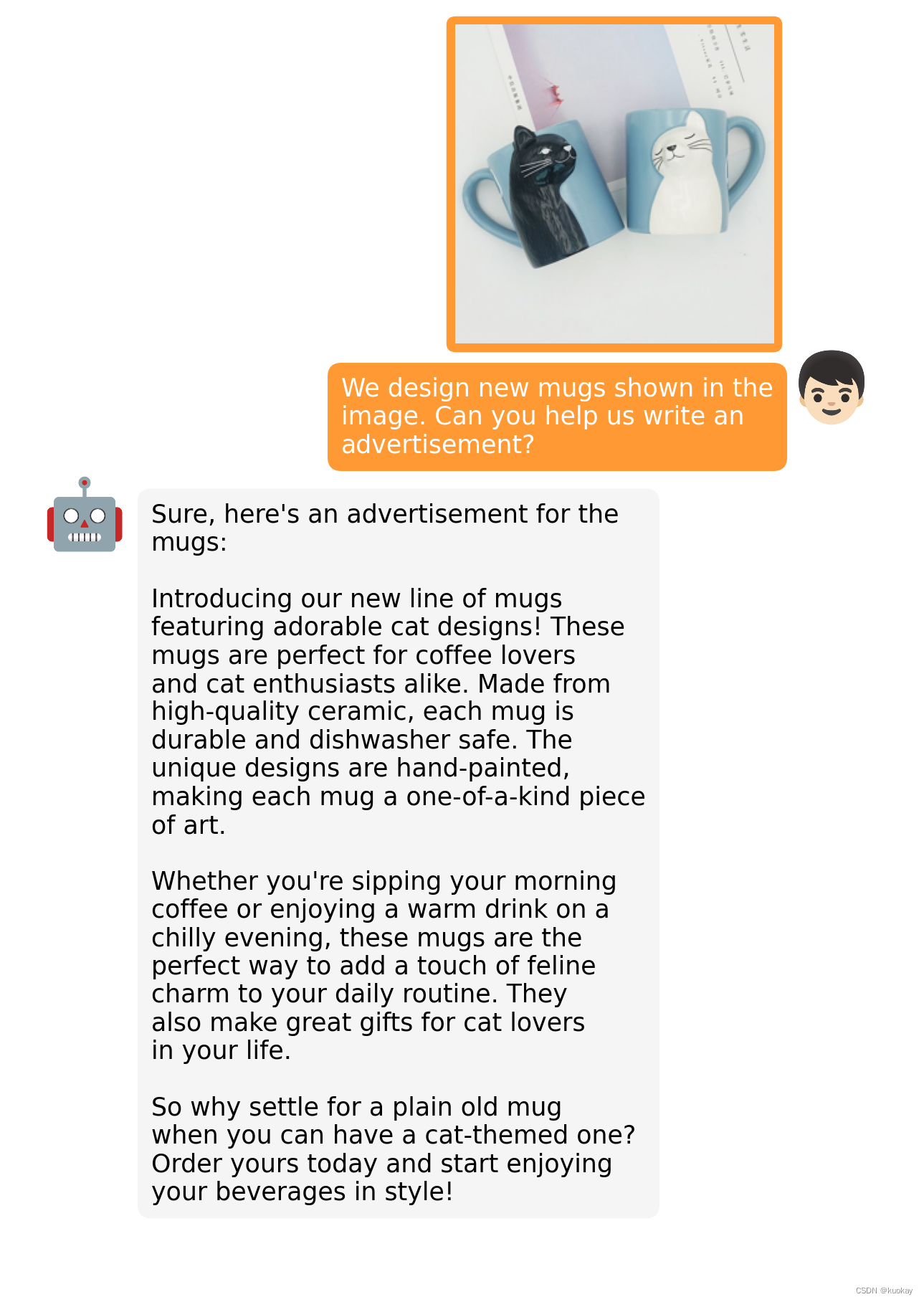
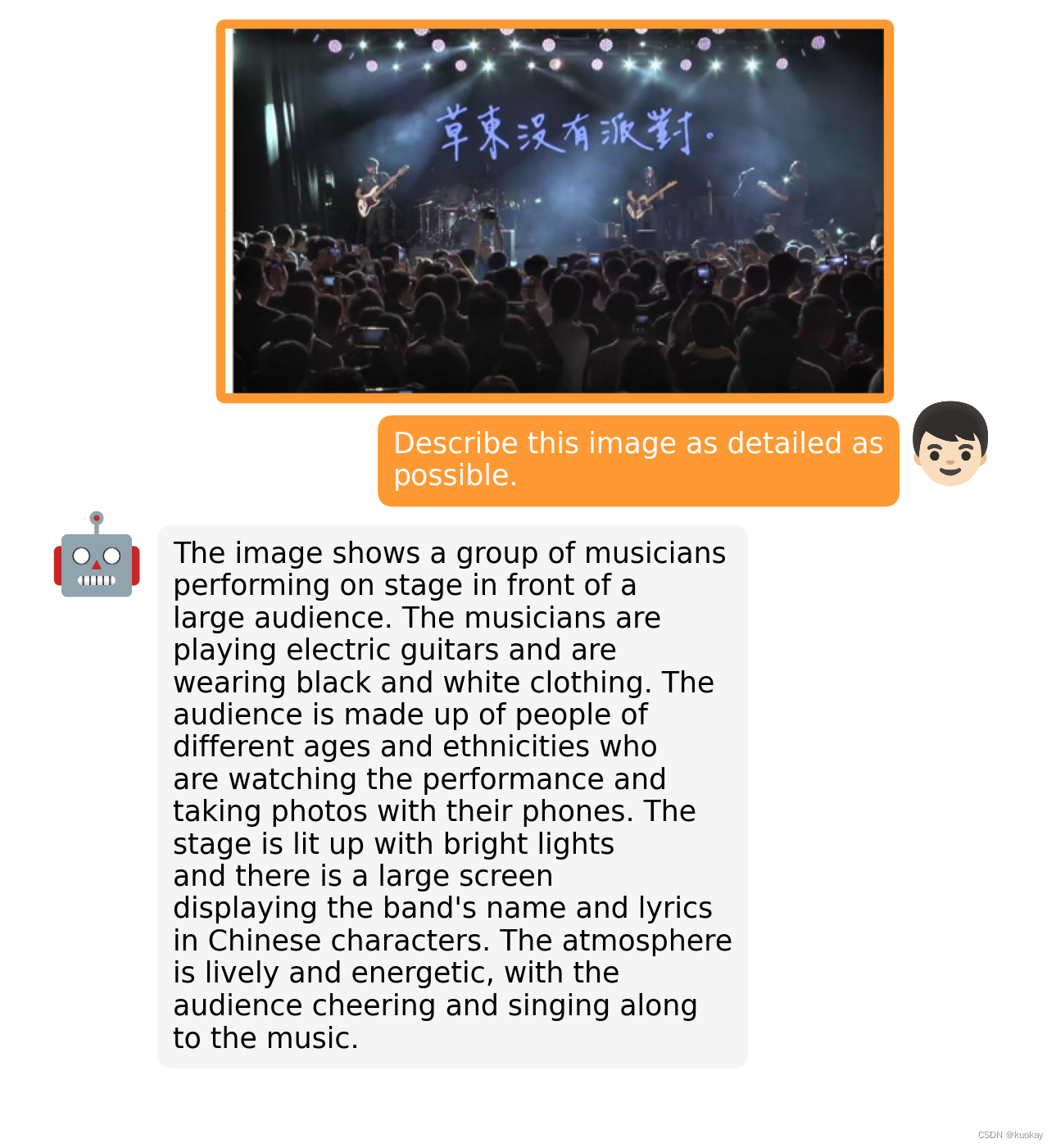
简介
MiniGPT-4 旨在将来自预训练视觉编码器的视觉信息与先进的大型语言模型 (LLM) 对齐。 具体来说,在文本方面,作者利用 Vicuna 作为语言解码器,在视觉感知方面,使用了与BLIP-2相同的视觉编码器,并且语言和视觉模型都是开源的。本文的主要目标就是使用线性映射层来弥合视觉编码器和 LLM 之间的差距,模型架构图如下所示:
特性:
- MiniGPT-4仅使用一个投影层将来自BLIP-2的冻结视觉编码器与冻结的LLM,Vicuna对齐。
- 我们分两个阶段训练 MiniGPT-4。第一个传统的预训练阶段是使用 5 个 A10 在 4 小时内使用大约 100 万个对齐的图像文本对进行训练。在第一阶段之后,骆马能够理解图像。但骆马的生成能力受到严重影响。
- 为了解决这个问题并提高可用性,我们提出了一种新颖的方法,通过模型本身和 ChatGPT 一起创建高质量的图像文本对。在此基础上,我们创建了一个小的(总共3500对)但高质量的数据集。
- 第二个微调阶段在对话模板中对此数据集进行训练,以显着提高其生成可靠性和整体可用性。令我们惊讶的是,这个阶段的计算效率很高,使用单个 A7 只需要大约 100 分钟。
- MiniGPT-4 产生了许多新兴的视觉语言功能,类似于 GPT-4 中展示的功能。
项目地址:https://github.com/Vision-CAIR/MiniGPT-4#online-demo
在线体验地址:https://minigpt-4.github.io/
快速体验
- 准备代码和环境
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4
- 准备训练的Vicuna权重文件
当前版本的Minigpt-4建立在Vicuna-13b的V0 Versoin上。请在此处参考他们的说明以获取权重。最终权重将在一个具有以下结构的单个文件夹中:
>vicuna_weights
├── config.json
├── generation_config.json
├── pytorch_model.bin.index.json
├── pytorch_model-00001-of-00003.bin
- 在本地启动演示
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml
训练
MiniGPT-4的训练包含两个对齐阶段。
-
在第一个预训练阶段,使用来自Laion和CC数据集的图像文本对训练模型 以调整视觉和语言模型。要下载和准备数据集,请检查 我们的第一阶段数据集准备说明https://github.com/Vision-CAIR/MiniGPT-4/blob/main/dataset/README_1_STAGE.md。 在第一阶段之后,视觉特征被映射并可以被语言理解 型。 若要启动第一阶段训练,请运行以下命令。在我们的实验中,我们使用4 A100。 您可以在配置文件中更改保存路径 train_configs/minigpt4_stage1_pretrain.yaml
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage1_pretrain.yaml
-
在第二阶段,我们使用自己创建的小型高质量图像文本对数据集 并将其转换为对话格式以进一步对齐 MiniGPT-4。 要下载并准备我们的第二阶段数据集,请查看我们的第二阶段数据集准备说明https://github.com/Vision-CAIR/MiniGPT-4/blob/main/dataset/README_2_STAGE.md。 要启动第二阶段对齐, 首先指定在 train_configs/minigpt1_stage4_pretrain.yaml 中在第 1 阶段训练的检查点文件的路径。 您还可以在此处指定输出路径。 然后,运行以下命令。在我们的实验中,我们使用 1 个 A100。
实验结果