1 引言
一个月前,OpenAI向世界展示了具有强大多模态理解能力的GPT-4,让大家对GPT的图像理解和分析能力充满了期待和想象,但目前OpenAI暂未对用户开放GPT-4的识图功能,实验室也一直在等待上手试用。好在GPT技术日新月异,近日,阿卜杜拉国王科技大学(KAUST)研究团队开源了GPT4的平替版本——MiniGPT-4,让人们拥有一个自己的具有图像理解与对话能力的AI大模型成为可能。
MiniGPT-4 具有出色的多模态能力,据官方案例展示,它能够实现从手写草稿创建网站代码、生成详细的图像描述、看图写故事和诗歌、为图像中描述的问题提供解决方案,以及根据食物照片生成菜谱等亮眼功能。
本文未来GIS实验室针对该技术从GIS领域实测效果、模型细节、配置需求等方面进行分析,可以根据兴趣直接通过目录跳转。
2 实测效果
2.1 理解并分析图片
(1)降水距平百分率专题图
输入一张全国降水距平百分率专题地图,让MiniGPT-4描述图中信息及图的含义。它误将“降水距平百分率”当做“降水量”,因此在回答中均以降水量多少(单位毫米)来解释专题图所包含的信息。显然它没有理解图名及图例的含义。另外,中国北部和东北部整体颜色明显不同,并不能一概而论。
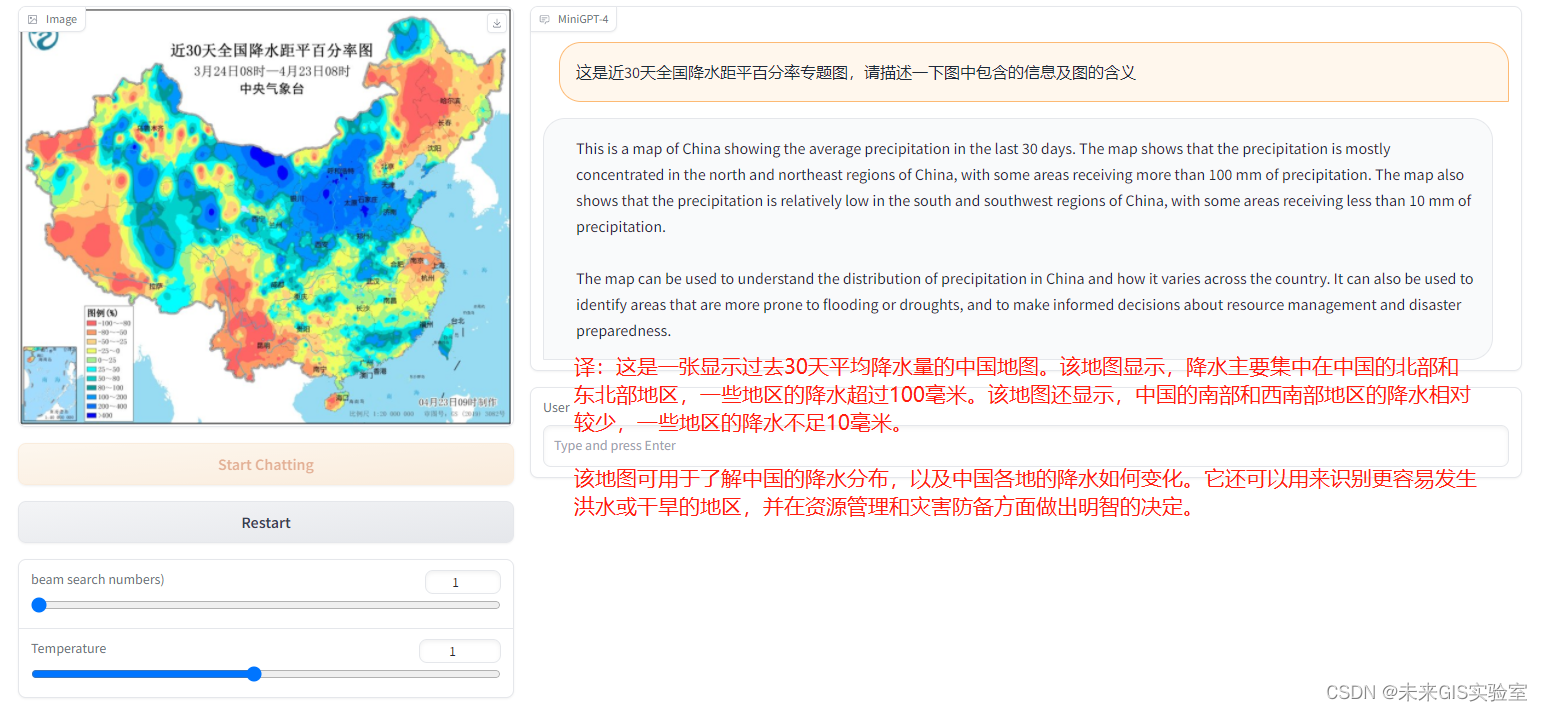 降水距平百分率指标是指某时段降水量与同期气候平均降水量之差除以同期气候平均降水量的百分比。降水距平百分率以历史平均水平为基础确定旱涝程度,反映了某时段降水量相对于同期平均状态的偏离程度。
降水距平百分率指标是指某时段降水量与同期气候平均降水量之差除以同期气候平均降水量的百分比。降水距平百分率以历史平均水平为基础确定旱涝程度,反映了某时段降水量相对于同期平均状态的偏离程度。
| 等级 |
干旱程度 |
降水距平百分率 |
| 1 |
无旱 |
>-15
扫描二维码关注公众号,回复:
17195463 查看本文章

|
| 2 |
轻旱 |
15~-30 |
| 3 |
中旱 |
30~-40 |
| 4 |
重旱 |
40~-45 |
| 5 |
特旱 |
<=-45 |
同样是30天全国降水距平百分率专题图,当给MiniGPT-4解释了什么是“降水距平百分率”,说明图例的含义即进行一定的人为引导之后,再让MiniGPT-4分析图中情况。这一次回答明显优于上一次。答案中提到了降水量距平百分率在20%~40%之间,且将该指标与干旱程度相联系,指出百分率低的地区干旱、百分率高的地方降水多。但是在具体地区分布上还不够准确。

考虑到第一次测试用中文提问,MiniGPT-4用英文回答的情况,推测该模型更“习惯”使用英文,对于英文的理解及问答能力更强。因此用英文提问同样的问题。此次测试中,MiniGPT-4能够直接用“降水量高于/低于平均水平”来代替“降水距平百分率”来回答问题,可见它理解了图名的含义。并且在第二段指出该图只显示了降水异常百分比,并不是实际的降水量信息,这个解释是非常正确与贴切的。

继续提问,如果未来几个月的气候仍然是这个趋势,那对东北地区的农业会有什么影响。MiniGPT-4根据专题图得到东北地区降水低于平均水平,会导致灌溉水减少、加剧土壤侵蚀、土壤肥力下降等,致使农作物减产,影响当地农业发展。并提出建议,要仔细监测和管理,减少天气对当地农业的负面影响。
经过多次、多方式的提问,答案经历了“不正确-不准确-不全面-较为全面”的过程。可见该模型具备图片理解能力,但是第一次提问过于泛泛,导致模型回答也比较模糊。在经过人为引导与提示之后,问题逐渐清晰、具体,模型回答也更加准确。因此掌握提问技巧,结合适当引导,该模型具备一定的应用价值。

(2)气候分布图
输入一张气候图让它解释一下。它回答这是中国地图,被划分成九个省,图上面显示了各省市的中英文名称。不提醒细节直接开问,除了能认出这是中国地图之外,其他完全不正确。
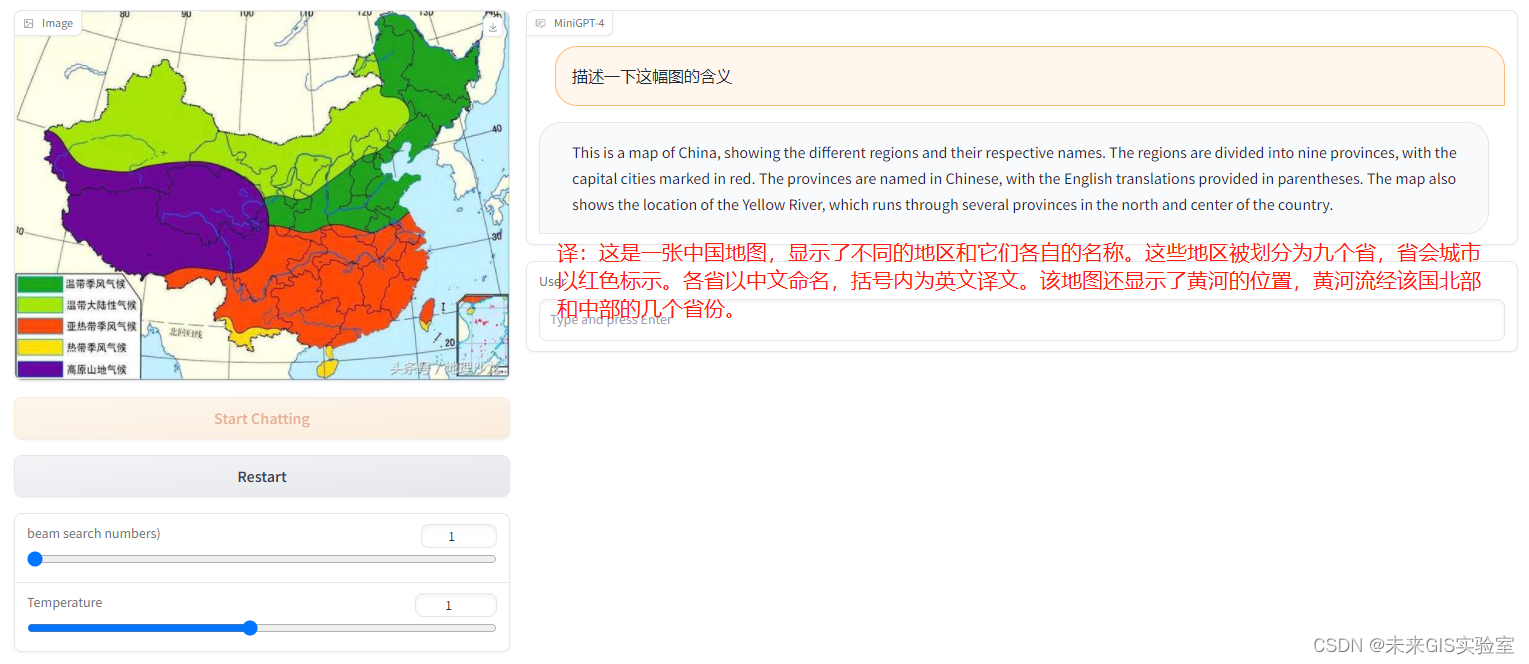
输入一幅英文版的气候分布图,同样简单提问这幅图的含义。MiniGPT-4能够正确回答出这是中国的气候分布图,并列出了包含的气候类型,不过答案的后半部分关于降水分布的阐述并不正确。但是与第一次问答相比,英文图文问答效果明显优于中文图文问答。

继续提问根据图中信息说明四川省的主要气候类型。结合提供给MiniGPT-4的气候分布图来看,四川仅有高原山地气候和亚热带季风气候。但模型回答了热带气候、亚热带气候、温带气候以及大陆性气候。虽然后面的气候特征与他自己回答的气候能够正确对应,但是某些气候在四川并不存在,且对于四川各个市地理位置的说明不完全正确。可见模型有一定的知识储备,但在知识储备与图片的理解与对应上还不够完善。

(3)土地利用类型统计图
输入一副土地利用类型统计图,图中显示了西南总体及广西、重庆、云南、贵州、四川五个省的土地利用(草地、耕地、灌木、森林、不透水面和其他)情况。MiniGPT-4的回答是山区植被分布情况,植被主要分为树木和草地,与图中表达信息并不相符。

将图中所有文字翻译为英文,并用英文提问。虽然答案更加丰富了,但是描述信息依然不正确。可见模型对于包含太多文字的图片理解能力较差,并不能将文字信息与图片信息有效对应。

(4) 地铁线路规划
输入一副成都市地铁线路图,给定起点、终点,让MiniGPT-4根据图中信息规划路线。它并未根据图中信息给出正确方案。

先后告知模型图例的含义、换乘站的标志等信息,经过多次引导也未能回答出正确路线。可见模型对于过于复杂的图像解读能力有限。

(5)年平均气温变化折线图
解释四川省年平均气温变化折线图。MiniGPT-4正确回答了该图为气温变化趋势图,但是年份不正确,范围也不正确。

在提问时稍加解释,这是1961到2021年四川省年平均气温逐年变化折线图,横坐标为年份,纵坐标为平均气温,红色折现为每年气温变化值,紫色直线为气温平均值。根据这些信息分析一下图中的信息,并说明你得到的结论。此时模型回答的更加全面,但是数据准确性欠佳。

(6)图表理解
上传一幅图表,让MiniGPT-4解释图表含义,回答完全不正确,似乎在毫无依据的胡说八道。究其原因,可能是图表中文字太多,重点是“表”,而不是“图”,所以模型并不能很好的理解。

(7)自然图片理解
上传一张“青蛙献花”的图片,从MiniGPT-4返回的答案来看,它对于自然图像的理解能力非常强,图中的重要信息基本涵盖,它甚至能够描述出青蛙是雕像,材质是陶瓷,地面是混凝土。

尝试让MiniGPT-4进行景物描述。第一次用中文提问,它回答的非常简单——“山水峡谷”,作的诗是一直重复一句话。第二次换成英文提问,它回答的就十分专业,图中山峰、植物、悬崖、水雾等要素全部能描绘出来,并且添加了丰富的形容词。再看它写的诗,主体明确、长短协调、结尾押韵、朗朗上口。

2.2 草图搭建网站
(1)官方的网站生成测试
MiniGPT-4官方的介绍中提到它可以从草图创建网站。官方展示的测试图如下,(a)图中让MiniGPT-4按照左边的草稿图绘制出网页,收到指令后,MiniGPT-4 给出对应的HTML代码,(b)图是根据MiniGPT-4提供的HTML代码制作的相应网站。

(a)

(b)
(2)模仿官方的测试
首先,将官网测试的图像重新手绘一遍,使用了更加清晰的图像和官网一样的提示语句。输出结果与官网结果有很大差异,CSS代码不完整,内容相比官网结果也更简单,根据输出的结果制作的网站也不能称之为网站,类似对图像做了一次文字识别又包装了一些HTML的元素。

上传图像,使用MiniGPT-4生成网站代码

△用生成的代码搭建的网站
更换更加明确的提问方式,结果还是一样。

△更换问题,结果一样
3 技术介绍
3.1 模型细节
MiniGPT-4 旨在将来自预训练视觉编码器的视觉信息与先进的大型语言模型 (LLM) 对齐。 具体来说,在文本方面,作者利用 Vicuna 作为语言解码器,在视觉感知方面,使用了与BLIP-2相同的视觉编码器,并且语言和视觉模型都是开源的。模型的主要目标就是使用线性映射层来减小视觉编码器和 LLM 之间的差距,模型架构图如下所示:
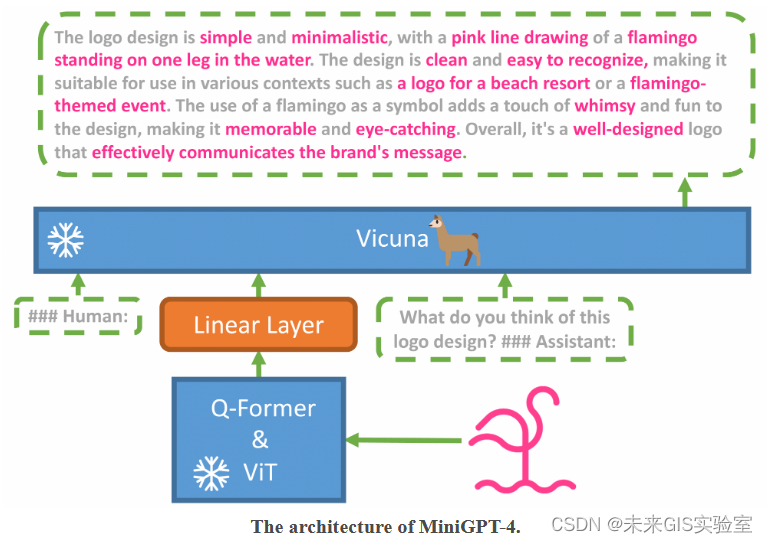
训练MiniGPT-4需要两个阶段:
第一个阶段是传统预训练阶段,使用了约500万张“图像-文本”数据对;经过这个阶段,模型具备了图像理解能力,但生成能力受到较大影响。为提升生成能力,还需要进行第二阶段的训练。
第二个阶段是微调阶段,使用了3500个高质量的“图像-文本”数据对,经过这一阶段,生成可靠性和整体稳定性得到显著提高。
至此,MiniGPT-4就具备了和GPT-4非常相似的视觉语言能力。
3.2 环境、模型、数据要求
如果要本地部署MiniGPT-4,需要准备以下软硬件环境和模型数据:
硬件环境:
需要准备显卡。
训练——预训练阶段:开发人员在4张A100上完成(耗时10个小时);微调阶段:开发人员在1张A100上完成(耗时7分钟)。
推理——130亿参数模型最少需要23G显存(例如24G显存的3090或4090),70亿参数模型最少需要11.5G显存。
如果直接使用预训练好的MiniGPT-4,那么无需准备训练所需的算力,只需准备推理的算力即可。
主要软件环境:
▪ cuda
▪ pytorch
▪ accelerate
▪ huggingface-hub
▪ openai
▪ tokenizers
▪ transformers
▪ sentence-transformers
模型:
▪ Vicuna
▪ LLaMA
需要准备Vicuna的预训练好的模型权重。但是因为Vicuna是基于LLaMA改动的,Vicuna的权重实际上不是能正常工作的权重,而是LLaMA模型权重的差异值。因此还需要自行准备LLaMA的模型权重。
有了LLaMA模型权重和Vicuna模型差异值权重,才能最终创建MiniGPT-4可以正常使用的模型权重。
数据:
▪ Laion数据集(预训练阶段使用)

△Laion数据集示例
▪ CC数据集(预训练阶段使用)

△CC数据集示例
▪ 开发团队自己创建的一个小型高质量“图像-文本”对数据集(微调阶段使用)
4 测试结论
MiniGPT-4具备一定的图片理解能力,但是目前还处在初级阶段,能力不稳定、准确性欠佳,具体情况如下:
(1)模型对于图片的理解能力受限于提问者的语言及图片中包含的语言:在实际测试过程中,问题、图片进行不同语言的组合,模型回答的准确、全面程度不同。根据实测情况汇总下述表格,可见一般情况下该模型更擅长英文图文的理解与问答,且对于无文字的图片理解能力优于有文字的图片。
| 用户提问 |
图片包含文字 |
模型回答 |
答案打分(5分制) |
|---|---|---|---|
| 中文 |
中文 |
中文 |
1 |
| 中文 |
中文 |
英文 |
2 |
| 中文 |
英文 |
英文 |
3 |
| 中文 |
无 |
中文 |
2 |
| 英文 |
中文 |
英文 |
3 |
| 英文 |
英文 |
英文 |
3.5 |
| 英文 |
无 |
英文 |
4 |
(2)模型对于图片的理解能力受图片中包含“知识”多少的影响:理解领域图片除了需要具备图像理解能力,还需要专业背景知识,因此在地图、统计图、线路图和图表等专业性较强、且包含信息和知识较多的图片上,实际应用效果并不理想。但是在自然图像上,如拍摄的照片、卡通图画等,能够描述画面内容,较为准确地回答用户问题,具备一定的可用行。
(3)引导式提问效果优于泛泛提问效果:输入一张图片,如果只是泛泛提问图片中包含什么信息,模型的回答也会比较模糊,更像是天马行空的随意回答。如果在提问时,提供给模型一些帮助信息,如图名、图例或专业词汇的意义等,即引导模型回答,效果往往会更好,答案更加准确、贴切。
(4)大模型的通用性使模型对于领域图片的理解更加丰富:模型使用各个领域的共500万张图-文对进行训练,其涵盖的信息广泛,通用性能更强。因此在图片理解过程中,考虑的因素也比较全面。比如在解释降水专题图时,它会结合地理位置、气候、土地利用类型、城市化程度等多方面分析。
(5)识别草图搭建网站的功能目前只是半成品:不管是模仿官网的测试,还是简单图像的测试,开放测试Demo的回答差强人意,不排除目前Demo只是其中的小参数版本。

「未来GIS实验室」作为超图研究院上游科研机构,致力于洞见未来GIS行业发展方向,验证前沿技术落地可行性,以及快速转化最新研究成果到关键产品。部门注重科研和创新功底,团队气氛自由融洽,科研氛围相对浓厚,每个人都有机会深耕自己感兴趣的前沿方向。