)
bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
return (anchors, labels, label_weights, bbox_targets, bbox_weights,
pos_inds, neg_inds)
def get_num_level_anchors_inside(self, num_level_anchors, inside_flags):
split_inside_flags = torch.split(inside_flags, num_level_anchors)
num_level_anchors_inside = [
int(flags.sum()) for flags in split_inside_flags
]
return num_level_anchors_inside # 确定每层特征图上对应的有效anchor的数量
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
"""
Args:
x (list[Tensor]): Features from FPN.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used
Returns:
tuple:
losses: (dict[str, Tensor]): A dictionary of loss components.
proposal_list (list[Tensor]): Proposals of each image.
"""
outs = self(x) # tuple [0]存放五层feature map得到的CLS [1]存放五层feature map得到的BBOX [2]存放五层feature map得到的CENTER
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(
*outs, img_metas=img_metas, cfg=proposal_cfg)
return losses, proposal_list辅助头
辅助头就是对faster rcnn和atss中输出的预测编码成query在输入到decoder中,并计算loss
# aux head
if self.with_pos_coord and len(positive_coords)>0:
for i in range(len(positive_coords)):
bbox_losses = self.query_head.forward_train_aux(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore, positive_coords[i], i)
bbox_losses = upd_loss(bbox_losses, idx=i)
losses.update(bbox_losses) def forward_aux(self, mlvl_feats, img_metas, aux_targets, head_idx):
"""Forward function.
Args:
mlvl_feats (tuple[Tensor]): Features from the upstream
network, each is a 4D-tensor with shape
(N, C, H, W).
img_metas (list[dict]): List of image information.
Returns:
all_cls_scores (Tensor): Outputs from the classification head, \
shape [nb_dec, bs, num_query, cls_out_channels]. Note \
cls_out_channels should includes background.
all_bbox_preds (Tensor): Sigmoid outputs from the regression \
head with normalized coordinate format (cx, cy, w, h). \
Shape [nb_dec, bs, num_query, 4].
enc_outputs_class (Tensor): The score of each point on encode \
feature map, has shape (N, h*w, num_class). Only when \
as_two_stage is True it would be returned, otherwise \
`None` would be returned.
enc_outputs_coord (Tensor): The proposal generate from the \
encode feature map, has shape (N, h*w, 4). Only when \
as_two_stage is True it would be returned, otherwise \
`None` would be returned.
"""
aux_coords, aux_labels, aux_targets, aux_label_weights, aux_bbox_weights, aux_feats, attn_masks = aux_targets
batch_size = mlvl_feats[0].size(0)
input_img_h, input_img_w = img_metas[0]['batch_input_shape']
img_masks = mlvl_feats[0].new_ones(
(batch_size, input_img_h, input_img_w))
for img_id in range(batch_size):
img_h, img_w, _ = img_metas[img_id]['img_shape']
img_masks[img_id, :img_h, :img_w] = 0
mlvl_masks = []
mlvl_positional_encodings = []
for feat in mlvl_feats:
mlvl_masks.append(
F.interpolate(img_masks[None],
size=feat.shape[-2:]).to(torch.bool).squeeze(0))
mlvl_positional_encodings.append(
self.positional_encoding(mlvl_masks[-1]))
query_embeds = None
hs, init_reference, inter_references = self.transformer.forward_aux(
mlvl_feats,
mlvl_masks,
query_embeds,
mlvl_positional_encodings,
aux_coords,
pos_feats=aux_feats,
reg_branches=self.reg_branches if self.with_box_refine else None, # noqa:E501
cls_branches=self.cls_branches if self.as_two_stage else None, # noqa:E501
return_encoder_output=True,
attn_masks=attn_masks,
head_idx=head_idx
)
hs = hs.permute(0, 2, 1, 3)
outputs_classes = []
outputs_coords = []
for lvl in range(hs.shape[0]):
if lvl == 0:
reference = init_reference
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference)
outputs_class = self.cls_branches[lvl](hs[lvl])
tmp = self.reg_branches[lvl](hs[lvl])
if reference.shape[-1] == 4:
tmp += reference
else:
assert reference.shape[-1] == 2
tmp[..., :2] += reference
outputs_coord = tmp.sigmoid()
outputs_classes.append(outputs_class)
outputs_coords.append(outputs_coord)
outputs_classes = torch.stack(outputs_classes)
outputs_coords = torch.stack(outputs_coords)
return outputs_classes, outputs_coords, \
None, None其中transformer的部分
def forward_aux(self,
mlvl_feats,
mlvl_masks,
query_embed,
mlvl_pos_embeds,
pos_anchors,
pos_feats=None,
reg_branches=None,
cls_branches=None,
return_encoder_output=False,
attn_masks=None,
head_idx=0,
**kwargs):
feat_flatten = []
mask_flatten = []
spatial_shapes = []
for lvl, (feat, mask, pos_embed) in enumerate(
zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)):
bs, c, h, w = feat.shape
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
feat = feat.flatten(2).transpose(1, 2)
mask = mask.flatten(1)
feat_flatten.append(feat)
mask_flatten.append(mask)
feat_flatten = torch.cat(feat_flatten, 1)
mask_flatten = torch.cat(mask_flatten, 1)
spatial_shapes = torch.as_tensor(
spatial_shapes, dtype=torch.long, device=feat_flatten.device)
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))
valid_ratios = torch.stack(
[self.get_valid_ratio(m) for m in mlvl_masks], 1)
feat_flatten = feat_flatten.permute(1, 0, 2) # (H*W, bs, embed_dims)
memory = feat_flatten
memory = memory.permute(1, 0, 2)
bs, _, c = memory.shape
topk = pos_anchors.shape[1]
topk_coords_unact = inverse_sigmoid((pos_anchors))
reference_points = pos_anchors
init_reference_out = reference_points
if self.num_co_heads > 0:
pos_trans_out = self.aux_pos_trans_norm[head_idx](
self.aux_pos_trans[head_idx](self.get_proposal_pos_embed(topk_coords_unact)))
query_pos, query = torch.split(pos_trans_out, c, dim=2)
if self.with_coord_feat:
query = query + self.pos_feats_norm[head_idx](self.pos_feats_trans[head_idx](pos_feats))
query_pos = query_pos + self.head_pos_embed.weight[head_idx]
# decoder
query = query.permute(1, 0, 2)
memory = memory.permute(1, 0, 2)
query_pos = query_pos.permute(1, 0, 2)
inter_states, inter_references = self.decoder(
query=query,
key=None,
value=memory,
query_pos=query_pos,
key_padding_mask=mask_flatten,
reference_points=reference_points,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
valid_ratios=valid_ratios,
reg_branches=reg_branches,
attn_masks=attn_masks,
**kwargs)
inter_references_out = inter_references
return inter_states, init_reference_out, \
inter_references_out这里的feature是之前encoder的输出
计算loss时就不再用匈牙利算法进行匹配了,因为这些query已经是预测得到的结果
def loss_single_aux(self,
cls_scores,
bbox_preds,
labels,
label_weights,
bbox_targets,
bbox_weights,
img_metas,
gt_bboxes_ignore_list=None):
""""Loss function for outputs from a single decoder layer of a single
feature level.
Args:
cls_scores (Tensor): Box score logits from a single decoder layer
for all images. Shape [bs, num_query, cls_out_channels].
bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
for all images, with normalized coordinate (cx, cy, w, h) and
shape [bs, num_query, 4].
gt_bboxes_list (list[Tensor]): Ground truth bboxes for each image
with shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (num_gts, ).
img_metas (list[dict]): List of image meta information.
gt_bboxes_ignore_list (list[Tensor], optional): Bounding
boxes which can be ignored for each image. Default None.
Returns:
dict[str, Tensor]: A dictionary of loss components for outputs from
a single decoder layer.
"""
num_imgs = cls_scores.size(0)
num_q = cls_scores.size(1)
try:
labels = labels.reshape(num_imgs * num_q)
label_weights = label_weights.reshape(num_imgs * num_q)
bbox_targets = bbox_targets.reshape(num_imgs * num_q, 4)
bbox_weights = bbox_weights.reshape(num_imgs * num_q, 4)
except:
return cls_scores.mean()*0, cls_scores.mean()*0, cls_scores.mean()*0
bg_class_ind = self.num_classes
num_total_pos = len(((labels >= 0) & (labels < bg_class_ind)).nonzero().squeeze(1))
num_total_neg = num_imgs*num_q - num_total_pos
# classification loss
cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
# construct weighted avg_factor to match with the official DETR repo
cls_avg_factor = num_total_pos * 1.0 + \
num_total_neg * self.bg_cls_weight
if self.sync_cls_avg_factor:
cls_avg_factor = reduce_mean(
cls_scores.new_tensor([cls_avg_factor]))
cls_avg_factor = max(cls_avg_factor, 1)
loss_cls = self.loss_cls(
cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
# Compute the average number of gt boxes across all gpus, for
# normalization purposes
num_total_pos = loss_cls.new_tensor([num_total_pos])
num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
# construct factors used for rescale bboxes
factors = []
for img_meta, bbox_pred in zip(img_metas, bbox_preds):
img_h, img_w, _ = img_meta['img_shape']
factor = bbox_pred.new_tensor([img_w, img_h, img_w,
img_h]).unsqueeze(0).repeat(
bbox_pred.size(0), 1)
factors.append(factor)
factors = torch.cat(factors, 0)
# DETR regress the relative position of boxes (cxcywh) in the image,
# thus the learning target is normalized by the image size. So here
# we need to re-scale them for calculating IoU loss
bbox_preds = bbox_preds.reshape(-1, 4)
bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
# regression IoU loss, defaultly GIoU loss
loss_iou = self.loss_iou(
bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
# regression L1 loss
loss_bbox = self.loss_bbox(
bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
return loss_cls*self.lambda_1, loss_bbox*self.lambda_1, loss_iou*self.lambda_1