-
项目地址:https://minigpt-4.github.io/
-
论文链接:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
-
代码:https://github.com/Vision-CAIR/MiniGPT-4
-
视频:https://youtu.be/__tftoxpBAw
-
数据集:https://drive.google.com/file/d/1nJXhoEcy3KTExr17I7BXqY5Y9Lx_-n-9/view
-
Demo地址:https://6b89c70eb5e14dca33.gradio.live/
-
Demo备选地址1:https://b2517615b965687635.gradio.live/
-
Demo备选地址2:https://c8de8ff74b6a6c6a9b.gradio.live/
-
Demo备选地址3:https://0a111504e072685259.gradio.live/
-
Demo备选地址4:https://90bc0bac96e6457e8f.gradio.live/
Demo界面如下:
MiniGPT-4介绍
阿卜杜拉国王科技大学的研究团队,提出了一个具有类似 GPT-4 图像理解与对话能力的 AI 大模型——MiniGPT-4,并将其开源
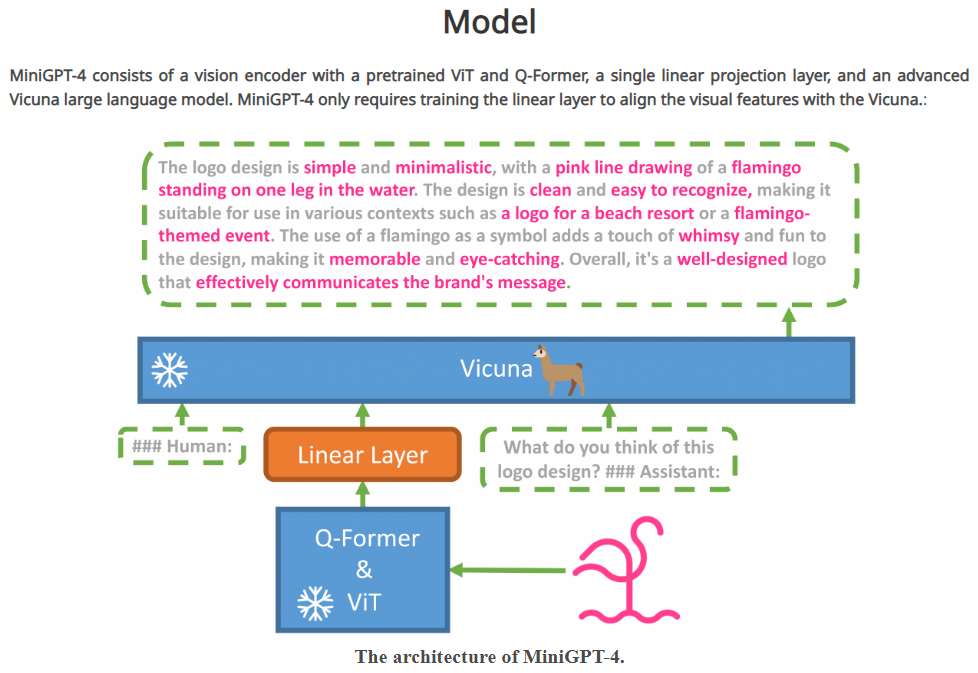
MiniGPT-4 由一个带有预训练的 ViT(与BLIP-2一样) 和 Q-Former 的视觉编码器、一个单一的线性投影层和一个 Vicuna 大语言模型组成,只训练线性投影层,视觉编码器和Vicuna的参数冻结。模型结构如下图所示:
实验发现,MiniGPT-4 具有出色的多模态能力,如从手写草稿创建网站、生成详细的图像描述、根据图像创作故事和诗歌、为图像中描述的问题提供解决方案,以及根据食物照片教对话对象如何烹饪一道美味的菜品等
MiniGPT-4两阶段fine-tuning
作者采用两阶段fine-tuningMiniGPT-4,第一阶段是在公开数据上微调,第二阶段是构建高质量的对话数据再微调。
First pretraining stage
MiniGPT-4使用一个线性投影层来对齐Vicuna语言编码器和视觉特征。刚开始,使用4个A100GPU以batch大小为256训练了20k个step(训练了10小时),训练数据是LAION,Conceptual Captions和SBU(总共5M数据),数据格式如下所示:

<ImageFeature> 表示是线性投影层得到的视觉特征。
如果生成的句子不够80个tokens,那么就在后面pad ###Human: Continue ###Assistant:
构建第二阶段微调所需要的数据
从Conceptual Caption数据集中随机选择5000个样本,这些样本可能会有噪声或者有错误,使用ChatGPT进行修复这些错误,Prompt如下:

最终人工进行检查,最后整理符合要求的样本有3500个,这些样本将用于第二阶段微调。
Second pretraining stage
第二阶段微调的Prompt数据格式如下:
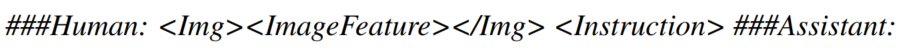
<Instruction> 是从预定义好的instruction集中随机采样的,比如“Describe this image in detail”或“Could you describe the contents of this image for me”
Note:在计算回归损失函数的时候不计算<Instruction> 这个特殊的Prompt。
这个阶段使用一个A100GPU在batch大小为12的时候,训练400个step,仅仅训练了7分钟。
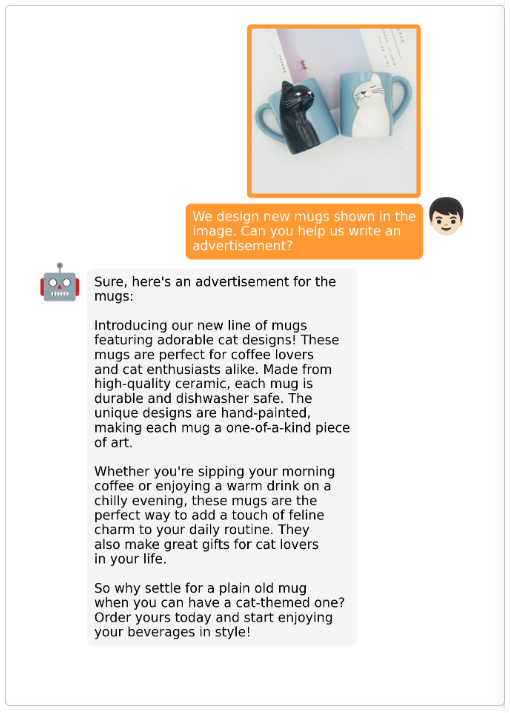
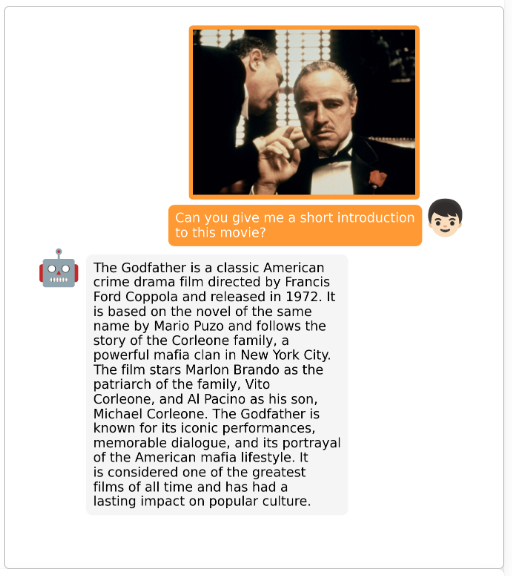
MiniGPT-4示例