多模态:MiniGPT-4
Introduction
GPT-4具有很好的多模态能力,但是不开源。大模型最近发展的也十分迅速,大模型的涌现能力可以很好的迁移到各类任务,于是作者猜想这种能力可不可以应用到多模态模型,让它具有与GPT-4类似的能力。
为了实现这个假设,作者采用了号称具有ChatGPT百分之90能力的Vicuna13B作为语言模型,采用与BLIP-2相同的视觉模块(ViT-G/14的视觉Encoder和Q-former),然后在用linear继续align视觉特征与文字特征。
然后在raw 的image- text上面训练,作者发现还不能够让他成为一个具有视觉能力的chat bot,于是作者标注了3500个高质量的数据对,然后微调。
在实验中,发现了与GPT-4类似的视觉能力。
Method
通过上述的介绍,可以很清晰的看懂下图模型结构:
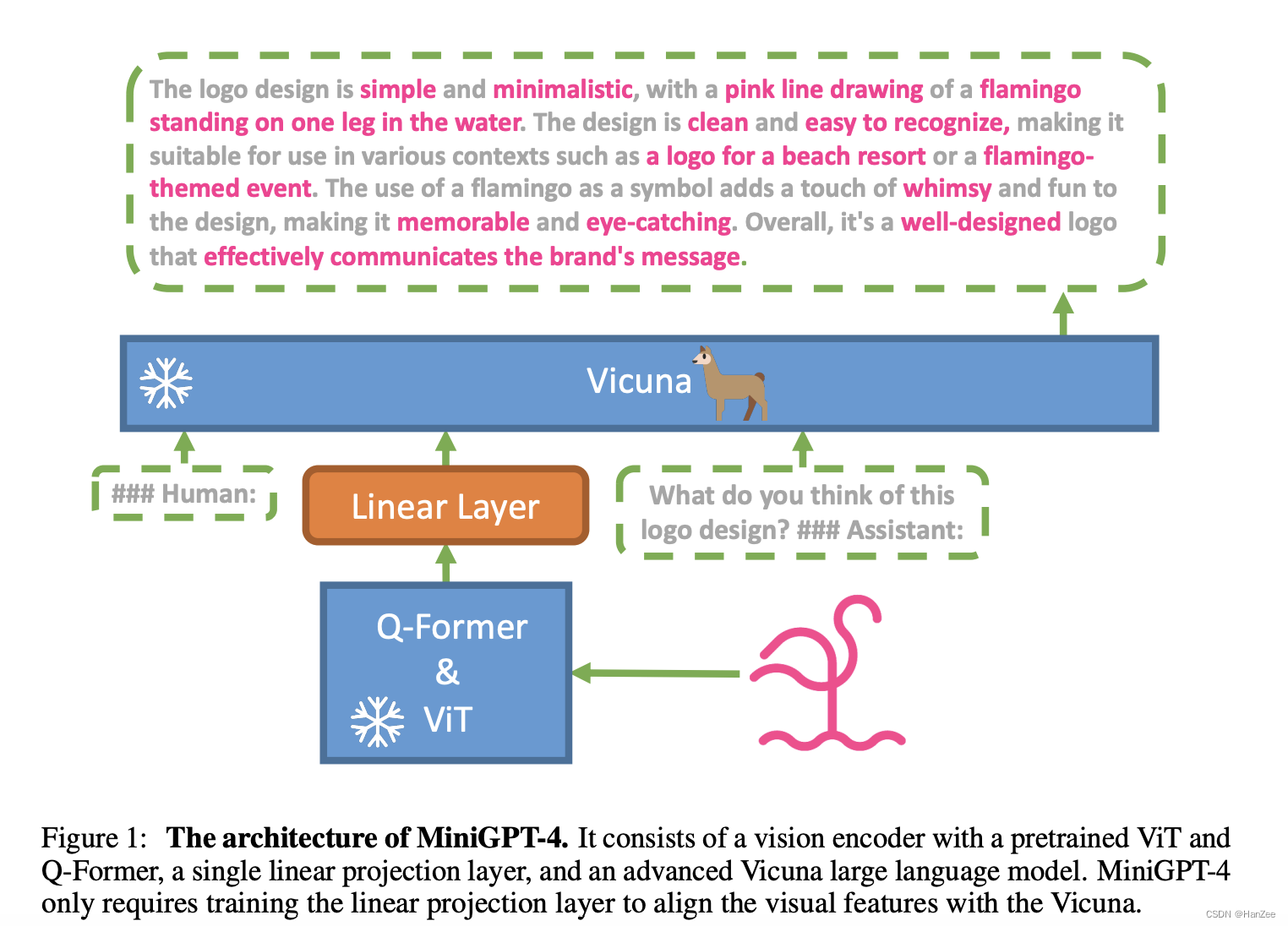
其中ViT、Q-Former、LLM均采用预训练模型,只训练linear layer。
其中训练分为两个阶段,第一阶段为初始化阶段,在大量的 raw text-image 训练学习视觉-文本先验知识。 大约5m个数据对,迭代了20000steps,batch=256.
训练完成后,作者发现,效果并没有达到一个具有视觉能力的对话机器的人水平,会出现 不能生成连贯的语句、重复句子、单词、不相关的内容等。。。
作者指出这种情况与当时的GPT-3很像,GPT-3通过SFT,RLHF才进化成了GPT-3.5,获得了可以与人类对齐的能力。
于是作者想继续对它执行SFT,但是image-text 数据对的获取难度要比指令数据大的多。
在初始化阶段,作者也为模型做了一个template,
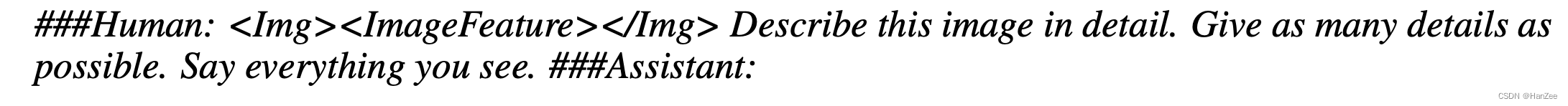
其中Image feature 就是经过线性层的图像特征,为了识别不完整的句子作者检查token是否大于80,如果小于80,在第二次输出结尾接上一个模版,
也就是template1+output1+template2
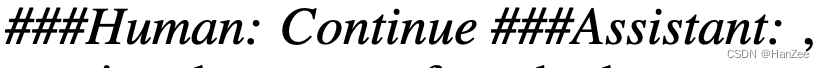
完成训练后,作者在此随机选取5000个数据对,生成数据。
然后作者又提出了Data post- processing 过程,是指通过ChatGPT去精修之前5000个图像的文本。
prompt:

通过上述操作,获取了3500-5000张高质量数据对。
然后通过这些数据执行SFT阶段。
template:
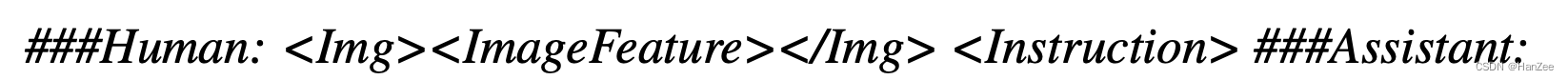
limitation
- 集成了LLM的缺点,容易产生幻觉。(胡编乱造)
- sft数据不够。
- 冻结VIT可能会缺乏一些必要的特征。
- 只训练一个linear 可能不够。
参考
https://arxiv.org/pdf/2304.10592.pdf