代码地址:GitHub - IDEA-Research/DN-DETR: [CVPR 2022 Oral]Official implementation of DN-DETR
论文地址: https://arxiv.org/pdf/2203.01305.pdf
DN-DETR是在DAB-DETR的基础上完成的,DN-DETR的作者认为导致DETR类模型收敛慢的原因在于匈牙利匹配所导致的二意性,即匈牙利算法匹配的离散性和模型训练的随机性,导致ground-truth的匹配变成了一个动态的、不稳定的过程。举个例子,在epoch=8時,1号预测框与2号真实框匹配,但到了epoch=9時,5号预测框与2号真实框相匹配。这种不确定性将会导致模型在前期要消耗大量的资源来学习特征(损失函数的计算是对通过匈牙利算法匹配上的预测框与真实框来进行计算,而匹配的不稳定性自然会使其学习困难)
一、backbone
backbone和DETR是一样的,也是仅仅取了最后一层的输出,将该输出作为encoder的输入,具体的可以参看DETR代码学习笔记(一)
二、prepare
先从DN-DETR的主函数开始(按代码顺序来):
本文中假设输入的图像尺寸为800*800,输出的feature map大小为800//32=25
class DABDETR(nn.Module):
""" This is the DAB-DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries,
aux_loss=False,
iter_update=True,
query_dim=4,
bbox_embed_diff_each_layer=False,
random_refpoints_xy=False,
):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
Conditional DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
iter_update: iterative update of boxes
query_dim: query dimension. 2 for point and 4 for box.
bbox_embed_diff_each_layer: dont share weights of prediction heads. Default for False. (shared weights.)
random_refpoints_xy: random init the x,y of anchor boxes and freeze them. (It sometimes helps to improve the performance)
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
self.hidden_dim = hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes)
self.bbox_embed_diff_each_layer = bbox_embed_diff_each_layer
# leave one dim for indicator
self.label_enc = nn.Embedding(num_classes + 1, hidden_dim - 1)
self.num_classes = num_classes
if bbox_embed_diff_each_layer:
self.bbox_embed = nn.ModuleList([MLP(hidden_dim, hidden_dim, 4, 3) for i in range(6)])
else:
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
# setting query dim
self.query_dim = query_dim
assert query_dim in [2, 4]
self.refpoint_embed = nn.Embedding(num_queries, query_dim)
self.random_refpoints_xy = random_refpoints_xy
if random_refpoints_xy:
# import ipdb; ipdb.set_trace()
self.refpoint_embed.weight.data[:, :2].uniform_(0,1)
self.refpoint_embed.weight.data[:, :2] = inverse_sigmoid(self.refpoint_embed.weight.data[:, :2])
self.refpoint_embed.weight.data[:, :2].requires_grad = False
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
self.iter_update = iter_update
if self.iter_update:
self.transformer.decoder.bbox_embed = self.bbox_embed
# init prior_prob setting for focal loss
prior_prob = 0.01
bias_value = -math.log((1 - prior_prob) / prior_prob)
self.class_embed.bias.data = torch.ones(num_classes) * bias_value
# import ipdb; ipdb.set_trace()
# init bbox_embed
if bbox_embed_diff_each_layer:
for bbox_embed in self.bbox_embed:
nn.init.constant_(bbox_embed.layers[-1].weight.data, 0)
nn.init.constant_(bbox_embed.layers[-1].bias.data, 0)
else:
nn.init.constant_(self.bbox_embed.layers[-1].weight.data, 0)
nn.init.constant_(self.bbox_embed.layers[-1].bias.data, 0)
def forward(self, samples: NestedTensor, dn_args=None):
"""
Add two functions prepare_for_dn and dn_post_process to implement dn
The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x num_classes]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, width, height). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.
"""
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
features, pos = self.backbone(samples)
src, mask = features[-1].decompose()
assert mask is not None
# default pipeline
embedweight = self.refpoint_embed.weight
# prepare for dn
input_query_label, input_query_bbox, attn_mask, mask_dict = \
prepare_for_dn(dn_args, embedweight, src.size(0), self.training, self.num_queries, self.num_classes,
self.hidden_dim, self.label_enc) # num_queries=300 num_classes=91 hidden_dim=256 label_enc=Embedding(92,255)
hs, reference = self.transformer(self.input_proj(src), mask, input_query_bbox, pos[-1], tgt=input_query_label,
attn_mask=attn_mask)
if not self.bbox_embed_diff_each_layer:
reference_before_sigmoid = inverse_sigmoid(reference)
tmp = self.bbox_embed(hs)
tmp[..., :self.query_dim] += reference_before_sigmoid
outputs_coord = tmp.sigmoid()
else:
reference_before_sigmoid = inverse_sigmoid(reference)
outputs_coords = []
for lvl in range(hs.shape[0]):
tmp = self.bbox_embed[lvl](hs[lvl])
tmp[..., :self.query_dim] += reference_before_sigmoid[lvl]
outputs_coord = tmp.sigmoid()
outputs_coords.append(outputs_coord)
outputs_coord = torch.stack(outputs_coords)
outputs_class = self.class_embed(hs)
# dn post process
outputs_class, outputs_coord = dn_post_process(outputs_class, outputs_coord, mask_dict) # 从output中取出未加入噪声的部分
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out, mask_dict
@torch.jit.unused
def _set_aux_loss(self, outputs_class, outputs_coord):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
return [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]代码主体和DAB基本一样,相对来说增加了prepare_for_dn产生decoder的输入
代码具体如下:
def prepare_for_dn(dn_args, embedweight, batch_size, training, num_queries, num_classes, hidden_dim, label_enc):
"""
prepare for dn components in forward function
Args:
dn_args: (targets, args.scalar, args.label_noise_scale,
args.box_noise_scale, args.num_patterns) from engine input
embedweight: positional queries as anchor
training: whether it is training or inference
num_queries: number of queries
num_classes: number of classes
hidden_dim: transformer hidden dimenstion
label_enc: label encoding embedding
Returns: input_query_label, input_query_bbox, attn_mask, mask_dict
"""
if training:
targets, scalar, label_noise_scale, box_noise_scale, num_patterns = dn_args # scalar 表示去噪组数
else:
num_patterns = dn_args
if num_patterns == 0:
num_patterns = 1
indicator0 = torch.zeros([num_queries * num_patterns, 1]).cpu() # indicator0 [300,1]
tgt = label_enc(torch.tensor(num_classes).cpu()).repeat(num_queries * num_patterns, 1) # tgt [300,255]
tgt = torch.cat([tgt, indicator0], dim=1) # tgt [300,256]
refpoint_emb = embedweight.repeat(num_patterns, 1) # refpoint_emb [300,4]
if training:
known = [(torch.ones_like(t['labels'])).cpu() for t in targets]
know_idx = [torch.nonzero(t) for t in known]
known_num = [sum(k) for k in known] # batch上每张图的label个数和
# you can uncomment this to use fix number of dn queries
# if int(max(known_num))>0:
# scalar=scalar//int(max(known_num))
# can be modified to selectively denosie some label or boxes; also known label prediction
unmask_bbox = unmask_label = torch.cat(known)
labels = torch.cat([t['labels'] for t in targets]) # 每个batch上所有图中的label
boxes = torch.cat([t['boxes'] for t in targets]) # 每个batch上所有图中的bbox
batch_idx = torch.cat([torch.full_like(t['labels'].long(), i) for i, t in enumerate(targets)]) # 每个label or bbox在batch维度上的索引
known_indice = torch.nonzero(unmask_label + unmask_bbox)
known_indice = known_indice.view(-1)
# add noise
known_indice = known_indice.repeat(scalar, 1).view(-1) # 重复scalar次
known_labels = labels.repeat(scalar, 1).view(-1)
known_bid = batch_idx.repeat(scalar, 1).view(-1)
known_bboxs = boxes.repeat(scalar, 1)
known_labels_expaned = known_labels.clone()
known_bbox_expand = known_bboxs.clone()
# noise on the label
if label_noise_scale > 0: # 随机初始化一个known_labels_expaned大小的张量,挑出小于label_noise_scale的索引生成chosen_indice,再随机生成chosen_indice大小的新类别,最后将新label按索引替换原始的label
p = torch.rand_like(known_labels_expaned.float())
chosen_indice = torch.nonzero(p < (label_noise_scale)).view(-1) # usually half of bbox noise
new_label = torch.randint_like(chosen_indice, 0, num_classes) # randomly put a new one here
known_labels_expaned.scatter_(0, chosen_indice, new_label)
# noise on the box
if box_noise_scale > 0: # 根据known_bbox_expand生成diff,按known_bbox_expand的shape生成随机数,按给定的公式将diff与该随机数相乘后加回known_bbox_expand
diff = torch.zeros_like(known_bbox_expand)
diff[:, :2] = known_bbox_expand[:, 2:] / 2
diff[:, 2:] = known_bbox_expand[:, 2:]
known_bbox_expand += torch.mul((torch.rand_like(known_bbox_expand) * 2 - 1.0),
diff).cpu() * box_noise_scale
known_bbox_expand = known_bbox_expand.clamp(min=0.0, max=1.0) # 防止超出图像边界
m = known_labels_expaned.long().to('cpu')
input_label_embed = label_enc(m) # input_label_embed [20,255]
# add dn part indicator
indicator1 = torch.ones([input_label_embed.shape[0], 1]).cpu() # indicator1 [20,1]
input_label_embed = torch.cat([input_label_embed, indicator1], dim=1) # input_label_embed [20,256]
input_bbox_embed = inverse_sigmoid(known_bbox_expand) # input_bbox_embed [20,4]
single_pad = int(max(known_num)) # 表示在该batch中包含的最大的label数
pad_size = int(single_pad * scalar)
padding_label = torch.zeros(pad_size, hidden_dim).cpu() # padding_label [single_pad*5,256]
padding_bbox = torch.zeros(pad_size, 4).cpu() # padding_label [single_pad*5,4]
input_query_label = torch.cat([padding_label, tgt], dim=0).repeat(batch_size, 1, 1) # input_query_label [N,300+single_pad*5,256]
input_query_bbox = torch.cat([padding_bbox, refpoint_emb], dim=0).repeat(batch_size, 1, 1) # input_query_label [N,300+single_pad*5,4]
# map in order
map_known_indice = torch.tensor([]).to('cpu')
if len(known_num):
map_known_indice = torch.cat([torch.tensor(range(num)) for num in known_num]) # [1,2, 1,2,3]
map_known_indice = torch.cat([map_known_indice + single_pad * i for i in range(scalar)]).long()
if len(known_bid):
ori_input_label = input_query_label.detach().clone()
ori_input_bbox = input_query_bbox.detach().clone()
input_query_label[(known_bid.long(), map_known_indice)] = input_label_embed
input_query_bbox[(known_bid.long(), map_known_indice)] = input_bbox_embed
diff_label = input_query_label - ori_input_label
diff_bbox = input_query_bbox - ori_input_bbox
chosen_indice_dl = torch.nonzero(diff_label != 0)
chosen_indice_db = torch.nonzero(diff_bbox != 0)
# 加入噪声后,还需要注意的一点便是信息之间的是否可见问题,噪声 queries 是会和匈牙利匹配任务的 queries 拼接起来一起送入 transformer中的。
# 在 transformer 中,它们会经过 attention 交互,这势必会得知一些信息,这是作弊行为,是绝对不允许的
# 一、首先,如上所述,匈牙利匹配任务的 queries 肯定不能看到 DN 任务的 queries。
# 二、其次,不同 dn group 的 queries 也不能相互看到。因为综合所有组来看,gt -> query 是 one-to-many 的,每个 gt 在
# 每组都会有 1 个 query 拥有自己的信息。于是,对于每个 query 来说,在其它各组中都势必存在 1 个 query 拥有自己负责预测的那个 gt 的信息。
# 三、接着,同一个 dn group 的 queries 是可以相互看的 。因为在每组内,gt -> query 是 one-to-one 的关系,对于每个 query 来说,其它 queries 都不会有自己 gt 的信息。
# 四、最后,DN 任务的 queries 可以去看匈牙利匹配任务的 queries ,因为只有前者才拥有 gt 信息,而后者是“凭空构造”的(主要是先验,需要自己去学习)。
# 总的来说,attention mask 的设计归纳为:
# 1、匈牙利匹配任务的 queries 不能看到 DN任务的 queries;
# 2、DN 任务中,不同组的 queries 不能相互看到;
# 3、其它情况均可见
tgt_size = pad_size + num_queries * num_patterns
attn_mask = torch.ones(tgt_size, tgt_size).to('cpu') < 0
# match query cannot see the reconstruct
attn_mask[pad_size:, :pad_size] = True
# reconstruct cannot see each other
for i in range(scalar):
if i == 0:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
if i == scalar - 1:
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
else:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
mask_dict = {
'known_indice': torch.as_tensor(known_indice).long(),
'batch_idx': torch.as_tensor(batch_idx).long(),
'map_known_indice': torch.as_tensor(map_known_indice).long(),
'known_lbs_bboxes': (known_labels, known_bboxs),
'know_idx': know_idx,
'pad_size': pad_size
}
else: # no dn for inference
input_query_label = tgt.repeat(batch_size, 1, 1)
input_query_bbox = refpoint_emb.repeat(batch_size, 1, 1)
attn_mask = None
mask_dict = None
input_query_label = input_query_label.transpose(0, 1) # input_query_label [300+single_pad*5,N,256]
input_query_bbox = input_query_bbox.transpose(0, 1) # input_query_bbox [300+single_pad*5,N,4]
return input_query_label, input_query_bbox, attn_mask, mask_dict这部分代码就是为box和label增加噪声
其中attn_mask:
tgt_size = pad_size + num_queries * num_patterns
attn_mask = torch.ones(tgt_size, tgt_size).to('cpu') < 0
# match query cannot see the reconstruct
attn_mask[pad_size:, :pad_size] = True
# reconstruct cannot see each other
for i in range(scalar):
if i == 0:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
if i == scalar - 1:
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
else:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
此处假设single_pad为2,该single_pad表示在该batch中包含的最大的label个数。single_pad后面也会用到

图示:
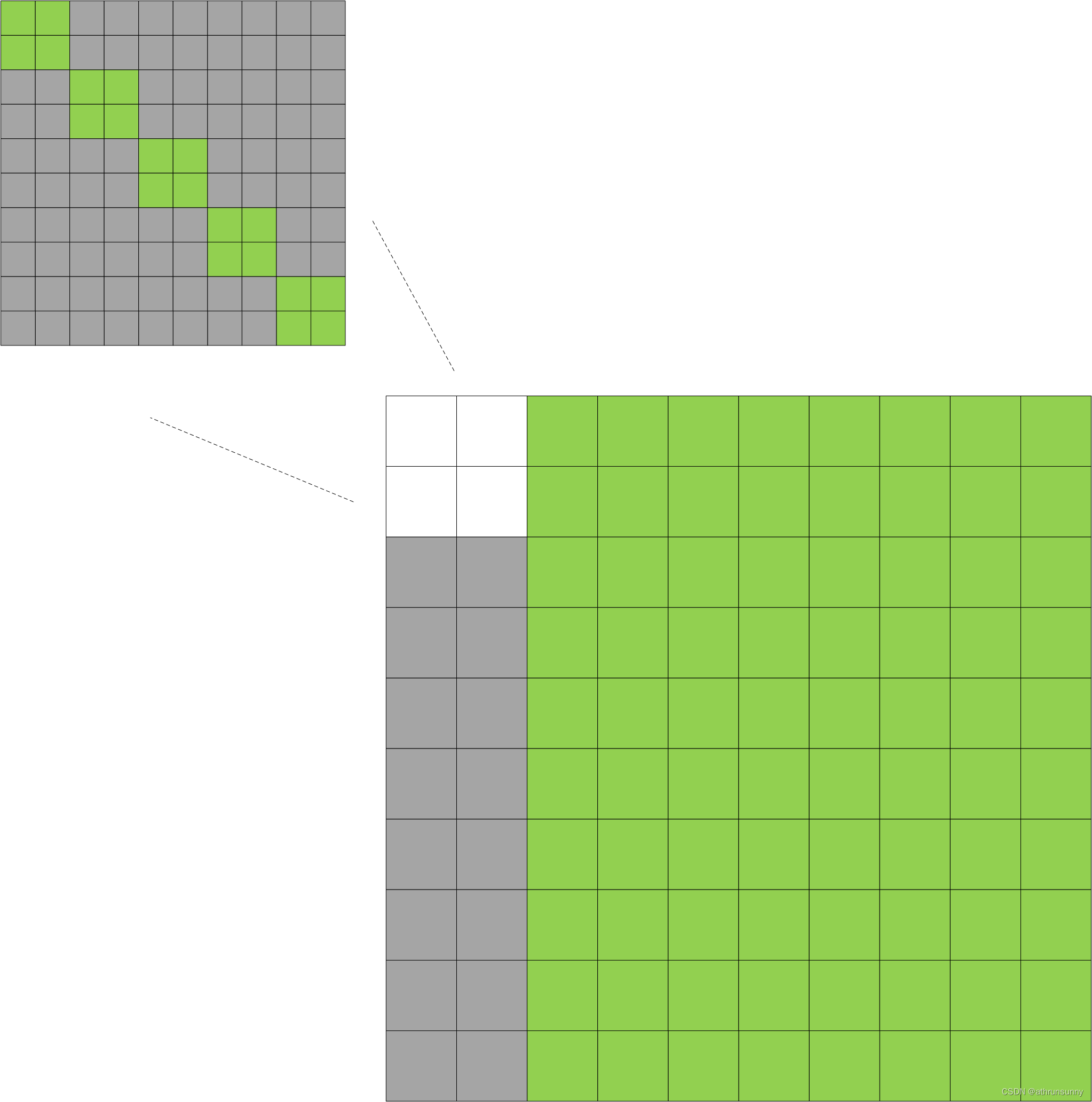
其中绿色部分表示为False,灰色部分表示为True。有那么点最初的transformer的味道。上图是个示意图,右下角的大图为310*310,因为single_pad为2,310=300+single_pad*5,左上的小图10*10,10=single_pad*5
三、encoder
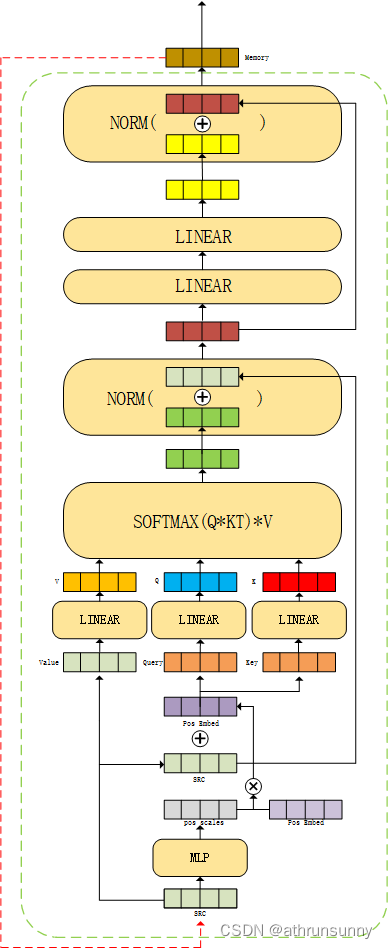
encoder和DAB-DETR一模一样,经过backbone的src的维度为[N,2048,25,25], pos经过PositionEmbeddingSineHW维度为[N,256,25,25],PositionEmbeddingSineHW和DETR中的PositionEmbeddingSine不同之处在于,PositionEmbeddingSine中使用一个temperature同时控制W和H,而PositionEmbeddingSineHW可在W和H上使用不同的temperature,整体上的功能基本相同。DETR的原始设置的T=10000,文中作者发现设置为T=20的效果最好。mask在上述中的博文中有详细解释,维度为[N,25,25]。
refpoint_embed由nn.Embedding(num_queries, query_dim)得到,其中num_queries为300,query_dim为4.
src在输入encoder之前会经过一个1*1的卷积进行降维[N,2048,25,25]->[N,256,25,25].
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_queries=300, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False, query_dim=4,
keep_query_pos=False, query_scale_type='cond_elewise',
num_patterns=0,
modulate_hw_attn=True,
bbox_embed_diff_each_layer=False,
):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before, keep_query_pos=keep_query_pos)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec,
d_model=d_model, query_dim=query_dim, keep_query_pos=keep_query_pos, query_scale_type=query_scale_type,
modulate_hw_attn=modulate_hw_attn,
bbox_embed_diff_each_layer=bbox_embed_diff_each_layer)
self._reset_parameters()
assert query_scale_type in ['cond_elewise', 'cond_scalar', 'fix_elewise']
self.d_model = d_model
self.nhead = nhead
self.dec_layers = num_decoder_layers
self.num_queries = num_queries
self.num_patterns = num_patterns
if not isinstance(num_patterns, int):
Warning("num_patterns should be int but {}".format(type(num_patterns)))
self.num_patterns = 0
if self.num_patterns > 0:
self.patterns = nn.Embedding(self.num_patterns, d_model)
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
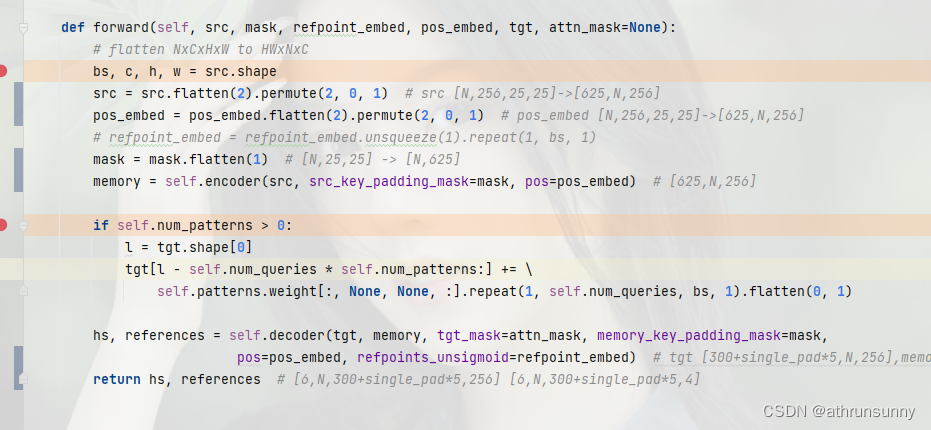
def forward(self, src, mask, refpoint_embed, pos_embed, tgt, attn_mask=None):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1) # src [N,256,25,25]->[625,N,256]
pos_embed = pos_embed.flatten(2).permute(2, 0, 1) # pos_embed [N,256,25,25]->[625,N,256]
# refpoint_embed = refpoint_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1) # [N,25,25] -> [N,625]
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed) # [625,N,256]
if self.num_patterns > 0:
l = tgt.shape[0]
tgt[l - self.num_queries * self.num_patterns:] += \
self.patterns.weight[:, None, None, :].repeat(1, self.num_queries, bs, 1).flatten(0, 1)
hs, references = self.decoder(tgt, memory, tgt_mask=attn_mask, memory_key_padding_mask=mask,
pos=pos_embed, refpoints_unsigmoid=refpoint_embed) # tgt [300+single_pad*5,N,256],memory [625,N,256] tgt_mask [300+single_pad*5,300+single_pad*5] memory_key_padding_mask [N,625] pos [625,N,256] refpoints_unsigmoid[300+single_pad*5,N,4]
return hs, references # [6,N,300+single_pad*5,256] [6,N,300+single_pad*5,4]在输入encoder之前还会对src,mask,refpoint_embed等做一些维度转换的预处理,之后将feature map 对应的src以及其对应的mask,以及mask经过PositionEmbeddingSineHW后得到的pos_embed传入encoder(后面有图解)。
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None, d_model=256):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.query_scale = MLP(d_model, d_model, d_model, 2)
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer_id, layer in enumerate(self.layers):
# rescale the content and pos sim
pos_scales = self.query_scale(output) # 两个Linear(256,256) [625,N,256]->[625,N,256]
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos*pos_scales)
if self.norm is not None:
output = self.norm(output)
return output在encoder中pos_embed会乘上每一层encoder输出的output经过两个Linear层得到的结果,作为新的pos_embed输入到下一层encoder
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src看图解会比较直观:
四、decoder
代码的主体沿用了之前的DAB-DETR,但是输入的部分增加了indicator,在计算loss的时候需要多做一步denoising部分的loss
进入decoder之前就不像DAB那样初始化一个全零的tgt,该tgt由prepare_for_dn生成,对应的是input_query_label
N个batch上300+single_pad*5个4维的位置信息,分别代表x,y,w,h,通过gen_sineembed_for_position()分别对他们进行位置编码,query_sine_embed的维度由obj_center[300+single_pad*5,N,4]变为[300+single_pad*5,N,512]。直接把DETR的postional query显示地建模为四维的框(x,y,w,h),同时每一层的decoder都会去预测相对偏移量 (Δx,Δy,Δw,Δh) ,并去更新检测框,得到更加精确的检测框预测: (x',y'w',h') =(x,y,w,h)+ (Δx,Δy,Δw,Δh),动态更新这个检测框,并用它来帮助decoder的cross-attention来抽取feature。
query_sine_embed再经过两个Linear层得到query_pos维度由[300+single_pad*5,N,512]->[300+single_pad*5,N,256]。
在推理时不需要加上single_pad*5
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False,
d_model=256, query_dim=2, keep_query_pos=False, query_scale_type='cond_elewise',
modulate_hw_attn=False,
bbox_embed_diff_each_layer=False,
):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
assert return_intermediate
self.query_dim = query_dim
assert query_scale_type in ['cond_elewise', 'cond_scalar', 'fix_elewise']
self.query_scale_type = query_scale_type
if query_scale_type == 'cond_elewise':
self.query_scale = MLP(d_model, d_model, d_model, 2)
elif query_scale_type == 'cond_scalar':
self.query_scale = MLP(d_model, d_model, 1, 2)
elif query_scale_type == 'fix_elewise':
self.query_scale = nn.Embedding(num_layers, d_model)
else:
raise NotImplementedError("Unknown query_scale_type: {}".format(query_scale_type))
self.ref_point_head = MLP(query_dim // 2 * d_model, d_model, d_model, 2)
self.bbox_embed = None
self.d_model = d_model
self.modulate_hw_attn = modulate_hw_attn
self.bbox_embed_diff_each_layer = bbox_embed_diff_each_layer
if modulate_hw_attn:
self.ref_anchor_head = MLP(d_model, d_model, 2, 2)
if not keep_query_pos:
for layer_id in range(num_layers - 1):
self.layers[layer_id + 1].ca_qpos_proj = None
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
refpoints_unsigmoid: Optional[Tensor] = None, # num_queries, bs, 2
): # tgt [300+single_pad*5,N,256],memory [625,N,256] tgt_mask [300+single_pad*5,300+single_pad*5] memory_key_padding_mask [N,625] pos [625,N,256] refpoints_unsigmoid[300+single_pad*5,N,4]
output = tgt
intermediate = []
reference_points = refpoints_unsigmoid.sigmoid() # [300+single_pad*5,N,4]
ref_points = [reference_points]
# import ipdb; ipdb.set_trace()
for layer_id, layer in enumerate(self.layers):
obj_center = reference_points[..., :self.query_dim] # [num_queries, batch_size, 2] #[300+single_pad*5,N,4]
# get sine embedding for the query vector
query_sine_embed = gen_sineembed_for_position(obj_center) # 对obj_center[300+single_pad*5,N,4] 中的x,y,w,h分别做位置编码->[300+single_pad*5,N,512]
query_pos = self.ref_point_head(query_sine_embed) # Linear(512,256) Linear(256,256) [300+single_pad*5,N,512]->[300+single_pad*5,N,256]
# For the first decoder layer, we do not apply transformation over p_s
if self.query_scale_type != 'fix_elewise': # 'cond_elewise'
if layer_id == 0:
pos_transformation = 1
else:
pos_transformation = self.query_scale(output) # Linear(256,256) Linear(256,256) [300+single_pad*5,N,256]
else:
pos_transformation = self.query_scale.weight[layer_id]
# apply transformation
query_sine_embed = query_sine_embed[...,:self.d_model] * pos_transformation
# modulated HW attentions
if self.modulate_hw_attn:
refHW_cond = self.ref_anchor_head(output).sigmoid() # nq, bs, 2 Linear(256,256) Linear(256,2) [300+single_pad*5,N,2]
query_sine_embed[..., self.d_model // 2:] *= (refHW_cond[..., 0] / obj_center[..., 2]).unsqueeze(-1)
query_sine_embed[..., :self.d_model // 2] *= (refHW_cond[..., 1] / obj_center[..., 3]).unsqueeze(-1)
# tgt_mask [300+single_pad*5,300+single_pad*5] memory_mask None tgt_key_padding_mask None memory_key_padding_mask [N,625] pos [625,N,256] query_pos [300+single_pad*5,N,256] query_sine_embed [300+single_pad*5,N,256]
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos, query_sine_embed=query_sine_embed,
is_first=(layer_id == 0))
# iter update
if self.bbox_embed is not None:
if self.bbox_embed_diff_each_layer:
tmp = self.bbox_embed[layer_id](output)
else:
tmp = self.bbox_embed(output)
# import ipdb; ipdb.set_trace()
tmp[..., :self.query_dim] += inverse_sigmoid(reference_points)
new_reference_points = tmp[..., :self.query_dim].sigmoid()
if layer_id != self.num_layers - 1:
ref_points.append(new_reference_points)
reference_points = new_reference_points.detach()
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
if self.bbox_embed is not None:
return [
torch.stack(intermediate).transpose(1, 2),
torch.stack(ref_points).transpose(1, 2),
]
else:
return [
torch.stack(intermediate).transpose(1, 2),
reference_points.unsqueeze(0).transpose(1, 2)
]
return output.unsqueeze(0)# For the first decoder layer, we do not apply transformation over p_s
if self.query_scale_type != 'fix_elewise':
if layer_id == 0:
pos_transformation = 1
else:
pos_transformation = self.query_scale(output) # Linear(256,256) Linear(256,256) [300,N,256]
else:
pos_transformation = self.query_scale.weight[layer_id]
代码默认的模式是‘cond_elewise’,第一层的pos_transformation是不会对output使用Linear进行处理,除了第一层decoder外,其他的层都会对output使用Linear进行处理。可以看图解比较直观
# modulated HW attentions
if self.modulate_hw_attn:
refHW_cond = self.ref_anchor_head(output).sigmoid() # nq, bs, 2 Linear(256,256) Linear(256,2) [300,N,2]
query_sine_embed[..., self.d_model // 2:] *= (refHW_cond[..., 0] / obj_center[..., 2]).unsqueeze(-1)
query_sine_embed[..., :self.d_model // 2] *= (refHW_cond[..., 1] / obj_center[..., 3]).unsqueeze(-1)
对应的公式:
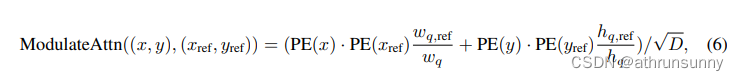
作者希望在这个注意力中加入尺度信息,并且发现,除以anchor的相对宽高,会对不同尺度匹配更好(归一化尺度)。
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False, keep_query_pos=False,
rm_self_attn_decoder=False):
super().__init__()
# Decoder Self-Attention
if not rm_self_attn_decoder:
self.sa_qcontent_proj = nn.Linear(d_model, d_model)
self.sa_qpos_proj = nn.Linear(d_model, d_model)
self.sa_kcontent_proj = nn.Linear(d_model, d_model)
self.sa_kpos_proj = nn.Linear(d_model, d_model)
self.sa_v_proj = nn.Linear(d_model, d_model)
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, vdim=d_model)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
# Decoder Cross-Attention
self.ca_qcontent_proj = nn.Linear(d_model, d_model)
self.ca_qpos_proj = nn.Linear(d_model, d_model)
self.ca_kcontent_proj = nn.Linear(d_model, d_model)
self.ca_kpos_proj = nn.Linear(d_model, d_model)
self.ca_v_proj = nn.Linear(d_model, d_model)
self.ca_qpos_sine_proj = nn.Linear(d_model, d_model)
self.cross_attn = MultiheadAttention(d_model*2, nhead, dropout=dropout, vdim=d_model)
self.nhead = nhead
self.rm_self_attn_decoder = rm_self_attn_decoder
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
self.keep_query_pos = keep_query_pos
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None,
query_sine_embed = None,
is_first = False):
# ========== Begin of Self-Attention =============
if not self.rm_self_attn_decoder:
# Apply projections here
# shape: num_queries x batch_size x 256
q_content = self.sa_qcontent_proj(tgt) # Linear(256,256) [300+single_pad*5,N,256] # target is the input of the first decoder layer. zero by default.
q_pos = self.sa_qpos_proj(query_pos) # Linear(256,256) [300+single_pad*5,N,256]
k_content = self.sa_kcontent_proj(tgt) # Linear(256,256) [300+single_pad*5,N,256]
k_pos = self.sa_kpos_proj(query_pos) # Linear(256,256) [300+single_pad*5,N,256]
v = self.sa_v_proj(tgt) # Linear(256,256) [300+single_pad*5,N,256]
num_queries, bs, n_model = q_content.shape
hw, _, _ = k_content.shape
q = q_content + q_pos
k = k_content + k_pos
# attn_mask [300+single_pad*5,300+single_pad*5] key_padding_mask None
tgt2 = self.self_attn(q, k, value=v, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
# ========== End of Self-Attention =============
tgt = tgt + self.dropout1(tgt2) # [300+single_pad*5,N,256]
tgt = self.norm1(tgt)
# ========== Begin of Cross-Attention =============
# Apply projections here
# shape: num_queries x batch_size x 256
q_content = self.ca_qcontent_proj(tgt) # Linear(256,256) [300+single_pad*5,N,256]
k_content = self.ca_kcontent_proj(memory) # Linear(256,256) [625,N,256]
v = self.ca_v_proj(memory) # Linear(256,256) [625,N,256]
num_queries, bs, n_model = q_content.shape
hw, _, _ = k_content.shape
k_pos = self.ca_kpos_proj(pos) # Linear(256,256) [625,N,256]
# For the first decoder layer, we concatenate the positional embedding predicted from
# the object query (the positional embedding) into the original query (key) in DETR.
if is_first or self.keep_query_pos:
q_pos = self.ca_qpos_proj(query_pos) # Linear(256,256) [300+single_pad*5,N,256]
q = q_content + q_pos
k = k_content + k_pos
else:
q = q_content
k = k_content
q = q.view(num_queries, bs, self.nhead, n_model//self.nhead) # [300+single_pad*5,N,8,32]
query_sine_embed = self.ca_qpos_sine_proj(query_sine_embed) # Linear(256,256) [300+single_pad*5,N,256]
query_sine_embed = query_sine_embed.view(num_queries, bs, self.nhead, n_model//self.nhead) # [300+single_pad*5,N,8,32]
q = torch.cat([q, query_sine_embed], dim=3).view(num_queries, bs, n_model * 2) # [300+single_pad*5,N,512]
k = k.view(hw, bs, self.nhead, n_model//self.nhead) # [625,N,8,32]
k_pos = k_pos.view(hw, bs, self.nhead, n_model//self.nhead) # [625,N,8,32]
k = torch.cat([k, k_pos], dim=3).view(hw, bs, n_model * 2) # [625,N,512]
tgt2 = self.cross_attn(query=q,
key=k,
value=v, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
# ========== End of Cross-Attention =============
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt # [300+single_pad*5,N,256]
# For the first decoder layer, we concatenate the positional embedding predicted from
# the object query (the positional embedding) into the original query (key) in DETR.
if is_first or self.keep_query_pos:
q_pos = self.ca_qpos_proj(query_pos) # Linear(256,256) [300+single_pad*5,N,256]
q = q_content + q_pos
k = k_content + k_pos
else:
q = q_content
k = k_content
这里要注意的是第一层的decoder,第一层会比较特殊,比如上面这里,其中:
1、k_pos:来自mask经过PE编码后得到的pos_embed,再将pos_embed经过Linear后得到最后的k_pos
2、q_pos:由query_sine_embed得到的query_pos,再将query_pos经过Linear后得到最后的q_pos
3、第一层decoder中,会将这两个值加在k,q上,之后会将k和k_pos cat在一起(每一层都会cat k_pos,只是在第一层或self.keep_query_pos为True时会在k上加k_pos,在q上加q_pos)
4、而q还会与query_sine_embed经过Linear后的结果cat在一起
在做self attn时会用上之前算好的mask
图解:
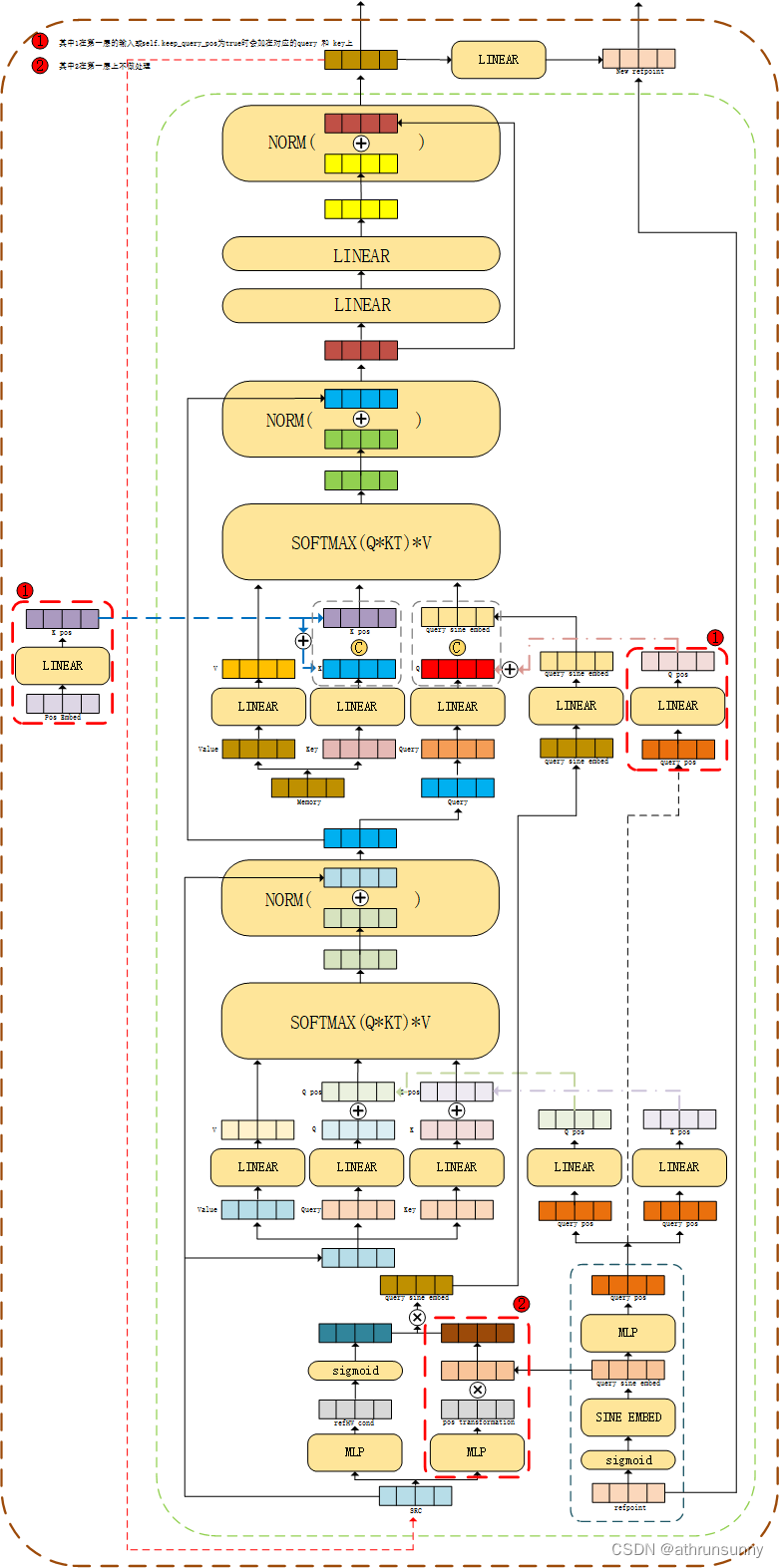
顺便附上一张论文中的图:

这里可能有人要问了,这里的图解和论文的不一样啊,别急,数据是都要经过decoder的,只是在计算loss的时候分开算了,在这里做了个辅助loss帮助收敛。
之后就是做一些后处理:
if not self.bbox_embed_diff_each_layer:
reference_before_sigmoid = inverse_sigmoid(reference)
tmp = self.bbox_embed(hs)
tmp[..., :self.query_dim] += reference_before_sigmoid
outputs_coord = tmp.sigmoid()
else:
reference_before_sigmoid = inverse_sigmoid(reference)
outputs_coords = []
for lvl in range(hs.shape[0]):
tmp = self.bbox_embed[lvl](hs[lvl])
tmp[..., :self.query_dim] += reference_before_sigmoid[lvl]
outputs_coord = tmp.sigmoid()
outputs_coords.append(outputs_coord)
outputs_coord = torch.stack(outputs_coords)
outputs_class = self.class_embed(hs)
# dn post process
outputs_class, outputs_coord = dn_post_process(outputs_class, outputs_coord, mask_dict) # 从output中取出未加入噪声的部分
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out, mask_dict
后处理过程中会将 denoising part和matching part分离
完整的流程图:
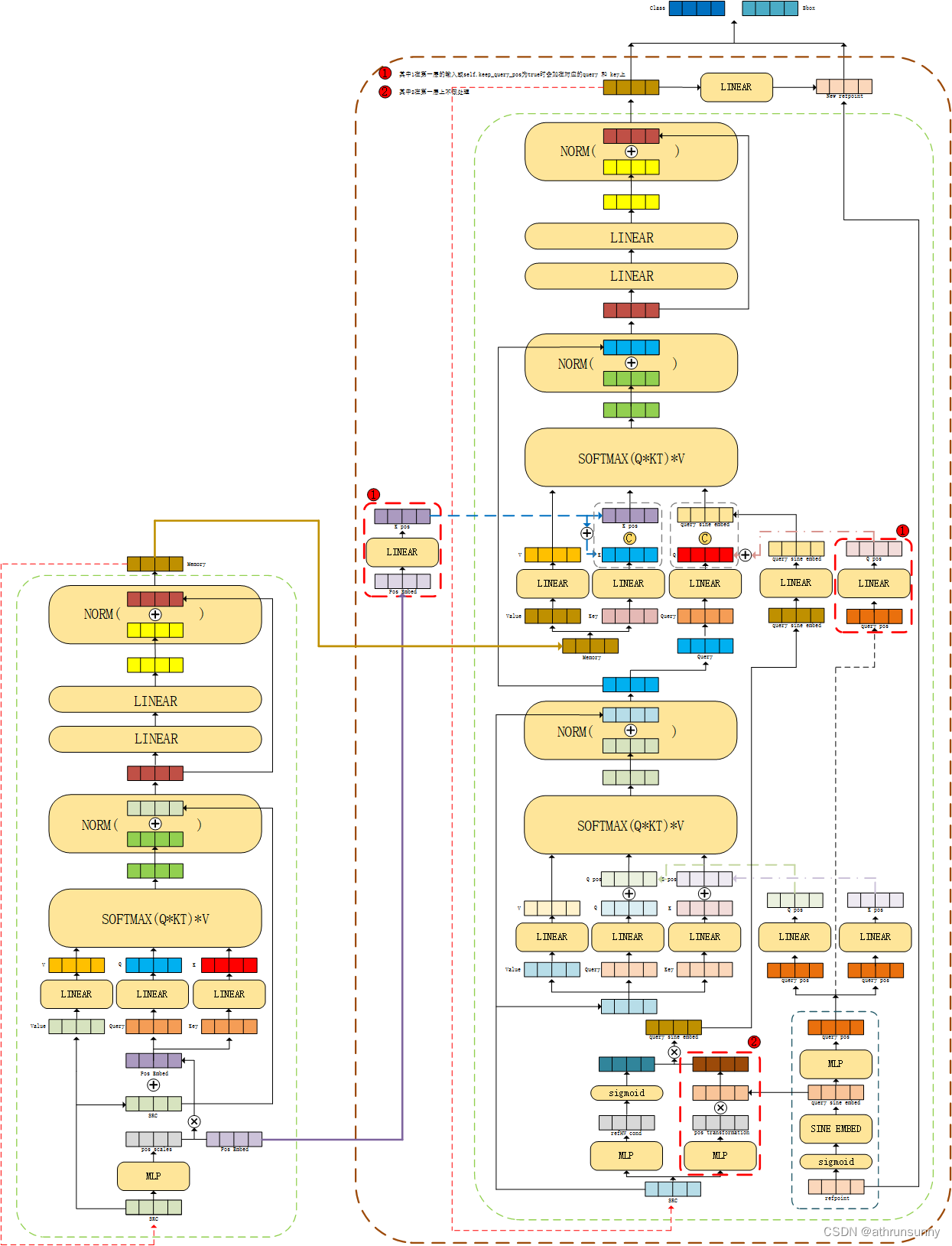
五、loss
匈牙利算法,核心就是找到最优的匹配,对该算法不理解的可以参看理解匈牙利算法
class HungarianMatcher(nn.Module):
"""This class computes an assignment between the targets and the predictions of the network
For efficiency reasons, the targets don't include the no_object. Because of this, in general,
there are more predictions than targets. In this case, we do a 1-to-1 matching of the best predictions,
while the others are un-matched (and thus treated as non-objects).
"""
def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1, focal_alpha = 0.25):
"""Creates the matcher
Params:
cost_class: This is the relative weight of the classification error in the matching cost
cost_bbox: This is the relative weight of the L1 error of the bounding box coordinates in the matching cost
cost_giou: This is the relative weight of the giou loss of the bounding box in the matching cost
"""
super().__init__()
self.cost_class = cost_class
self.cost_bbox = cost_bbox
self.cost_giou = cost_giou
assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs cant be 0"
self.focal_alpha = focal_alpha
@torch.no_grad()
def forward(self, outputs, targets):
""" Performs the matching
Params:
outputs: This is a dict that contains at least these entries:
"pred_logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
"pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates
targets: This is a list of targets (len(targets) = batch_size), where each target is a dict containing:
"labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of ground-truth
objects in the target) containing the class labels
"boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates
Returns:
A list of size batch_size, containing tuples of (index_i, index_j) where:
- index_i is the indices of the selected predictions (in order)
- index_j is the indices of the corresponding selected targets (in order)
For each batch element, it holds:
len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
"""
bs, num_queries = outputs["pred_logits"].shape[:2] # N ,300
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).sigmoid() # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes # 将目标的ground truth id和bbox在batch维度合并,假设此处共有4个类(假设每个batch上有两个类)那么tgt_ids的shape为4,tgt_bbox的shape为[4,4]
tgt_ids = torch.cat([v["labels"] for v in targets])
tgt_bbox = torch.cat([v["boxes"] for v in targets])
# Compute the classification cost.
alpha = self.focal_alpha
gamma = 2.0
neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-(1 - out_prob + 1e-8).log()) # [600,91]
pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log()) # [600,91]
cost_class = pos_cost_class[:, tgt_ids] - neg_cost_class[:, tgt_ids] # [600,4] 因为gt总共有4个label
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1) # 计算out_bbox和tgt_bbox的L1距离,此时cost_bbox的shape为[600,4]
# Compute the giou cost betwen boxes
# import ipdb; ipdb.set_trace()
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox)) # 计算giou,此时cost_giou的shape为[600,4]
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu() # C [600,4]->[2,300,4]
sizes = [len(v["boxes"]) for v in targets]
# 匈牙利算法的实现,指派最优的目标索引,输出一个二维列表,第一维是batch为0,即一个batch中第一张图像通过匈
# 牙利算法计算得到的最优解的横纵坐标,第二维是batch为1,即一个batch中第二张图像,后面的batch维度以此类推
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
def build_matcher(args):
return HungarianMatcher(
cost_class=args.set_cost_class, cost_bbox=args.set_cost_bbox, cost_giou=args.set_cost_giou,
focal_alpha=args.focal_alpha
)在计算matching part的class loss时引入了focal loss
def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
"""
Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary
classification label for each element in inputs
(0 for the negative class and 1 for the positive class).
alpha: (optional) Weighting factor in range (0,1) to balance
positive vs negative examples. Default = -1 (no weighting).
gamma: Exponent of the modulating factor (1 - p_t) to
balance easy vs hard examples.
Returns:
Loss tensor
"""
prob = inputs.sigmoid()
ce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
p_t = prob * targets + (1 - prob) * (1 - targets)
loss = ce_loss * ((1 - p_t) ** gamma)
if alpha >= 0:
alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
loss = alpha_t * loss
return loss.mean(1).sum() / num_boxesclass SetCriterion(nn.Module):
""" This class computes the loss for Conditional DETR.
The process happens in two steps:
1) we compute hungarian assignment between ground truth boxes and the outputs of the model
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
"""
def __init__(self, num_classes, matcher, weight_dict, focal_alpha, losses):
""" Create the criterion.
Parameters:
num_classes: number of object categories, omitting the special no-object category
matcher: module able to compute a matching between targets and proposals
weight_dict: dict containing as key the names of the losses and as values their relative weight.
losses: list of all the losses to be applied. See get_loss for list of available losses.
focal_alpha: alpha in Focal Loss
"""
super().__init__()
self.num_classes = num_classes
self.matcher = matcher
self.weight_dict = weight_dict
self.losses = losses
self.focal_alpha = focal_alpha
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (Binary focal loss)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
assert 'pred_logits' in outputs
src_logits = outputs['pred_logits'] # pred_logits [N,300,91] pred_boxes [N,300,4]
idx = self._get_src_permutation_idx(indices)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)]) # target_classes_o由targets["labels"] 根据 indices的纵坐标重新排序得到
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o
target_classes_onehot = torch.zeros([src_logits.shape[0], src_logits.shape[1], src_logits.shape[2]+1],
dtype=src_logits.dtype, layout=src_logits.layout, device=src_logits.device)
target_classes_onehot.scatter_(2, target_classes.unsqueeze(-1), 1)
target_classes_onehot = target_classes_onehot[:,:,:-1] # one_hot编码 [N,300,91]
loss_ce = sigmoid_focal_loss(src_logits, target_classes_onehot, num_boxes, alpha=self.focal_alpha, gamma=2) * src_logits.shape[1]
losses = {'loss_ce': loss_ce}
if log:
# TODO this should probably be a separate loss, not hacked in this one here
losses['class_error'] = 100 - accuracy(src_logits[idx], target_classes_o)[0]
return losses
@torch.no_grad()
def loss_cardinality(self, outputs, targets, indices, num_boxes):
""" Compute the cardinality error, ie the absolute error in the number of predicted non-empty boxes
This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients
"""
pred_logits = outputs['pred_logits']
device = pred_logits.device
tgt_lengths = torch.as_tensor([len(v["labels"]) for v in targets], device=device)
# Count the number of predictions that are NOT "no-object" (which is the last class)
card_pred = (pred_logits.argmax(-1) != pred_logits.shape[-1] - 1).sum(1)
card_err = F.l1_loss(card_pred.float(), tgt_lengths.float())
losses = {'cardinality_error': card_err}
return losses
def loss_boxes(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
assert 'pred_boxes' in outputs
idx = self._get_src_permutation_idx(indices)
src_boxes = outputs['pred_boxes'][idx] # [4,4]
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0) # [4,4]
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none')
losses = {}
losses['loss_bbox'] = loss_bbox.sum() / num_boxes
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes
# calculate the x,y and h,w loss
with torch.no_grad():
losses['loss_xy'] = loss_bbox[..., :2].sum() / num_boxes
losses['loss_hw'] = loss_bbox[..., 2:].sum() / num_boxes
return losses
def loss_masks(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the masks: the focal loss and the dice loss.
targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w]
"""
assert "pred_masks" in outputs
src_idx = self._get_src_permutation_idx(indices)
tgt_idx = self._get_tgt_permutation_idx(indices)
src_masks = outputs["pred_masks"]
src_masks = src_masks[src_idx]
masks = [t["masks"] for t in targets]
# TODO use valid to mask invalid areas due to padding in loss
target_masks, valid = nested_tensor_from_tensor_list(masks).decompose()
target_masks = target_masks.to(src_masks)
target_masks = target_masks[tgt_idx]
# upsample predictions to the target size
src_masks = interpolate(src_masks[:, None], size=target_masks.shape[-2:],
mode="bilinear", align_corners=False)
src_masks = src_masks[:, 0].flatten(1)
target_masks = target_masks.flatten(1)
target_masks = target_masks.view(src_masks.shape)
losses = {
"loss_mask": sigmoid_focal_loss(src_masks, target_masks, num_boxes),
"loss_dice": dice_loss(src_masks, target_masks, num_boxes),
}
return losses
def _get_src_permutation_idx(self, indices):
# permute predictions following indices
batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)]) # batch_idx得到的就是匈牙利算法匹配后的索引是属于batch中的哪一张图像,如tensor([0, 0, 1, 1])
src_idx = torch.cat([src for (src, _) in indices]) # src_idx则表示匈牙利算法得到的横坐标信息
return batch_idx, src_idx
def _get_tgt_permutation_idx(self, indices):
# permute targets following indices
batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
tgt_idx = torch.cat([tgt for (_, tgt) in indices])
return batch_idx, tgt_idx
def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs):
loss_map = {
'labels': self.loss_labels,
'cardinality': self.loss_cardinality,
'boxes': self.loss_boxes,
'masks': self.loss_masks
}
assert loss in loss_map, f'do you really want to compute {loss} loss?'
return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs)
def forward(self, outputs, targets, mask_dict=None, return_indices=False):
"""
Add a function prep_for_dn to prepare for dn loss components.
Add dn loss calculation tgt_loss_label and tgt_loss_box.
This performs the loss computation.
Parameters:
outputs: dict of tensors, see the output specification of the model for the format
targets: list of dicts, such that len(targets) == batch_size.
The expected keys in each dict depends on the losses applied, see each loss' doc
return_indices: used for vis. if True, the layer0-5 indices will be returned as well.
"""
outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs'} # pred_logits [N,300,91] pred_boxes [N,300,4]
# Retrieve the matching between the outputs of the last layer and the targets
indices = self.matcher(outputs_without_aux, targets)
if return_indices:
indices0_copy = indices
indices_list = []
# Compute the average number of target boxes accross all nodes, for normalization purposes
num_boxes = sum(len(t["labels"]) for t in targets)
num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
if is_dist_avail_and_initialized():
torch.distributed.all_reduce(num_boxes)
num_boxes = torch.clamp(num_boxes / get_world_size(), min=1).item()
# Compute all the requested losses
losses = {}
for loss in self.losses:
losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
# In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
if 'aux_outputs' in outputs:
for i, aux_outputs in enumerate(outputs['aux_outputs']):
indices = self.matcher(aux_outputs, targets)
if return_indices:
indices_list.append(indices)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, aux_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
# dn loss computation
aux_num = 0
if 'aux_outputs' in outputs:
aux_num = len(outputs['aux_outputs'])
dn_losses = compute_dn_loss(mask_dict, self.training, aux_num, self.focal_alpha)
losses.update(dn_losses)
if return_indices:
indices_list.append(indices0_copy)
return losses, indices_list
return losses在代码的最下端有个compute_dn_loss
dn_losses = compute_dn_loss(mask_dict, self.training, aux_num, self.focal_alpha)
def compute_dn_loss(mask_dict, training, aux_num, focal_alpha):
"""
compute dn loss in criterion
Args:
mask_dict: a dict for dn information
training: training or inference flag
aux_num: aux loss number
focal_alpha: for focal loss
"""
losses = {}
if training and 'output_known_lbs_bboxes' in mask_dict:
known_labels, known_bboxs, output_known_class, output_known_coord, \
num_tgt = prepare_for_loss(mask_dict)
losses.update(tgt_loss_labels(output_known_class[-1], known_labels, num_tgt, focal_alpha))
losses.update(tgt_loss_boxes(output_known_coord[-1], known_bboxs, num_tgt))
else:
losses['tgt_loss_bbox'] = torch.as_tensor(0.).to('cuda')
losses['tgt_loss_giou'] = torch.as_tensor(0.).to('cuda')
losses['tgt_loss_ce'] = torch.as_tensor(0.).to('cuda')
losses['tgt_class_error'] = torch.as_tensor(0.).to('cuda')
if aux_num:
for i in range(aux_num):
# dn aux loss
if training and 'output_known_lbs_bboxes' in mask_dict:
l_dict = tgt_loss_labels(output_known_class[i], known_labels, num_tgt, focal_alpha)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
l_dict = tgt_loss_boxes(output_known_coord[i], known_bboxs, num_tgt)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
else:
l_dict = dict()
l_dict['tgt_loss_bbox'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_class_error'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_loss_giou'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_loss_ce'] = torch.as_tensor(0.).to('cuda')
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
return losses由prepare_for_loss函数取出denoising part的部分
具体:
def prepare_for_loss(mask_dict):
"""
prepare dn components to calculate loss
Args:
mask_dict: a dict that contains dn information
"""
output_known_class, output_known_coord = mask_dict['output_known_lbs_bboxes'] # output_known_class [6,N,single_pad*5,91] output_known_coord [6,N,single_pad*5,4]
known_labels, known_bboxs = mask_dict['known_lbs_bboxes'] # known_labels [nums_labels*5] known_bboxs [nums_labels*5,4]
map_known_indice = mask_dict['map_known_indice'] # map_known_indice [nums_labels*5]
known_indice = mask_dict['known_indice'] # known_indice [nums_labels*5]
batch_idx = mask_dict['batch_idx']
bid = batch_idx[known_indice]
if len(output_known_class) > 0:
output_known_class = output_known_class.permute(1, 2, 0, 3)[(bid, map_known_indice)].permute(1, 0, 2) # output_known_class [6,nums_labels*5,91]
output_known_coord = output_known_coord.permute(1, 2, 0, 3)[(bid, map_known_indice)].permute(1, 0, 2) # output_known_coord [6,nums_labels*5,4]
num_tgt = known_indice.numel()
return known_labels, known_bboxs, output_known_class, output_known_coord, num_tgt计算bboxes和class的loss部分和matching part部分基本一致:
def tgt_loss_boxes(src_boxes, tgt_boxes, num_tgt,):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
if len(tgt_boxes) == 0:
return {
'tgt_loss_bbox': torch.as_tensor(0.).to('cuda'),
'tgt_loss_giou': torch.as_tensor(0.).to('cuda'),
}
loss_bbox = F.l1_loss(src_boxes, tgt_boxes, reduction='none') # src_boxes [nums_labels*5,4] tgt_boxes [nums_labels*5,4]
losses = {}
losses['tgt_loss_bbox'] = loss_bbox.sum() / num_tgt
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(tgt_boxes)))
losses['tgt_loss_giou'] = loss_giou.sum() / num_tgt
return losses
def tgt_loss_labels(src_logits_, tgt_labels_, num_tgt, focal_alpha, log=True):
"""Classification loss (NLL)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
if len(tgt_labels_) == 0:
return {
'tgt_loss_ce': torch.as_tensor(0.).to('cuda'),
'tgt_class_error': torch.as_tensor(0.).to('cuda'),
}
src_logits, tgt_labels= src_logits_.unsqueeze(0), tgt_labels_.unsqueeze(0) # src_logits [1,nums_labels*5,91] tgt_labels [1,nums_labels*5]
target_classes_onehot = torch.zeros([src_logits.shape[0], src_logits.shape[1], src_logits.shape[2] + 1],
dtype=src_logits.dtype, layout=src_logits.layout, device=src_logits.device)
target_classes_onehot.scatter_(2, tgt_labels.unsqueeze(-1), 1)
target_classes_onehot = target_classes_onehot[:, :, :-1]
loss_ce = sigmoid_focal_loss(src_logits, target_classes_onehot, num_tgt, alpha=focal_alpha, gamma=2) * src_logits.shape[1]
losses = {'tgt_loss_ce': loss_ce}
losses['tgt_class_error'] = 100 - accuracy(src_logits_, tgt_labels_)[0]
return losses网络在推理的时候就是下图中matching part的部分。
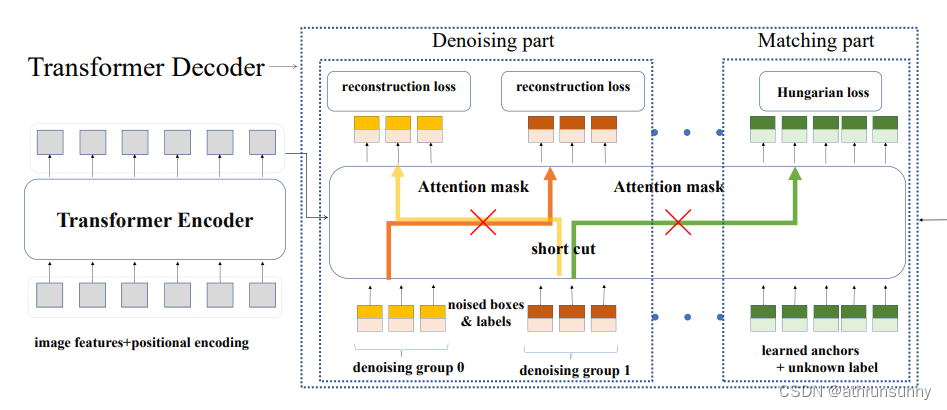
网络的主体代码到这里就讲完了